 深度學習時代的新主宰:可微編程
深度學習時代的新主宰:可微編程
深度學習自誕生之日起,即面臨著黑盒智能、可解釋性差等質疑,發展至今,不可否認地帶來了一波人工智能的發展熱潮,然而正面臨研究熱情漸褪、算法紅利逐漸消失等問題,整個學術界都在討論,后深度學習時代,誰將是主宰。
恰在此時,LeCun語出驚人地表示,“Deep Learning has outlived its usefulness as a buzz-phrase. Deep Learning est mort. Vive Differentiable Programming!” 一方面將對深度學習的質疑推向了高潮,另一方面奠定了可微編程的地位。
可微編程,作為銜接傳統算法與深度學習之間的橋梁為深度算法提供可解釋性,將成為打開深度學習黑盒子的一大利器。
本文中,來自四川大學的彭璽研究員,將為大家介紹后深度學習時代的新主宰:可微編程。
文末,大講堂提供文中提到參考文獻的下載鏈接。


今天的匯報將從上面四個部分展開。
第一部分,介紹一下可微編程的一些相關的概念。
第二部分,介紹我們的第一個工作。現在大多可微編程是把優化過程展開,轉換成回復式神經網絡。而我們這項工作也是把優化過程展開,發現能夠得到新的長短期記憶,再從可微編程角度,找到與長短期記憶網絡的連接。
第三部分,介紹我們的第二個工作。現有的絕大多數可微編程的工作都是基于優化的過程展開,然后尋找它和神經網絡之間的關系。而我們這項工作是從目標函數進行變形得到一個前向式神經網絡。
第四部分,是我們對于這些研究問題的一些思考。


首先介紹一下可微編程是什么呢?簡單來說,就是把神經網絡當成一種語言,而不是一個簡單的機器學習的方法,從而描述我們客觀世界的概念以及概念之間的關系。這種觀點無限地提高了神經網絡的地位。

LeCun曾在facebook的文章里說:”Deep Learning Is Dead. Long Live Differentiable Programming!” (深度學習已死,可微編程永生)。
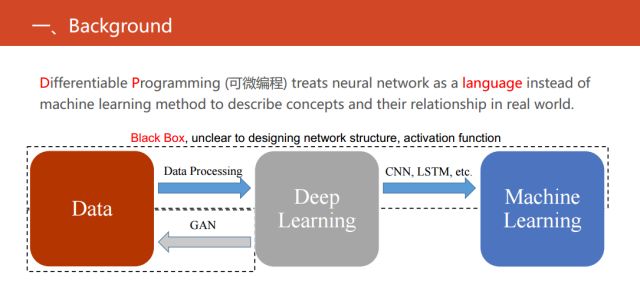
具體的可微編程和現有的深度學習、機器學習又有什么關系呢?這里有一個簡單的對比,在上圖中顯示的三個實體之間發生的三項關系。目前最流行的方法是用深度學習提取特征,然后結合機器學習的一些方法來解決實際當中的一些問題,也可以反過來用深度神經網絡拿來直接生成數據,也就是目前最火的生成式對抗網絡。

