 AI計算的幾條路線,微軟為什么選擇FPGA?
AI計算的幾條路線,微軟為什么選擇FPGA?
AI計算的幾條路線
1993年,當黃仁勛等三個電子工程師在加州圣何塞的一家餐館碰頭準備成立一家圖形處理芯片公司時,他們還不知道20年后,他們做的這個芯片還能用來做人工智能、自動駕駛。
1985年,Xilinx創始人之一Ross Freeman發明FPGA芯片的時候,他也不會想到近30年后,FPGA芯片會被廣泛應用于人工智能領域的計算。黃仁勛還能親自帶領NVIDIA參加人工智能芯片大戰,而Ross Freeman在1989年年僅41歲就因肺炎不幸早逝。
目前人工智能的產業重心,已經從早期的深度學習算法和框架,轉到了AI硬件平臺。Google開發出專用的AI芯片——TPU,如下圖。
可是,另一個巨頭微軟卻全面擁抱FPGA作為AI計算平臺。同時,亞馬遜和百度也是FPGA路線。百度在一個電路板上集成了CPU、GPU和FPGA,稱為“XPU”。亞馬遜的云服務提供F1加速平臺,提供FPGA計算加速。
微軟為什么選擇FPGA
下圖是微軟的FPGA擴展卡,叫做DPU,“Soft DNN Processing Unit”。
微軟FPGA戰略是成體系的,包括三個主要部分:
1. FPGA擴展卡能夠互聯、擴展,同時融入到數據中心服務中去,提供高帶寬、低延遲的加速服務;
2. FPGA是可編程的,方便用戶開發自己的程序;
3. 微軟為自己的神經網絡模型CNTK提供了編譯器和開發環境。
為什么微軟選擇了FPGA?因為微軟和Google是兩種不同的基因,Google喜歡嘗試新技術,所以自然要用TPU去追求最高的性能。但是,微軟是一家商業文化很重的公司,選擇一個方案看的是性價比和商業價值。做專用芯片盡管很炫,但是是否真的值得?
做芯片主要的缺點是投資大、時間周期長,芯片做好后里面的邏輯就不能修改。人工智能的算法一直在快速迭代,而做芯片至少要一兩年的時間,意味著只能支持舊的架構和算法。如果芯片想要支持新的算法,就要做成通用型,提供指令集給用戶編程,通用性又會降低性能,增加功耗,因為有些功能是浪費的。所以不少芯片公司盡管做了芯片,但是很多產品還是FPGA做的,比如比特大陸的挖礦機,芯片做出來就已經無法支持新的挖礦算法了。
阿呆8年前在微軟亞洲研究院參與用FPGA+Open Channel SSD加速Bing搜索引擎的研究,那個時候FPGA做機器學習性能已經可以甩CPU幾條大街了,同時還能節省購買服務器的成本,降低散熱、土地等成本。所以微軟選擇FPGA是基于商業考慮和長期積累和探索的經驗。
CPU、GPU、ASIC和FPGA橫向對比
我們現在常見的硬件計算平臺包括CPU、GPU、ASIC和FPGA。CPU是最通用的,有成熟的指令集,例如X86、ARM、MIPS、Power等,用戶只要基于指令集開發軟件就能使用CPU完成各種任務。但是,CPU的通用性決定了計算性能是最差的,在現代計算機中,很多計算都需要高度的并行和流水線架構,但是,CPU盡管流水線很長,計算核心數最多只有幾十個,并行度不夠。比如看一個高清視頻,那么多像素要并行渲染,CPU就拖后腿了。
GPU克服了CPU并行度不夠的缺點,把幾百上千個并行計算核心堆到一個芯片里,用戶用GPU的編程語言,比如CUDA、OpenCL等就可以開發程序用GPU來加速應用。但是,GPU也有嚴重的缺點,就是最小單元是計算核心,還是太大了。在計算機體系結構中,有一個很重要的概念就是粒度,粒度越細,就意味著用戶可以發揮的空間越多。就跟蓋樓一樣,如果用小小的磚頭,可以做出很多漂亮的造型,但是建設時間久,如果用混凝土預制件,很快就蓋好大樓了,可是樓的樣式就受到限制。如下圖,就是預制件蓋樓,搭積木一樣,很快,可是都長得差不多,想蓋的別的樓就不行。
