") 一種通用的圖像分類方法
一種通用的圖像分類方法
這篇文章介紹了作者在Kaggle植物幼苗分類比賽使用的方法,該方法連續(xù)幾個月排名第一,最終排名第五。該方法非常通用,也可以用于其他圖像識別任務。
任務概述
你能區(qū)分雜草和作物幼苗嗎?
有效做到這一點的能力意味著更高的作物產(chǎn)量和更好的環(huán)境管理。
奧爾胡斯大學信號處理小組與南丹麥大學合作發(fā)布了一個數(shù)據(jù)集,其中包含大約960種不同生長階段的植物的圖像,這些植物屬于12個物種。
樣本植物之一:繁縷樣本[3]
該數(shù)據(jù)集包含有標注的RGB圖像,物理分辨率約為每毫米10個像素。
為了規(guī)范對數(shù)據(jù)集獲得的分類結果的評價,研究者提出了基于F1分數(shù)的基準。
下面的圖是數(shù)據(jù)集中所有12個類的樣本:
圖像分類任務可以分為5個步驟:
步驟1
機器學習中的第一個也是最重要的任務是在繼續(xù)使用任何算法之前對數(shù)據(jù)集進行分析。這對于理解數(shù)據(jù)集的復雜性非常重要,最終將有助于設計算法。
圖像和類的分布如下:

如前所述,共有12個類,4750張圖像。但是,從上面的圖中可以看出,數(shù)據(jù)的分布不均勻,類的分布從最大有654張圖像到最小只有221張圖像。這表明數(shù)據(jù)不均衡,數(shù)據(jù)需要均衡才能獲得最佳結果。我們將在第3個步驟講這一點。
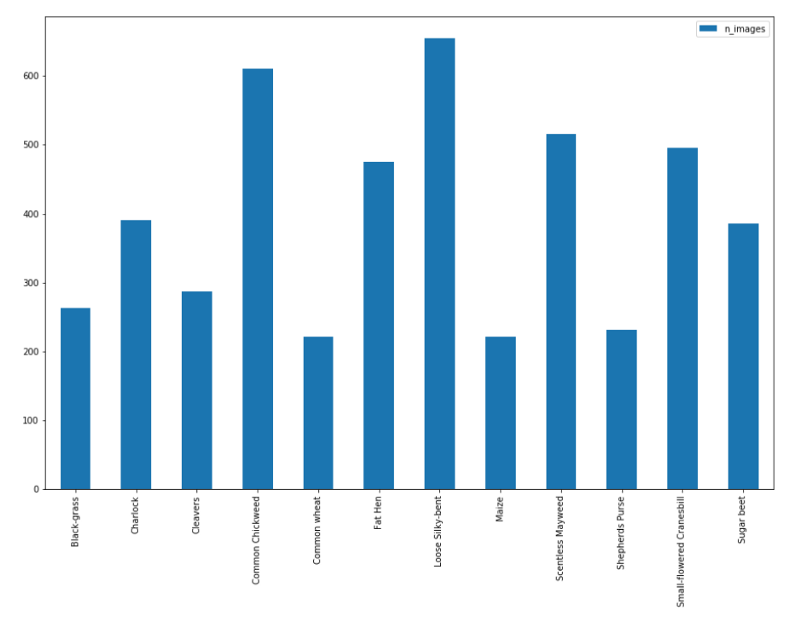
每個類的圖像分布
為了更好地理解數(shù)據(jù),對圖像進行可視化非常重要。因此,每個類中會拿出一些示例圖像,以查看圖像之間的差異。

從上面的圖中得不到什么理解,因為所有的圖像看起來都差不多。因此,我決定使用被稱為t分布隨機鄰域嵌入(t-SNE)的可視化技術來查看圖像的分布。
t-SNE是降維的一種技術,特別適用于高維數(shù)據(jù)集的可視化。該技術可以通過Barnes-Hut近似實現(xiàn),使其可以應用于大型真實世界的數(shù)據(jù)集[14]。
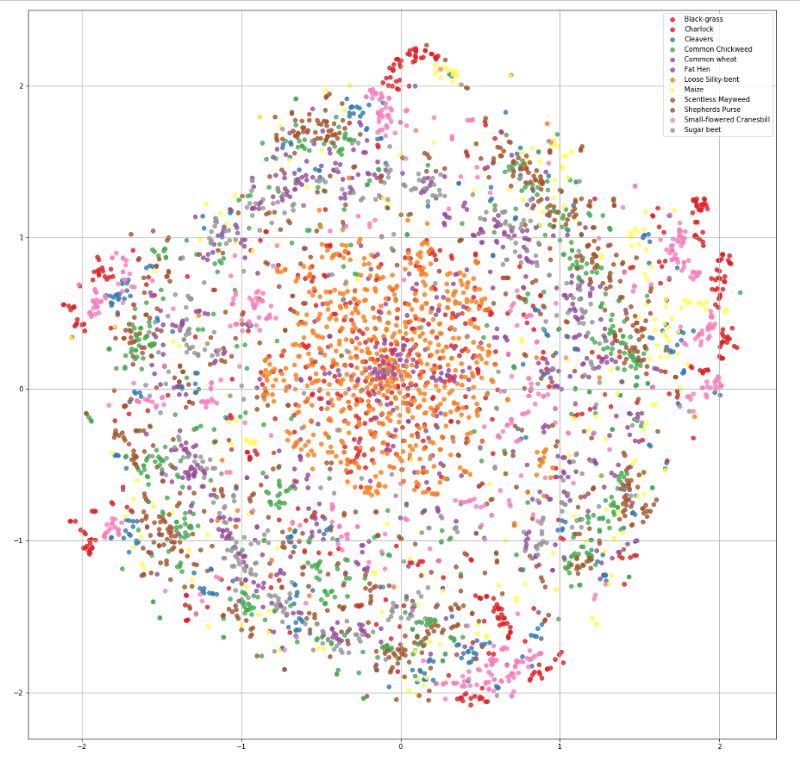
數(shù)據(jù)集的t-SNE可視化