但我們可以發現缺失了一塊,也是目前可微編程做的主流工作。缺失的就是把現有的機器學習的方法轉化成等價的神經網絡,使得同時具有傳統的統計機器學習方法的可解釋性強以及深度神經網絡性能較優等優點。
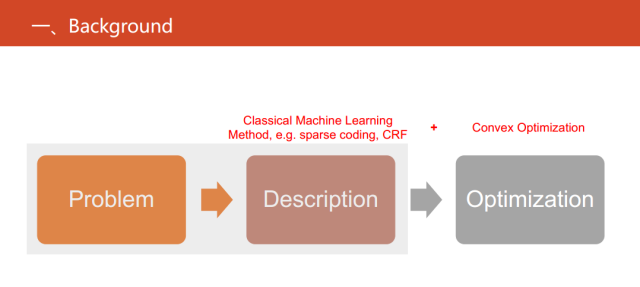
針對現實世界中的一些問題,傳統的機器學習的方法思路是首先基于一些假設或者先驗知識(比如稀疏編碼等),將其形式化成目標函數,再對其進行優化求解。但當得到一個新的目標函數時,我們還需要研究目標函數數學上的性質對其進行優化,如目前最流行的優化方法--凸優劃。
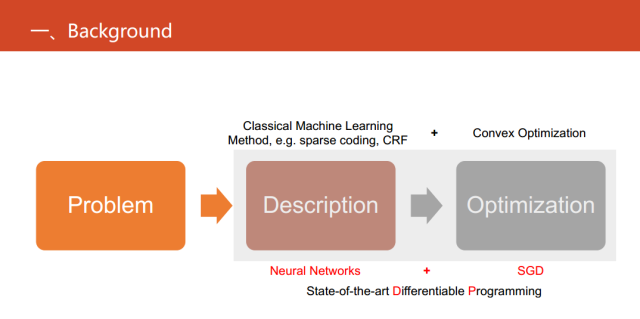
但是這樣做飽受詬病的一個原因就是可解釋不強。那可微編程可以做什么?其實就把神經網絡直接當成一種語言,直接用于替代問題的描述或者說抽象化問題。這樣做的好處顯而易見,首先,它易于優化。只需要一個SGD或者SGD的變種,而不需要發展出非常復雜的優化的算法。此外,它還易于計算。并且,它也能做端到端的學習。


在神經網絡以深度學習為標志復出之后,最早的可微編程的工作應該是Yann LeCun的ISTA。求解稀疏編碼這個目標函數的優化方法有非常多,ISTA是其中非常有名的一個。上圖中間紅框標注的公式就是ISTA的核心,具體細節可以閱讀文章《Learning fast approximations of sparse coding》。

觀察上圖中紅色方框的公式,可以看到Z是依賴于前一步的Z值。這在數學上就等價于一個動力學系統或者一個迭代過程,而動力學系統本質上就是回復式神經網絡的數學本質。因此,進一步地把右下角公式簡單地變形等價成RNN,這是神經網絡復出以來最為知名的一個可微編程的工作。

隨后有很多的進展,比如2016年NIPS上的文章《Attend, Infer, Repeat: Fast Scene Understanding with Generative Models》關于生成模型的工作,這項工作也是目前比較熱門的研究。

另外,在2015的ICCV上《Conditional Random Fields as Recurrent Neural Networks》文章中提出,把條件隨機場的求解變形成了循環神經網絡的相關運算,在圖像語義分割上實現了突破。

