 盤點一些應用于汽車自動駕駛的芯片
盤點一些應用于汽車自動駕駛的芯片
當硬件傳感器接收到環境信息后,數據會被導入到計算平臺,進而由不同芯片進行運算。無人駕駛硬件平臺是多種技術、多個模塊的集成,主要包括:傳感器平臺、計算平臺、以及控制平臺。本文將詳細介紹計算平臺現有的解決方案。
無人駕駛硬件平臺是多種技術、多個模塊的集成,主要包括:傳感器平臺、計算平臺、以及控制平臺。本文將詳細介紹計算平臺現有的解決方案。
經常看我們公眾號的朋友應該知道,當硬件傳感器接收到環境信息后,數據會被導入到計算平臺,進而由不同芯片進行運算。計算平臺的設計直接影響無人駕駛系統的實時性和魯棒性。
目前主流的自動駕駛芯片解決方案主要包括GPU、FPGA、DSP和ASIC四種。本文除了列舉這四種之外,還列舉其他的一些應用于汽車自動駕駛的芯片。
1.英偉達基于GPU的計算解決方案——DRIVE PX
NVIDIA DRIVE PX 2自動駕駛開發平臺
NVIDIA的PX平臺是目前領先的基于GPU的無人駕駛解決方案。2016年1月,搭載“Pascal顯卡”的DrivePX2自動駕駛平臺正式問世。
DRIVE PX 2的一些基本性能參數:
1.基于16nm FinFET工藝,功耗高達250W ,采用水冷散熱設計。支持12路攝像頭輸入、激光定位、雷達和超聲波傳感器;
2. CPU部分:兩顆新一代NVIDIA Tegra處理器,當中包括了8個A57核心和4個Denver核心;
3. 首發NVIDIA的新一代GPU架構Pascal(即帕斯卡,宣稱性能是上一代的麥克斯韋構架的10倍),單精度計算能力達到8TFlops,超越TITAN X,有后者10倍以上的深度學習計算能力。
每個PX2由兩個Tegra SoC和兩個Pascal GPU圖形處理器組成,其中每個圖像處理器都有自己的專用內存并配備有專用的指令以完成深度神經網絡加速。為了提供高吞吐量,每個Tegra SOC使用PCI-E Gen 2 x4總線與Pascal GPU直接相連,其總帶寬為4 GB/s。此外,兩個CPU-GPU集群通過千兆以太網項鏈,數據傳輸速度可達70 Gigabit/s。借助于優化的I/O架構與深度神經網絡的硬件加速,每個PX2能夠每秒執行24兆次深度學習計算。這意味著當運行AlexNet深度學習典型應用時,PX2的處理能力可達2800幀/秒。
NVIDIA的DRIVE PX 2平臺到底如何在自動駕駛汽車上發揮作用呢?這里要重點講一下它在高精度地圖繪制上發揮的優勢。DRIVE PX 2能夠將外部傳感器獲取的圖像數據加工處理后制成單個的高精度點云。系統將所有DRIVE PX 2平臺的點云數據上傳至云端服務器,經過DGX-1處理后,可融合為一副完整的高精度地圖。所以,車內的DRIVE PX 2,云端的DGX-1配合發揮作用,形成了NVIDIA完整的自動駕駛技術平臺解決方案。
Pegasus
NVIDIA于其今年的生態圈大會GTC Eurpoe上發表自動駕駛運算平臺Drive PX家族的新成員,其代號為「Pegasus」。 「Pegasus」預計從2018年第二季起提供給NVIDIA的自動駕駛研發伙伴。
據稱「Pegasus」的運算能力達到320 TOPS(Trillion OperaTIons Per Second),超越其前代平臺「Drive PX 2」之運算能力高達10倍。 此運算能力主要來自于4顆處理器-2顆為以NVIDIA目前最新GPU架構「Volta」為核心的SoC「Xavier」、以及另外2顆為車用機械視覺與深度學習所準備的專用GPU。
