 FPGA需要跑多快?影響FPGA計算性能的幾大因素
FPGA需要跑多快?影響FPGA計算性能的幾大因素
專用芯片ASIC的開發流程是:設計、驗證、流片、封裝、測試;
而FPGA已經是做好的芯片,所以不需要流片、封裝、測試。這樣,可以至少節省四個月的時間。
另外ASIC還有可能多次流片才能成功,同步的軟件開發也需要芯片做好才能完成大部分功能,這些也是時間成本。
在量小的時候,FPGA的成本低,量大了之后,ASIC的成本低。
FPGA的功耗比ASIC高,因為有很多多余的邏輯,不過比CPU省電,畢竟CPU的多余邏輯更多。
相比ASIC,FPGA的調試比較方便,可以直接燒到FPGA執行,也可以用調試工具抓取芯片里面的信號查看狀態。
FPGA需要跑多快?
跟Intel CPU相比,FPGA的主頻差一個數量級,一般FPGA芯片時鐘頻率300MHz左右,而Intel CPU可以到3GHz,就是說CPU 1秒能做30億次計算,而FPGA只能做3億次,差了10倍。
另外FPGA用作可重構計算是來加速CPU的,如果和CPU跑一樣快就沒意思了,所以一般要比CPU快5倍才行。
FPGA的開發周期是比較久的,1年甚至2年很正常,在這個過程中,CPU上的軟件算法還在不斷升級,所以有可能FPGA算法設計的比CPU快,等開發完,卻發現CPU上的軟件算法快速迭代,已經超過FPGA算法了。這種事還是比較常見的,不只是軟件算法升級,CPU自己也會升級,這些都有可能讓FPGA加速器做了無用功。比如用FPGA做一個數據壓縮卡,可是CPU可能就自己帶了一個數據壓縮功能,成本還比FPGA卡低,開發FPGA的人白干一場。阿呆以前就遇到過這種問題,在FPGA里面做了一個AI算法,架構設計的牛逼了點,大家又干的慢了點,兩年完工,再去跟做AI的人一交流,發現這套算法已經是舊的框架了。。。
所以,正常來說,FPGA算法加速性能設計的時候要比CPU快5-10倍才能保證最終做出來的產品是可以實現硬件加速的目標。
影響FPGA計算性能的幾大因素
1. 數據并行性
對FPGA計算來說,同時處理大量的數據,同時數據之間沒有相互依賴是最好的。這樣,可以有幾百上千個并行計算單元獨立處理幾百上千個數據,如果數據之間有依賴,比如有很多的if else,就并發不起來,A必須要等B完成才能執行。就跟步騎兵混合軍團出征,如果將軍下令大家要同步進軍,步兵要和騎兵一起沖,騎兵不能跑太快,要等步兵一起走,那這個仗就沒法打了,只能被敵人包餃子。
2. 數據大小和計算復雜度
FPGA并行計算是很多個計算并行執行,如果每個計算單元要處理的數據太多,同時計算邏輯太復雜,那么占用的FPGA計算資源就變多了,這樣總的并行單元數量相應減少,性能下降。而且,老司機都知道,計算邏輯太復雜,在電路上消耗的時間變多,還會導致每個模塊的延遲變長,這樣時鐘頻率也會下降,也會影響到性能。
3. 流水線
計算復雜的時候,延遲會變長,如果要求計算任務在一個時鐘周期里完成,那么時鐘周期就變長了,相應的頻率降低,性能下降。所以為了提高時鐘頻率,FPGA會采用流水線技術,把復雜的計算分解成幾段,放到幾個時鐘周期里完成。這樣做的后果就是,計算需要的時間變長了,但是總的性能卻提高了。為什么?阿呆來舉例說明。