在2016的TPAMI上《Learning to Diffuse: A New Perspective of Designing PDEs for Visual Analysis》文章中,提出的PDE工作在多個任務視覺上取得很好的效果。
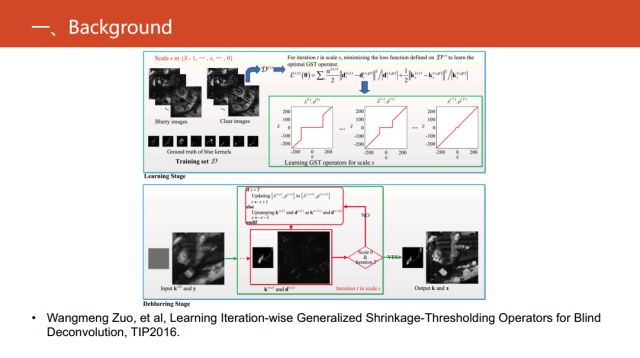
在2016的TIP《Learning Iteration-wise Generalized Shrinkage-Thresholding Operators for Blind Deconvolution》里,針對盲卷積這個問題,發展出能夠實現稀疏編碼的回復神經網絡。
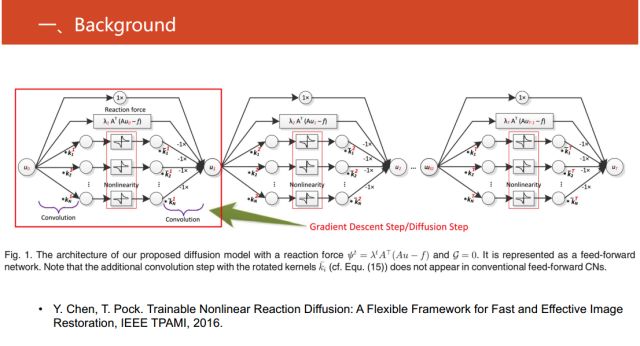
在2016的IEEE TPAMI的《Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration》文章中,對圖像重構工作進行了這方面研究。
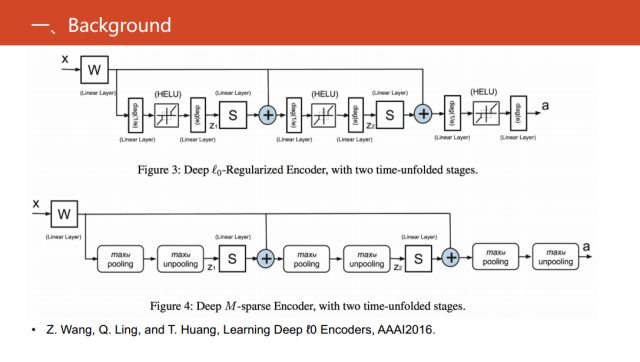
在2016年的AAAI文章《Learning Deep ?0 Encoders》中對0范數的優化問題,進行變形和等價建議的回復式神經網絡。
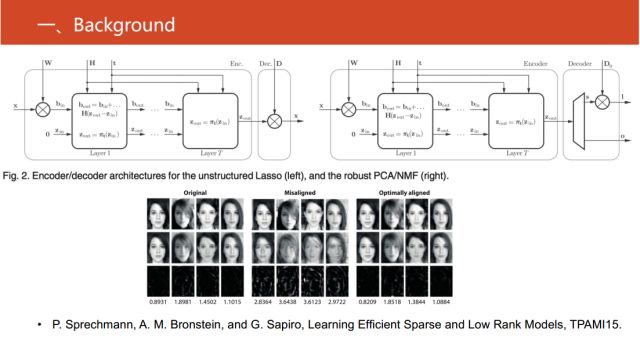
在2015年TPAMI文章《Learning Efficient Sparse and Low Rank Models》中,對使用深度神經網絡來實現稀疏模型和非負矩陣分解之間建模的回復式神經網絡。

將這些研究進行歸納總結,就是把一些現有的統計機器學習方法,特別是現有的優化過程展開,形成一個簡單的神經網絡,且其中大多都是一個簡單的回復式神經網絡。從而使它能享有傳統機器學習的優點,比如端到端學習,同時兼具易于優化以及高可解釋性等優點。
我相信這樣介紹大家可以有一個直觀的概念。目前可微編程就是對傳統的機器學習的一個逆向的過程,由于傳統的機器學習的結構非常清晰,對逆向過程可以產生的神經網絡,就可以知道哪一個激活函數的作用是什么,每一層的輸出、目的是什么,這也是現有的深度學習方法所不具備的優勢。

下面給大家介紹一下我們的第一個工作。我們這項工作從可微編程出發,來研究稀疏編碼的優化方法—ISTA 。

目前,常見的對L1范數優化的方法具有四個局限性:
第一,在優化過程中,對于每一個變量的更新都是采用固定的學習率。所以沒有考慮優化變量的每個維度之間的不同。
第二, 這些優化過程并沒有考慮歷史信息。但是在優化這個研究鄰域里已經有大量的工作證明如果考慮歷史信息,能夠加速算法的收斂。
基于這兩點不足,我們提出了自適應的ISTA算法。

還有兩個不足是什么呢?
第三,在稀疏編碼推理過程中,計算代價很高。
第四,稀疏表示矩陣計算和字典學習是兩個分隔開的步驟。但現在流行端到端的訓練,也就是同時優化步驟,這樣做可能會產生次優的解。
而這兩個不足,正好是可微編程能夠克服的問題。因此基于這些問題,我們對自適應的ISTA變形和展開提出新的神經網絡——SC2Net。


