 我們對目前機器學習進展的衡量有多可靠?
我們對目前機器學習進展的衡量有多可靠?
我們對機器學習的發展認識,很大程度上取決于少數幾個標準基準,比如CIFAR-10,ImageNet或MuJoCo。
近年來人工智能發展,大的,比如一項又一項“超越人類水平”的進步,以及小的、甚至幾乎每天都在發生的(這要感謝Arxiv),比如在各種論文中不斷被刷新的“state-of-the-art”,無不讓人感嘆領域的蓬勃。
但是,實際情況或許并沒有這么美好。
一項伯克利和MIT合作的新研究,對過去近十年中提出的一些經典分類器(比如VGG和ResNet)進行再測試后發現,由于測試集過擬合,很多分類器的精度實際并沒有宣稱的那么高;在新的數據集上測試結果表明,這些分類器的精度普遍都有下降,幅度4%~10%不等。
研究者表示,這一結果可以被視為證據,證明模型的精度這個數字是不可靠的,并且容易受到數據分布中微小的自然變化的影響。
這項新的研究也提出了一個值得反思的問題——我們目前用來衡量機器學習進展的手段和方法,究竟有多可靠?
重復使用相同的測試集,無法推廣到新數據
作者在論文中寫道,在過去五年里,機器學習已經成為一個實驗領域。在深度學習的推動下,大多數發表的論文都采用了同一種套路,那就是看一種新的方法在幾個關鍵基準上性能有多少提升。換句話說,就是簡單粗暴地對比數值,很少有人去解釋為什么。
而在對比數值的時候,大多數研究的評估都取決于少數幾個標準的基準,例如CIFAR-10、ImageNet或MuJoCo。不僅如此,由于Ground truth的數據分布一般很難得到,所以研究人員只能在單獨的測試集上評估模型的性能。
“現在,在整個算法和模型設計過程中,多次重復使用相同的測試集的做法已經被普遍接受。盡管將新模型與以前的結果進行比較是很自然的想法,但顯然目前的研究方法破壞了分類器獨立于測試集這一關鍵假設。”
這種不匹配帶來了明顯的危害,因為研究人員可以很容易地設計出只能在特定測試集上運行良好,但實際上無法推廣到新數據的模型。
CIFAR-10可重復性實驗:VGG、ResNet等經典模型精度普遍下降
為了審視這種現象造成的后果,研究人員對CIFAR-10以及相關分類器做了再調查。研究的主要目標是,衡量新進的分類器在泛化到來自相同分布的、未知新數據時能做得多好。
選擇標準CIFAR-10數據集,是因為它透明的創建過程使其特別適合于這個任務。此外,CIFAR-10已經成為近10年來研究的熱點,在調查適應性(adaptivity)是否導致過擬合這個問題上,它是一個很好的測試用例。

