 OpenAI的由5個神經網絡組成的OpenAI Five,已經開始擊敗Dota 2的業余玩家隊伍
OpenAI的由5個神經網絡組成的OpenAI Five,已經開始擊敗Dota 2的業余玩家隊伍
剛剛,OpenAI宣布了一個大新聞——他們的一個由5個神經網絡組成的OpenAI Five,已經開始擊敗Dota 2的業余玩家隊伍。
剛剛,OpenAI 宣布了一個大新聞——還記得去年他們的AI在 Dota2 1v1 比賽中戰勝了人類職業玩家 Dendi嗎?現在,OpenAI的由5個神經網絡組成的OpenAI Five,已經開始擊敗Dota 2的業余玩家隊伍。
4月23日,OpenAI Five首次擊敗了腳本基線。5月15日,OpenAI Five與第一隊平分秋色,贏得了一場比賽并輸掉了另一場。6月6日,OpenAI Five在與隊伍1、2、3的比賽中全部獲勝。之后,我們又與第4和第5隊進行了非正式的比賽,預計會輸得很慘,但OpenAI Five在前3場比賽中贏得了兩場。
OpenAI表示,雖然他們現在玩的是有限制的游戲,但他們的目標是在8月份擊敗國際頂級職業團隊(不過只限于一組有限的英雄)。同時,他們也坦承這個任務艱巨——“我們可能不會成功:Dota 2是世界上最流行和最復雜的電子競技游戲之一,每年都有來自全世界最富有創造力和積極性的專業人員參賽,競爭Dota年度價值4000萬美元的獎金(這也是所有電子競技游戲中份額最大的獎金)。
如今,OpenAI Five每天都通過自我對戰(self-play)來學習,而每天自我對戰的量是180年的游戲——沒錯,是180年。它使用OpenAI提出的算法“近端策略優化”(PPO)的擴展版,在256個GPU和128,000個CPU內核上進行訓練。每個英雄都使用單獨的LSTM,不使用人類數據,最終AI能夠學會識別策略。這表明,強化學習能夠進行大但卻可實現規模(large but achievable scale)的長期規劃,而不發生根本性的進展,這與OpenAI開始項目時的預期相悖。
為了對他們所取得的進步衡量基準,OpenAI將在7月28日舉行一場比賽,歡迎觀看直播甚至親臨現場。
OpenAI Five與OpenAI玩DOTA最好的團隊競賽。比賽由暴風游戲的專業評論員和OpenAI Dota團隊成員Christy Dennison進行了評論,也得到了玩家的觀戰。
Dota游戲是一個典型的AI難題,它綜合了決策周期長,空間大而且敵我雙方是在非完全信息下博弈。OpenAI繼去年解決1v1的問題后,1年內能在5v5的更復雜情況下,完全依靠自我對抗學習、無顯式通訊信道的前提下,即展現出了類似于人的長期規劃協作能力,代表了多智能體決策智能的國際最高水準,也體現了大規模算力帶來的美感。
Dota2究竟有多難?復雜程度超乎想象
玩星際爭霸或Dota,需要AI在不確定的情況下進行推理與規劃,涉及多個智能體協作完成復雜的任務,權衡短中長期不同的收益。相比下圍棋這樣的確定性問題,星際爭霸/Dota的搜索空間要高出10個數量級。
因此,攻克星際爭霸或者Dota這樣的復雜電子競技游戲,是AI的最大挑戰之一,也將是AI的一個里程碑式的成就。
Dota 2 是一個實時競技電子游戲,有兩支5人隊伍組成,每個人都控制一個英雄,能玩Dota的AI,必須掌握以下技巧:
很長的時間線。Dota游戲以每秒30幀的速度運行,平均時間為45分鐘,因此每場游戲的時間tick為80,000次。大多數行為(例如命令英雄移動到某個位置)單獨產生的影響較小,但有些個別的行為,比如在城市間移動(回城卷軸),可能會在戰略上影響游戲。還有一些策略,則能影響整個戰局。OpenAI Five每4幀觀察一次,產生20,000次移動。相比之下,國際象棋通常在40次移動之前就結束,圍棋則是150手移動前結束,而且幾乎每一次移動都是戰略性的。
部分觀察狀態。在Dota過程中,隊伍(units)和建筑物只能看到他們周圍的區域。地圖的其他部分隱藏在霧中,敵人和他們的戰略也是隱藏的。因此,比賽需要根據不完整的數據進行推斷,并且需要對對手的最佳狀態進行建模。相比之下,國際象棋和圍棋都是信息完全顯露出來的游戲。
高維連續動作空間。在Dota中,每個英雄可以采取數十個動作,而許多動作都是針對另一個單位(unit)或地面上的某個位置。OpenAI將每個英雄的空間分割成170,000個可能的行動;不計算連續部分,每個tick平均有大約1000次有效操作。國際象棋中的平均動作數為35,在圍棋中,這是數字也只有250。
高維連續的觀察空間。Dota在包含十個英雄,幾十個建筑物,幾十個NPC以及諸如符文、樹木和病房等游戲長尾特征。OpenAI的模型通過Valve的Bot API觀察Dota游戲的狀態,其中20,000(大多是浮點)數字表示允許人類訪問的所有信息。相比之下,國際象棋棋盤有大約70個枚舉值(8x8的棋盤加6種棋子類型和其他一些的歷史信息),而圍棋則有大約400個枚舉值(19x19的棋盤加黑白兩種棋子)。
Dota規則也非常復雜。這是一個已經被積極開發了十多年的游戲,游戲邏輯在幾十萬行代碼中實現。這個邏輯需要幾毫秒的時間才能執行,而對于國際象棋或圍棋引擎則只需要幾納秒。游戲也每兩周更新一次,不斷改變環境語義。
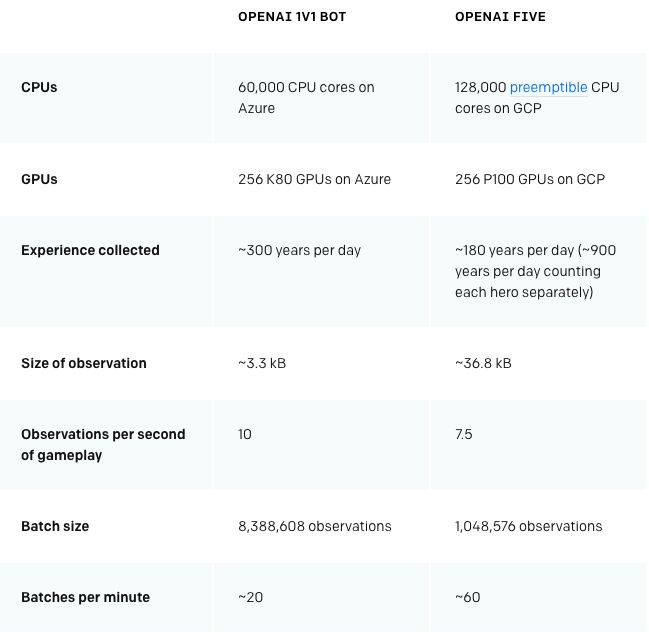
完全從自我對戰中學習,128000CPU+256 P100GPU
OpenAI的系統使用Proximal Policy Optimization的大規模版本進行學習。OpenAI Five和OpenAI早期的1v1 bot都是完全從自我對戰中學習。它們從隨機參數開始,不使用來自人類回放(replay)的搜索或引導。
RL研究人員(包括OpenAI自己)一般認為,長時間視野(long time horizons)需要從根本上取得新的進展,比如分層強化學習。結果表明,實際上現如今的算法已經足夠,至少當它們以足夠的規模和合理的探索方式運行時。
OpenAI的agent經過訓練,可以最大化未來獎勵的指數衰減總和,并由稱為γ的指數衰減因子加權。在最新的OpenAI Five訓練中,他們從0.998(評估未來獎勵的半衰期為46秒)到0.9997(評估未來獎勵的半衰期為五分鐘)退化γ。相比之下,PPO論文中最長的half-life是0.5秒,Rainbow論文中最長的半衰期為4.4秒。
盡管當前版本的OpenAI Five在最后一擊時表現不佳,但其objective prioritization已經堪比一個常見的專家。獲得戰略地圖控制等長期回報往往需要犧牲短期回報,例如從農業獲得的黃金,因為組建攻擊塔需要時間。這表明系統真正在進行長期的優化。