2.德州儀器基于DSP的解決方案——TDA2x SoC
TI TDA2x SoC
德州儀器提供了一種基于DSP的無人駕駛的解決方案。其TDA2x SoC擁有兩個浮點DSP內核C66x和四個專為視覺處理設計的完全可編程的視覺加速器。相比ARM Cortex-15處理器,視覺加速器可提供八倍的視覺處理加速且功耗更低。類似設計有CEVA XM4。這是另一款基于DSP的無人駕駛計算解決方案,專門面向計算視覺任務中的視頻流分析計算。使用CEVA XM4每秒處理30幀1080p的視頻僅消耗功率30MW,是一種相對節能的解決方案。
TDA2x SoC 基于異構可擴展架構,該架構包括 TI 定浮點 C66x DSP 內核、全面可編程Vision AccelerationPac、ARM? Cortex?-A15 MPCoreTM 處理器與兩個 Cortex-M4 內核,以及視頻及圖形內核與大量的外設。
該 TDA2x 可實現各種前置攝像機應用的同步運行,其中包括遠光燈輔助、車道保持輔助、高級巡航控制、交通信號識別、行人/對象檢測以及防碰撞等。此外,TDA2x 還支持智能 2D 及 3D 環繞視圖以及后方碰撞警告等泊車輔助應用,并可運行為前置攝像機開發的行人/對象算法。TI TDA2x 還可作為融合雷達與攝像機傳感器數據的中央處理器,幫助做出更穩健的 ADAS 決定。
3.Altera基于FPGA的解決方案——CycloneV SoC
Altera Cyclone V芯片
Altera公司的Cyclone V SoC是一個基于FPGA的無人駕駛解決方案,CycloneV SoC FPGA 系列基于28nm低功耗(LP)工藝,提供需要5G收發器應用的最低功耗,和以前的產品檢驗相比,功耗降低40%.器件集成了基于ARM處理器的硬件處理器系統(HPS),具有更有效的邏輯綜合功能,收發器系列和SoC FPGA系列,從而降低系統功耗。主要用在工業無線和有線通信、軍用設備和汽車市場。
Cyclone V SoC現已應用在奧迪無人車產品中。Altera公司的FPGA專為傳感器融合提供優化,可結合分析來自多個傳感器的數據以完成高度可靠的物體檢測。類似的產品有Zynq專為無人駕駛設計的Ultra ScaleMPSoC。當運行卷積神經網絡計算任務時,Ultra ScaleMPSoC運算效能為14幀/秒/瓦,優于NVIDIA Tesla K40 GPU可達的4幀/秒/瓦。同時,在目標跟蹤計算方面,Ultra ScaleMPSoC在1080p視頻流上的處理能力可達60fps。
奧迪全新A8車型上搭載的zFAS域控制器就使用了Altera提供的FPGA芯片-Cyclonev Soc
4.Mobileye基于ASIC的解決方案——Eyeq5SOC
ASIC(Application SpecificIntegrated Circuits)即專用集成電路,是指應特定用戶要求和特定電子系統的需要而設計、制造的集成電路。Mobileye是一家基于ASIC的無人駕駛解決方案提供商。
Mobileye EyeQ5芯片將裝備8枚多線程CPU內核,同時還會搭載18枚Mobileye的下一代視覺處理器。“傳感器融合”是EyeQ5推出的主要目的。
其Eyeq5 SOC裝備有四種異構的全編程加速器,分別對專有的算法進行了優化,包括有:計算機視覺、信號處理和機器學習等。Eyeq5 SOC同時實現了兩個PCI-E端口以支持多處理器間通信。這種加速器架構嘗試為每一個計算任務適配最合適的計算單元,硬件資源的多樣性使應用程序能夠節省計算時間并提高計算效能。
