") 斯坦福提出基于目標的策略強化學(xué)習(xí)方法——SOORL
斯坦福提出基于目標的策略強化學(xué)習(xí)方法——SOORL
人類的學(xué)習(xí)能力一直是人工智能追求的目標,但就目前而言,算法的學(xué)習(xí)速度還遠遠不如人類。為了達到人類學(xué)習(xí)的速率,斯坦福的研究人員們提出了一種基于目標的策略強化學(xué)習(xí)方法——SOORL,把重點放在對策略的探索和模型選擇上。以下是論智帶來的編譯。

假設(shè)讓一個十二歲的孩子玩一下午雅達利游戲,就算他之前從沒玩過,晚飯前也足以掌握游戲規(guī)則。Pitfall!是是雅達利2600上銷量最高的游戲之一,它的難度很高,玩家控制著一個名為“哈里”的角色,他要在20分鐘內(nèi)穿過叢林,找到32個寶藏。一路上共有255個場景(rooms),其中會碰到許多危險,例如陷阱、流沙、滾動的枕木、火焰、蛇以及蝎子等。最近的獎勵也要在起始點7個場景之外,所以獎勵分布非常稀疏,即使對人類來說,沒有經(jīng)驗也很難操控。
深度神經(jīng)網(wǎng)絡(luò)和強化學(xué)習(xí)這對cp在模仿人類打游戲方面可謂是取得了不小的進步。但是這些智能體往往需要數(shù)百萬個步驟進行訓(xùn)練,但是人類在學(xué)習(xí)新事物時效率可要高多了。我們是如何快速學(xué)習(xí)高效的獎勵的,又是怎樣讓智能體做到同樣水平的?
有人認為,人們學(xué)習(xí)并利用能解釋世界如何運行的結(jié)構(gòu)化模型,以及能用目標而不是像素表示世界的模型,從而智能體也能靠同樣的方法從中獲得經(jīng)驗。
具體來說,我們假設(shè)同時具備三個要素即可:運用抽象的目標水平的表示、學(xué)習(xí)能快速學(xué)習(xí)世界動態(tài)并支持快速計劃的模型、利用前瞻計劃進行基于模型的策略探索。
在這一思想的啟發(fā)下,我們提出了策略目標強化學(xué)習(xí)(SOORL)算法,據(jù)我們所知,這是第一個能在雅達利游戲Pitfall!中能到積極獎勵的算法。重要的是,該算法在這一過程中不需要人類的示范,可以闖過50關(guān)。SOORL算法利用強大的先驗知識而非傳統(tǒng)的深度強化學(xué)習(xí)算法,對環(huán)境中的目標和潛在的動態(tài)模型有了了解。但是相比于需要人類示范的方法來說,SOORL算法所掌握的信息就少了很多。
SOORL在兩方面超過了之前以目標為導(dǎo)向的強化學(xué)習(xí)方法:
智能體在積極嘗試選擇一種簡單模式,該模式解釋了世界是如何運作的從而看起來是決定性的。
智能體用一種基于模型的積極計劃方法,在做決定時假設(shè)智能體不會計算出一個完美的計劃來應(yīng)對即使知道世界怎樣運作后會有何反應(yīng)。
這兩種方法都是從人類遇到的困難中受到的啟發(fā)——先前經(jīng)驗很少,同時算力有限,人類必須快速學(xué)習(xí)做出正確的決定。為了達到這一目標,我們第一條方法發(fā)現(xiàn),與復(fù)雜的、需要大量數(shù)據(jù)的深度神經(jīng)網(wǎng)絡(luò)模型不同,如果玩家按下的某一按鍵需要很少經(jīng)驗來估計,那么簡單的決定性模型可以減少計劃所需的計算力,盡管會經(jīng)常出錯,但對達到良好的效果已經(jīng)足夠了。第二,在獎勵分散、復(fù)雜的電子游戲中,玩一場游戲可能需要成百上千個步驟,對于任何一個計算力有限的智能體來說,想在每個步驟都作出合適的計劃是非常困難的,就算是12歲的小孩也是如此。我們用一種常用并且強大的方法做前瞻計劃,即蒙特卡洛樹搜索,將其與目標導(dǎo)向的方法結(jié)合,用作最優(yōu)策略的探索,同時指導(dǎo)智能體學(xué)習(xí)它不了解的世界的環(huán)境。