蛋蛋本來1個小時造1個玩具,一天8小時造8個。后來造玩具改成蛋蛋、小蛋蛋、蛋媽三個人干,任務分解成三段,每人半小時,1個半小時才能造出玩具,看起來造玩具的時間變長了。可是三個人一天工作總時間3*8=24小時,一天生產24/1.5=16個玩具,產量翻番了。
這就叫三個臭皮匠,賽過一個諸葛亮。
4. 靜態控制邏輯
我們寫軟件程序的時候,習慣了給函數很多參數作為條件,根據參數內容執行函數的操作。FPGA做計算就不希望靠參數內容確定怎么計算,而是希望一開始就定好。比如在軟件里面,算個位數的平方和二位數的平方差不多,可是到FPGA里面,個位數需要的計算資源少,二位數占用的多,一個計算單元要同時支持個位數和二位數平方計算就會很占資源,最好是一開始就確定好算哪一種,不要動態確定。
存儲和計算的關系
1. 數據密集型和計算密集型
我們的計算有數據密集型和計算密集型兩種,如果計算的次數多,就是計算密集型,反之,就是IO密集型。比如n×n矩陣乘法,每個數據讀和寫都認為是一次IO,讀兩個矩陣的數據,寫入結果矩陣的數據,需要3n2次IO,而計算的次數是n3,所以是計算密集型。但是n×n矩陣加法,同樣需要3n2次IO,不過計算的的次數只有n2,屬于IO密集型。
2. 脈動陣列結構
AI的計算往往涉及到矩陣乘法和向量乘法等,所以IO這邊的存儲往往成了性能瓶頸,我們經常會看到,為了解決“存儲墻”問題,AI芯片里面(例如Google TPU)會采用脈動陣列結構,盡量做到IO進來的數據重用,把IO密集型轉化為計算密集型。如下圖,左側和上方都有數據進來,就跟心跳一樣,不斷有血液流進來,但是內部有計算陣列,不會浪費中間產生的數據,所有的計算單元都在并行工作,產生可怕的計算性能。
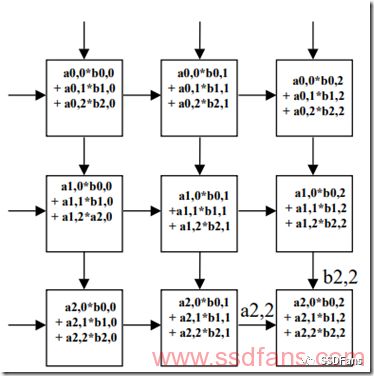
3. AI計算的“存儲墻”問題
AI計算需要讀大量的數據,如果依賴于AI芯片外部的存儲器,比如DDR DRAM等,延遲和性能都會受到影響,DDR占用管腳多,能耗高,只能接一兩個,最多4個,沒辦法滿足很多并行計算單元的IO需求。所以,需要預先在芯片里面放置大量的SRAM和寄存器等作為片內高速緩存,通過很多個小容量片內RAM,實現大量的并發IO,提供給成百上千個并行計算引擎。
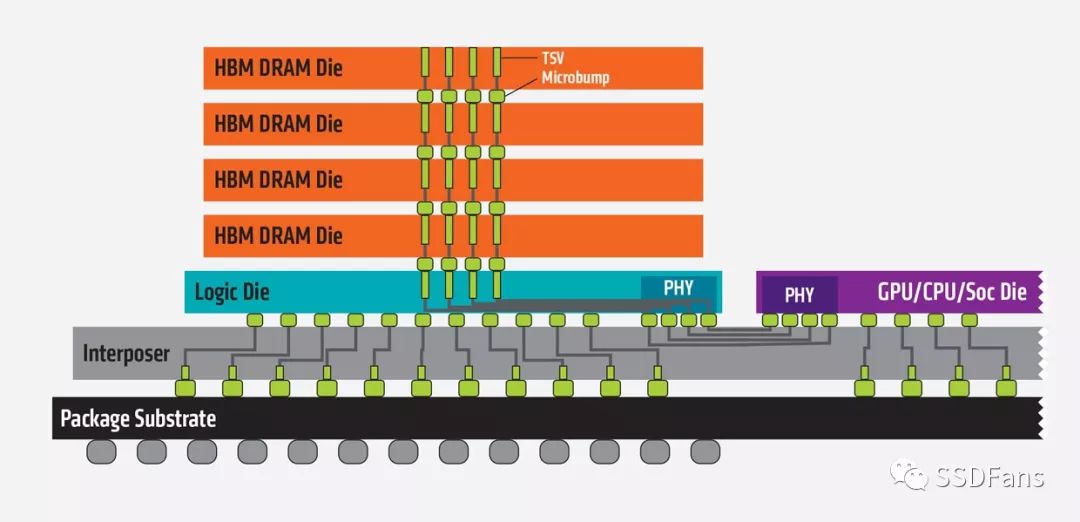
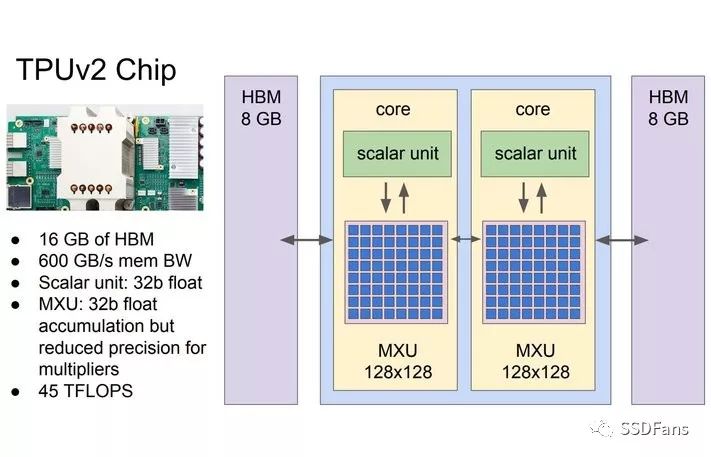
為了解決存儲墻問題,有兩種路徑:
(1) 基于HBM(High-bandwidth Memory)技術的3D堆疊,很多存儲芯片和AI芯片封裝在一起。AMD和NVIDIA的Vega和Volta GPU都集成了16GB的HBM2。而其他公司的一些最新的AI芯片架構,也都集成了3D堆疊存儲,比如Intel Nervana也用3D HBM,而Wave Computing用的是美光(Micron)的HMC,另外一種形式的3D堆疊存儲。Google的TPU 2.0也是每個核用了8GB的HBM。