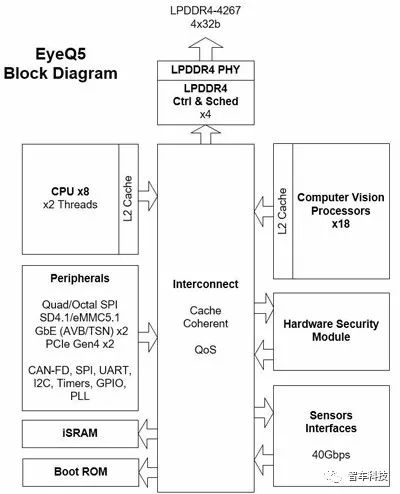
mobileyeEyeQ5 芯片的電路系統塊圖(block diagram)
5.其他
1)谷歌的計算平臺——TPU芯片
谷歌TPU芯片
谷歌公布了AlphaGo戰勝李世石的“秘密武器”就是芯片TPU(張亮處理單元,Tensor Processing Unit),TPU專門為谷歌TensorFlow等機器學習應用打造,能夠降低運算精度,在相同時間內處理更復雜、更強大的機器學習模型并將其更快投入使用。其性能把人工智能技術往前推進了7年左右,相當于摩爾定律的3代時間。
TPU使得機器學習類深度神經網絡模型在每瓦特性能上由于傳統硬件。TPU在2016谷歌I/O大會上首次被提及,然而谷歌早在2013年就已經開始秘密研發TPU,并于2014年就應用在了谷歌的數據中心。
相比GPU的適合訓練,TPU更適合做訓練后的分析決策。這一點在谷歌的官方生命中得到印證:TPU只在特定的機器學習應用中起到輔助作用,公司將繼續使用其他廠商制造的CPU和GPU。
在2018谷歌I/O大會上,谷歌宣布新的張量處理單元(TPU)將幫助谷歌改進使用AI的應用程序,新版本TPU與它的前身類似,也將通過谷歌的公共云服務向第三方開發者開放,并表示,每個芯片的性能都是去年的8倍,遠遠超過了100Petaflops(Petaflops:每秒一千兆/一千萬億(10^15)次的浮點運算)。”而目前,容納16個英偉達最新GPU的盒子僅能提供2Petaflops的計算能力。
2)恩智浦NXP自動駕駛汽車的計算平臺BlueBox
BlueBox是一款基于Linux系統打造的開放式計算平臺,可供主機廠和一級供應商開發、試驗自己的無人駕駛汽車。它的主要功能是將之前彼此隔離的單個傳感器節點和處理器進行功能上的結合。BlueBox能夠在40W功率下實現90000 DMIPS(每秒百萬條指令)的計算速度。但相比其他競爭對手提供的ADAS/自動駕駛解決方案,BlueBox減少了對風扇、液冷及不穩定熱能管理系統等電器元件的使用。
BlueBox裝備了一枚恩智浦NXP S32V汽車視覺處理器和一枚LS2088A內嵌式計算機處理器。S32V屬于安全控制器范疇,能夠分析駕駛環境,評估風險因素,然后指示汽車的行為,而LS2088則是為其保駕護航的高性能計算平臺。
S32V芯片包含有不同的圖形處理引擎,特制的高性能圖形處理加速器,高性能ARM內核,高級APEX圖形處理和傳感器融合。它的功能包括了傳感器/執行器管理和故障檢驗。其中故障檢驗除能夠對內存、硬件配置和程序流實時檢測外,它還具備錯誤管理能力。
而負責進行高性能運算的LS2088A內嵌式處理器是由8個64位ARM Cortex-A72內核組成,配合頻率2GHz的特制加速器、高性能通信接口和DDR4內存控制器,延時極低。
除了S32V和LS2088A這兩枚核心的處理器之外,BlueBox還搭載了其他為實現不同傳感器節點功能的芯片,它們能夠處理從V2X、雷達、視覺系統、激光雷達以及車輛狀態獲取的信息。
3)概率芯片
“S1”概率芯片示意圖
2016年4月,MIT TechnologyReview報道,DARPA投資了一款由美國Singular Computing公司開發的“S1”概率芯片。其優點包括:算法邏輯異常簡單,不需要復雜的數據結構,不需要數值代數計算;計算精度可以模擬不同數目的隨機行走自如控制;不同的隨機行走相互獨立,可以大規模并行模擬;模擬過程中,不需要全局信息,只需要網絡局部信息即可。模擬測試中,使用S1追蹤視頻里的移動物體,每幀處理速度比傳統處理器快了近100倍,而能耗還不到傳統處理器的2%。專用概率芯片可以發揮概率算法簡單并行的特點,極大提高系統性能。
