 機器學習實用指南——多類分類與誤差分析
機器學習實用指南——多類分類與誤差分析
多類分類
二分類器只能區分兩個類,而多類分類器(也被叫做多項式分類器)可以區分多于兩個類。
一些算法(比如隨機森林分類器或者樸素貝葉斯分類器)可以直接處理多類分類問題。其他一些算法(比如 SVM 分類器或者線性分類器)則是嚴格的二分類器。然后,有許多策略可以讓你用二分類器去執行多類分類。
舉例子,創建一個可以將圖片分成 10 類(從 0 到 9)的系統的一個方法是:訓練10個二分類器,每一個對應一個數字(探測器 0,探測器 1,探測器 2,以此類推)。然后當你想對某張圖片進行分類的時候,讓每一個分類器對這個圖片進行分類,選出決策分數最高的那個分類器。這叫做“一對所有”(OvA)策略(也被叫做“一對其他”)。
另一個策略是對每一對數字都訓練一個二分類器:一個分類器用來處理數字 0 和數字 1,一個用來處理數字 0 和數字 2,一個用來處理數字 1 和 2,以此類推。這叫做“一對一”(OvO)策略。如果有 N 個類。你需要訓練N*(N-1)/2個分類器。對于 MNIST 問題,需要訓練 45 個二分類器!當你想對一張圖片進行分類,你必須將這張圖片跑在全部45個二分類器上。然后看哪個類勝出。OvO 策略的主要有點是:每個分類器只需要在訓練集的部分數據上面進行訓練。這部分數據是它所需要區分的那兩個類對應的數據。
一些算法(比如 SVM 分類器)在訓練集的大小上很難擴展,所以對于這些算法,OvO 是比較好的,因為它可以在小的數據集上面可以更多地訓練,較之于巨大的數據集而言。但是,對于大部分的二分類器來說,OvA 是更好的選擇。
Scikit-Learn 可以探測出你想使用一個二分類器去完成多分類的任務,它會自動地執行 OvA(除了 SVM 分類器,它使用 OvO)。讓我們試一下SGDClassifier.
>>> sgd_clf.fit(X_train, y_train) # y_train, not y_train_5 >>> sgd_clf.predict([some_digit]) array([ 5.])
很容易。上面的代碼在訓練集上訓練了一個SGDClassifier。這個分類器處理原始的目標class,從 0 到 9(y_train),而不是僅僅探測是否為 5 (y_train_5)。然后它做出一個判斷(在這個案例下只有一個正確的數字)。在幕后,Scikit-Learn 實際上訓練了 10 個二分類器,每個分類器都產到一張圖片的決策數值,選擇數值最高的那個類。
為了證明這是真實的,你可以調用decision_function()方法。不是返回每個樣例的一個數值,而是返回 10 個數值,一個數值對應于一個類。
>>> some_digit_scores = sgd_clf.decision_function([some_digit]) >>> some_digit_scores array([[-311402.62954431, -363517.28355739, -446449.5306454 , -183226.61023518, -414337.15339485, 161855.74572176, -452576.39616343, -471957.14962573, -518542.33997148, -536774.63961222]])
最高數值是對應于類別 5 :
>>> np.argmax(some_digit_scores) 5 >>> sgd_clf.classes_ array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9.]) >>> sgd_clf.classes[5] 5.0
一個分類器被訓練好了之后,它會保存目標類別列表到它的屬性classes_ 中去,按照值排序。在本例子當中,在classes_ 數組當中的每個類的索引方便地匹配了類本身,比如,索引為 5 的類恰好是類別 5 本身。但通常不會這么幸運。
如果你想強制 Scikit-Learn 使用 OvO 策略或者 OvA 策略,你可以使用OneVsOneClassifier類或者OneVsRestClassifier類。創建一個樣例,傳遞一個二分類器給它的構造函數。舉例子,下面的代碼會創建一個多類分類器,使用 OvO 策略,基于SGDClassifier。
>>> from sklearn.multiclass import OneVsOneClassifier >>> ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42)) >>> ovo_clf.fit(X_train, y_train) >>> ovo_clf.predict([some_digit]) array([ 5.]) >>> len(ovo_clf.estimators_) 45
訓練一個RandomForestClassifier同樣簡單:
>>> forest_clf.fit(X_train, y_train) >>> forest_clf.predict([some_digit]) array([ 5.])