ASIC克服了GPU粒度太粗的缺點,能讓用戶從晶體管級開始自定義邏輯,最后交給芯片代工廠生產出專用芯片。不管是性能還是功耗,都比GPU好很多,畢竟從最底層開始設計,沒有浪費的電路,而且追求最高的性能。但是ASIC也有很大的缺點:投資大、開發周期長、芯片邏輯不能修改。現在做一款大規模芯片,至少需要幾千萬到幾億的投資,時間周期一兩年左右,尤其是AI芯片,沒有通用IP,很多要自己開發,時間周期更久。芯片做好后,如果有大問題或者功能升級(有些小問題可以通過預留的邏輯修改金屬層連線解決),還不能直接修改,而要重新修改版圖,交付工廠流片。
所以,最后就回到了FPGA:兼顧ASIC計算粒度細和GPU可編程的優點。FPGA的計算粒度很細,可以到與非門級別,但是邏輯還能修改,是可編程的。
FPGA入門
我們上大學學計算機,首先學習的基礎知識是布爾代數,從與非門等邏輯門出發,可以搭出加法器、乘法器等數字邏輯,最后一級級組合,實現很復雜的計算功能(阿呆這里八卦一下,深度學習的泰斗Hinton教授是布爾的孫子的兒子)。在ASIC里面,與非門通過晶體管實現,但是晶體管無法做到可編程,必須要做成版圖,送到芯片代工廠生產才能用。那怎樣做到數字邏輯也能可編程呢?我們都知道,數字邏輯可以用真值表來表示,如下圖就是與非門的真值表。
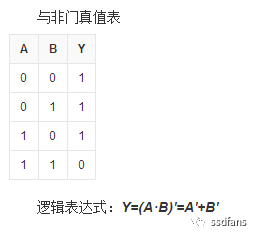
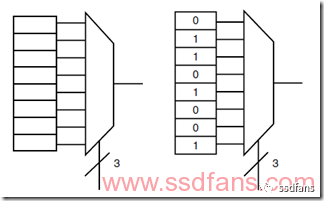
FPGA的發明人想了一個辦法,就是用一個查找表來存儲真值表的輸出結果。如下圖就是一個3bit的異或門查找表,3bit一共是8個狀態,查找表保存了每個狀態的結果,輸入的3個bit作為索引,直接從表里讀到計算結果,通過一個選擇開關輸出。這樣避免了搭建計算邏輯,同時簡化了芯片結構,只需要在芯片里面放許許多多的查找表,大家一起級聯和組合就能實現復雜的邏輯和計算。目前主流的FPGA采用SRAM工藝,就是把查找表的狀態都保存在SRAM里面,
但是,僅僅有查找表是不夠的,數字集成電路的根是時鐘,所有的邏輯按照時鐘節拍來同步。舉個例子,幾個流氓打群架,是沒有章法的,但是幾萬人的大軍作戰,如果還是各打各的,就發揮不了群體的優勢。比如士兵與士兵之間如何配合?連與連之間如何分工合作?大軍作戰需要講究陣法,中國古代的戰神們就熟讀兵書,會用八卦陣、長蛇陣等陣法,按照統一的號令指揮大軍作戰,無往不利。比如,法正和黃忠搭配,在定軍山對山擺好陣勢,法正站在山頂舉令旗指揮,在他的號令下,最終老將黃忠把悍將夏侯淵劈作兩半,就是靠陣法以弱勝強的例子。FPGA里面有幾十萬甚至百萬個查找表,需要統一的號令來行動,這就是時鐘。
下圖是FPGA內部的基本單元,查找表+D觸發器+選擇開關。D觸發器用來存儲,查找表是組合邏輯。每個時鐘周期會輸出一個值,通過選擇開關來選擇用查找表還是D觸發器。
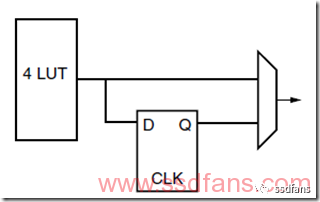
如果你看明白了上面FPGA的基本單元,你就理解了數字電路的基礎——RTL,Register Transfer Level,寄存器傳輸級。數字電路包含兩個基本部分:組合邏輯和時序邏輯,組合邏輯就是我們前面講的布爾代數,可以做邏輯運算,但是沒有記憶功能,上圖中的查找表就是起了組合邏輯的作用。時序邏輯是帶有記憶功能,可以按照時鐘節拍控制輸入輸出,上圖中的D觸發器起了記憶功能,我們叫做寄存器。這樣,組合邏輯和時序邏輯結合起來,我們就可以從這個層面設計大規模數字電路,叫做RTL設計,就是說從組合邏輯和時序邏輯級別來設計復雜的計算系統。
FPGA如何實現可編程?
