") 用淺顯的語言帶領(lǐng)大家了解可解釋性的概念與方法
用淺顯的語言帶領(lǐng)大家了解可解釋性的概念與方法
01
深度學(xué)習(xí)的可解釋性研究(一)
讓模型具備說人話的能力
▌可解釋性是什么?
廣義上的可解釋性指在我們需要了解或解決一件事情的時(shí)候,我們可以獲得我們所需要的足夠的可以理解的信息。
比如我們?cè)谡{(diào)試bug的時(shí)候,需要通過變量審查和日志信息定位到問題出在哪里。比如在科學(xué)研究中面臨一個(gè)新問題的研究時(shí),我們需要查閱一些資料來了解這個(gè)新問題的基本概念和研究現(xiàn)狀,以獲得對(duì)研究方向的正確認(rèn)識(shí)。
反過來理解,如果在一些情境中我們無法得到相應(yīng)的足夠的信息,那么這些事情對(duì)我們來說都是不可解釋的。比如劉慈欣的短篇《朝聞道》中霍金提出的“宇宙的目的是什么”這個(gè)問題一下子把無所不知的排險(xiǎn)者卡住了,因?yàn)樵俑叩鹊奈拿鞫紱]辦法理解和掌握造物主創(chuàng)造宇宙時(shí)的全部信息,這些終極問題對(duì)我們來說永遠(yuǎn)都是不可解釋的。
而具體到機(jī)器學(xué)習(xí)領(lǐng)域來說,以最用戶友好的決策樹模型為例,模型每作出一個(gè)決策都會(huì)通過一個(gè)決策序列來向我們展示模型的決策依據(jù):比如男性&未婚&博士&禿頭的條件對(duì)應(yīng)“不感興趣”這個(gè)決策,而且決策樹模型自帶的基于信息理論的篩選變量標(biāo)準(zhǔn)也有助于幫助我們理解在模型決策產(chǎn)生的過程中哪些變量起到了顯著的作用。
所以在一定程度上,我們認(rèn)為決策樹模型是一個(gè)具有比較好的可解釋性的模型,在以后的介紹中我們也會(huì)講到,以決策樹為代表的規(guī)則模型在可解釋性研究方面起到了非常關(guān)鍵的作用。
再以用戶最不友好的多層神經(jīng)網(wǎng)絡(luò)模型為例,模型產(chǎn)生決策的依據(jù)是什么呢?大概是以比如 1/(e^-(2*1/(e^(-(2*x+y))+1) + 3*1/(e^(-(8*x+5*y))+1))+1) 是否大于0.5為標(biāo)準(zhǔn)(這已經(jīng)是最簡單的模型結(jié)構(gòu)了),這一連串的非線性函數(shù)的疊加公式讓人難以直接理解神經(jīng)網(wǎng)絡(luò)的“腦回路”,所以深度神經(jīng)網(wǎng)絡(luò)習(xí)慣性被大家認(rèn)為是黑箱模型。
17年ICML的Tutorial中給出的一個(gè)關(guān)于可解釋性的定義是:Interpretation is the process of giving explanationsto Human.
總結(jié)一下就是“說人話”,“說人話”,“說人話”,不以人類可以理解的方式給出的解釋都叫耍流氓,記住這三個(gè)字,你就差不多把握了可解釋性的精髓所在。
▌我們?yōu)槭裁葱枰山忉屝裕?/p>
廣義上來說我們對(duì)可解釋性的需求主要來源于對(duì)問題和任務(wù)了解得還不夠充分。具體到深度學(xué)習(xí)/機(jī)器學(xué)習(xí)領(lǐng)域,就像我們上文提到的多層神經(jīng)網(wǎng)絡(luò)存在的問題,盡管高度的非線性賦予了多層神經(jīng)網(wǎng)絡(luò)極高的模型表示能力,配合一些堪稱現(xiàn)代煉丹術(shù)的調(diào)參技術(shù)可以在很多問題上達(dá)到非常喜人的表現(xiàn),大家如果經(jīng)常關(guān)注AI的頭條新聞,那些機(jī)器學(xué)習(xí)和神經(jīng)網(wǎng)絡(luò)不可思議的最新突破甚至經(jīng)常會(huì)讓人產(chǎn)生AI馬上要取代人類的恐懼和幻覺。
但正如近日貝葉斯網(wǎng)絡(luò)的創(chuàng)始人Pearl所指出的,“幾乎所有的深度學(xué)習(xí)突破性的本質(zhì)上來說都只是些曲線擬合罷了”,他認(rèn)為今天人工智能領(lǐng)域的技術(shù)水平只不過是上一代機(jī)器已有功能的增強(qiáng)版。
雖然我們?cè)斐隽藴?zhǔn)確度極高的機(jī)器,但最后只能得到一堆看上去毫無意義的模型參數(shù)和擬合度非常高的判定結(jié)果,但實(shí)際上模型本身也意味著知識(shí),我們希望知道模型究竟從數(shù)據(jù)中學(xué)到了哪些知識(shí)(以人類可以理解的方式表達(dá)的)從而產(chǎn)生了最終的決策。從中是不是可以幫助我們發(fā)現(xiàn)一些潛在的關(guān)聯(lián),比如我想基于深度學(xué)習(xí)模型開發(fā)一個(gè)幫助醫(yī)生判定病人風(fēng)險(xiǎn)的應(yīng)用,除了最終的判定結(jié)果之外,我可能還需要了解模型產(chǎn)生這樣的判定是基于病人哪些因素的考慮。如果一個(gè)模型完全不可解釋,那么在很多領(lǐng)域的應(yīng)用就會(huì)因?yàn)闆]辦法給出更多可靠的信息而受到限制。這也是為什么在深度學(xué)習(xí)準(zhǔn)確率這么高的情況下,仍然有一大部分人傾向于應(yīng)用可解釋性高的傳統(tǒng)統(tǒng)計(jì)學(xué)模型的原因。
