 如何利用非監督學習實現了不同音樂間的樂器、體裁和風格間的轉換
如何利用非監督學習實現了不同音樂間的樂器、體裁和風格間的轉換
Facebook上月末發表了一篇名為“A Universal Music Translation Network”的文章(原文鏈接在文末),詳細闡述了如何利用非監督學習實現了不同音樂間的樂器、體裁和風格間的轉換。相信小伙伴們或多或少地了解過這篇論文。

但是如果從音樂家的角度來看這個過程是如何進行的呢?本文將從四個不同的層次帶領我們更深入地理解這篇論文中所描述的方法,看看到底是什么神奇的魔力將長笛的悠揚轉換為了鋼琴的動聽的。
level-0:新手
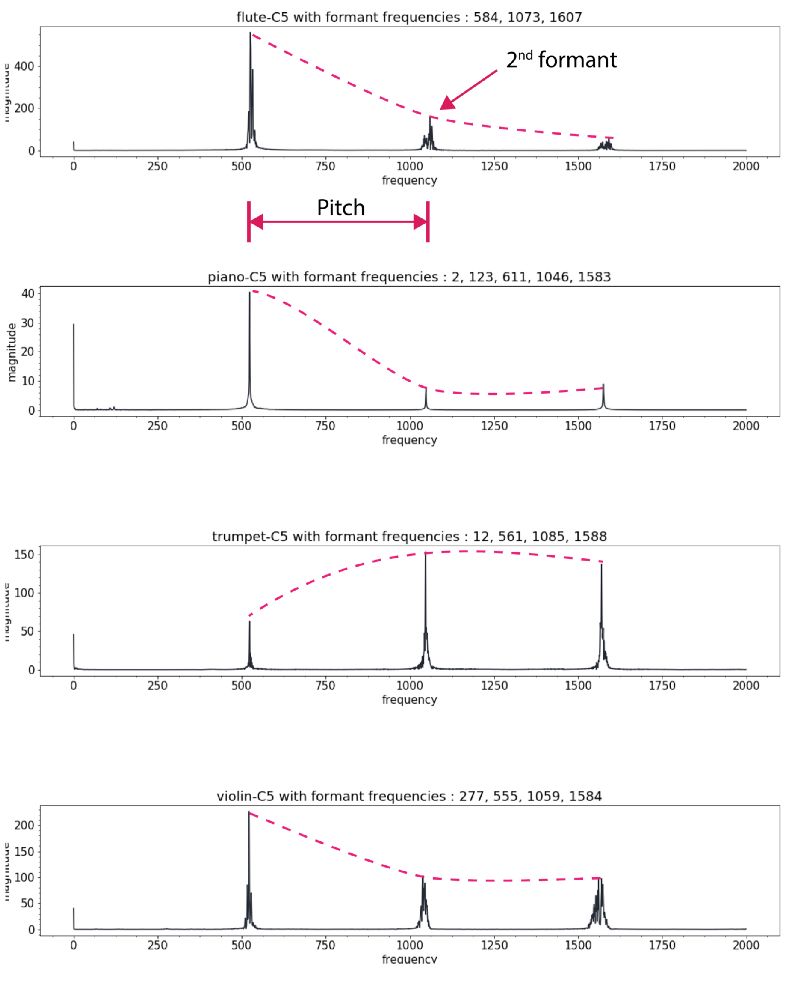
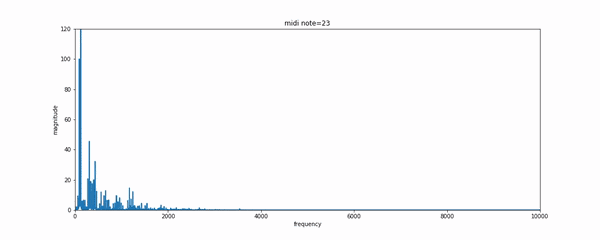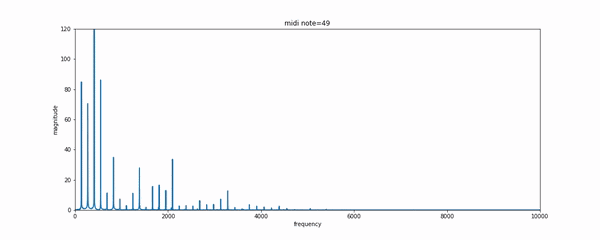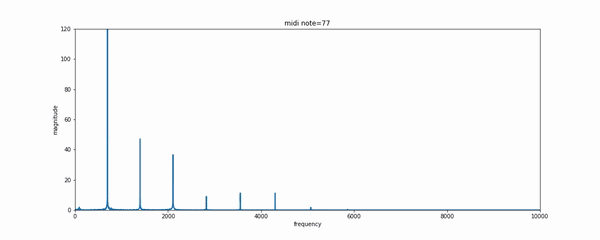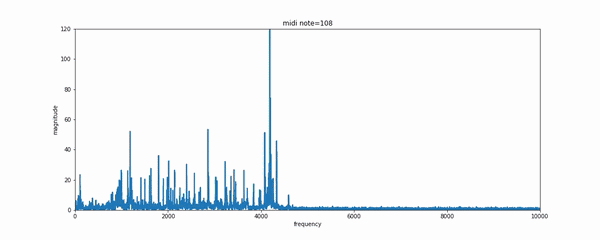
對于新手來說想要快速實現風格轉換,傅里葉變換將是一個不錯的手段。利用頻譜分析將會迅速的找出對應的和弦和音符并在新的樂器上演奏出來。事實上傳統的處理方法提供了一系列這樣的手段:通過解碼器與基于本征樂器的樂器歸一化方法或者復調方法來實現。每一種樂器都有獨特的音符集和時域瞬態特征,但困難的是即使對于單一樂器來說,其頻譜包絡在不同的音高下并不服從同峰值模式。同時還有不同的泛音和諧頻需要處理。所有的這些使得音樂在不同樂器間的風格轉換十分困難。
level-1:深度學習專業的同學
如果擁有一點樂理基礎的話,可以使用CNN模型通過MIDI格式的音樂生成的label來學習音樂的表達和轉錄。MIDI是一種在合成器中常用的數字音樂,每一個鍵被按下或者抬起都意味著一次事件的觸發。可以通過如MAPS一樣的數據集來實現復調鋼琴音樂的轉錄問題。
level-2:NLP學者將如何處理呢?
