

據(jù)外媒CNET報(bào)道,創(chuàng)建一個(gè)可以解開(kāi)魔方的算法相對(duì)簡(jiǎn)單。但是,如果在沒(méi)有人類幫助的情況下解開(kāi)魔方可能是一個(gè)完全不同的任務(wù)。加利福尼亞大學(xué)的Stephen McAleer和他的同事們認(rèn)為他們已經(jīng)解決了這個(gè)問(wèn)題,并采用了一個(gè)稱為“自學(xué)的漸進(jìn)迭代”的過(guò)程。
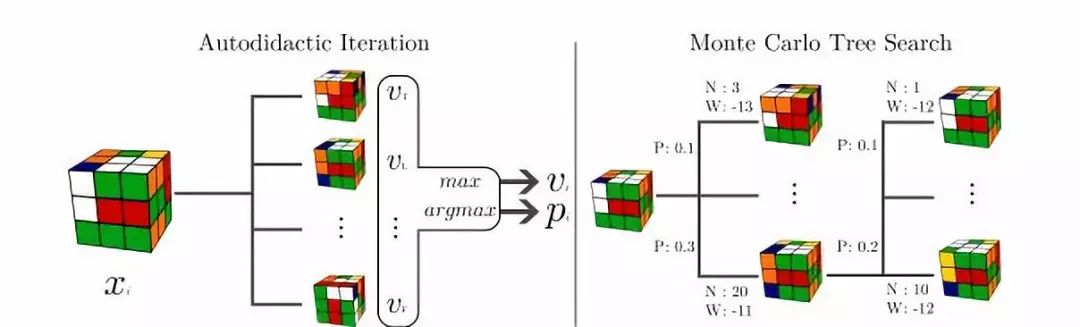
McAleer和他的團(tuán)隊(duì)稱這個(gè)過(guò)程為“一種新型的強(qiáng)化學(xué)習(xí)算法,能夠教導(dǎo)算法如何在沒(méi)有人類協(xié)助的情況下解開(kāi)魔方。” 他們聲稱,這種學(xué)習(xí)算法可以在30步內(nèi)解開(kāi)100%的隨機(jī)打亂魔方 - 這和人類的表現(xiàn)不相上下或優(yōu)于人類的表現(xiàn)。
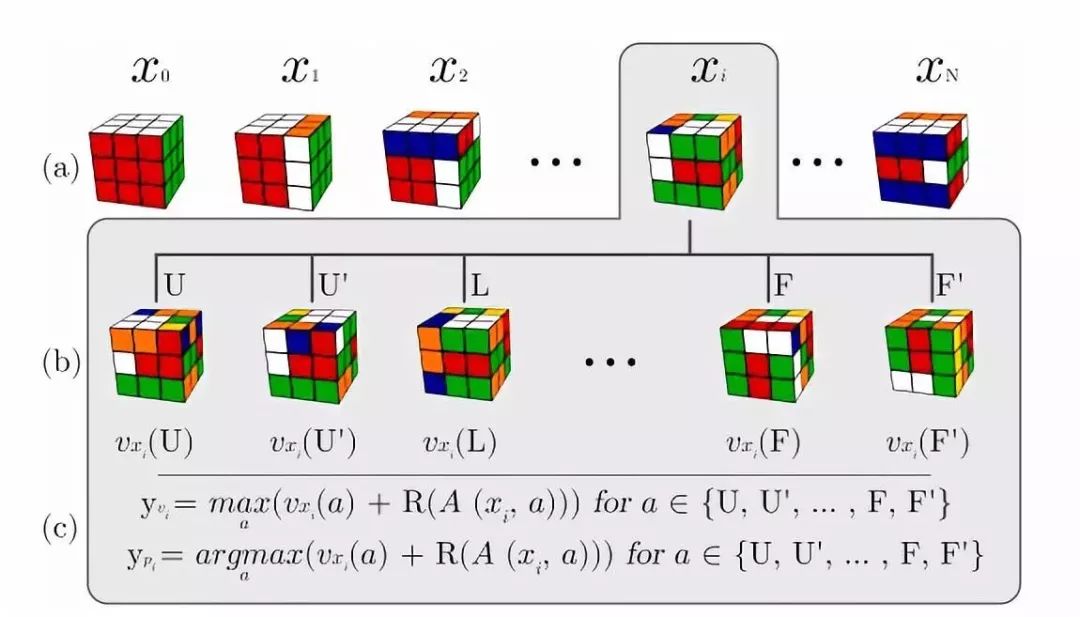
這種類型的算法與在棋類游戲中超越人類表現(xiàn)的算法有區(qū)別。這些系統(tǒng)是“強(qiáng)化學(xué)習(xí)”系統(tǒng)。這個(gè)系統(tǒng)在完成解魔方后會(huì)查看是否每個(gè)提議的步驟都是一種改進(jìn)。
-
算法
+關(guān)注
關(guān)注
23文章
4657瀏覽量
93933 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11407
原文標(biāo)題:GGAI 前沿 | 機(jī)器學(xué)習(xí)算法現(xiàn)在可以在沒(méi)有人類幫助的情況下解開(kāi)魔方
文章出處:【微信號(hào):ggservicerobot,微信公眾號(hào):高工智能未來(lái)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
什么是深度強(qiáng)化學(xué)習(xí)?深度強(qiáng)化學(xué)習(xí)算法應(yīng)用分析

深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
強(qiáng)化學(xué)習(xí)和監(jiān)督式學(xué)習(xí), 非監(jiān)督式學(xué)習(xí)的區(qū)別
基于強(qiáng)化學(xué)習(xí)的MADDPG算法原理及實(shí)現(xiàn)
量化深度強(qiáng)化學(xué)習(xí)算法的泛化能力

懶惰強(qiáng)化學(xué)習(xí)算法在發(fā)電調(diào)控REG框架的應(yīng)用
基于PPO強(qiáng)化學(xué)習(xí)算法的AI應(yīng)用案例
機(jī)器學(xué)習(xí)中的無(wú)模型強(qiáng)化學(xué)習(xí)算法及研究綜述

基于強(qiáng)化學(xué)習(xí)的偽裝攻擊檢測(cè)算法
強(qiáng)化學(xué)習(xí)的基礎(chǔ)知識(shí)和6種基本算法解釋
7個(gè)流行的強(qiáng)化學(xué)習(xí)算法及代碼實(shí)現(xiàn)
強(qiáng)化學(xué)習(xí)的基礎(chǔ)知識(shí)和6種基本算法解釋

基于強(qiáng)化學(xué)習(xí)的目標(biāo)檢測(cè)算法案例
在沒(méi)有人機(jī)界面的情況下,應(yīng)如何配置設(shè)備?





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論