模型結構
每個OpenAI Five網絡都包含一個單層的、1024-unit的LSTM,它可以查看當前的游戲狀態(從Valve的Bot API中提取),并通過幾個可能的action heads發出動作。每個 head都具有語義含義,例如,延遲動作的刻度數,選擇一個動作時,該動作在單元周圍網格中的X或Y坐標等。Action heads是獨立計算的。
OpenAI Five使用觀察空間和動作空間進行交互式演示。OpenAI Five將世界視為20000個數字的列表,并通過發出一個包含8個枚舉值的列表來采取行動。選擇不同的行動和目標以了解OpenAI Five如何編碼每個動作,以及它如何觀察世界。下圖顯示了人類會看到的場景。
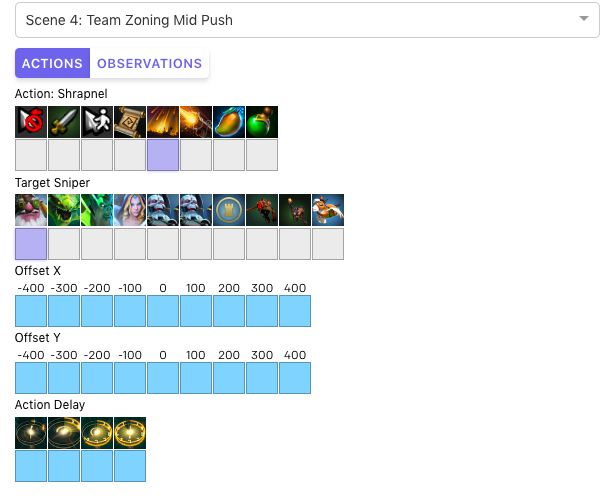
OpenAI Five可以對丟失的與它所看到的相關的狀態片段做出反應。例如,直到最近,OpenAI Five的觀察都還沒有包括彈片區域(彈片落在敵人身上的區域),人類在屏幕上能看到這些區域。然而,我們觀察到OpenAI Five學習走出(雖然不能避免進入)活躍的彈片區域,因為當進入彈片區時,它可以看到它的健康狀況在下降。
探索
盡管有學習算法能夠處理較長的視野,我們仍然需要探索環境。即使我們設了限制,仍然有數百個物品,幾十種建筑,法術和單元類型,以及需要了解的復雜的游戲機制——其中許多產生了強大的組合。要有效地探索這個巨大的空間并不容易。
OpenAI Five從自我玩游戲(self-play)過程中學習(從隨機權重開始),這為探索環境提供了一個自然的設置。為了避免“戰略崩潰”,agent在80%的游戲中進行自我訓練,其余20%的游戲則與過去的自己對戰。在第一場比賽中,英雄漫無目的地在地圖上漫步。經過幾個小時的訓練后,出現了諸如laning、farming或中期戰斗等概念。幾天之后,它們一直采用基本的人類策略:試圖從對手手中奪取神符,步行到一級塔去農場,并在地圖周圍旋轉英雄以獲得lane優勢。通過進一步的訓練,它們變得精通5-hero push 這樣的高級戰略了。
在2017年3月,我們的第一個agent擊敗了bot,但仍然搞不定人類。為了強制在戰略空間進行探索,在訓練期間(并且只在訓練期間),我們對這些單元的屬性(健康,速度,啟動級別等)進行了隨機化,然后用它開始能與人類對打。后來,當一名測試玩家一直不斷地擊敗我們的1v1 bot時,我們增加了隨機訓練,測試玩家開始出現失敗。(我們的機器人團隊同時將類似的隨機化技術應用于物理機器人身上,以便從模式世界轉換到現實世界。)
OpenAI Five使用我們為1v1 bot編寫的隨機數據。它還使用一個新的“lane assignment”。在每次訓練游戲開始時,我們隨機地將每個英雄“分配”給一些lane的子集,并在它發生偏離是對其進行懲罰,直到游戲中隨機選擇的時間。
這樣的探索得到了很好的回報。我們的獎勵主要由衡量人類如何在游戲中做決定的指標組成:凈價值,kills,死亡,助攻,上次命中等等。我們通過減去另一組的平均獎勵后處理每個agent的獎勵,以防止agent找到 positive-sum 的情況。
我們硬編碼項目和技能構建(最初為我們的腳本基準編寫),并選擇隨機使用哪些構建。
協調