不可解釋同樣也意味著危險(xiǎn),事實(shí)上很多領(lǐng)域?qū)ι疃葘W(xué)習(xí)模型應(yīng)用的顧慮除了模型本身無法給出足夠的信息之外,也有或多或少關(guān)于安全性的考慮。比如,下面一個(gè)非常經(jīng)典的關(guān)于對(duì)抗樣本的例子,對(duì)于一個(gè)CNN模型,在熊貓的圖片中添加了一些噪聲之后卻以99.3%的概率被判定為長臂猿。
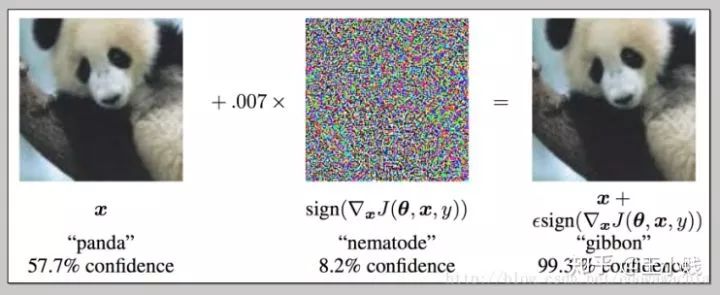
在熊貓圖片中加入噪聲,模型以99.3%的概率將圖片識(shí)別為長臂猿
事實(shí)上其他一些可解釋性較好的模型面對(duì)的對(duì)抗樣本問題可能甚至比深度學(xué)習(xí)模型更多,但具備可解釋性的模型在面對(duì)這些問題的時(shí)候是可以對(duì)異常產(chǎn)生的原因進(jìn)行追蹤和定位的,比如線性回歸模型中我們可以發(fā)現(xiàn)某個(gè)輸入?yún)?shù)過大/過小導(dǎo)致了最后判別失常。但深度學(xué)習(xí)模型很難說上面這兩幅圖到底是因?yàn)槟男﹨^(qū)別導(dǎo)致了判定結(jié)果出現(xiàn)了如此大的偏差。盡管關(guān)于對(duì)抗樣本的研究最近也非常火熱,但依然缺乏具備可解釋性的關(guān)于這類問題的解釋。
當(dāng)然很多學(xué)者對(duì)可解釋性的必要性也存有疑惑,在NIPS 2017會(huì)場上,曾進(jìn)行了一場非常激烈火爆的主題為“可解釋性在機(jī)器學(xué)習(xí)中是否必要”的辯論,大家對(duì)可解釋性的呼聲還是非常高的。
但人工智能三巨頭之一的Yann LeCun卻認(rèn)為:人類大腦是非常有限的,我們沒有那么多腦容量去研究所有東西的可解釋性。有些東西是需要解釋的,比如法律,但大多數(shù)情況下,它們并沒有你想象中那么重要。比如世界上有那么多應(yīng)用、網(wǎng)站,你每天用Facebook、Google的時(shí)候,你也沒想著要尋求它們背后的可解釋性。
LeCun也舉了一個(gè)例子:他多年前和一群經(jīng)濟(jì)學(xué)家也做了一個(gè)模型來預(yù)測房價(jià)。第一個(gè)用的簡單的線性于猜測模型,經(jīng)濟(jì)學(xué)家也能解釋清楚其中的原理;第二個(gè)用的是復(fù)雜的神經(jīng)網(wǎng)絡(luò),但效果比第一個(gè)好上不少。結(jié)果,這群經(jīng)濟(jì)學(xué)家想要開公司做了。你說他們會(huì)選哪個(gè)?LeCun表示,任何時(shí)候在這兩種里面選擇都會(huì)選效果好的。就像很多年里雖然我們不知道藥物里的成分但一直在用一樣。
但是不可否認(rèn)的是,可解釋性始終是一個(gè)非常好的性質(zhì),如果我們能兼顧效率、準(zhǔn)確度、說人話這三個(gè)方面,具備可解釋性模型將在很多應(yīng)用場景中具有不可替代的優(yōu)勢。
有哪些可解釋性方法?
我們之前也提到機(jī)器學(xué)習(xí)的目的是從數(shù)據(jù)中發(fā)現(xiàn)知識(shí)或解決問題,那么在這個(gè)過程中只要是能夠提供給我們關(guān)于數(shù)據(jù)或模型的可以理解的信息,有助于我們更充分地發(fā)現(xiàn)知識(shí)、理解和解決問題的方法,那么都可以歸類為可解釋性方法。如果按照可解釋性方法進(jìn)行的過程進(jìn)行劃分的話,大概可以劃分為三個(gè)大類:
1. 在建模之前的可解釋性方法
2. 建立本身具備可解釋性的模型
3. 在建模之后使用可解釋性方法對(duì)模型作出解釋
▌在建模之前的可解釋性方法
這一類方法其實(shí)主要涉及一些數(shù)據(jù)預(yù)處理或數(shù)據(jù)展示的方法。機(jī)器學(xué)習(xí)解決的是從數(shù)據(jù)中發(fā)現(xiàn)知識(shí)和規(guī)律的問題,如果我們對(duì)想要處理的數(shù)據(jù)特征所知甚少,指望對(duì)所要解決的問題本身有很好的理解是不現(xiàn)實(shí)的,在建模之前的可解釋性方法的關(guān)鍵在于幫助我們迅速而全面地了解數(shù)據(jù)分布的特征,從而幫助我們考慮在建模過程中可能面臨的問題并選擇一種最合理的模型來逼近問題所能達(dá)到的最優(yōu)解。
數(shù)據(jù)可視化方法就是一類非常重要的建模前可解釋性方法。很多對(duì)數(shù)據(jù)挖掘稍微有些了解的人可能會(huì)認(rèn)為數(shù)據(jù)可視化是數(shù)據(jù)挖掘工作的最后一步,大概就是通過設(shè)計(jì)一些好看又唬人的圖表或來展示你的分析挖掘成果。但大多數(shù)時(shí)候,我們?cè)谡嬲芯恳粋€(gè)數(shù)據(jù)問題之前,通過建立一系列方方面面的可視化方法來建立我們對(duì)數(shù)據(jù)的直觀理解是非常必須的,特別是當(dāng)數(shù)據(jù)量非常大或者數(shù)據(jù)維度非常高的時(shí)候,比如一些時(shí)空高維數(shù)據(jù),如果可以建立一些一些交互式的可視化方法將會(huì)極大地幫助我們從各個(gè)層次角度理解數(shù)據(jù)的分布,在這個(gè)方面我們實(shí)驗(yàn)室也做過一些非常不錯(cuò)的工作。