左邊是ISTA的關鍵的優化步驟,基于此,我們引進了動量向量(i(t),f(t))。這就是標準的受益于現代的優化的一些相關的方法,通過引入這兩個量,從而解決非自適應更新問題和沒有考慮歷史信息的不足。更進一步來看,這里存在一個問題,i(t),f(t)如果是兩個向量的話,只能確定它的值。使用傳統的機器學習方法進行訓練,我們人為指定它的值。在研究中,發現可以把這兩個向量當成兩個變量從數據中學習,就產生了我們提出的自適應ISTA。

同時,我們還發現這種自適應ISTA可以等價于新的長短期記憶神經網絡。具體來看,我們可以認為i和f是等價于LSTM中的input gate 和output gate。但是需要注意的是,和經典的LSTM相比,自適應的ISTA是沒有output gate。

基于以上,我們就組建了Sparse LSTM,并且構建了相應的神經網絡結構。
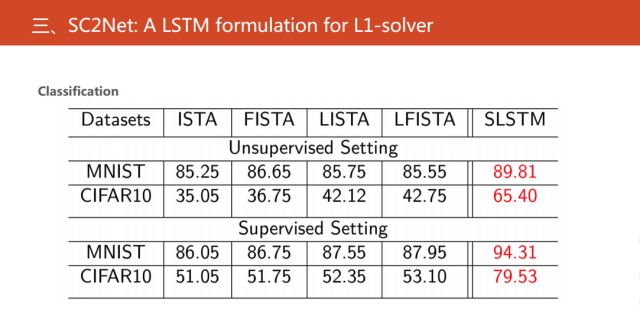
接下來,展示我們的實驗結果。在無監督和有監督的特征提取的情況下,對網絡的分類性能進行驗證。

接下來還進行圖像重構,圖中顯示的是一個重構的誤差,越黑就代表誤差越小。
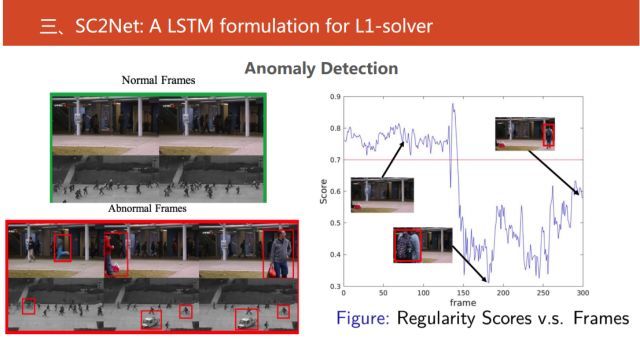
我們還做了視頻當中的異常事件的檢測,給定一個圈,在圈中的都是正常事件,不在圈中的就是異常事件。接下來使用稀疏重構系數作為指標,找到一定閾值,在這個范圍內的都是正常事件,而不在其中的就是異常事件。
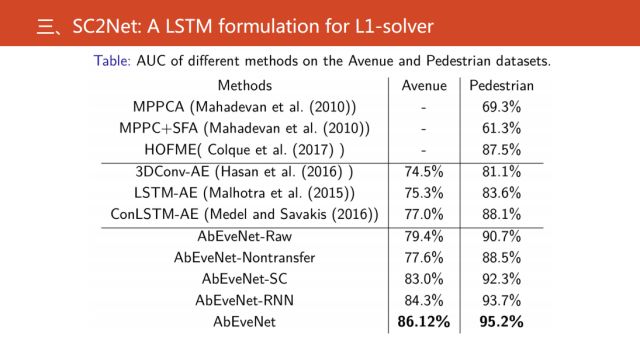
通過實驗可以看到,我們的結果是目前是最好的異常事件檢測算法。