OpenAI Five不包含英雄神經網絡之間的明確通信渠道。團隊合作由我們稱為“團隊精神”(team spirit)的超參數控制。team spirit的范圍從0到1,對OpenAI Five的每個英雄應該關心其個人獎勵函數與團隊獎勵函數的平均值賦予權重。我們在訓練中將它的值從0降到1。
快速
我們的系統是一個稱為Rapid的通用RL訓練系統,可用于任何Gym環境。我們已經使用Rapid解決了OpenAI的其他一些問題,包括競爭性的自我對戰。
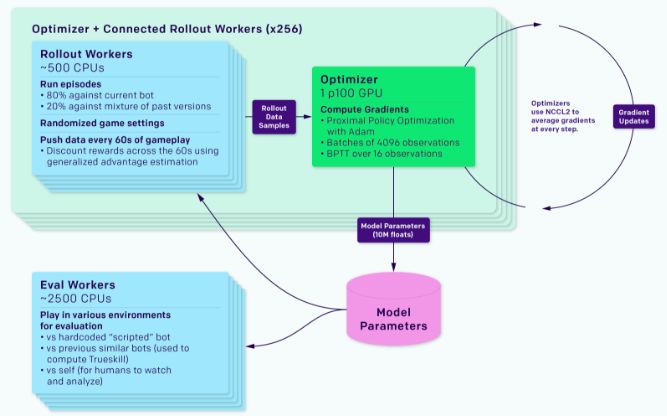
訓練系統分為運行游戲副本的rolloutworker和收集經驗的agent,以及optimizer節點,這些節點在整個GPU隊列中執行同步梯度下降。 rollout worker通過Redis將它們的經驗同步到optimizer每個實驗還包括訓練好的agent進行評估,以及監控軟件,如TensorBoard,Sentry和Grafana。
在同步梯度下降過程中,每個GPU計算batch部分的梯度,然后對梯度進行全局平均。下圖顯示了不同數量的GPU同步58MB數據的延遲。
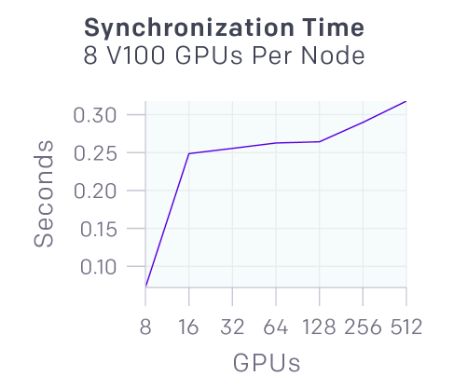
我們為Rapid實施了Kubernetes,Azure和GCP后端。
游戲結果
到目前為止,OpenAI Five已經(在我們的限制下)與這些對手進行了比賽:
最佳OpenAI員工團隊:2.5k MMR(46th percentile)
觀看OpenAI員工比賽的最佳觀眾(包括第一次OpenAI員工比賽的解說員Blitz):4-6k MMR(90th-99th percentile),盡管他們從來沒有作為一個團隊參賽。
Valve employee團隊:2.5-4k MMR(46th-90th percentile)。
業余團隊:4.2k MMR(93rd percentile),訓練為一支隊伍。
半專業團隊:5.5k MMR(99th percentile),訓練為一支隊伍。
4月23日版的OpenAI Five是第一個擊敗我們的腳本基線的版本。5月15號的OpenAI Five與第一隊旗鼓相當,贏了一場比賽,又輸了一場。6月6日的OpenAI Five戰勝了1-3對。我們和4隊、5隊建立了非正式的比賽,預計出現很差的表現,但是OpenAI Five在前三場比賽中均贏了兩場。
“機器人的團隊合作方面簡直勢不可擋,感覺就像五個無私的玩家一樣,知道一個很好的總體戰略。”——— Blitz
我們發現OpenAI Five:
為了換取控制敵人的優勢路safelane,多次犧牲自己的優勢路(上路是夜魘,下路是天輝),迫使戰斗向敵人更難防御的一邊進行。這種策略在過去幾年出現在專業領域,現在被認為是流行的策略。Blitz說他是在經過8年的比賽后才知道這一點的,當時Team Liquid告訴他這件事。
從比賽初期到賽季中期的轉場比對手更快。 它是這樣做的:(1)當玩家在他們路上過度擴張時,建立成功的Ganks;(2)在對手組織對抗之前組隊占領塔。
在少數領域偏離了目前的游戲風格,比如給予支持英雄許多早期經驗和黃金。 OpenAI Five的優先級使得它的傷害更早達到頂峰,并使它的優勢更加強大,贏得團隊戰斗并利用錯誤來確保快速的勝利。
與人類的不同之處
