

上一篇文章我們引出了GoogLeNet InceptionV1的網絡結構,這篇文章中我們會詳細講到Inception V2/V3/V4的發展歷程以及它們的網絡結構和亮點。
GoogLeNet Inception V2
GoogLeNet Inception V2在《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》出現,最大亮點是提出了Batch Normalization方法,它起到以下作用:
使用較大的學習率而不用特別關心諸如梯度爆炸或消失等優化問題;
降低了模型效果對初始權重的依賴;
可以加速收斂,一定程度上可以不使用Dropout這種降低收斂速度的方法,但卻起到了正則化作用提高了模型泛化性;
即使不使用ReLU也能緩解激活函數飽和問題;
能夠學習到從當前層到下一層的分布縮放( scaling (方差),shift (期望))系數。
在機器學習中,我們通常會做一種假設:訓練樣本獨立同分布(iid)且訓練樣本與測試樣本分布一致,如果真實數據符合這個假設則模型效果可能會不錯,反之亦然,這個在學術上叫Covariate Shift,所以從樣本(外部)的角度說,對于神經網絡也是一樣的道理。從結構(內部)的角度說,由于神經網絡由多層組成,樣本在層與層之間邊提特征邊往前傳播,如果每層的輸入分布不一致,那么勢必造成要么模型效果不好,要么學習速度較慢,學術上這個叫InternalCovariate Shift。
假設:y為樣本標注,X={x1,x2,x3,......}為樣本x
通過神經網絡若干層后每層的輸入;
理論上:p(x,y)的聯合概率分布應該與集合X中任意一層輸入的聯合概率分布一致,如:p(x,y)=p(x1,y);
但是:p(x,y)=p(y|x)?p(x),其中條件概率p(y|x)是一致的,即p(y|x)=p(y|x1)=p(y|x1)=......,但由于神經網絡每一層對輸入分布的改變,導致邊緣概率是不一致的,即p(x)≠p(x1)≠p(x2)......,甚至隨著網絡深度的加深,前面層微小的變化會導致后面層巨大的變化。
BN整個算法過程如下:

以batch的方式做訓練,對m個樣本求期望和方差后對訓練數據做白化,通過白化操作可以去除特征相關性并把數據縮放在一個球體上,這么做的好處既可以加快優化算法的優化速度也可能提高優化精度,一個直觀的解釋:
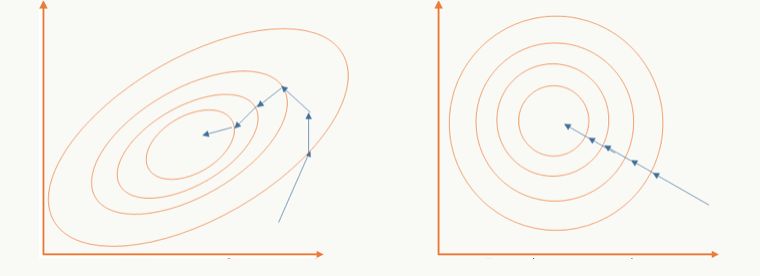
左邊是未做白化的原始可行域,右邊是做了白化的可行域;
當原始輸入對模型學習更有利時能夠恢復原始輸入(和殘差網絡有點神似):