NLP學者最有可能使用的方法應該是sequence to sequence模型了,但這種方法需要同時追蹤原始樂器和目標樂器的發音序列。
level-3:直接學習轉換和鄰域歸一化
對于十分優秀的音樂家來說,他們會明白每一種樂器之間的細微差別是MIDI所不能捕捉到的,而這個問題就是facebook文章中的創新所在。研究人員借鑒了wavenet的自回歸架構并充分利用它將這一問題轉換為了“下一個音符是什么”的類似問題,從而將其變成了一個非監督問題來解決。

wavenet本質上使用隨學習過程不斷擴大的卷積得到了增加的感受野,從而可以得到更好的預測結果和包含更為豐富特征的隱含空間。這些特征抓住了人類聲音和樂器聲音的本質,就像cnn中抽取的圖像特征一樣。此時如果你想要通過學習一個自回歸模型來預測鋼琴的下一個音調,你只需要簡單的學習一對兒wavenet編碼器和解碼器。編碼器將把原始的音樂序列投射到隱含空間中,而解碼器將盡力理解隱含空間的中的數值并解碼成下序列的下一個值。
是不是很奇妙?如果一個模型可以編碼鋼琴但解碼成其他樂器是不是就可以實現音樂在不同樂器間的轉換啦?這就是FacebookAI研究人員的努力。他們利用一個相同的編碼器對多種樂器進行編碼,而后利用不同的解碼器實現不同樂器的解碼,實現了多種樂器之間的風格互轉。那么它是如何工作的呢?下面讓我我們來具體看一看。
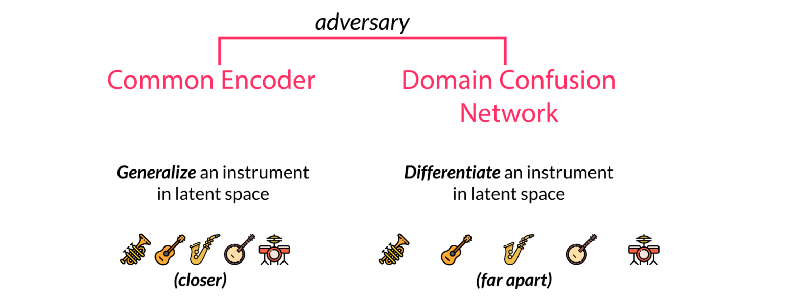
多個樂器間共享同一個解碼器會迫使這個解碼器去學習音樂間的相同特征。但對于解碼器來說,我們需要告訴它這到底是什么樂器,需要解碼的目標域是什么。這就需要對于不同樂器的域訓練特殊的解碼器來實現。論文中使用了對抗的方法來實現這一目標。由于通用的潛在空間希望去尋找通用的特征而忽略了每種樂器的特殊性,而混淆矩陣則希望分割共同特征中不同的表達并盡可能的實現不同的類別特征。通過特殊與一般之間的對抗得到了兩個性能強大的編碼和解碼模型。值得注意的是要想同時獲得兩個性能優異的編解碼模型,需要仔細地選擇正則化系數來實現。
讓我們來看看這個模型的損失函數。具體的訓練過程是這樣的,首先在不同樂器的域中選取一個樣本sj,隨后利用隨機變調來避免模型無腦地對數據進行記憶。論文中對0.25-0.5s長的樣本使用了-0.5-0.5的半步變調,可以用O(sj,r)來表示,其中r是隨機種子。你也許會對這一步感到疑惑,但使用過谷歌magenta模型或者瞬時生成模型的人都會有這樣的經歷,有的時候模型會像鸚鵡學舌一樣簡單的重復記憶下的序列,簡直是公然的過擬合了。而這就是數據增強和偏移過程的關鍵所在,也是訓練多種樂器的編碼器關鍵所在。