這次 Scikit-Learn 沒有必要去運行 OvO 或者 OvA,因為隨機森林分類器能夠直接將一個樣例分到多個類別。你可以調用predict_proba(),得到樣例對應的類別的概率值的列表:
>>> forest_clf.predict_proba([some_digit]) array([[ 0.1, 0. , 0. , 0.1, 0. , 0.8, 0. , 0. , 0. , 0. ]])
你可以看到這個分類器相當確信它的預測:在數組的索引 5 上的 0.8,意味著這個模型以 80% 的概率估算這張圖片代表數字 5。它也認為這個圖片可能是數字 0 或者數字 3,分別都是 10% 的幾率。
現在當然你想評估這些分類器。像平常一樣,你想使用交叉驗證。讓我們用cross_val_score()來評估SGDClassifier的精度。
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy") array([ 0.84063187, 0.84899245, 0.86652998])
在所有測試折(test fold)上,它有 84% 的精度。如果你是用一個隨機的分類器,你將會得到 10% 的正確率。所以這不是一個壞的分數,但是你可以做的更好。舉例子,簡單將輸入正則化,將會提高精度到 90% 以上。
>>> from sklearn.preprocessing import StandardScaler >>> scaler = StandardScaler() >>> X_train_scaled = scaler.fit_transform(X_train.astype(np.float64)) >>> cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy") array([ 0.91011798, 0.90874544, 0.906636 ])
誤差分析
當然,如果這是一個實際的項目,你會在你的機器學習項目當中,跟隨以下步驟(見附錄 B):探索準備數據的候選方案,嘗試多種模型,把最好的幾個模型列為入圍名單,用GridSearchCV調試超參數,盡可能地自動化,像你前面的章節做的那樣。在這里,我們假設你已經找到一個不錯的模型,你試圖找到方法去改善它。一個方式是分析模型產生的誤差的類型。
首先,你可以檢查混淆矩陣。你需要使用cross_val_predict()做出預測,然后調用confusion_matrix()函數,像你早前做的那樣。
>>> y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)>>> conf_mx = confusion_matrix(y_train, y_train_pred)>>> conf_mx array([[5725, 3, 24, 9, 10, 49, 50, 10, 39, 4], [ 2, 6493, 43, 25, 7, 40, 5, 10, 109, 8], [ 51, 41, 5321, 104, 89, 26, 87, 60, 166, 13], [ 47, 46, 141, 5342, 1, 231, 40, 50, 141, 92], [ 19, 29, 41, 10, 5366, 9, 56, 37, 86, 189], [ 73, 45, 36, 193, 64, 4582, 111, 30, 193, 94], [ 29, 34, 44, 2, 42, 85, 5627, 10, 45, 0], [ 25, 24, 74, 32, 54, 12, 6, 5787, 15, 236], [ 52, 161, 73, 156, 10, 163, 61, 25, 5027, 123], [ 43, 35, 26, 92, 178, 28, 2, 223, 82, 5240]])
這里是一對數字。使用 Matplotlib 的matshow()函數,將混淆矩陣以圖像的方式呈現,將會更加方便。
plt.matshow(conf_mx, cmap=plt.cm.gray) plt.show()
這個混淆矩陣看起來相當好,因為大多數的圖片在主對角線上。在主對角線上意味著被分類正確。數字 5 對應的格子看起來比其他數字要暗淡許多。這可能是數據集當中數字 5 的圖片比較少,又或者是分類器對于數字 5 的表現不如其他數字那么好。你可以驗證兩種情況。
讓我們關注僅包含誤差數據的圖像呈現。首先你需要將混淆矩陣的每一個值除以相應類別的圖片的總數目。這樣子,你可以比較錯誤率,而不是絕對的錯誤數(這對大的類別不公平)。
row_sums = conf_mx.sum(axis=1, keepdims=True) norm_conf_mx = conf_mx / row_sums
現在讓我們用 0 來填充對角線。這樣子就只保留了被錯誤分類的數據。讓我們畫出這個結果。
np.fill_diagonal(norm_conf_mx, 0) plt.matshow(norm_conf_mx, cmap=plt.cm.gray) plt.show()
現在你可以清楚看出分類器制造出來的各類誤差。記住:行代表實際類別,列代表預測的類別。第 8、9 列相當亮,這告訴你許多圖片被誤分成數字 8 或者數字 9。相似的,第 8、9 行也相當亮,告訴你數字 8、數字 9 經常被誤以為是其他數字。相反,一些行相當黑,比如第一行:這意味著大部分的數字 1 被正確分類(一些被誤分類為數字 8 )。留意到誤差圖不是嚴格對稱的。舉例子,比起將數字 8 誤分類為數字 5 的數量,有更多的數字 5 被誤分類為數字 8。