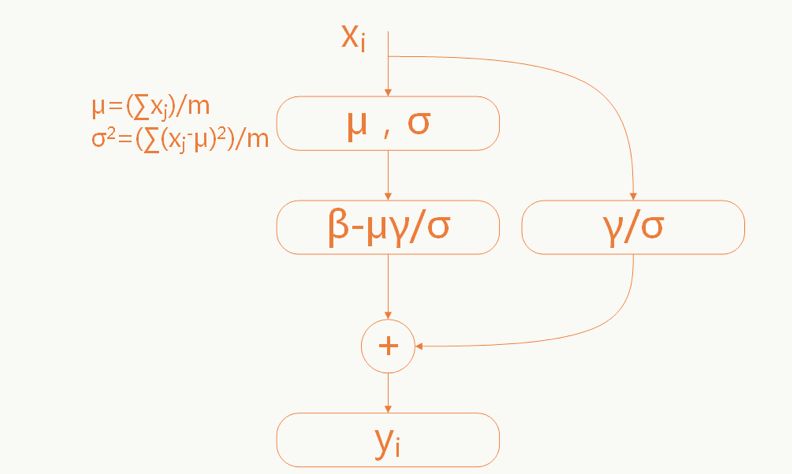
這里的參數γ和σ是需要學習的。
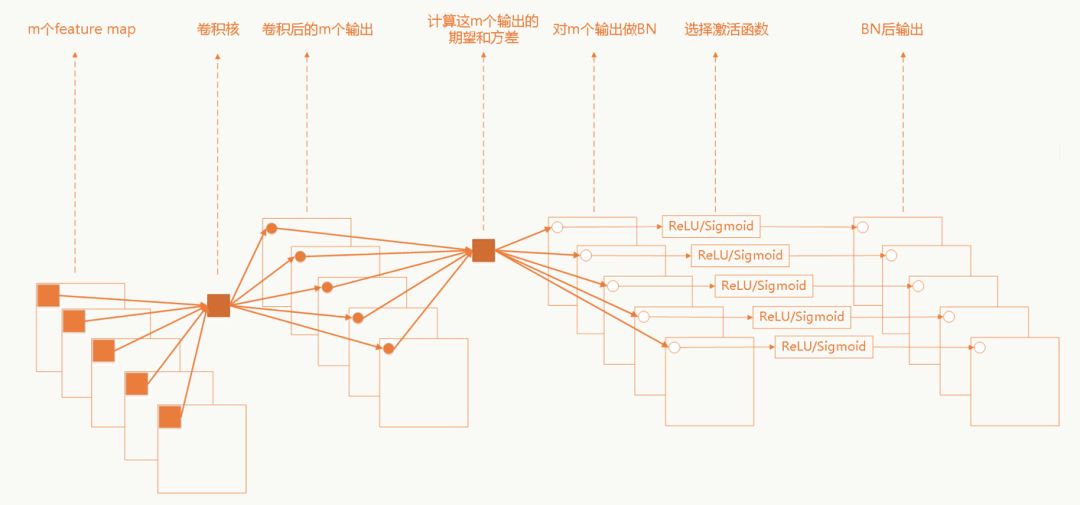
卷積神經網絡中的BN
卷積網絡中采用權重共享策略,每個feature map只有一對γ和σ需要學習。
GoogLeNet Inception V3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出(注意,在這篇論文中作者把該網絡結構叫做v2版,我們以最終的v4版論文的劃分為標準),該論文的亮點在于:
提出通用的網絡結構設計準則
引入卷積分解提高效率
引入高效的feature map降維
網絡結構設計的準則
前面也說過,深度學習網絡的探索更多是個實驗科學,在實驗中人們總結出一些結構設計準則,但說實話我覺得不一定都有實操性:
避免特征表示上的瓶頸,尤其在神經網絡的前若干層
神經網絡包含一個自動提取特征的過程,例如多層卷積,直觀并符合常識的理解:如果在網絡初期特征提取的太粗,細節已經丟了,后續即使結構再精細也沒法做有效表示了;舉個極端的例子:在宇宙中辨別一個星球,正常來說是通過由近及遠,從房屋、樹木到海洋、大陸板塊再到整個星球之后進入整個宇宙,如果我們一開始就直接拉遠到宇宙,你會發現所有星球都是球體,沒法區分哪個是地球哪個是水星。