OpenAI Five可以訪問與人類相同的信息,但是它可以立即看到諸如位置、健康狀況和物品清單等數據,這些數據是人類必須手動檢查的。我們的方法與觀察狀態沒有本質的聯系,但是僅僅從游戲中渲染像素就需要數千個GPU。
OpenAI Five的平均動作速度約為每分鐘150-170個動作(理論上最大動作速度為450個,因為每隔4幀就觀察一次)。對于熟練的玩家來說,幀完美的時機對于OpenAI Five來說是微不足道的。 OpenAI Five的平均反應時間為80ms,比人類快。
這些差異在1v1中最為重要(我們的機器人的響應時間為67ms),但是我們已經看到人類從機器人身上學習并適應機器人,所以競技場相對比較公平。數十位專業人士在去年TI的幾個月里使用我們的1v1機器人進行訓練。根據Blitz的說法,1v1機器人改變了人們對1v1的看法(機器人采用了快節奏的游戲風格,現在每個人都適應了)。
一些驚人的發現
二元獎勵能夠帶來好的表現。我們的1v1模型有一個有形的獎勵,包括對最后命中目標、殺戮等等的獎勵。我們做了一個實驗,只獎勵那些獲勝的agent或只獎勵失敗的agent,它訓練一個數量級更慢,并且在中間有一些停滯,這與我們通常看到的平滑的學習曲線形成了對比。實驗運行在4500個內核和16個k80 GPU上,訓練到半專業級(70個TrueSkill),而不是我們最好的1v1機器人的90個TrueSkill。
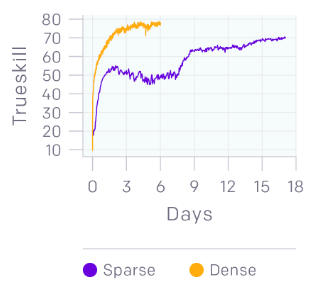
Creep blocking可以從頭開始學習。對于1v1,我們學習了使用傳統RL進行creep blocking并帶有“creep block”獎勵。我們的一個團隊成員在休假時離開了2v2模型的訓練,打算看看還需要多久的訓練才能提高性能。令他驚訝的是,這個模型學會了沒有任何特別的指導或獎勵的情況下creep block。
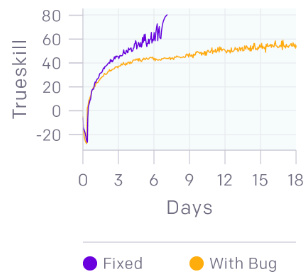
我們還在修復bug。上面的圖表顯示了擊敗業余玩家的代碼的訓練運行情況,相比之下,我們只是修復了一些bug,比如在訓練中偶爾發生的崩潰,或者達到25級時導致一個大的負面獎勵的錯誤。事實證明,這個系統有可能擊敗人類高手,但同時也可能隱藏著嚴重的bug!
接下來是什么?
我們的隊伍正集中精力完成我們8月份的目標。我們不知道這個目標能否實現,但我們相信,只要努力工作(還有點運氣),我們就能實現。
這篇文章描述了6月6日我們系統的快照。在超越人類性能的過程中,我們將發布更新,并在項目完成后就最終系統編寫報告。請在7月28日加入我們,屆時我們將與一組頂級球員比賽!
我們的目標是超越Dota。現實世界人工智能的部署將需要處理Dota提出的挑戰,而這些挑戰并不反映在國際象棋、圍棋、雅達利游戲或Mujoco基準測試任務中。最后,我們將衡量Dota系統在實際任務中的應用成功程度。
-
cpu
+關注
關注
68文章
10872瀏覽量
211999 -
神經網絡
+關注
關注
42文章
4772瀏覽量
100838 -
強化學習
+關注
關注
4文章
267瀏覽量
11263
原文標題:【攻克Dota2】OpenAI自學習多智能體5v5團隊戰擊敗人類玩家
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論