


基于一個可伸縮的、任務無關的系統,OpenAI在一組包含不同的語言任務中獲得了最優的實驗結果,方法是兩種現有理念的結合:遷移學習和無監督的預訓練。這些結果證明了有監督的學習方法可以與無監督的預訓練進行完美的結合。這個想法許多人在過去探索過,OpenAI希望結果能激發更多的研究,進而將這個想法應用到更大、更多樣化的數據集上。
我們的系統分為兩個階段:首先,我們通過無監督的方式在大數據集上訓練一個遷移學習模型,訓練過程中使用語言模型的訓練結果作為信號,然后我們在更小的有監督數據集上對這個模型進行微調,以幫助它解決特定的任務。這個方法的開發是在我們前一個sentiment neuron(情緒神經元)的工作之后進行的,在sentiment neuron任務中我們注意到,通過利用足夠的數據對模型進行訓練,無監督學習可以獲得令人驚訝的判別特征。在這里,我們想進一步探討這個想法:我們能否開發一個模型,以一種無監督的方式使用大量數據對模型進行訓練,然后對模型進行微調,以在不同的任務中都獲得良好的性能?我們的研究結果表明,這種方法的效果出奇地好。同樣的核心模型可以針對完全不同的任務進行微調,以適應任務。
本研究是基于在半監督序列學習中引入的方法,該方法展示了如何通過對LSTM進行無監督的預訓練,然后進行有監督的微調,來提高文本分類的能力。它還擴展了ULMFiT的研究,該研究展示了如何對單個數據不可知的LSTM語言模型進行微調,從而在各種文本分類數據集上獲得最優的性能。我們的工作展示了如何在這種方法中使用遷移學習模型,從而在文本分類之外的更廣泛任務中取得成功,例如常識推理、語義相似性和閱讀理解等。它與ELMo類似,但屬于任務無關型問題,它包含了預訓練,希望使用針對任務的特殊模型架構來獲得最優的結果。
我們通過對很少的參數調優來達到我們的目的。所有的數據集都僅使用一個前向語言模型,沒有任何組合,并且大多數的結果都使用完全相同的超參數設置。
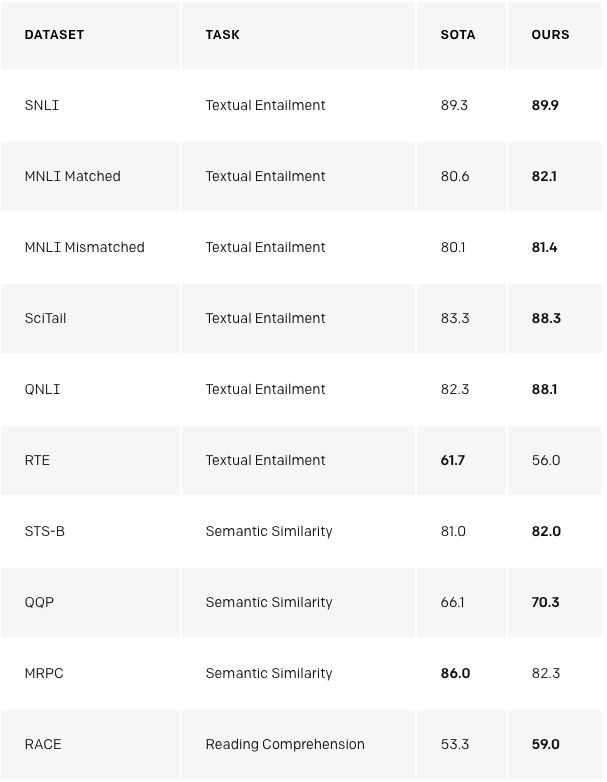
我們的方法在COPA、RACE和ROCStories三個數據集上的性能都表現得特別好,這些數據集是用來測試常識推理和閱讀理解的。我們的模型在這些數據集上獲得了最優的結果。這些數據集的識別被認為需要多句推理和重要的世界知識,這表明我們的模型主要通過無監督學習來提高這些能力。以上表明,無監督的技術有希望開發復雜的語言理解能力。
為什么是無監督學習?