最后簡單地概括一下,相對現有的可微編程,我們是將優化的過程或者說具體的基于LSTM優化的過程和長短期記憶網絡,最后掌握了他們之間關系。這對可微編程有一些促進的作用,也可以從另外一個角度理解長短期記憶網絡。
剛才我們得到的網絡和標準的只有一個區別,就是我們沒有Output gate。
相關的代碼公開,大家可以掃描上圖中的二維碼。

第二個工作較之前更進一步,是在聚類這個背景下來擴展,把k-means這個聚類算法轉化成為一個前向式記憶網絡。不同于現有的可微編程的方法,它是從優化的角度出發,我們直接把k-means聚類算法的目標函數直接進行變形,然后建立對應的神經網絡模型。

K-means是什么?
它是在機器學習,計算機視覺,數據挖掘中最為知名的一個算法。主要是利用數據之間的相似性或者不相似性,將數據分為多個簇。最近一二十年,整個聚類的研究領域主要關注的是高維數據的聚類,本質上就是機器學習的共性問題-——線性不可分的問題。

為了解決這個問題,基于核聚類算法,譜聚類,子空間聚類方法,以及近期基于深度神經網絡的聚類方法,這些方法都是在解決這個線性不可分的問題。
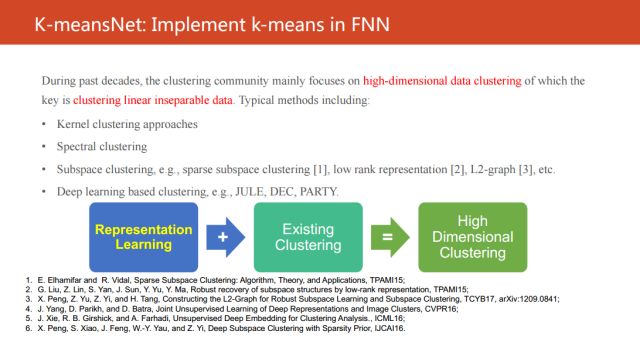
現有的高維聚類方法可以簡單地概括成這個圖。它們都是用表示學習的方法將不可分的數據投影到另外一個線性可分的空間中,然后再進行聚類。而且現有的研究工作主要都是關注在如何學到一個好的表示。大家都知道,目前深度學習已經成為最為有效的表示學習方法之一,一定意義上可以把“之一”去掉,特別是在數據量較多的情況下。

因此,我們就認為如果表示學習能夠用深度神經網絡來解決,我們是不是要考慮更多的研究能夠實現聚類的神經網絡。但是讓我們驚訝的是,目前非常少的工作研究能以一個神經網絡來實現聚類的,寥寥可數,比較知名一點的比如說自組織映射。

受這個觀察的啟發,我們思考計劃從可微編程的角度對經典的算法進行變形,從而形成一個新的神經網絡,從而解決上述的痛點。
這里的公式是k-means的目標函數,其中x是輸入,Ω是第j個聚類的中心。我們最終的目標是最小化不同類別之間的相似性,最大化相同類別之間的相似性。

通過對k-means目標函數簡單的變形,其實本質上只是把標簽只能分配到某一個聚類空間的約束去掉,轉變成了輸入Xi在第j個聚類中心的概率。

如右圖所示的簡單變形得到公式(6)和(7),并且我們發現這兩個公式是可以等價為一個簡潔的前向式神經網絡。

如果大家只看左邊的神經網絡,大家可能會覺得非常不稀奇,好像就是一個很簡單的Sigmoid函數,再加上一個隱含層的神經網絡。但是如果結合右邊的公式來看,就會發現,這么簡單的神經網絡是等價于K-means的。