還有一類比較重要的方法是探索性質(zhì)的數(shù)據(jù)分析,可以幫助我們更好地理解數(shù)據(jù)的分布情況。比如一種稱為MMD-critic方法中,可以幫助我們找到數(shù)據(jù)中一些具有代表性或者不具代表性的樣本。

使用MMD-critic從Imagenet數(shù)據(jù)集中學(xué)到的代表性樣本和非代表性樣本(以兩種狗為例)
▌建立本身具備可解釋性的模型
建立本身具備可解釋性的模型是我個(gè)人覺得是最關(guān)鍵的一類可解釋性方法,同樣也是一類要求和限定很高的方法,具備“說人話”能力的可解釋性模型大概可以分為以下幾種:
1. 基于規(guī)則的方法(Rule-based)
2. 基于單個(gè)特征的方法(Per-feature-based)
3. 基于實(shí)例的方法(Case-based)
4. 稀疏性方法(Sparsity)
5. 單調(diào)性方法(Monotonicity)
基于規(guī)則的方法比如我們提到的非常經(jīng)典的決策樹模型。這類模型中任何的一個(gè)決策都可以對(duì)應(yīng)到一個(gè)邏輯規(guī)則表示。但當(dāng)規(guī)則表示過多或者原始的特征本身就不是特別好解釋的時(shí)候,基于規(guī)則的方法有時(shí)候也不太適用。
基于單個(gè)特征的方法主要是一些非常經(jīng)典的線性模型,比如線性回歸、邏輯回歸、廣義線性回歸、廣義加性模型等,這類模型可以說是現(xiàn)在可解釋性最高的方法,可能學(xué)習(xí)機(jī)器學(xué)習(xí)或計(jì)算機(jī)相關(guān)專業(yè)的朋友會(huì)認(rèn)為線性回歸是最基本最低級(jí)的模型,但如果大家學(xué)過計(jì)量經(jīng)濟(jì)學(xué),就會(huì)發(fā)現(xiàn)大半本書都在討論線性模型,包括經(jīng)濟(jì)學(xué)及相關(guān)領(lǐng)域的論文其實(shí)大多數(shù)也都是使用線性回歸作為方法來進(jìn)行研究。
這種非常經(jīng)典的模型全世界每秒都會(huì)被用到大概800多萬次。為什么大家這么青睞這個(gè)模型呢?除了模型的結(jié)構(gòu)比較簡單之外,更重要的是線性回歸模型及其一些變種擁有非常solid的統(tǒng)計(jì)學(xué)基礎(chǔ),統(tǒng)計(jì)學(xué)可以說是最看重可解釋性的一門學(xué)科了,上百年來無數(shù)數(shù)學(xué)家統(tǒng)計(jì)學(xué)家探討了在各種不同情況下的模型的參數(shù)估計(jì)、參數(shù)修正、假設(shè)檢驗(yàn)、邊界條件等等問題,目的就是為了使得在各種不同情況下都能使模型具有有非常好的可解釋性,如果大家有時(shí)間有興趣的話,除了學(xué)習(xí)機(jī)器學(xué)習(xí)深度模型模型之外還可以盡量多了解一些統(tǒng)計(jì)學(xué)的知識(shí),可能對(duì)一些問題會(huì)獲得完全不一樣的思考和理解。
基于實(shí)例的方法主要是通過一些代表性的樣本來解釋聚類/分類結(jié)果的方法。比如下圖所展示的貝葉斯實(shí)例模型(Bayesian Case Model,BCM),我們將樣本分成三個(gè)組團(tuán),可以分別找出每個(gè)組團(tuán)中具有的代表性樣例和重要的子空間。比如對(duì)于下面第一類聚類來說,綠臉是具有代表性的樣本,而綠色、方塊是具有代表性的特征子空間。
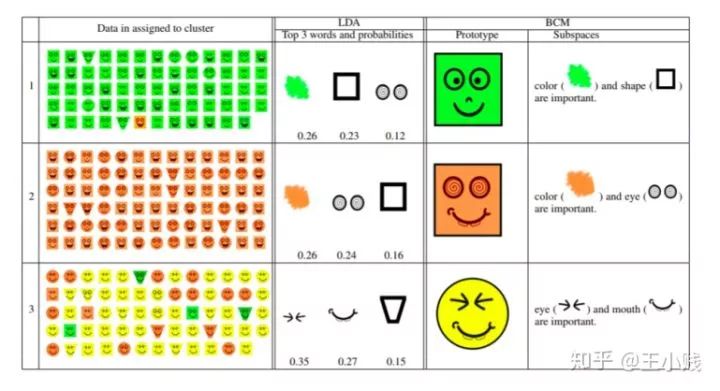
使用BCM學(xué)到的分類及其對(duì)應(yīng)的代表性樣本和代表性特征子空間
基于實(shí)例的方法的一些局限在于可能挑出來的樣本不具有代表性或者人們可能會(huì)有過度泛化的傾向。
基于稀疏性的方法主要是利用信息的稀疏性特質(zhì),將模型盡可能地簡化表示。比如如下圖的一種圖稀疏性的LDA方法,根據(jù)層次性的單詞信息形成了層次性的主題表達(dá),這樣一些小的主題就可以被更泛化的主題所概括,從而可以使我們更容易理解特定主題所代表的含義。
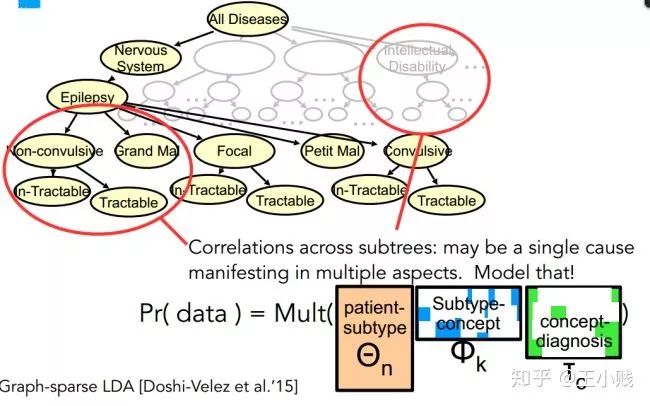
Graph-based LDA 中的主題層次結(jié)構(gòu)
基于單調(diào)性的方法:在很多機(jī)器學(xué)習(xí)問題中,有一些輸入和輸出之間存在正相關(guān)/負(fù)相關(guān)關(guān)系,如果在模型訓(xùn)練中我們可以找出這種單調(diào)性的關(guān)系就可以讓模型具有更高的可解釋性。比如醫(yī)生對(duì)患特定疾病的概率的估計(jì)主要由一些跟該疾病相關(guān)聯(lián)的高風(fēng)險(xiǎn)因素決定,找出單調(diào)性關(guān)系就可以幫助我們識(shí)別這些高風(fēng)險(xiǎn)因素。
▌在建模之后使用可解釋性性方法作出解釋
建模后的可解釋性方法主要是針對(duì)具有黑箱性質(zhì)的深度學(xué)習(xí)模型而言的,主要分為以下幾類的工作:
1. 隱層分析方法