那么問題來了,FPGA怎么實現可編程?如果要控制上面的基本單元,需要存好查找表的幾個狀態值,比如4輸入查找表,就要存16bit,同時要存1個組合邏輯的選擇bit和1個D觸發器初始值bit。FPGA把這些配置數據保存在SRAM里面,并配置到每個基本單元中,通過寫自定義數據到SRAM,就實現了對整個FPGA邏輯的可編程。
有了上面的基本邏輯單元還不夠,多個基本邏輯怎么級聯?級聯的連接部分怎么可編程?
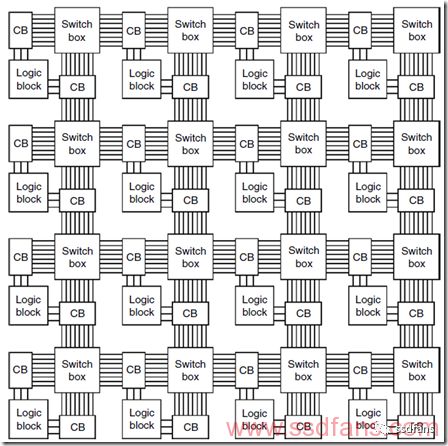
下圖是FPGA內邏輯塊之間互聯的結構圖。邏輯塊的輸入輸出通過連接塊Connection Block CB和交換塊結合級聯到其他的邏輯塊,連接塊決定邏輯塊的信號連到哪根連接線上,交換塊決定哪些連接線是通的,把邏輯塊需要的信號連到相鄰的邏輯塊。連接塊和交換塊都是可以基于SRAM方法編程的,連接塊里面是一些選擇開關,交換塊里面是一些交換器。
看得出來,連接線遠比邏輯塊更復雜,在現代FPGA芯片中,連線一般占了90%的面積,真正的邏輯部分只有10%左右面積。
FPGA的擴展資源
FPGA里面只是上面的組合邏輯是不夠的,因為用戶有時候不想自己搭邏輯,有些常用的邏輯希望直接用現成的。所以現代FPGA自帶了很多常用的計算單元,比如加法器、乘法器、片上RAM,甚至嵌入式CPU,它們不是通過查找表搭的,而是跟ASIC一樣,用晶體管搭成,這樣更省芯片面積,同時性能更好。這些計算單元可以讓用戶配置和組合。
比如,深度學習中會使用大量的乘法器,這個時候,FPGA內部提供很多乘法器就發揮了很大的作用,這些乘法器和用戶邏輯結合,可以實現很多人工智能計算,并達到高性能。
-
FPGA
+關注
關注
1629文章
21748瀏覽量
603984 -
微軟
+關注
關注
4文章
6600瀏覽量
104135 -
人工智能
+關注
關注
1792文章
47354瀏覽量
238819
原文標題:阿呆讀可重構計算1:為什么微軟選擇FPGA做AI?
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI讓FPGA獲得新生:CPU+GPU都搞不定的機器學習問題,微軟和百度用FPGA解決了
中高端FPGA如何選擇
FPGA的學習方向路線?
微軟HoloLens正研發AI芯片 可識別語音和圖像
【案例分享】FPGA+AI,領你走進新科技時代
EdgeBoard FZ5 邊緣AI計算盒及計算卡
FPGA將成為英特爾進入微軟AI市場遲到的船票
微軟推出Brainwave項目以提供更快的FPGA芯片
FPGA的計算性能還能否滿足現代社會的需求
NVIDIA 攜手微軟打造大規模云端 AI 計算機
「重大突破」微軟量子超級計算機路線圖公布!






 工商網監
工商網監
評論