在實驗中,研究人員首先用新的、確定是模型沒有見過的大約2000幅圖像,制作了一個新的測試集,并將新測試集的子類分布與原始 CIFAR-10 數據集仔細地做匹配,盡可能保持一致。
然后,在新測試集上評估了30個圖像分類器的性能,包括經典的VGG、ResNet,最近新提出的ResNeXt、PyramidNet、DenseNet,以及在ICLR 2018發布的Shake-Drop,這個Shake-Drop正則化方法結合以前的分類器,取得了目前的state-of-art。
結果如下表所示。原始CIFAR-10測試集和新測試集的模型精度,Gap是兩者精度的差異。ΔRank表示排名的變化,比如“-2”意味著在新測試集中的排名下降了兩個位置。
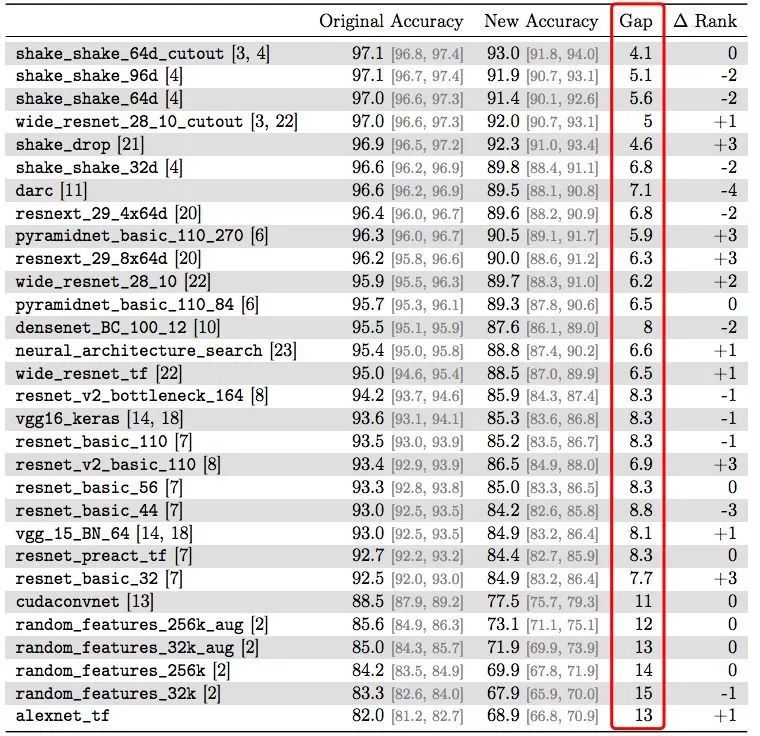
由結果可知,新測試集上模型的精度相比原始測試集有明顯下降。例如,VGG和ResNet這兩個模型在原始數據集上準確率為93%,而在新測試集上降為了85%左右。此外,作者還表示,他們發現現有測試集上模型的性能相比新測試集更加具有預測性。
對于出現這種結果的原因,作者設定了多個假設并一一進行了討論,除了統計誤差、調參等之外,主要還是過擬合。
作者表示,他們的結果展現了當前機器學習進展令人意外的一面。盡管CIFAR-10測試集已經被不斷適應(adapting)了很多年,但這種趨勢并沒有停滯。表現最好的模型仍然是最近提出的Shake-Shake網絡(Cutout正則化)。而且,在新的測試集置上,Shake-Shake比標準ResNet的優勢從4%增加到8%。這表明,瞄準一個測試集猛攻的研究方法對過擬合而言是十分有效的。
同時,這個結果也對當前分類器的魯棒性提出了質疑。盡管新數據集只做了微小的改變(分布轉移),但現有的被廣泛使用的模型,分類準確性普遍顯著下降。例如,前面提到的VGG和ResNet的精度損失對應于CIFAR-10的多年進展。
作者特別指出,他們的實驗引起的分布轉移(distributional shift)既不是對抗性的(adversarial),也不是不同數據源導致的結果。因此,即使在良性環境中,分布轉移也會帶來嚴峻的挑戰,研究人員需要思考,目前的模型真正能泛化到什么程度。
機器學習研究也需要注意可重復性
Python Machine Learning 一書作者Sebastian Raschka評論這項研究認為,它再次提醒機器學習研究人員注意測試集重復使用(以及違背獨立性)的問題。
谷歌大腦研究科學家、Twitter賬戶hardmaru表示,對機器學習研究進行可靠評估的方法十分重要。他期待見到有關文本和翻譯的類似研究,并查看PTB,wikitext,enwik8,WMT'14 EN-FR,EN-DE等結構如何從相同分布轉移到新的測試集。
不過,hardmaru表示,如果在PTB上得到類似的結果,那么對于深度學習研究界來說實際上是好事,因為在PTB這個小數據集上進行超級優化的典型過程,確實會讓人發現泛化性能更好的新方法。
作者表示,未來實驗應該探索在其他數據集(例如ImageNet)和其他任務(如語言建模)上是否同樣對過擬合具有復原性。此外,我們應該了解哪些自然發生的分布變化對圖像分類器具有挑戰性。
為了真正理解泛化問題,更多的研究應該收集有洞察力的新數據并評估現有算法在這些數據上的性能表現。類似于招募新參與者進行醫學或心理學的可重復性實驗,機器學習研究也需要對模型性能的可重復多做研究。
-
MIT
+關注
關注
3文章
253瀏覽量
23624 -
機器學習
+關注
關注
66文章
8459瀏覽量
133373
原文標題:十年機器學習結果不可靠?伯克利&MIT研究質疑了30個經典模型
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊

【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
如何選擇云原生機器學習平臺
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
人工智能、機器學習和深度學習存在什么區別

AMD贊助多支FIRST機器人競賽團隊
衡量功率放大電路的參數有哪些
【「時間序列與機器學習」閱讀體驗】時間序列的信息提取
【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
如何理解機器學習中的訓練集、驗證集和測試集
深度學習與傳統機器學習的對比
機器學習8大調參技巧





 工商網監
工商網監
評論