2. 模擬/代理模型
3. 敏感性分析方法
這部分是我們接下來介紹和研究的重點(diǎn),因此主要放在后續(xù)的文章中進(jìn)行講解,在本篇中不作過多介紹。
除了對(duì)深度學(xué)習(xí)模型本身進(jìn)行解釋的方法之外,也有一部分工作旨在建立本身具有可解釋性的深度學(xué)習(xí)模型,這和我們前面介紹通用的可解釋性模型有區(qū)別也有聯(lián)系,也放到以后的文章中進(jìn)行介紹。
02
深度學(xué)習(xí)的可解釋性研究(二)
不如打開箱子看一看
在上一節(jié)中我們介紹了深度學(xué)習(xí)可解釋性的三種方法:1. 隱層分析法,2. 敏感性分析法 3. 代理/替代模型法。在這一節(jié)中我們主要介紹第一種方法:隱層分析法。
▌黑箱真的是黑箱嗎?——深度學(xué)習(xí)的物質(zhì)組成視角
通過上一節(jié)的介紹我們也了解到,深度學(xué)習(xí)的黑箱性主要來源于其高度非線性性質(zhì),每個(gè)神經(jīng)元都是由上一層的線性組合再加上一個(gè)非線性函數(shù)的得到,我們無法像理解線性回歸的參數(shù)那樣通過非常solid的統(tǒng)計(jì)學(xué)基礎(chǔ)假設(shè)來理解神經(jīng)網(wǎng)絡(luò)中的參數(shù)含義及其重要程度、波動(dòng)范圍。
但實(shí)際上我們是知道這些參數(shù)的具體值以及整個(gè)訓(xùn)練過程的,所以神經(jīng)網(wǎng)絡(luò)模型本身其實(shí)并不是一個(gè)黑箱,其黑箱性在于我們沒辦法用人類可以理解的方式理解模型的具體含義和行為,而神經(jīng)網(wǎng)絡(luò)的一個(gè)非常好的性質(zhì)在于神經(jīng)元的分層組合形式,這讓我們可以用物質(zhì)組成的視角來理解神經(jīng)網(wǎng)絡(luò)的運(yùn)作方式。比如如下圖所示,人體的組成過程是從分子-細(xì)胞-組織-器官-系統(tǒng)-人體:
人體的組成結(jié)構(gòu)示意
而通過一些對(duì)神經(jīng)網(wǎng)絡(luò)隱層的可視化我們也發(fā)現(xiàn):比如下圖的一個(gè)人臉識(shí)別的例子,神經(jīng)網(wǎng)絡(luò)在這個(gè)過程中先學(xué)到了邊角的概念,之后學(xué)到了五官,最后學(xué)到了整個(gè)面部的特征。
(以上內(nèi)容參考了@YJango在如何簡單形象又有趣地講解神經(jīng)網(wǎng)絡(luò)是什么?中的回答,侵刪)
如果我們能夠用一些方法來幫助我們理解這個(gè)從低級(jí)概念到高級(jí)概念的生成過程,那么就離理解神經(jīng)網(wǎng)絡(luò)的具體結(jié)構(gòu)就近了很多。而這也可以逐漸幫助我們完成一個(gè)“祛魅”的過程,將調(diào)參的魔法真正變成一項(xiàng)可控、可解釋的過程。
要理解這個(gè)概念的生成過程很重要的一點(diǎn)就是要研究隱層的概念表示,在接下來的部分中我將給大家介紹業(yè)界關(guān)于隱層分析方法的幾個(gè)研究工作。
▌模型學(xué)到了哪些概念?
要理解神經(jīng)網(wǎng)絡(luò)中每層都學(xué)到了哪些概念一個(gè)非常直觀的方法就是通過對(duì)隱層運(yùn)用一些可視化方法來將其轉(zhuǎn)化成人類可以理解的有實(shí)際含義的圖像,這方面一個(gè)非常具有代表性的一個(gè)工作就是14年ECCV的一篇經(jīng)典之作:《Visualizing and Understanding Convolutional Networks》,這篇文章主要利用了反卷積的相關(guān)思想實(shí)現(xiàn)了特征可視化來幫助我們理解CNN的每一層究竟學(xué)到了什么東西。我們都知道典型的CNN模型的一個(gè)完整卷積過程是由卷積-激活-池化(pooling)三個(gè)步驟組成的。而如果想把一個(gè)CNN的中間層轉(zhuǎn)化成原始輸入空間呢?我們就需要經(jīng)過反池化-反激活-反卷積這樣的一個(gè)逆過程。整個(gè)模型的結(jié)構(gòu)如下圖所示:
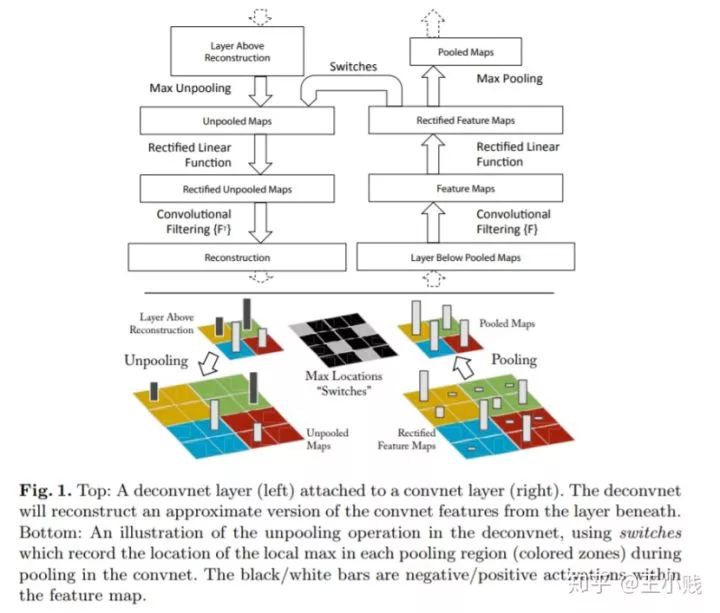
反池化:
反池化其實(shí)很好理解,以下面的圖片為例,左圖可以表示是池化(pooling)過程,右圖表示反池化(unpooling)過程,池化過程中我們將3*3的一個(gè)pooling塊中的最大值取出,而反池化則是將pooling后的值恢復(fù)成3*3的像素單元,由于我們現(xiàn)在只有一個(gè)激活值, 所以只將該激活值對(duì)應(yīng)原pooling塊中位置的值還原回去,其他的值設(shè)定成0。所以在max-pooling的時(shí)候,我們不光要知道pooling值,同時(shí)也要記錄下pooling值的對(duì)應(yīng)位置,比如下圖pooling值的位置就是(0,1)。
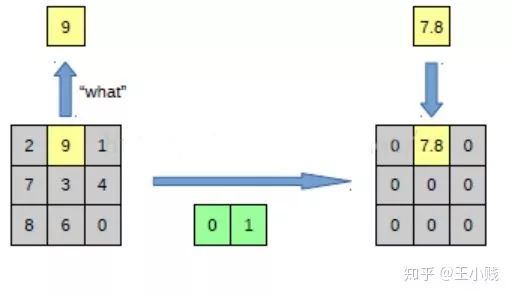
反池化過程
反激活:
在典型的CNN模型中,我們一般使用Relu作為激活函數(shù),而反激活的值和實(shí)際的激活值沒有任何區(qū)別:只保留正數(shù),其余值為0即可。