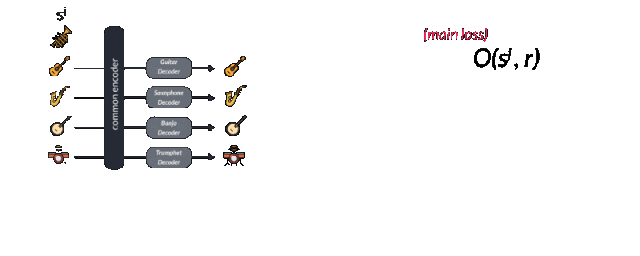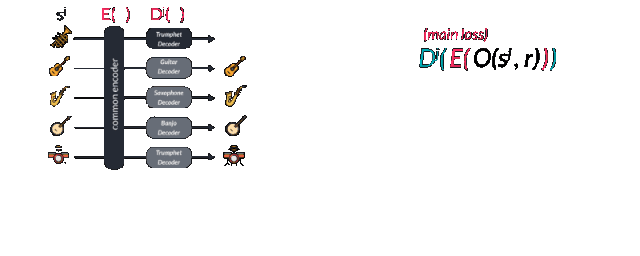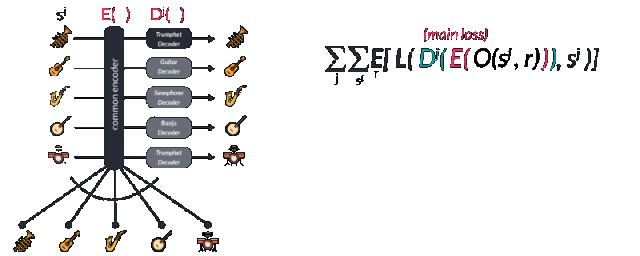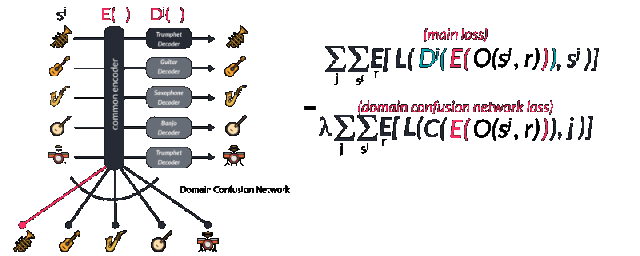
隨后增強數據通過wavenet編碼器中擴大的卷積層轉換到了隱含空間中,并通過對應的解碼器Dj還原到了其對應的樂器空間中并預測出了下一個音符輸出。研究人員通過交叉熵比較實際的下一個輸出和預測的下一個輸出來計算損失函數。其中第一項代表重建誤差要盡可能的小,而第二項領域分類的誤差則用于盡可能的分開不同域的特征,這也是網絡進行對抗訓練的表現。作為一個對抗模型,一個監督的正則項通過后編碼的特征矢量用于預測不同的域。它被稱為域混淆網絡(Domain Confusion Network)。
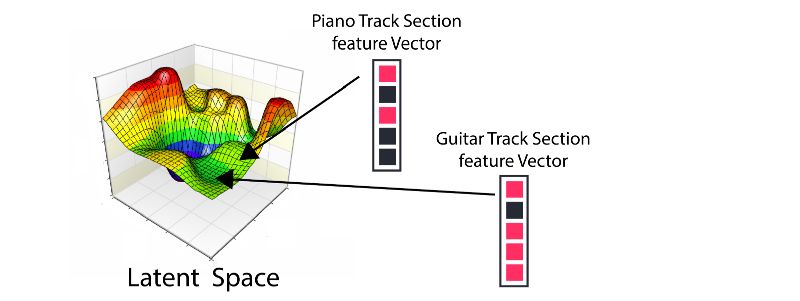
網絡在實際工作過程中,輸入的一個交響樂片段會被轉換和翻譯為一種特殊的樂器,但這個模型最令人驚嘆的能力還不止于此。當輸入一種模型從未見過的樂器時,通過自動編碼和解碼過程它依然可以完美的工作!這證明了模型中的編碼器確實可以提取出音樂中的一般化特征并在隱含空間中表示出來,及時沒有見過這個樂器。這是很多生成算法的核心概念,像GANs和變分自編碼都利用這一思想創造了很多迷人的工作。
-
Facebook
+關注
關注
3文章
1429瀏覽量
54720 -
傅里葉變換
+關注
關注
6文章
441瀏覽量
42592 -
深度學習
+關注
關注
73文章
5500瀏覽量
121111
原文標題:深度解析Facebook的音樂轉換AI模型
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深非監督學習-Hierarchical clustering 層次聚類python的實現
基于半監督學習框架的識別算法
英偉達通過利用GAN及無監督學習,實現了場景間的四季轉換
你想要的機器學習課程筆記在這:主要討論監督學習和無監督學習
如何用Python進行無監督學習
機器學習算法中有監督和無監督學習的區別
最基礎的半監督學習
半監督學習最基礎的3個概念






 工商網監
工商網監
評論