 關于基于動態連續數據的GPU調試系統的設計和實現
關于基于動態連續數據的GPU調試系統的設計和實現
0 引言
隨著GPU技術的發展,GPU結構變得越來越復雜,對硬件的調試成為一個越來越困難的任務。硬件調試的困難在于硬件本身的不透明性。在發生問題的時候,工程師沒有辦法像軟件調試那樣,看到硬件內部發生了什么,也不能像軟件調試那樣,半路設一個斷點,把硬件停下來。
為方便對硬件的調試,GPU設計人員開發出很多種硬件調試方法來降低硬件調試的難度,傳統上有DebugBus、掃描路徑法、ARM CoreSightTM技術。這些方法的目的都是用某種方法將硬件內部信息暴露給工程師,降低硬件的不透明性,但其暴露出的信息都是硬件內部某個時間點的靜態信息,對硬件工程師的幫助是有限的。
本文提出一種新的調試架構,相對于傳統技術,它能夠提供一段時間內的動態數據給工程師,讓工程師能夠了解在這段時間內硬件內部狀況是如何變化的,使得工程師能迅速定位到造成問題的異常變化。甚至更進一步,工程師可以將得到的信息導入模擬環境,在模擬環境里面重現硬件的問題。
1 傳統硬件調試方式及其缺陷
1.1 DebugBus
DebugBus技術是最早在芯片設計中引進的調試技術[1-2]。其基本原理是在硬件設計中添加一批狀態寄存器,每個模塊都把自己的狀態編碼后送到這個狀態寄存器中。當發生問題的時候,工程師讀取狀態寄存器中的狀態碼,從而可以分析問題發生的原因。
DebugBus技術缺陷在于,狀態寄存器的位是有限的,所以能反映模塊的狀態也是有限的,工程師通過狀態碼只能大概了解模塊的真實情況。
1.2 基于掃描路徑法的可測性設計技術
基于掃描路徑法的可測性設計技術是可測性設計(DFT)技術的一個重要方法[3-5],這種方法能夠從芯片外部設定電路中各個觸發器的狀態,并通過簡單的掃描鏈設計,掃描觀測觸發器是否工作在正常狀態,以此來檢測電路的正確性。
這種技術的缺陷在于它速度太慢,因為它是一個串行的操作,不能一次讀出全部數據,導致工程師不能得到一個即時的數據[6]。
1.3 ARM CoreSightTM技術
CoreSightTM技術是ARM公司在2004年推出的一個新的調試體系架構,以提供更為強大的調試能力[7]。
CoreSightTM技術比較適合于軟件調試,因為它提供給工程師的是模塊之間的指令和寄存器傳遞序列,軟件工程師可以知道自己送給硬件的命令是如何在硬件各個模塊之間傳遞。但硬件開發工程師更多的是想了解模塊和模塊之間完整的會話信息,甚至是模塊內部的一些信號[8-9]。
2 新調試系統硬件部分
對于硬件開發工程師來說,要調試硬件問題需要得到大量硬件內部模塊和模塊之間的會話信息,這些信息最好是某個時間段內連續的信息,而不是簡單的某個時間點的信息。
但是要把所有這些信息收集給調試人員,就需要解決兩個問題:
第一,每個時鐘周期產生的信息是大量的,為了不影響后面的時序,必須在一個時鐘周期內處理完。但硬件帶寬的限制又決定了這些不可能在一個周期內處理完。這也是過去技術上只能提供簡略信息的主要原因。