反卷積:
反卷積的過程其實(shí)非常有意思,其實(shí)反卷積這個(gè)名字多多少少有些誤人子弟,和真正的反卷積并沒有多大關(guān)系,真實(shí)的含義應(yīng)該是轉(zhuǎn)置卷積(Transposed Convolution),CNN模型的卷積過程本質(zhì)上來講和一般的神經(jīng)網(wǎng)絡(luò)沒有任何區(qū)別(只不過將一些共用參數(shù)組合成了一個(gè)濾波器的形式),都可以轉(zhuǎn)變成一個(gè)矩陣乘法的操作(只不過對(duì)CNN模型來說是一個(gè)參數(shù)重復(fù)度很高的稀疏矩陣),我們不妨將這個(gè)稀疏矩陣表示為 C,那么后一層和前一層的關(guān)系就可以表示為: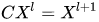
而在反向傳播的過程中,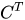 往往可以表示為卷積層對(duì)輸入層的梯度,也就是說通過對(duì)卷積層進(jìn)行適當(dāng)?shù)难a(bǔ)0操作,再用原始的卷積核轉(zhuǎn)置之后的卷積核進(jìn)行卷積操作,就可以得到相應(yīng)的梯度矩陣與當(dāng)前卷積層的乘積,而我們?cè)谶@里使用反池化-反激活之后的特征(其中包含了大部分為0的數(shù)值)進(jìn)行該操作其實(shí)表征了原始輸入對(duì)池化之后的特征的影響,因?yàn)樵诜醇せ钸^程中保證了所有值非負(fù)因此反卷積的過程中符號(hào)不會(huì)發(fā)生改變。
往往可以表示為卷積層對(duì)輸入層的梯度,也就是說通過對(duì)卷積層進(jìn)行適當(dāng)?shù)难a(bǔ)0操作,再用原始的卷積核轉(zhuǎn)置之后的卷積核進(jìn)行卷積操作,就可以得到相應(yīng)的梯度矩陣與當(dāng)前卷積層的乘積,而我們?cè)谶@里使用反池化-反激活之后的特征(其中包含了大部分為0的數(shù)值)進(jìn)行該操作其實(shí)表征了原始輸入對(duì)池化之后的特征的影響,因?yàn)樵诜醇せ钸^程中保證了所有值非負(fù)因此反卷積的過程中符號(hào)不會(huì)發(fā)生改變。
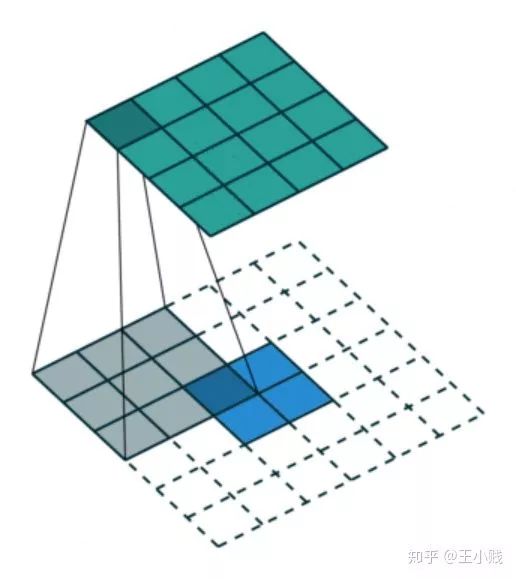
反卷積是個(gè)上采樣過程
通過上面的介紹我們其實(shí)可以明白,這個(gè)反卷積的方法之所以能夠成功地將CNN的隱層可視化出來,一個(gè)關(guān)鍵就在于通過反激活-反池化的過程,我們屏蔽掉了很多對(duì)當(dāng)前層的激活值沒有實(shí)際作用的輸入層的影響將其歸為0,通過反卷積操作就得到了僅對(duì)當(dāng)前層有實(shí)際貢獻(xiàn)的輸入層的數(shù)值——將其作為該層的特征表示。因?yàn)槲覀冏詈蟮玫降倪@個(gè)特征表示和原輸入空間的大小是一致的,其數(shù)值表示也對(duì)應(yīng)著原始空間的像素點(diǎn),所以在一定程度上,這是我們可以理解的一個(gè)特征表示。
從實(shí)驗(yàn)結(jié)果可以看出來,第二層對(duì)應(yīng)著一些邊角或色彩特征,第三層對(duì)應(yīng)著紋理特征,第四層對(duì)應(yīng)著一些如狗臉、車輪這樣的局部部位,第五層則對(duì)整體的物體有較強(qiáng)的識(shí)別能力。
通過上面這篇論文的工作,我們可以大致地用肉眼來判斷神經(jīng)網(wǎng)絡(luò)學(xué)到的概念類型,但如果能識(shí)別一些語義概念的話對(duì)我們來說可能更有意義,在這方面一個(gè)非常有代表性的工作是在CVPR 2017上發(fā)表《Network Dissection:Quantifying.Interpretability.of.Deep.VisualRepresentations》,這篇文章提出了一種網(wǎng)絡(luò)切割(Network Dissection)的方法來提取CNN的概念表示。
所謂的網(wǎng)絡(luò)切割(Network Dissection)方法其實(shí)分為三個(gè)步驟:
1. 識(shí)別一個(gè)范圍很廣的人工標(biāo)注的視覺語義概念數(shù)據(jù)集
2. 將隱層變量對(duì)應(yīng)到這些概念表示上
3. 量化這些隱層-概念對(duì)的匹配程度
為了獲得大量的視覺語義概念數(shù)據(jù),研究人員收集了來自不同數(shù)據(jù)源的分層語義標(biāo)注數(shù)據(jù)(包括顏色、材質(zhì)、材料、部分、物體、場景這幾個(gè)層次),如下圖所示
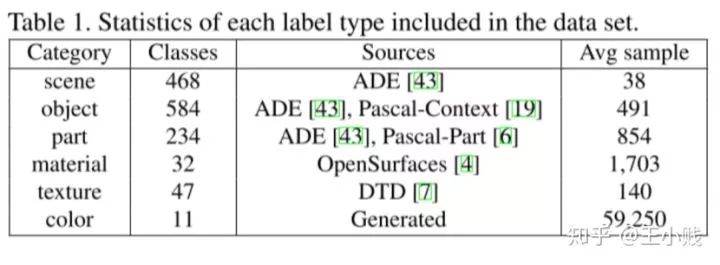
而如何將隱層變量對(duì)應(yīng)到這些概念表示上并獲得隱層-概念對(duì)的匹配程度呢,本文提出了如下的方法:
對(duì)于每個(gè)輸入圖像x,獲取每個(gè)隱層k的activation map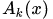 (其實(shí)也就是feature map),這樣就可以得到隱層k激活值的分布,對(duì)于每個(gè)隱層k,我們都可以找到一個(gè)?