所以feature map的大小應該是隨著層數的加深逐步變小,但為了保證特征能得到有效表示和組合其通道數量會逐漸增加。
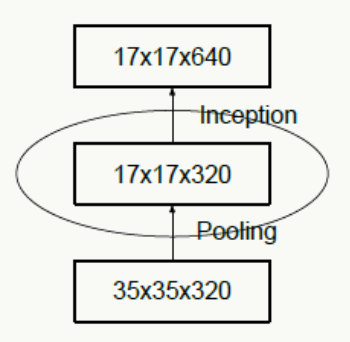
下圖違反了這個原則,剛開就始直接從35×35×320被抽樣降維到了17×17×320,特征細節被大量丟失,即使后面有Inception去做各種特征提取和組合也沒用。
對于神經網絡的某一層,通過更多的激活輸出分支可以產生互相解耦的特征表示,從而產生高階稀疏特征,從而加速收斂,注意下圖的1×3和3×1激活輸出:
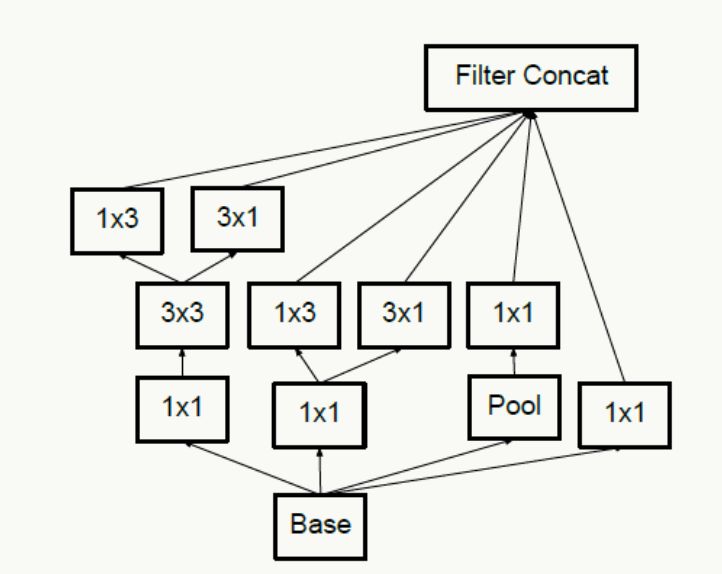
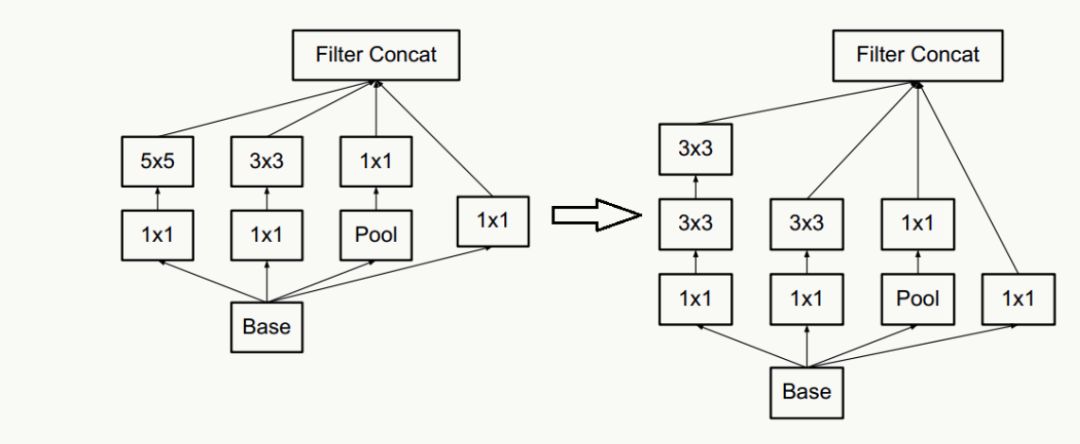
合理使用維度縮減不會破壞網絡特征表示能力反而能加快收斂速度,典型的例如通過兩個3×3代替一個5×5的降維策略,不考慮padding,用兩個3×3代替一個5×5能節省1-(3×3+3×3)/(5×5)=28%的計算消耗。
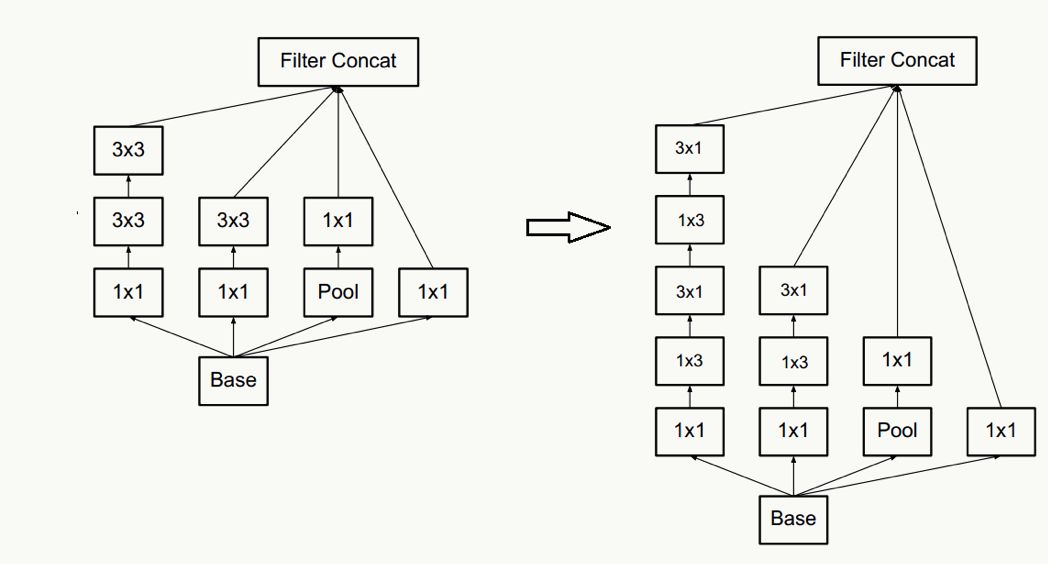