我們在相關的一些數據集上進行驗證,比如說我們使用數據mnist和CIFAR10驗證神經網絡,取得了非常好的效果。


接著我們使用CIFAR100數據的20個子集進行驗證,也是取得很不錯的結果。
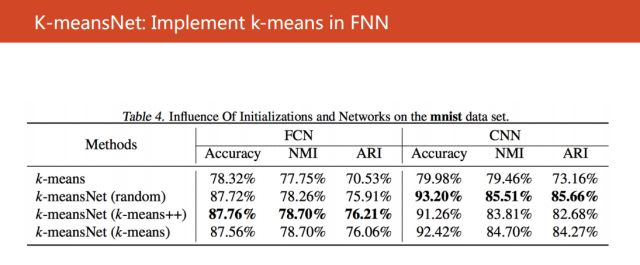
同時我們還考慮使用CNN來發現特征,可以得到超過93%的距離精確度。所以得出一個結論,我們的算法對于距離中心的初始化方法是非常棒的。

這個工作和現有的可微編程不同主要是兩點:
第一,我們的研究思路是從目標出發,而不是從優化過程出發進行研究
第二,我們得到的是前向式神經網絡,而不是回復式的神經網絡。

接下來給大家分享一下我和我的合作伙伴的一些思考。
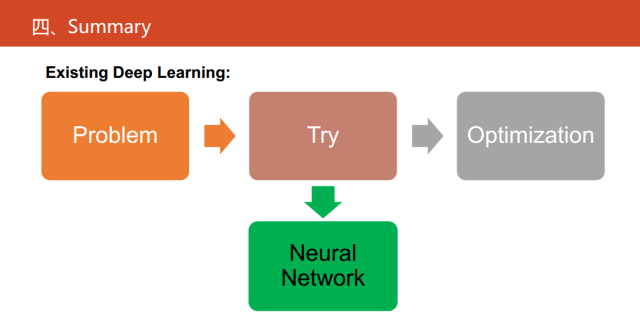
目前,深度學習的研究主要是對通過對一些算法的性能指標不斷地試錯,最后確定整個網絡的結構以及相關的超參,這也是深度學習最為詬病的一點。

現在深度神經網絡已經占據了絕對的優勢,可微編程提供了從高解釋性的角度去做這件事,它是將神經網絡作為一種語言,將傳統的算法轉化成神經網絡以后,一定程度上緩解了一些深度學習的不足。
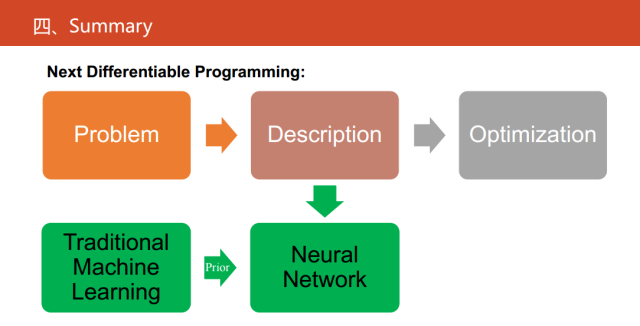
下一步可微編程做什么?現在的可微編程是對傳統的繼續學習方法的等價或者一種替代物。從問題的描述,再到問題的建模、求解,這是一個很復雜的過程。如果我們對傳統的學習的方法,在一定的假設和前提下已經有建好的建模,我們建立等價的神經網絡,其實就能走出最容易的一步。
在未來,如果我們真的要貫徹可微編程,就是把它當成一種語言。神經網絡應該更進一步,應該直接對問題進行建模,也就是對我們的物理現象進行建模,并且傳統的統計機器學習方法有一些先驗知識,進而解決我們的一些實際問題。
可能這是更接近于做人工智能這個領域的一個更貼切的思路。
-
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:可微編程:打開深度學習的黑盒子
文章出處:【微信號:deeplearningclass,微信公眾號:深度學習大講堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

NPU在深度學習中的應用
FPGA加速深度學習模型的案例
AI大模型與深度學習的關系
FPGA做深度學習能走多遠?
深度學習中的時間序列分類方法
深度學習與nlp的區別在哪
深度學習的基本原理與核心算法
深度學習常用的Python庫
深度解析深度學習下的語義SLAM

FPGA在深度學習應用中或將取代GPU
為什么深度學習的效果更好?


詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論