(其實(shí)也就是feature map),這樣就可以得到隱層k激活值的分布,對(duì)于每個(gè)隱層k,我們都可以找到一個(gè)?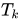 ?使得?
?使得?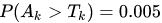 ,這個(gè)?
,這個(gè)?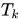 可以作為接下來判斷區(qū)域是否激活的一個(gè)標(biāo)準(zhǔn)。
可以作為接下來判斷區(qū)域是否激活的一個(gè)標(biāo)準(zhǔn)。
為了方便對(duì)比低分辨率的卷積層和輸入層的概念激活熱圖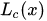
(其實(shí)就是標(biāo)注出了相關(guān)概念在圖像中的代表區(qū)域),我們將低分辨率的卷積層的特征圖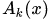 通過插值的方法擴(kuò)展為和原始圖片尺寸一樣大的圖像?
通過插值的方法擴(kuò)展為和原始圖片尺寸一樣大的圖像?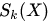 ?。
?。
之后再建立一個(gè)二元分割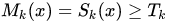 ?,這樣就得到了所有被激活的區(qū)域,而我們通過將?
?,這樣就得到了所有被激活的區(qū)域,而我們通過將?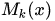 和輸入層的概念激活熱圖?
和輸入層的概念激活熱圖?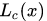 作對(duì)比,這樣就可以獲得隱層-概念對(duì)的匹配程度:
作對(duì)比,這樣就可以獲得隱層-概念對(duì)的匹配程度:
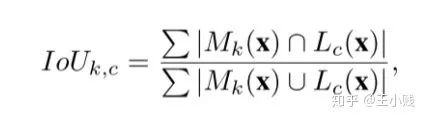
可以發(fā)現(xiàn)如果匹配度高的話,那么分子就比較大(交叉范圍大),分母就比較小(合并范圍小),我們通過和顏色、材質(zhì)、材料、部分、物體、場景不同層次的概念作匹配就能得到隱層學(xué)到的概念層次了,這個(gè)模型的結(jié)構(gòu)如下圖所示:
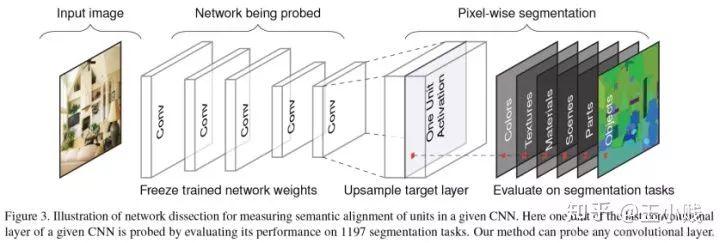
Network Dissection的模型結(jié)構(gòu)
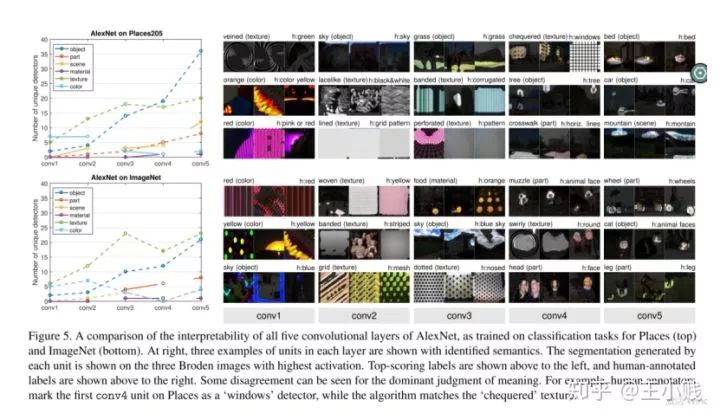
模型在AlexNet上的實(shí)驗(yàn)結(jié)果
從實(shí)驗(yàn)結(jié)果中我們也可以發(fā)現(xiàn)隨著層數(shù)的增加,神經(jīng)網(wǎng)絡(luò)學(xué)到的概念類型也逐漸變得高級(jí),比如在AlexNet中,前面的卷積層對(duì)顏色、材質(zhì)的識(shí)別力較強(qiáng),后面的卷積層對(duì)物體、場景的識(shí)別力較強(qiáng)。特別是對(duì)物體的識(shí)別上,后面的卷積層有突出的優(yōu)勢。
▌低級(jí)到高級(jí)=泛化到特化?
