") 一款采用單位元精度的深度學(xué)習(xí)推論(inference)芯片原型
一款采用單位元精度的深度學(xué)習(xí)推論(inference)芯片原型
比利時(shí)研究機(jī)構(gòu)Imec在近日舉行的年度技術(shù)論壇(ITF BELGIUM 2018)上透露,該機(jī)構(gòu)正在打造一款采用單位元精度的深度學(xué)習(xí)推論(inference)芯片原型;Imec并期望在明年收集采用創(chuàng)新資料型態(tài)與架構(gòu)──采用存儲(chǔ)器內(nèi)處理器(processor-in-memory,PIM),或是Analog存儲(chǔ)器結(jié)構(gòu)(analog memory fabric)──的客戶端裝置有效性資料。
學(xué)術(shù)界已經(jīng)研究PIM架構(gòu)數(shù)十年,而該架構(gòu)越來(lái)越受到資料密集的機(jī)器演算法歡迎,例如新創(chuàng)公司Mythic以及IBM Research都有相關(guān)開(kāi)發(fā)成果。許多學(xué)術(shù)研究機(jī)構(gòu)正在實(shí)驗(yàn)1~4位元的資料型別(data type),以減輕深度學(xué)習(xí)所需的沉重存儲(chǔ)器需求;到目前為止,包括Arm等公司的AI加速器商用芯片設(shè)計(jì)都集中在8位元或更大容量的資料型別,部分原因是編程工具例如Google的TensorFlow缺乏對(duì)較小資料型別的支援。
Imec擁有在一家晶圓代工廠制作的40nm制程加速器邏輯部份,而現(xiàn)在是要在自家晶圓廠添加一個(gè)MRAM層;該機(jī)構(gòu)利用SRAM模擬此設(shè)計(jì)的性能,并且評(píng)估5nm節(jié)點(diǎn)的設(shè)計(jì)規(guī)則。此研究是Imec與至少兩家匿名IDM業(yè)者伙伴合作、仍在開(kāi)發(fā)階段的專(zhuān)案,從近兩年前展開(kāi),很快制作了采用某種電阻式存儲(chǔ)器(ReRAM)的65nmPIM設(shè)計(jì)原型。
該65nm芯片并非鎖定深度學(xué)習(xí)演算法,雖然Imec展示了利用它啟動(dòng)一段迷人的電腦合成音樂(lè);其學(xué)習(xí)模式是利用了根據(jù)以音樂(lè)形式呈現(xiàn)、從感測(cè)器所串流之資料的時(shí)間序列分析(time-series analysis)。而40nm低功耗神經(jīng)網(wǎng)路加速器(Low-Energy Neural Network Accelerator,LENNA)則會(huì)鎖定深度學(xué)習(xí),在相對(duì)較小型的MRAM單元中運(yùn)算與儲(chǔ)存二進(jìn)位權(quán)重。
Imec技術(shù)團(tuán)隊(duì)的杰出成員Diederik Verkest接受EE Times采訪時(shí)表示:「我們的任務(wù)是定義出我們應(yīng)該利用新興存儲(chǔ)器為機(jī)器學(xué)習(xí)開(kāi)發(fā)什么樣的半導(dǎo)體技術(shù)──或許我們會(huì)需要制程上的調(diào)整,」以取得最佳化結(jié)果。該機(jī)構(gòu)半導(dǎo)體技術(shù)與系統(tǒng)部門(mén)執(zhí)行副總裁An Steegen則表示:「AI會(huì)是制程技術(shù)藍(lán)圖演化的推手,因此Imec會(huì)在AI (以及PIM架構(gòu))方面下很多功夫──這方面的工作成果將會(huì)非常重要。」
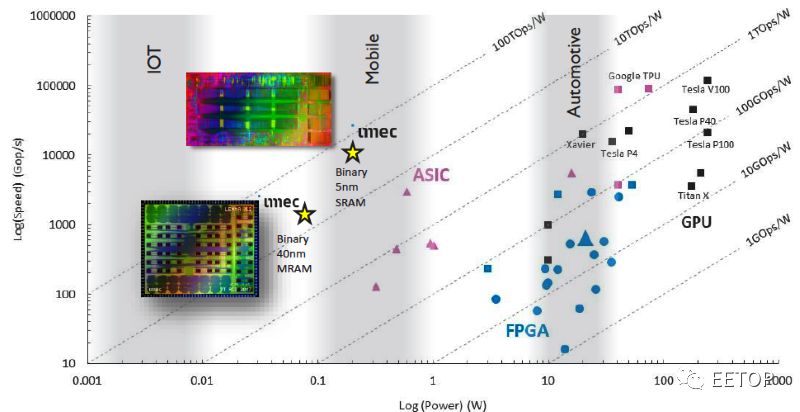
Imec聲稱(chēng)其LENNA芯片在推論任務(wù)上的表現(xiàn)將超越現(xiàn)有的CPU與GPU
確實(shí),如來(lái)自英國(guó)的新創(chuàng)公司Graphcore執(zhí)行長(zhǎng)Nigel Toon所言,AI標(biāo)志著「運(yùn)算技術(shù)的根本性轉(zhuǎn)變」;該公司將于今年稍晚推出首款芯片。Toon在Imec年度技術(shù)論壇上發(fā)表專(zhuān)題演說(shuō)時(shí)表示:「今日的硬體限制了我們,我們需要某種更靈活的方案…我們想看到能根據(jù)經(jīng)驗(yàn)調(diào)整的(神經(jīng)網(wǎng)路)模型;」他舉例指出,兩年前Google實(shí)習(xí)生總共花了25萬(wàn)美元電費(fèi),只為了在該公司采用傳統(tǒng)x86處理器或Nvidia GPU的資料中心嘗試最佳化神經(jīng)網(wǎng)路模型。