第二,由于每個時鐘周期都產生大量的信息,因此我們要處理的整體信息量非常巨大,導致這些信息的存儲就是一個問題。
為了解決這些問題,設計了一個雙時鐘系統。當我們發現需要存儲信息的時候,我們就把全局時鐘停止,從而使得各個模塊停止工作。同時我們用另外一套時鐘系統驅動調試模塊收集和壓縮信息。當信息收集完成以后,就把相關的數據發送到存儲模塊去存儲。當存儲完成時候,再重新激活全局時鐘,讓各個模塊繼續工作。
由于采用了雙時鐘系統,提供了足夠的時間來進行信息的收集和存儲。因此在存儲媒介上,我們放棄了價格昂貴但容量偏小的閃存,而是選擇了從板載內存中分配一塊較大的區間,這樣就能在成本范圍內提供能夠存放足夠多信息的存儲空間。
根據以上設計,我們把新的調試系統分成了5個模塊。
2.1 會話取樣模塊
會話取樣模塊負責將模塊和模塊之間的會話傳給會話監控模塊或者會話記錄模塊。假設我們有兩個模塊A和B,一般情況下,模塊A和模塊B之間通過接口C連接,互相傳遞信息,如圖1所示。

將會話取樣模塊放在接口C上,通過它來檢查模塊A和模塊B之間是否有會話,如果有會話發生,那么就把會話內容傳給會話存儲模塊,并由會話存儲模塊將內容整理存儲到存儲媒介上,如圖2所示。

2.2 會話監控模塊
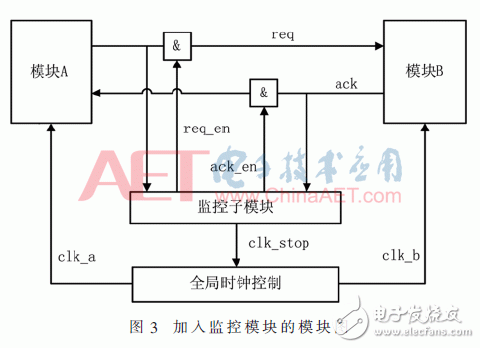
會話監控模塊負責監控模塊之間的會話,一旦它發現模塊A和模塊B之間發生了會話,那么會話監控模塊就會通知全局時鐘控制模塊,把所有模塊的時鐘中止,如圖3所示。
2.3 會話記錄模塊
會話記錄模塊負責在全局時鐘停止時,將會話的內容記錄到內存中。我們沒有采用傳統上的內部Cache的模式,因為雖然內存中記錄比較慢,但是可以提供極大的記錄空間,可以記錄相當長時間的會話。只要內存足夠大,就可以記錄足夠長的會話。
會話記錄模塊會把會話記錄循環寫入對于軟件分配給硬件的內存,同時它提供兩個寄存器給軟件用于判斷是否有信息寫入。一個寄存器表示內存中未處理信息的頭部,一個寄存器表示內存中未處理信息的尾部。會話記錄模塊在寫入信息前,會檢查未處理信息的尾部是否和未處理信息頭部重合,如果是,說明內存中信息已經滿了,那么記錄模塊會停下等待軟件把信息讀走。
由于各個模塊之間會話大小不同,因此在存儲的數據結構上,我們沒有采取固定長度的數據結構,而是設計了一種變長的數據結構。它分為頭部和數據兩塊。頭部是一個固定結構,表面數據包的信息,而其后跟隨著一個變長的數據流。它包含了三部分信息:
(1)模塊ID:記錄了信息來自哪個模塊。
(2)數據長度:會話信息的大小。
(3)時間戳:會話發生的時間,可以用于仿真模型。
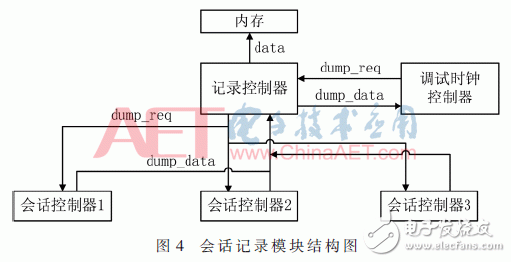
在實際應用中,內存控制器只有一個輸入,為了協調各個模塊的寫入順序,我們專門設計了一個記錄控制器,用來接收各個會話記錄模塊的輸出,并轉送到內存控制器中,如圖4所示。
2.4 全局時鐘控制器