當(dāng)然從低級(jí)概念到高級(jí)概念的一個(gè)過程中總是會(huì)伴隨著一個(gè)非常有意思的現(xiàn)象:泛化性逐漸降低,特化性逐漸升高。比如在細(xì)胞層次上,人類和其他動(dòng)物的區(qū)別比較小,這個(gè)層次的泛化性就高,但到組織器官層次區(qū)別就比較大,這個(gè)層次的特化性就高。Bengio團(tuán)隊(duì)在2014年發(fā)表的一篇工作《How transferable are features in deep neural networks》就是通過研究特征的可遷移性來對(duì)這個(gè)從泛化的特化的過程進(jìn)行評(píng)估。
特征在遷移任務(wù)上的表現(xiàn)往往是評(píng)價(jià)特征泛化性能的一個(gè)非常好的依據(jù)。在遷移學(xué)習(xí)中,我們首先基于基礎(chǔ)數(shù)據(jù)訓(xùn)練一個(gè)基礎(chǔ)網(wǎng)絡(luò),然后將特征改換到另一個(gè)任務(wù)上,如果特征是具備泛化性的,那么其在遷移任務(wù)中應(yīng)該也是適用的。在這個(gè)工作中,作者將1000個(gè)ImageNet的分類分成了兩個(gè)組,每個(gè)組個(gè)包含大約500個(gè)分類和645000個(gè)樣本。然后利用這兩組數(shù)據(jù)各訓(xùn)練一個(gè)八層的卷積網(wǎng)絡(luò)baseA和baseB,然后分別取第1到第7個(gè)卷積層訓(xùn)練幾個(gè)新的網(wǎng)絡(luò),以第3層為例:
自我復(fù)制網(wǎng)絡(luò)(selffer network)B3B,前三層從baseB上復(fù)制并凍結(jié)。剩余的5個(gè)卷積層隨機(jī)初始化并在數(shù)據(jù)集B上訓(xùn)練,這個(gè)網(wǎng)絡(luò)作為控制組。
一個(gè)遷移網(wǎng)絡(luò)(transfer network)A3B:前三層從baseA上復(fù)制并凍結(jié)。剩余的5個(gè)卷積層隨機(jī)初始化并在數(shù)據(jù)集B上訓(xùn)練。如果A3B的任務(wù)表現(xiàn)和baseB一樣好,那么就說明第三層的特征至少對(duì)于B任務(wù)來講是泛化的,如果不如baseB,那么說明第三層特征就是特化的。
一個(gè)自我復(fù)制網(wǎng)絡(luò)B3B+,網(wǎng)絡(luò)結(jié)構(gòu)和B3B一樣,但所有層都是可學(xué)習(xí)的。
一個(gè)遷移網(wǎng)絡(luò)A3B+,網(wǎng)絡(luò)結(jié)構(gòu)和A3B一樣,但所有層都是可學(xué)習(xí)的。
這些網(wǎng)絡(luò)的結(jié)構(gòu)圖如下圖所示:
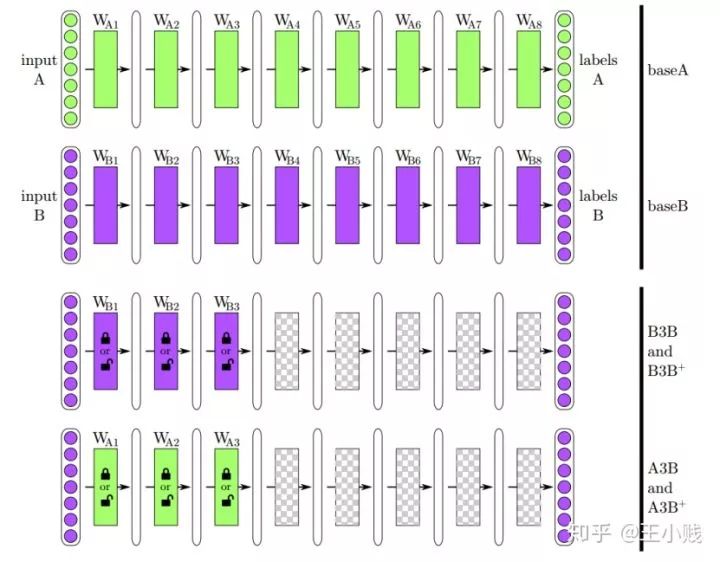
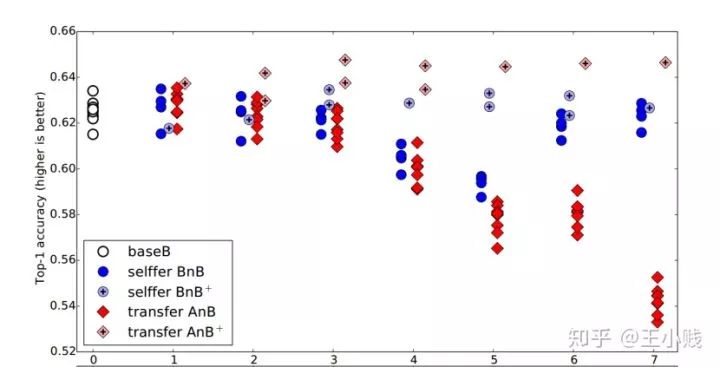
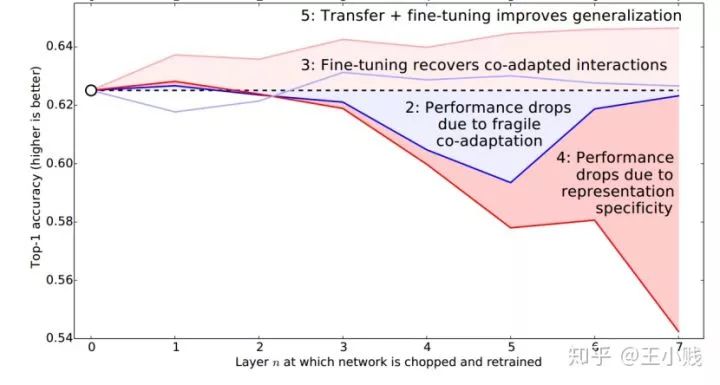
而從實(shí)驗(yàn)結(jié)果來看,transferAnB的隨著層數(shù)的增加性能在不斷下降(泛化降低,特化提升,這印證了我們對(duì)泛化特化性質(zhì)隨層數(shù)變化的基本判斷),而控制組的selfferBnB的性能出現(xiàn)了先下降后上升的現(xiàn)象(泛化和特化都不足夠的中間層既缺乏可學(xué)習(xí)性,特征的描述性又不夠強(qiáng),因而出現(xiàn)了性能下降的現(xiàn)象),transferBnB+和transferAnB+一直維持著比較好的性能,但其中transferAnB+的性能確是最好的,特征在遷移任務(wù)上表現(xiàn)出來的優(yōu)勢其實(shí)也對(duì)應(yīng)了我們?cè)谏弦还?jié)中講的模型本身也意味著知識(shí)。