以及一個n×n卷積核通過順序相連的兩個1×n和n×1做降維(有點像矩陣分解),如果n=3,計算性能可以提升1-(3+3)/9=33%,但如果考慮高性能計算性能,這種分解可能會造成L1 cache miss率上升。
通過合理平衡網絡的寬度和深度優化網絡計算消耗(這句話尤其不具有實操性)。
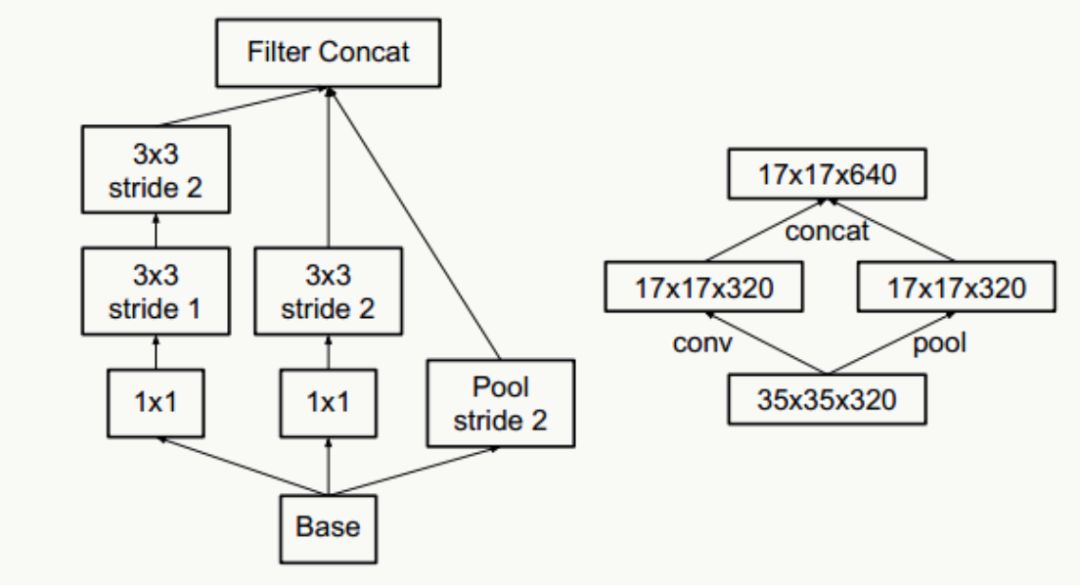
抽樣降維,傳統抽樣方法為pooling+卷積操作,為了防止出現特征表示的瓶頸,往往需要更多的卷積核,例如輸入為n個d×d的feature map,共有k個卷積核,pooling時stride=2,為不出現特征表示瓶頸,往往k的取值為2n,通過引入inception module結構,即降低計算復雜度,又不會出現特征表示瓶頸,實現上有如下兩種方式:
平滑樣本標注
對于多分類的樣本標注一般是one-hot的,例如[0,0,0,1],使用類似交叉熵的損失函數會使得模型學習中對ground truth標簽分配過于置信的概率,并且由于ground truth標簽的logit值與其他標簽差距過大導致,出現過擬合,導致降低泛化性。一種解決方法是加正則項,即對樣本標簽給個概率分布做調節,使得樣本標注變成“soft”的,例如[0.1,0.2,0.1,0.6],這種方式在實驗中降低了top-1和top-5的錯誤率0.2%。