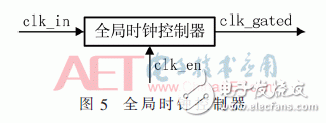
該模塊用來控制各個模塊的時鐘。一旦一個會話記錄的請求發生,那么全局時鐘控制器就會向各個模塊發出時鐘停止信號,中止各個模塊的運行,在會話記錄完成后,才會發出時鐘繼續的信號。
圖5就是全局時鐘控制器的模塊圖,這是整個架構設計中最基本的一塊。
2.5 調試時鐘模塊
在全局時鐘被中止的時候,雖然其他模塊都停止工作了,但是會話記錄模塊、會話取樣模塊、內存控制器等一系列模塊都還要繼續工作,因為系統為他們單獨設置了這么一個時鐘模塊,在全局時鐘被中止時,繼續為其他模塊提供時鐘中斷。
3 新調試系統的軟件部分
軟件部分的功能就是根據工程師的需求配置相應的調試環境,并將硬件產生的信息存儲到相應的文件中去。
雖然新調試系統解決了存儲時間較長的問題,但是為了提高調試效率,在存儲過程中,我們采用多Buffer輪替的方式來提高數據的讀取效率。
4 應用的成果
在新一代GPU的結構中加上了新的硬件調試架構,取得了初步的成果。
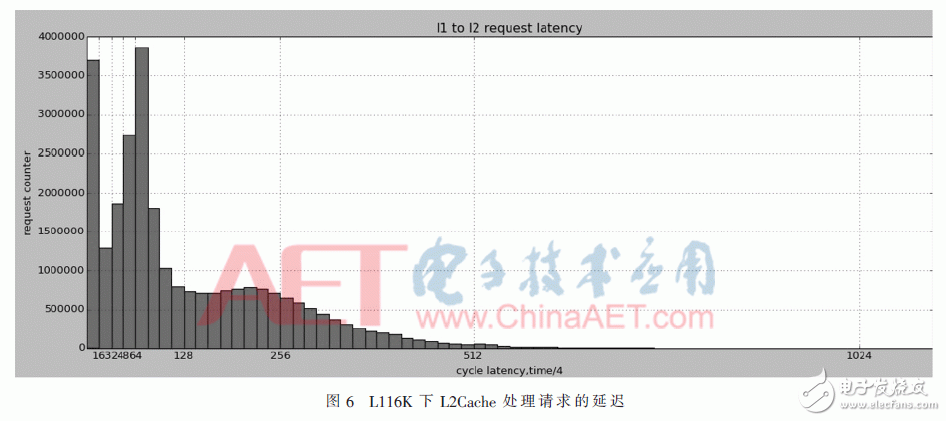
在這次設計開發中,在FPGA上通過大量的應用,利用新的調試系統對L2Cache進行了研究,獲取了大量的數據。圖6是在不同的L1Cache設計下,L2 Cache和內存存儲模塊(MXU)之間會話后的分析結果。從圖中,我們可以清晰地看到在實際中,L2 Cache是如何處理接收的請求,以及其中的4個bank各自的負載情況如何,使得硬件開發人員可以清晰地發現Cache設計中存在的問題,并為優化Cache結構提供了充分的數據基礎。
另外,我們也在FPGA上重現了一些硬件隨機問題,并且獲取了相應的數據。在把這些數據導入我們的RTL仿真環境后,成功地在模擬環境中重現了這些硬件問題。現在通過調試系統獲取信息進行模擬重現,解決了過去硬件開發人員調試硬件問題由于硬件封裝而只能通過間接信息分析來調試的問題。硬件開發人員可以根據波形來分析出問題的原因,極大地提高開發人員調試的速度。
5 結語
利用這種雙時鐘架構,我們能否更進一步開發單步調試系統,使得硬件調試象軟件調試一樣,可以設斷點,停下后即時查看硬件狀態。如果能實現,那將更進一步簡化硬件調試能力,提高硬件開發水平,這也是我們下一步的研究方向之一。
-
寄存器
+關注
關注
31文章
5357瀏覽量
120632 -
gpu
+關注
關注
28文章
4752瀏覽量
129056
發布評論請先 登錄
相關推薦
輪胎動態試驗臺在線測控系統的研制
采集的動態數據 繪制成XY圖,如何實現連續?
NVIDIA Tesla P40動態GPU內存分配可能嗎?
從一個文本數據的文件夾中,怎樣實現數據的連續提取
動態模塊加載的調試經驗分享
動態二進制翻譯系統的調試器框架
關于動態甲類功放電路的工作原理與調試要點
連續時間系統時域分析的MATLAB實現
避免FPGA、GPU和ASIC系統電源管理中的調試周期






 工商網監
工商網監
評論