早在2018年MIT Technology Review“十大科技突破技術”預測中,概率芯片就榜上有名。通過犧牲微小的計算精度換取能耗的顯著降低,概率芯片在歷來追求精準的芯片領域獨樹一幟,但正因為如此,概率芯片很可能后來居上。
4)中國芯片解決方案
寒武紀的芯片
寒武紀1M處理器
“寒武紀”是中國科學院計算技術研究所發布的全球首個能夠“深度學習”的“神經網絡”處理器芯片。2012年中科院計算所和法國Inria等機構共同提出了國際上首個人工神經網絡硬件的基準測試集benchNN。此后,中科院計算所和法國Inria的研究人員共同推出了一系列不同結構的DianNao神經網絡硬件加速器結構。當前寒武紀系列包含四種處理器機構:DianNao(面向多種功能人工神經網絡的原型處理器結構)、DaDianao(面向大規模人工神經網絡)和PuDianNao(面向多種機器學習算法),面向卷積神經網絡的ShiDianNao。寒武紀進入產業化運營,其主要方向是高性能服務器芯片、高性能終端芯片和服務機器人芯片。
寒武紀1M處理器IP主打的是智能駕駛領域,后將應用領域拓寬到了智能手機、智能音箱、攝像頭、自動駕駛等方面。寒武紀官方數據,1M的int 8(8位運算)效能比高達達5Tops/watt(每瓦5萬億次運算),并且提供了2Tops、4Tops、8Tops三種尺寸的處理器內核,以滿足不同需求。1M還將支持CNN、RNN、SVM、k-NN等多種深度學習模型與機器學習算法的加速,能夠完成視覺、語音、自然語言處理等任務。
中星微的芯片——星光智能一號
“星光智能一號”芯片和主板
2016年6月,中星微率先推出了中國首款嵌入式神經網絡處理器(NPU)芯片“星光智能一號”,這也是全球首枚具備深度學習人工智能的嵌入式視頻采集壓縮編碼系統級芯片,并已實現量產。該芯片采用“數據驅動”并行計算的架構,單顆NPU(28nm)能耗僅為400mW,極大地提升了計算能力與功耗的比例,可以廣泛應用于智能駕駛輔助、無人機機器人等嵌入式機器視覺領域。
地平線的芯片——征程和旭日
2017年 12月,地平線發布了兩款款嵌入式人工智能芯片——面向智能駕駛的征程(Journey)1.0處理器和面向智能攝像頭的旭日(Sunrise)1.0處理器。這兩款芯片屬于ASIC人工智能專用芯片。
地平線征程1.0處理器
征程1.0:面向智能駕駛,能夠同時對行人、機動車、非機動車、車道線、交通標志牌、紅綠燈等多類目標進行精準的實時監測與識別,同時滿足車載嚴苛的環境要求以及不同環境下的視覺感知需求。征程1.0屬于工業級的處理器,不是車規級的。因此地平線一開始會去做ADAS的后裝市場,不過他們有計劃,把他們的處理器推向車規級。
地平線旭日1.0處理器
旭日1.0:面向智能攝像頭,能夠在本地進行大規模人臉抓拍與識別、視頻結構化處理等,可廣泛用于商業、安防等多個實際應用場景。
目前新一代自動駕駛處理器征程2.0正在研發中,而未來在軟硬件的進一步協同優化后,是面向L3/L4的自動駕駛解決方案,可滿足自動駕駛場景下高性能和低功耗的需求。
-
芯片
+關注
關注
456文章
50886瀏覽量
424181 -
無人駕駛
+關注
關注
98文章
4067瀏覽量
120568 -
自動駕駛
+關注
關注
784文章
13838瀏覽量
166529
原文標題:盤點自動駕駛硬件計算平臺解決方案
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論