實(shí)現(xiàn)復(fù)雜的折衷平衡
Imec希望LENNA能在關(guān)于PIM或Analog存儲(chǔ)器架構(gòu)能比需要存取外部存儲(chǔ)器的傳統(tǒng)架構(gòu)節(jié)省多少能量方面提供經(jīng)驗(yàn);此外該機(jī)構(gòu)的另一個(gè)目標(biāo),是量化采用二進(jìn)制方案在精確度、成本與處理量方面的折衷(tradeoff)。
加速器芯片通常能在一些熱門(mén)的測(cè)試上提供約90%的精確度,例如ImageNet競(jìng)賽;Verkest表示,單位元資料型別目前有10%左右的精度削減,「但如果你調(diào)整你的神經(jīng)網(wǎng)路,可以達(dá)到最高85%~87%的精確度。」他原本負(fù)責(zé)督導(dǎo)Imec的邏輯制程微縮技術(shù)藍(lán)圖,在Apple挖腳該機(jī)構(gòu)的第一個(gè)AI專(zhuān)案經(jīng)理之后,又兼管AI專(zhuān)案。
Verkest表示,理論上Analog存儲(chǔ)器單元應(yīng)該能以一系列數(shù)值來(lái)儲(chǔ)存權(quán)重(weights),但是「那些存儲(chǔ)器元件的變異性有很多需要考量之處;」他指出,Imec的開(kāi)發(fā)專(zhuān)案將嘗試找出能提供最佳化精度、處理量與可靠度之間最佳化平衡的精度水準(zhǔn)。
而Toon則認(rèn)為聚焦于資料型別是被誤導(dǎo)了:「低精度并沒(méi)有某些人想得那么嚴(yán)重,存儲(chǔ)器存取是我們必須修正之處;」他并未詳細(xì)介紹Graphcore的解決方案,但聲稱(chēng)該公司技術(shù)可提供比目前采用HBM2存儲(chǔ)器的最佳GPU高40倍的存儲(chǔ)器頻寬。
在芯片架構(gòu)方面,Imec的研究人員還未決定他們是要設(shè)計(jì)PIM或采用Analog存儲(chǔ)器結(jié)構(gòu);后者比較像是一種Analog SoC,計(jì)算是在Analog區(qū)塊處理,可因此減少或免除數(shù)位-Analog轉(zhuǎn)換。不同種類(lèi)的神經(jīng)網(wǎng)路會(huì)有更適合的不同架構(gòu),例如卷積神經(jīng)網(wǎng)路(CNN)會(huì)儲(chǔ)存與重復(fù)使用權(quán)重,通常能以傳統(tǒng)GPU妥善運(yùn)作;歸遞神經(jīng)網(wǎng)路(RNN)以及長(zhǎng)短期記憶模型(long short-term memories,LSTMs)則傾向于在使用過(guò)后就拋棄權(quán)重,因此更適合運(yùn)算式存儲(chǔ)器結(jié)構(gòu)

Imec可能會(huì)以存儲(chǔ)器結(jié)構(gòu)來(lái)打造LENNA,讓運(yùn)算留在Analog功能區(qū)塊
新的平行架構(gòu)非常難編程,因此大多數(shù)供應(yīng)商正在嘗試建立在TensorFlow等現(xiàn)有架構(gòu)中攝取程式碼的途徑。而Graphcore則是打造了一種名為Poplar的軟體層,旨在以C++或Python語(yǔ)言來(lái)完成這項(xiàng)工作;Toon表示:「我們把在處理器中映射圖形(graphs)的復(fù)雜性推到編譯器(也就是扮演該角色的Poplar)。」
Graphcore的客戶很快就會(huì)發(fā)現(xiàn)該程序會(huì)有多簡(jiǎn)單或是多困難;這家新創(chuàng)公司預(yù)計(jì)在年中將第一款產(chǎn)品出貨給一線大客戶,預(yù)期他們會(huì)在今年底采用該款芯片執(zhí)行大型云端供應(yīng)商的服務(wù)。Toon聲稱(chēng),其加速器芯片將能把CNN的速度提升五至十倍,同時(shí)間采用RNN或LSTM的更復(fù)雜模型則能看到100倍的效能提升。
-
存儲(chǔ)器
+關(guān)注
關(guān)注
38文章
7502瀏覽量
163936 -
加速器
+關(guān)注
關(guān)注
2文章
800瀏覽量
37917 -
AI芯片
+關(guān)注
關(guān)注
17文章
1889瀏覽量
35074
原文標(biāo)題:Imec等多家公司正力促AI芯片設(shè)計(jì)最佳化
文章出處:【微信號(hào):eetop-1,微信公眾號(hào):EETOP】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論