Pitfall!也許是智能體最后一個尚未攻破的雅達利游戲。如文章開頭所說,Pitfall!中的第一個積極獎勵出現(xiàn)多個場景之后,玩家需要非常小心地操作才能得到,這就需要智能體在闖關(guān)時具備策劃能力和對未來的預(yù)見能力。
我們的SOORL智能體在50回中的平均可以解鎖17個場景,而之前的用像素作為輸入、同時又沒有策略探索的DDQN標準在2000回之后的平均只能解鎖6個場景。
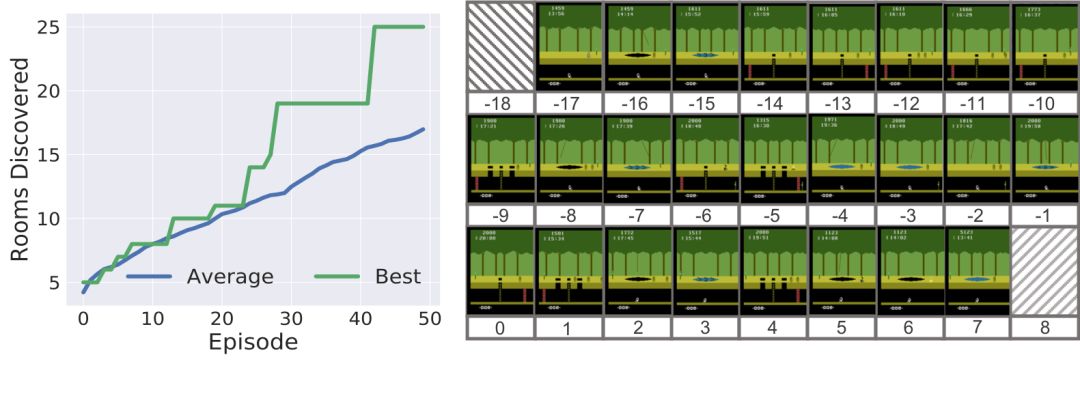
SOORL最多解鎖了25個場景
下面的直方圖顯示出在不同的隨機種子下,SOORL算法在訓(xùn)練時的100次游戲中最佳的表現(xiàn)分布。
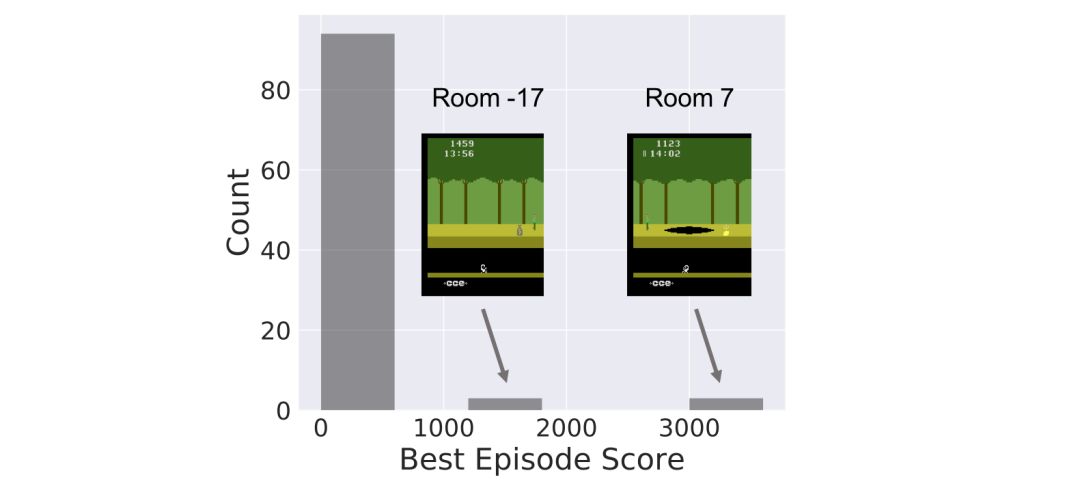
可以看到,SOORL在大多數(shù)情況下并不比之前所有深度強化學(xué)習(xí)的方法好,之前的方法得到最佳的獎勵為0(雖然這種方法都是在500甚至5000次游戲之后才得到的,而我們的方法只要50次就可以得到最佳獎勵)。在這種情況下,SOORL經(jīng)常可以比其他方法解鎖更多房間,但是并沒有達到更高的最佳成績。但是,在幾次游戲中,SOORL得到了2000分甚至4000分的獎勵,這是沒有人類示范的情況下獲得的最好分數(shù)。在有人示范的情況下目前最好的分數(shù)是60000分,盡管分數(shù)很高,但是這種方法仍需要大量的先驗知識,并且還需要一個可靠的模型減少探索過程中遇到的挑戰(zhàn)。
下面是SOORL智能體掌握的幾種有趣的小技巧:
飛渡深坑
鱷魚口脫險
躲避沙坑
SOORL仍然還有很多限制。也許其中最重要的缺點就是它需要一種合理的潛在動態(tài)模型進行具體化,使得SOORL可以在這個子集上進行模型選擇。另外在蒙特卡洛樹搜索期間,它沒有學(xué)習(xí)并利用價值函數(shù),這在早期的AlphaGo版本上是很重要的一部分。我們希望加入一個價值函數(shù)能大大改善其性能。
但是除了這些弱點,這些結(jié)果還是非常令人激動的。因為這個基于模型的強化學(xué)習(xí)智能體能在類似Pitfall!這樣獎勵非常稀疏的電子游戲中快速地學(xué)習(xí),通過各種策略學(xué)習(xí)如何在簡單模式下做出正確決策。
-
斯坦福
+關(guān)注
關(guān)注
0文章
28瀏覽量
9229 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
266瀏覽量
11246
原文標題:斯坦福提出無需人類示范的強化學(xué)習(xí)算法SOORL
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
斯坦福開發(fā)過熱自動斷電電池
關(guān)于斯坦福的CNTFET的問題
深度強化學(xué)習(xí)實戰(zhàn)
回收新舊 斯坦福SRS DG645 延遲發(fā)生器
DG645 斯坦福 SRS DG645 延遲發(fā)生器 現(xiàn)金回收
深度學(xué)習(xí)技術(shù)的開發(fā)與應(yīng)用
基于LCS和LS-SVM的多機器人強化學(xué)習(xí)
解析圖像分類器結(jié)構(gòu)搜索的正則化異步進化方法 并和強化學(xué)習(xí)方法進行對比






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論