 Arm機器學習處理器助力邊緣設備機器學習
Arm機器學習處理器助力邊緣設備機器學習
如果能夠擁有一部智能個人助理,它能聽懂我們說的話并做出智能反應,然后處理日常任務,那感覺一定很棒。鑒于機器學習(ML)領域近期取得的進展,Arm相信這一天很快就會到來。機器學習已經遠遠越過移動市場的邊界,延伸到醫療保健、零售、汽車和服務器等領域,從只能識別貓的圖片發展到可以解決現實問題的水平。
現在主要的難點是如何將這種能力轉移到邊緣,解決如今普遍存在的隱私、安全、帶寬和延遲問題,Arm 機器學習處理器朝這個方向邁出了一大步。
移動性能
機器學習處理器是專門為移動和相鄰市場(例如智能相機、AR/VR、無人機、醫療和消費性電子產品等)推出的全新設計,性能為 4.6 TOP/s,能效為 3 TOPs/W。計算能力和內存的進一步優化大大提高了它們在不同網絡中的性能。
其架構包括用于執行卷積層的固定功能引擎以及用于執行非卷積層和實現選定原語和算子的可編程層引擎。網絡控制單元管理網絡的整體執行和網絡的遍歷,DMA 負責將數據移入、移出主內存。板載內存可以對重量和特征圖進行中央存儲,減少流入外部存儲器的流量,從而降低功耗。
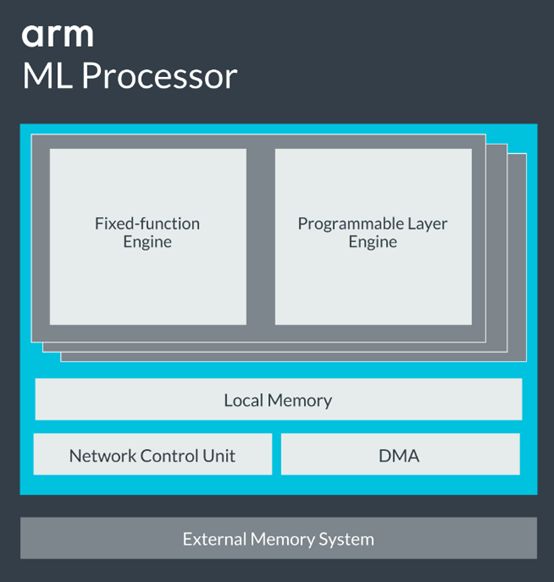
有了固定功能和可編程引擎,機器學習處理器變得非常強大、高效和靈活,足以應對未來的挑戰,不僅保留了原始性能,還具備多功能性,能夠有效運行各種神經網絡。
主要特點
采用開源軟件,無鎖定。
與現有軟件框架緊密集成:TensorFlow、TensorFlow Lite、Caffe、Caffe 2。
經優化后適用于Arm Cortex CPU和Arm Mali GPU。
Arm 機器學習處理器架構

為應對多個市場帶來的挑戰,滿足不同的性能需求,從物聯網的每秒幾 GOP 到服務器的每秒數十 TOP,機器學習處理器采用了全新的可擴展架構。
對于物聯網或嵌入式應用,該架構的性能可降低至約每秒 2 GOP,而對于 ADAS、5G 或服務器型應用,性能可提高至每秒 150 TOP。這些多重配置的效率可達到現有解決方案的數倍。
由于與現有的 Arm CPU、GPU 和其他 IP 兼容,且能提供完整的異構系統,該架構還可通過 TensorFlow、TensorFlow Lite、Caffe 和 Caffe 2 等常用的機器學習框架來獲取。
隨著機器學習的工作負載不斷增大,計算需求將呈現出多種形式。Arm 已經開始采用擁有不同性能和效率等級的增強型 CPU 和 GPU,運行多種機器學習用例。我們推出Arm 機器學習平臺的目的在于擴大選擇范圍,提供異構環境,滿足每種用例的選擇和靈活性需求,開發出邊緣智能系統。
-
處理器
+關注
關注
68文章
19317瀏覽量
230098 -
ARM
+關注
關注
134文章
9104瀏覽量
367869 -
機器學習
+關注
關注
66文章
8422瀏覽量
132743
原文標題:助力邊緣設備機器學習,Arm機器學習處理器來了!
文章出處:【微信號:arm_china,微信公眾號:Arm芯聞】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
ARM發布兩款針對移動終端的AI芯片架構:物體檢測和機器學習處理器






 工商網監
工商網監
評論