▌?wù)娴男枰敲炊鄬訂幔?/p>
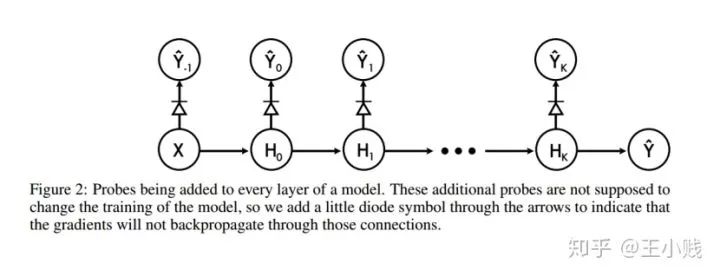
對(duì)于神經(jīng)網(wǎng)絡(luò)來說,隱層的數(shù)量永遠(yuǎn)都是一個(gè)玄學(xué),我們?nèi)绾卫斫怆[層的數(shù)量和模型性能之間的關(guān)系呢?Bengio在2016年還做過一個(gè)工作《Understanding intermediate layers using linear classifier probes》。這篇文章的思路非常簡單,就是通過在每個(gè)隱層中添加一個(gè)線性探針來測試隱層的表征性能。什么是線性探針呢?也很簡單,就是以每個(gè)隱藏層為輸入,判別的label為輸出建立一個(gè)邏輯回歸模型,通過評(píng)估模型的準(zhǔn)確率我們就能得到隱層在整個(gè)訓(xùn)練過程中以及訓(xùn)練結(jié)束之后表征性能的變化。
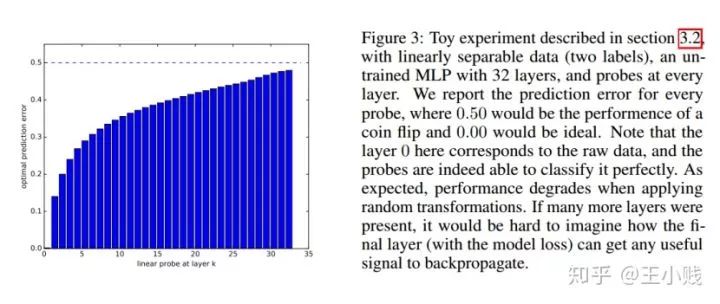
通過32個(gè)隱層在二分?jǐn)?shù)據(jù)上的實(shí)驗(yàn)我們可以發(fā)現(xiàn)隨著隱層的增加表征性能不斷提高,但提高的比率也逐漸趨于緩慢。
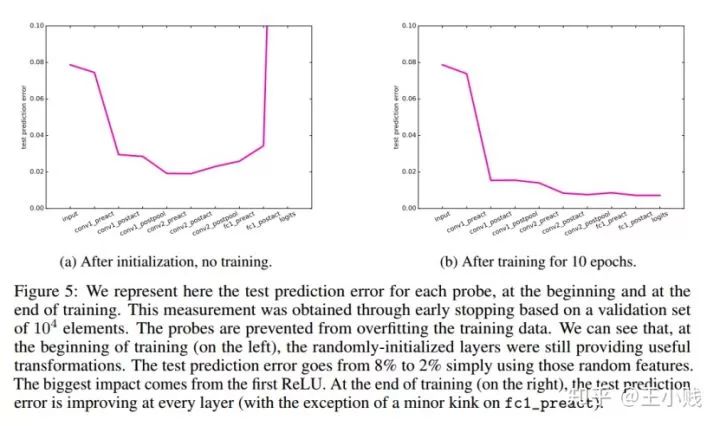
在基于Minist數(shù)據(jù)訓(xùn)練的CNN模型上,經(jīng)過10個(gè)周期的訓(xùn)練,第一個(gè)卷積層的表征性能提升非常明顯,但之后的卷積層并沒有很明顯的提升。
▌小結(jié)
本文中我們主要介紹了四個(gè)在隱層分析上有代表性的工作,這類方法在神經(jīng)網(wǎng)絡(luò)可解釋性的研究中向我們揭示了隱層性質(zhì)的變化和概念生成的過程,在之后要講到的敏感性分析方法中,也會(huì)不可避免地涉及對(duì)隱層的分析。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8406瀏覽量
132562 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121111
原文標(biāo)題:詳解深度學(xué)習(xí)的可解釋性研究(上篇)
文章出處:【微信號(hào):AI_Thinker,微信公眾號(hào):人工智能頭條】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
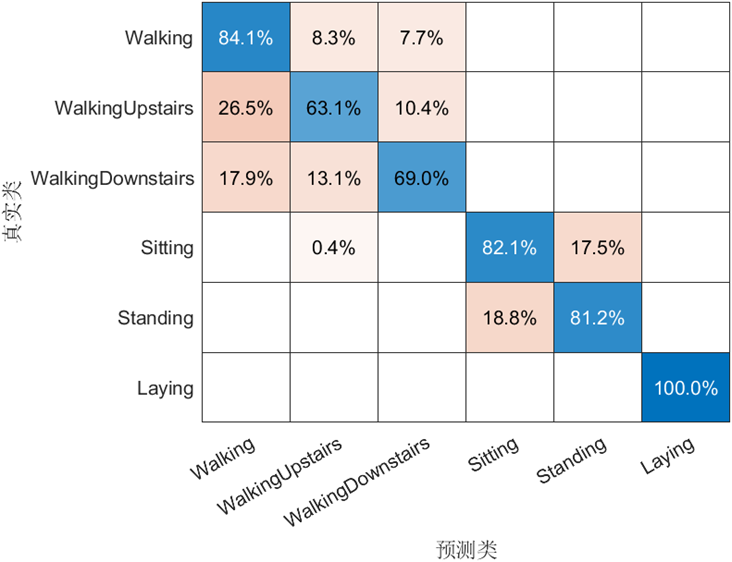
機(jī)器學(xué)習(xí)模型可解釋性的結(jié)果分析
什么是“可解釋的”? 可解釋性AI不能解釋什么
斯坦福探索深度神經(jīng)網(wǎng)絡(luò)可解釋性 決策樹是關(guān)鍵

機(jī)器學(xué)習(xí)模型的“可解釋性”的概念及其重要意義
神經(jīng)網(wǎng)絡(luò)可解釋性研究的重要性日益凸顯
深度理解神經(jīng)網(wǎng)絡(luò)黑盒子:可驗(yàn)證性和可解釋性
Explainable AI旨在提高機(jī)器學(xué)習(xí)模型的可解釋性
機(jī)器學(xué)習(xí)模型可解釋性的介紹
圖神經(jīng)網(wǎng)絡(luò)的解釋性綜述
《計(jì)算機(jī)研究與發(fā)展》—機(jī)器學(xué)習(xí)的可解釋性

關(guān)于機(jī)器學(xué)習(xí)模型的六大可解釋性技術(shù)
機(jī)器學(xué)習(xí)模型的可解釋性算法詳解
使用RAPIDS加速實(shí)現(xiàn)SHAP的模型可解釋性
可以提高機(jī)器學(xué)習(xí)模型的可解釋性技術(shù)
文獻(xiàn)綜述:確保人工智能可解釋性和可信度的來源記錄
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論