網絡結構
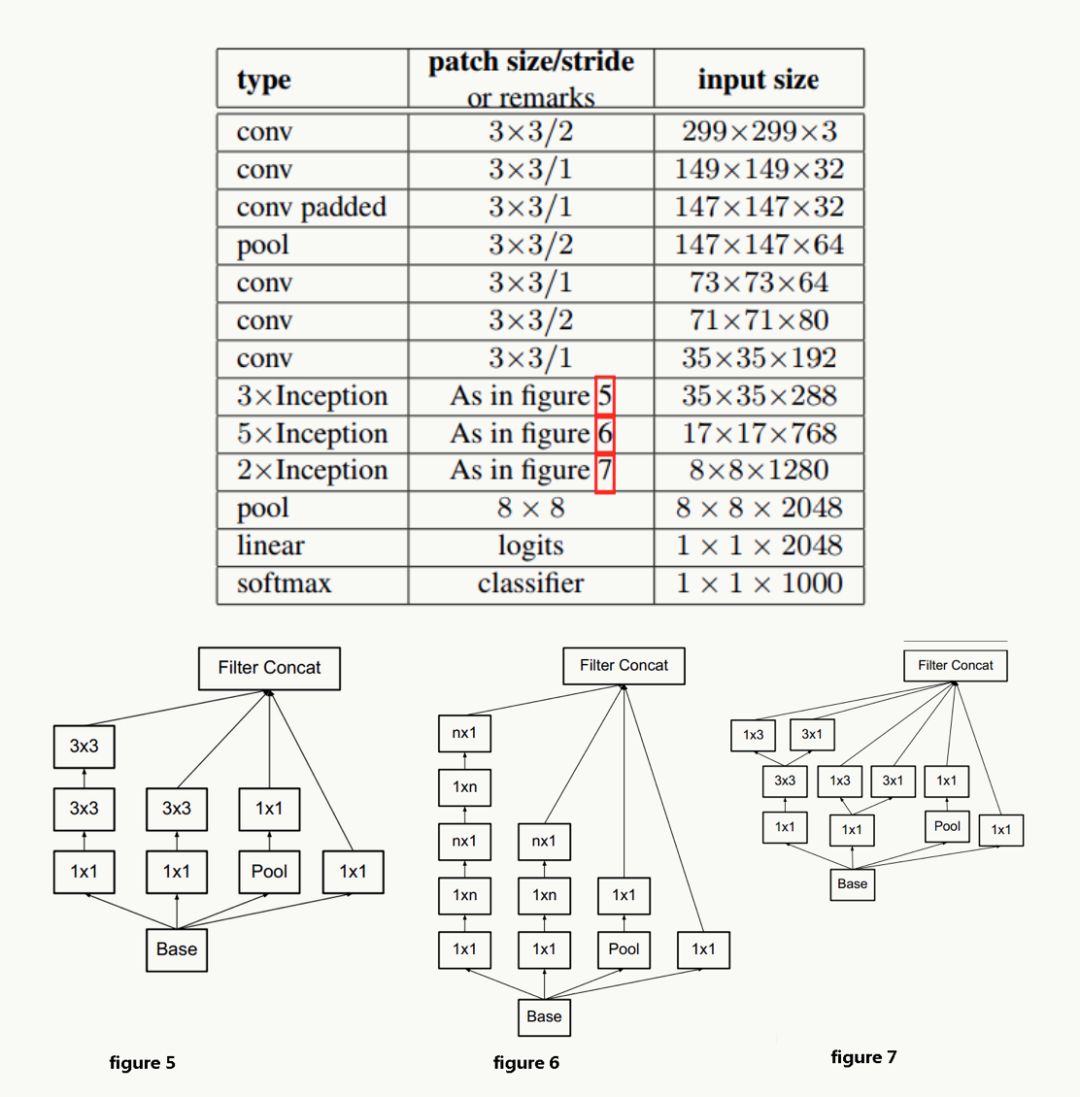
GoogLeNet Inception V4
GoogLeNet Inception V4/和ResNet V1/V2這三種結構在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》一文中提出,論文的亮點是:提出了效果更好的GoogLeNet Inception v4網絡結構;與殘差網絡融合,提出效果不遜于v4但訓練速度更快的結構。
GoogLeNet Inception V4網絡結構
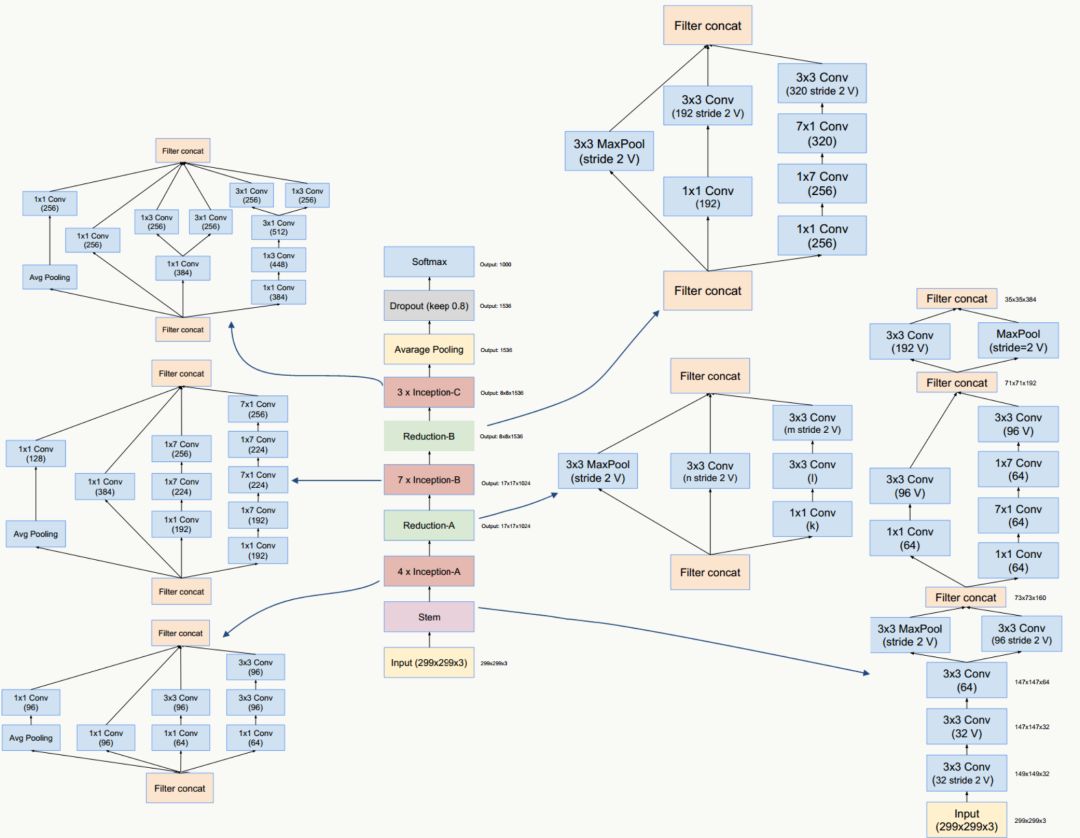
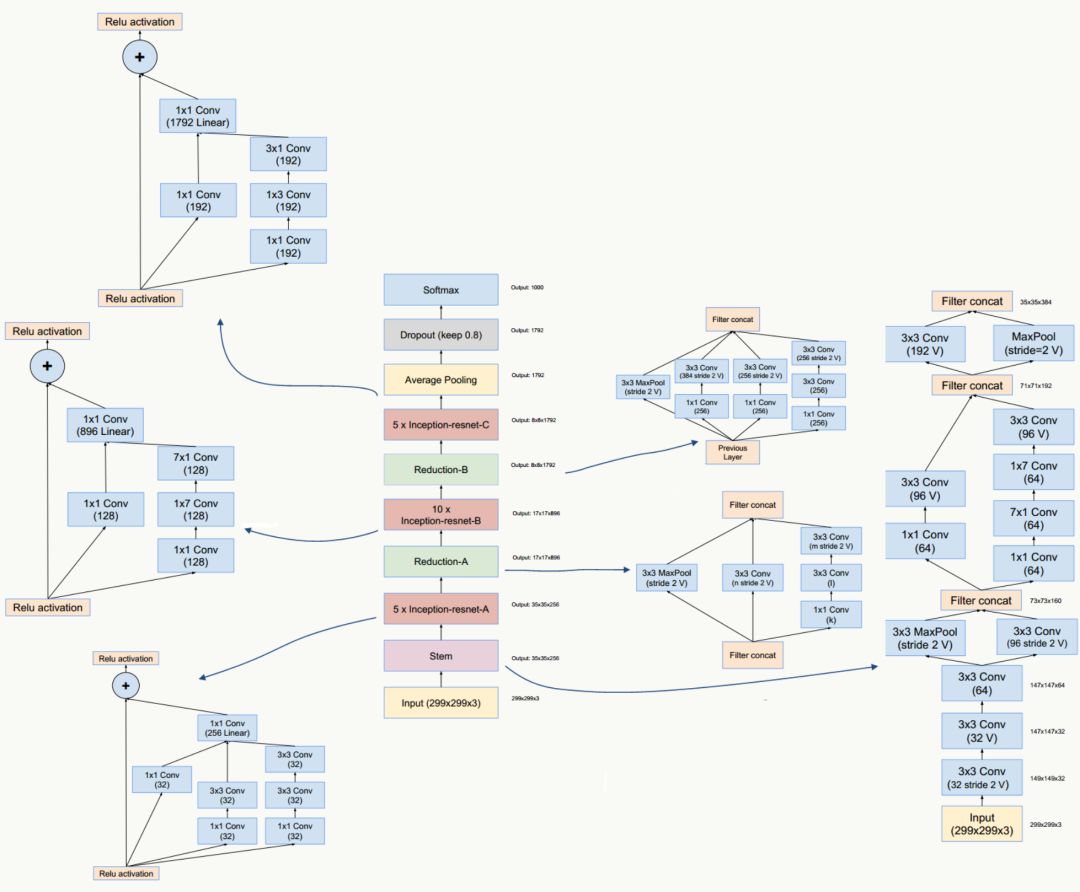
GoogLeNet Inception ResNet網絡結構
代碼實踐
Tensorflow的代碼在slim模塊下有完整的實現,paddlepaddle的可以參考上篇文章中寫的inception v1的代碼來寫。
總結
這篇文章比較偏理論,主要講了GoogLeNet的inception模塊的發展,包括在v2中提出的batch normalization,v3中提出的卷積分級與更通用的網絡結構準則,v4中的與殘差網絡結合等,在實際應用過程中可以可以對同一份數據用不同的網絡結構跑一跑,看看結果如何,實際體驗一下不同網絡結構的loss下降速率,對準確率的提升等。
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102921 -
機器學習
+關注
關注
66文章
8493瀏覽量
134168
原文標題:【深度學習系列】用PaddlePaddle和Tensorflow實現GoogLeNet InceptionV2/V3/V4
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
僅采用四只N溝道場效應管的全橋驅動電路
淺析SDIO協議V2和V3版本的區別
ESP devkitc v3與v4和CAN網絡之間有什么不同?
采用兩只N溝道和兩只P溝道場效應管的全橋驅動電路
Open AI推出神經元可視化庫Microscope
ProDOS ROM-Drive v3-替換為v4開源分享

基于YOLO-V5的網絡結構及實現行人社交距離風險提示
NodeMCU V2 Amica V3 Lolin的盾牌





 工商網監
工商網監

評論