(2) 計算存儲一體化。用RRAM等新型掉電不丟失數據的存儲介質和AI計算引擎集成在一顆芯片內,數據一直存在AI芯片里面,不需要從外部加載,減少了數據搬移,效率和性能都很高。例如加州大學謝源教授團隊把神經網絡計算和RRAM放到一顆芯片里面,功耗可以降低20倍,速度提高50倍。IBM在《自然》也發了一篇文章,宣布在相變存儲器上實現了同樣的針對AI應用的神經網絡計算。
我們用FPGA做計算,有一個很重要的概念,叫做Domain Specific Computing,是UCLA的叢京生教授提出來的,就是針對某一個領域的計算任務,在硬件算法上做特殊優化,主要是性能提升和算法壓縮,實現高性能、低成本。
FPGA做計算第一板斧:化動為靜
前面說過,FPGA如果按照某個參數去執行不同的計算任務,就很浪費資源,因為每一種計算引擎都要用硬件計算資源實現,等用戶來用。如果我們知道一段時間里面計算任務是固定的,就可以把FPGA配置成只有某一個計算任務,節省資源,增強計算能力。
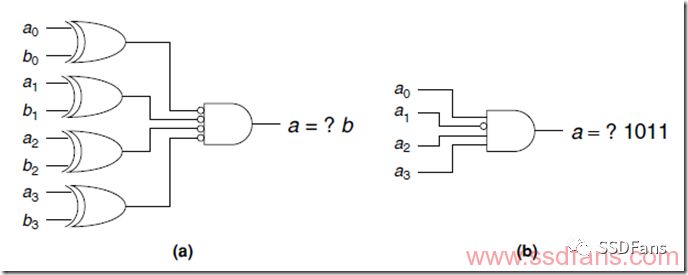
另一種情況叫做常數折疊,如果我們發現一段時間內某個變量其實不會變化,就可以當成常數,不用占用計算邏輯。如下圖,本來是兩個4bit數a和b比較器,但是已知b是1011,就可以直接用a來輸出結果了,省了4個邏輯門。
FPGA做計算第二板斧:實時重配置
現在的FPGA支持里面的計算邏輯實時重配置,可以整個FPGA重新配置成新邏輯,比如上一毫秒是aPU,下一毫秒配成bPU。更實用的是部分邏輯實時重配置,因為FPGA里面很多邏輯是控制用的,不需要經常改,但是計算的那部分要根據使用情況經常換,所以支持某個分區的實時重配置。
FPGA做計算第三板斧:位寬壓縮
我們寫軟件程序,習慣了兩個32位或64位變量加減乘除,因為大家共享一個CPU計算單元,不浪費資源。可是到FPGA里面,是一種并行計算,每一個程序都是占用計算資源的,所以能省則省。比如,兩個32位數相乘,如果我們已經知道某個數只會有兩個bit是有效數據,就只需要用2個bit表示它,然后最后的結果做個移位就可以了。
歸根結底,我們只要明白FPGA計算快的兩大優點就是并行和流水線,但是必須時刻有并行計算的思想,盡量壓縮算法占用的資源,這樣才能用有限的FPGA計算資源實現最強大的并行計算能力。
-
FPGA
+關注
關注
1629文章
21729瀏覽量
602986 -
cpu
+關注
關注
68文章
10854瀏覽量
211578 -
加速器
+關注
關注
2文章
796瀏覽量
37839
原文標題:阿呆讀可重構計算3:FPGA做AI三板斧
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA管教分配需要考慮因素
學習FPGA需要哪些基礎?怎么學好FPGA?
基于FPGA的計算性能
軟件無線電設計中選擇ASIC、FPGA和DSP需要考慮哪些因素?
FPGA幾大廠商介紹,你知道的有哪些呢?精選資料分享
FPGA幾大廠商介紹,你知道的有哪些呢?精選資料分享
FPGA幾大廠商介紹,你知道的有哪些呢?






 工商網監
工商網監
評論