監督學習是大多數機器學習算法成功的核心。然而,它需要對大量的數據進行仔細的清理,創建的代價也極其昂貴,這樣才能獲得很好的效果。無監督學習的吸引力在于它有可能解決這些缺點。由于無監督的學習消除了人為顯式標記的瓶頸,它也很好地擴展了當前的趨勢,即增加了原始數據的計算能力和可用性。無監督學習是一個非常活躍的研究領域,但它的實際應用往往很有限。
最近的一次一項嘗試是試圖通過使用無監督學習來對具有大量未標記數據的系統進行增強,從而進一步提高模型的語言能力。通過無監督訓練的單詞表示可以使用包含萬億字節信息組成的大型數據集,當與有監督學習相結合時,可以提高各種NLP任務的性能。直到最近,這些無監督的NLP技術(例如GLoVe和word2vec)使用了簡單的模型(詞向量)和訓練信號(單詞的局部同時出現)。skip-Thought向量是一個很值得注意的早期想法,它展示了更復雜的方法如何進行改進的潛能。而現在正在使用新的技術將進一步提高實驗性能。上述技術包括使用預訓練的句子來表示模型,上下文化的詞向量(特別是ELMo和CoVE),以及像我們提出來的方法:使用特定的模型架構來將無監督的預訓練和有監督的微調融合在一起。
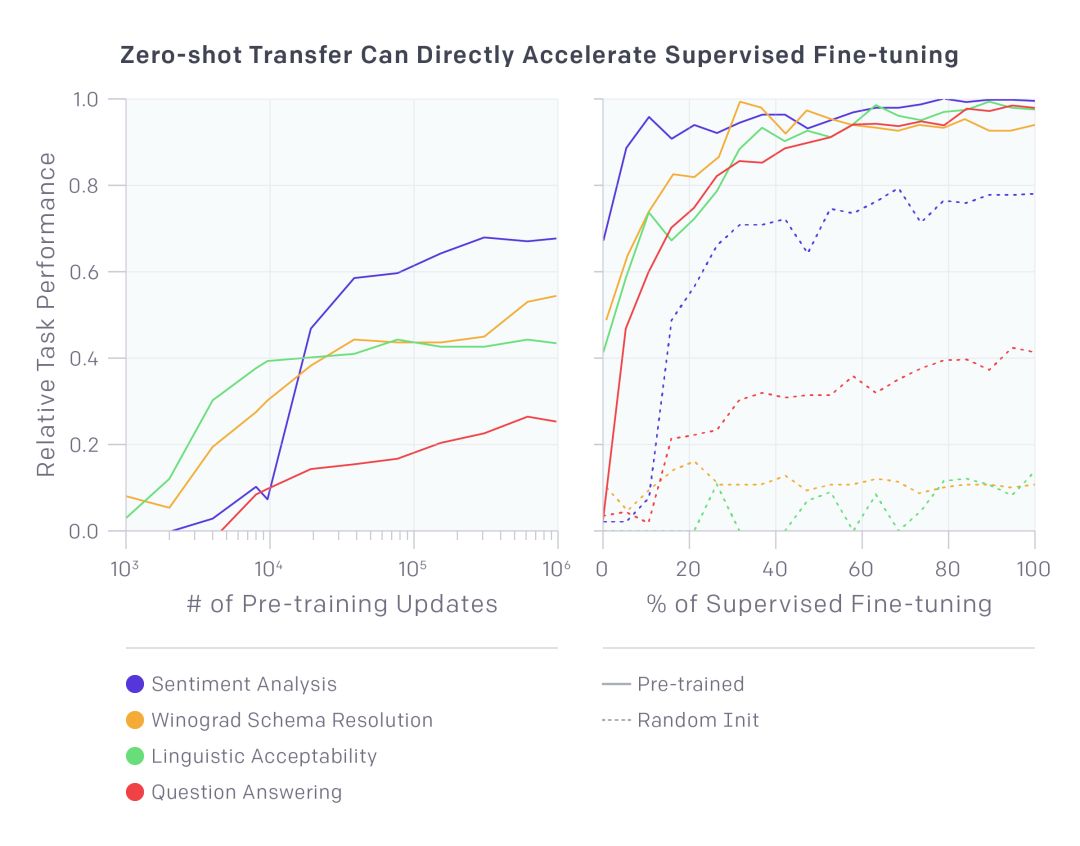
在大量文本的基礎上對我們的模型進行預訓練,極大地提高了它在具有挑戰性的自然語言處理任務上的性能,比如Winograd模式解析。
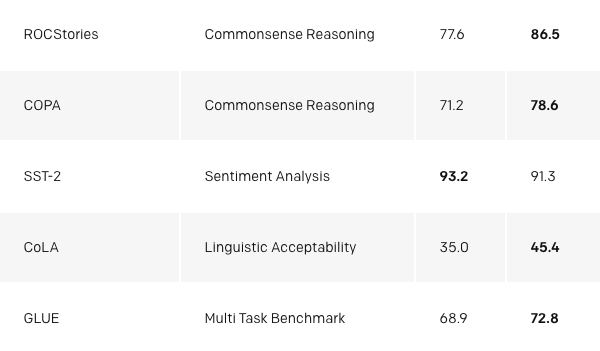
我們還注意到,我們可以使用未訓練的基礎語言模型執行任務。例如,隨著基礎語言模型的改進,像選擇多個正確答案這樣任務的性能會穩步增加。雖然這些方法的絕對性能相對于最新的有監督技術而言仍然很低,(對于問答系統,它的表現優于簡單的滑動窗口那樣的基線系統)但是鼓舞人心的一點是,這種行為在廣泛集合的任務中是具有魯棒性的。使用這些啟發式算法,不包含關于任務和世界的信息的隨機初始化網絡不會比包含這些信息的隨機初始化方法獲得更好的效果。這就提供了一些見解,告訴我們為什么生成預訓練可以提高下游任務的性能。
我們還可以使用模型中現有的語言功能來執行情感分析。對于由正面和負面影評組成的斯坦福情緒Treebank數據集,我們可以通過使用語言模型在句子后面輸入單詞“very”來猜測評論是正面還是負面,還能看看這個模型是否具有預測“積極的”或“消極的”的傾向。 這種方法根本不需要根據任務調整模型,其性能與經典基線相當,準確度達到80%左右。
我們的工作也驗證了遷移學習的魯棒性和有效性,這表明它足夠靈活,可以在不需要對復雜的任務進行定制或對超參數進行調優的情況下,在廣泛數據的任務上獲得最優的結果。
缺點
這個項目有一些問題還是值得注意的:
計算要求:許多以前的NLP任務方法都是從頭開始,在單個GPU上訓練相對較小的模型。 我們的方法需要昂貴的預訓練步驟:在8個GPU上進行為期1個月的訓練。幸運的是,這個訓練只需要進行一次。我們正在發布我們的模型,這樣其他人就不用再次訓練這樣的模型了。同時,與之前的工作相比,它也是一個大型模型,因此使用更多的計算和內存,我們使用了37層(12塊)Transformer架構,并且我們訓練的序列最多可達512個令牌。大多數實驗都是在4個/8個GPU系統上進行的。該模型可以快速調整新任務,從而有助于減輕額外的資源需求。
學習到文本中所包含的世界局限性和數據傾斜:互聯網上隨時可用的書籍和文本不包含關于世界的完整乃至準確的信息。最近的工作表明,某些類型的信息很難通過文本學習,而其他工作表明模型學習且利用了數據分布中包含的傾斜。
脆弱的泛化能力:盡管我們的方法改善了廣泛任務的性能,但目前的深度學習NLP模型的表現有時仍然是違反直覺并且令人震驚的,尤其是在以系統性,對抗性或分布式分布的方式進行評估時。盡管我們已經觀察到一些進展的跡象,但我們的方法對這些問題并非免疫。相比較于以往純文本的神經網絡,我們的方法具有更優越的詞法魯棒性。在2018年Glockner等人介紹的數據集中,我們的模型準確率達到83.75%,表現類似于通過WordNet整合外部知識的KIM方法。
展望未來
擴展方法:我們已經觀察到,語言模型性能的改進與下游任務的改進密切相關。目前我們正在使用一臺包含8 GPU計算機作為硬件,并僅使用大概包含5GB文本的幾千本書作為訓練數據集。 根據經驗表明,使用更多的計算性能和數據可以使算法有很大的改進空間。
改進微調:我們的方法目前非常簡單。如果使用更復雜的適應和遷移技術(例如ULMFiT中探索的技術)可能會有實質性的改進。
更好地理解生成性預訓練的原理會對模型有益:盡管我們已經討論了一些我們在此討論的想法,但更有針對性的實驗和研究將有助于區分那些不同的解釋。例如,我們觀察到的性能提高有多少是得益于改進了處理更廣泛背景的能力以及改進的世界知識?
-
nlp
+關注
關注
1文章
490瀏覽量
22649 -
遷移學習
+關注
關注
0文章
74瀏覽量
5741
原文標題:OpenAI最新研究:通過無監督學習提高語言理解能力
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
AI模型是如何訓練的?訓練一個模型花費多大?
一文詳解知識增強的語言預訓練模型
【大語言模型:原理與工程實踐】大語言模型的預訓練
迄今最大模型?OpenAI發布參數量高達15億的通用語言模型GPT-2

NLP中的對抗訓練到底是什么
利用ImageNet訓練了一個能降噪、超分和去雨的圖像預訓練模型
2021 OPPO開發者大會:NLP預訓練大模型
2021年OPPO開發者大會 融合知識的NLP預訓練大模型







 工商網監
工商網監

評論