分析混淆矩陣通常可以給你提供深刻的見解去改善你的分類器。回顧這幅圖,看樣子你應該努力改善分類器在數字 8 和數字 9 上的表現,和糾正 3/5 的混淆。舉例子,你可以嘗試去收集更多的數據,或者你可以構造新的、有助于分類器的特征。舉例子,寫一個算法去數閉合的環(比如,數字 8 有兩個環,數字 6 有一個, 5 沒有)。又或者你可以預處理圖片(比如,使用 Scikit-Learn,Pillow, OpenCV)去構造一個模式,比如閉合的環。
分析獨特的誤差,是獲得關于你的分類器是如何工作及其為什么失敗的洞見的一個好途徑。但是這相對難和耗時。舉例子,我們可以畫出數字 3 和 5 的例子
cl_a, cl_b = 3, 5 X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)] X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)] X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)] X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)] plt.figure(figsize=(8,8)) plt.subplot(221); plot_digits(X_aa[:25], ../images_per_row=5) plt.subplot(222); plot_digits(X_ab[:25], ../images_per_row=5) plt.subplot(223); plot_digits(X_ba[:25], ../images_per_row=5) plt.subplot(224); plot_digits(X_bb[:25], ../images_per_row=5) plt.show()

左邊兩個5*5的塊將數字識別為 3,右邊的將數字識別為 5。一些被分類器錯誤分類的數字(比如左下角和右上角的塊)是書寫地相當差,甚至讓人類分類都會覺得很困難(比如第 8 行第 1 列的數字 5,看起來非常像數字 3 )。但是,大部分被誤分類的數字,在我們看來都是顯而易見的錯誤。很難明白為什么分類器會分錯。原因是我們使用的簡單的SGDClassifier,這是一個線性模型。它所做的全部工作就是分配一個類權重給每一個像素,然后當它看到一張新的圖片,它就將加權的像素強度相加,每個類得到一個新的值。所以,因為 3 和 5 只有一小部分的像素有差異,這個模型很容易混淆它們。
3 和 5 之間的主要差異是連接頂部的線和底部的線的細線的位置。如果你畫一個 3,連接處稍微向左偏移,分類器很可能將它分類成 5。反之亦然。換一個說法,這個分類器對于圖片的位移和旋轉相當敏感。所以,減輕 3/5 混淆的一個方法是對圖片進行預處理,確保它們都很好地中心化和不過度旋轉。這同樣很可能幫助減輕其他類型的錯誤。
多標簽分類
到目前為止,所有的樣例都總是被分配到僅一個類。有些情況下,你也許想讓你的分類器給一個樣例輸出多個類別。比如說,思考一個人臉識別器。如果對于同一張圖片,它識別出幾個人,它應該做什么?當然它應該給每一個它識別出的人貼上一個標簽。比方說,這個分類器被訓練成識別三個人臉,Alice,Bob,Charlie;然后當它被輸入一張含有 Alice 和 Bob 的圖片,它應該輸出[1, 0, 1](意思是:Alice 是,Bob 不是,Charlie 是)。這種輸出多個二值標簽的分類系統被叫做多標簽分類系統。
目前我們不打算深入臉部識別。我們可以先看一個簡單點的例子,僅僅是為了闡明的目的。
from sklearn.neighbors import KNeighborsClassifier y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel)
這段代碼創造了一個y_multilabel數組,里面包含兩個目標標簽。第一個標簽指出這個數字是否為大數字(7,8 或者 9),第二個標簽指出這個數字是否是奇數。接下來幾行代碼會創建一個KNeighborsClassifier樣例(它支持多標簽分類,但不是所有分類器都可以),然后我們使用多目標數組來訓練它。現在你可以生成一個預測,然后它輸出兩個標簽:
>>> knn_clf.predict([some_digit]) array([[False, True]], dtype=bool)
它工作正確。數字 5 不是大數(False),同時是一個奇數(True)。
有許多方法去評估一個多標簽分類器,和選擇正確的量度標準,這取決于你的項目。舉個例子,一個方法是對每個個體標簽去量度 F1 值(或者前面討論過的其他任意的二分類器的量度標準),然后計算平均值。下面的代碼計算全部標簽的平均 F1 值:
>>> y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_train, cv=3) >>> f1_score(y_train, y_train_knn_pred, average="macro") 0.96845540180280221
這里假設所有標簽有著同等的重要性,但可能不是這樣。特別是,如果你的 Alice 的照片比 Bob 或者 Charlie 更多的時候,也許你想讓分類器在 Alice 的照片上具有更大的權重。一個簡單的選項是:給每一個標簽的權重等于它的支持度(比如,那個標簽的樣例的數目)。為了做到這點,簡單地在上面代碼中設置average="weighted"。
多輸出分類
我們即將討論的最后一種分類任務被叫做“多輸出-多類分類”(或者簡稱為多輸出分類)。它是多標簽分類的簡單泛化,在這里每一個標簽可以是多類別的(比如說,它可以有多于兩個可能值)。
為了說明這點,我們建立一個系統,它可以去除圖片當中的噪音。它將一張混有噪音的圖片作為輸入,期待它輸出一張干凈的數字圖片,用一個像素強度的數組表示,就像 MNIST 圖片那樣。注意到這個分類器的輸出是多標簽的(一個像素一個標簽)和每個標簽可以有多個值(像素強度取值范圍從 0 到 255)。所以它是一個多輸出分類系統的例子。
分類與回歸之間的界限是模糊的,比如這個例子。按理說,預測一個像素的強度更類似于一個回歸任務,而不是一個分類任務。而且,多輸出系統不限于分類任務。你甚至可以讓你一個系統給每一個樣例都輸出多個標簽,包括類標簽和值標簽。
讓我們從 MNIST 的圖片創建訓練集和測試集開始,然后給圖片的像素強度添加噪聲,這里是用 NumPy 的randint()函數。目標圖像是原始圖像。
noise = rnd.randint(0, 100, (len(X_train), 784)) noise = rnd.randint(0, 100, (len(X_test), 784)) X_train_mod = X_train + noise X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_test
讓我們看一下測試集當中的一張圖片(是的,我們在窺探測試集,所以你應該馬上鄒眉):
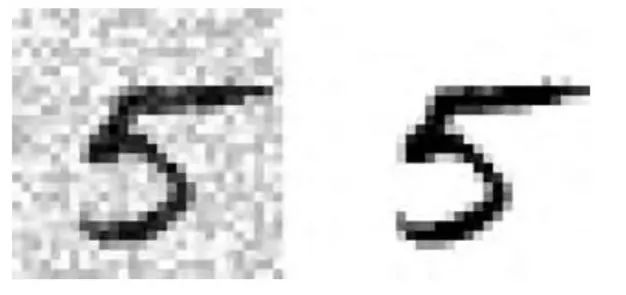
左邊的加噪聲的輸入圖片。右邊是干凈的目標圖片。現在我們訓練分類器,讓它清潔這張圖片:
knn_clf.fit(X_train_mod, y_train_mod) clean_digit = knn_clf.predict([X_test_mod[some_index]]) plot_digit(clean_digit)
看起來足夠接近目標圖片。現在總結我們的分類之旅。希望你現在應該知道如何選擇好的量度標準,挑選出合適的準確率/召回率的折衷方案,比較分類器,更概括地說,就是為不同的任務建立起好的分類系統。
練習
嘗試在 MNIST 數據集上建立一個分類器,使它在測試集上的精度超過 97%。提示:KNeighborsClassifier非常適合這個任務。你只需要找出一個好的超參數值(試一下對權重和超參數n_neighbors進行網格搜索)。
寫一個函數可以是 MNIST 中的圖像任意方向移動(上下左右)一個像素。然后,對訓練集上的每張圖片,復制四個移動后的副本(每個方向一個副本),把它們加到訓練集當中去。最后在擴展后的訓練集上訓練你最好的模型,并且在測試集上測量它的精度。你應該會觀察到你的模型會有更好的表現。這種人工擴大訓練集的方法叫做數據增強,或者訓練集擴張。
拿 Titanic 數據集去搗鼓一番。開始這個項目有一個很棒的平臺:Kaggle!
建立一個垃圾郵件分類器(這是一個更有挑戰性的練習):
下載垃圾郵件和非垃圾郵件的樣例數據。地址是Apache SpamAssassin 的公共數據集
解壓這些數據集,并且熟悉它的數據格式。
將數據集分成訓練集和測試集
寫一個數據準備的流水線,將每一封郵件轉換為特征向量。你的流水線應該將一封郵件轉換為一個稀疏向量,對于所有可能的詞,這個向量標志哪個詞出現了,哪個詞沒有出現。舉例子,如果所有郵件只包含了"Hello","How","are", "you"這四個詞,那么一封郵件(內容是:"Hello you Hello Hello you")將會被轉換為向量[1, 0, 0, 1](意思是:"Hello"出現,"How"不出現,"are"不出現,"you"出現),或者[3, 0, 0, 2],如果你想數出每個單詞出現的次數。
你也許想給你的流水線增加超參數,控制是否剝過郵件頭、將郵件轉換為小寫、去除標點符號、將所有 URL 替換成"URL",將所有數字替換成"NUMBER",或者甚至提取詞干(比如,截斷詞尾。有現成的 Python 庫可以做到這點)。
然后 嘗試幾個不同的分類器,看看你可否建立一個很棒的垃圾郵件分類器,同時有著高召回率和高準確率。
-
機器學習
+關注
關注
66文章
8408瀏覽量
132567 -
數據集
+關注
關注
4文章
1208瀏覽量
24689 -
tensorflow
+關注
關注
13文章
329瀏覽量
60528
原文標題:【翻譯】Sklearn 與 TensorFlow 機器學習實用指南 —— 第3章 分類(下)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【下載】《機器學習》+《機器學習實戰》
常用python機器學習庫盤點
如何使用Arm CMSIS-DSP實現經典機器學習庫
多標記學習的分類器圈方法
閾值分類器組合的多標簽分類算法
關于機器學習的相關分析介紹






 工商網監
工商網監
評論