現(xiàn)在,仔細觀察后,我們幾乎看不出不同類之間的差異。數(shù)據(jù)的差異是只對人類來說很難區(qū)分,還是不管對人類還是對機器學習模型來說都很難區(qū)分,了解這一點很重要。因此,我們將做一個基本的benchmark。
訓練集和驗證集
在開始使用模型基準之前,我們需要將數(shù)據(jù)劃分為訓練數(shù)據(jù)集和驗證數(shù)據(jù)集。在模型在原始測試集上進行測試之前,驗證集扮演測試數(shù)據(jù)集的角色。因此,基本上一個模型在訓練數(shù)據(jù)集上進行訓練,在驗證集上進行測試,然后在驗證集上對模型進行改進。當我們對驗證集的結果滿意,我們就可以將模型應用到真實測試數(shù)據(jù)集上。這樣,我們可以在驗證集上看到模型是過擬合還是欠擬合,從而幫助我們更好地擬合模型。
對有4750張圖像的這個數(shù)據(jù)集,我們將80%的圖像作為訓練數(shù)據(jù)集,20%作為驗證集。
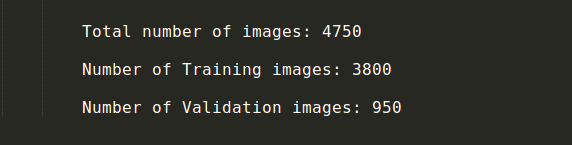
分開訓練數(shù)據(jù)和驗證數(shù)據(jù)
步驟2
有了訓練集和驗證集后,我們開始對數(shù)據(jù)集進行基準測試。這是一個分類問題,在給出一個測試數(shù)據(jù)時,我們需要將它分到12個類中的一個。我們將使用卷積神經(jīng)網(wǎng)絡(CNN)來完成這個任務。
創(chuàng)建CNN模型有幾種方法,但對于第一個基準,我們將使用Keras深度學習庫。我們將在Keras中使用現(xiàn)有的預訓練好的模型,我們將對其進行微調(diào)以完成我們的任務。
從頭開始訓練CNN是低效的。因此,我們使用一個在有1000個類的ImageNet上預訓練的CNN模型的權重,通過凍結某些層,解凍其中一些層,并在其上進行訓練,對其進行微調(diào)。這是因為頂層學習簡單的基本特征,我們不需要訓練那些層,它們可以直接應用到我們的任務中。需要注意的是,我們需要檢查我們的數(shù)據(jù)集是否與ImageNet相似,以及我們的數(shù)據(jù)集有多大。這兩個特性將決定我們?nèi)绾芜M行微調(diào)。
在這個例子中,數(shù)據(jù)集很小,但有點類似于ImageNet。因此,我們可以首先直接使用ImageNet的權重,只需添加一個包括12個類的最終輸出層,以查看第一個基準。然后我們將解凍一些底部的層,并且只訓練這些層。
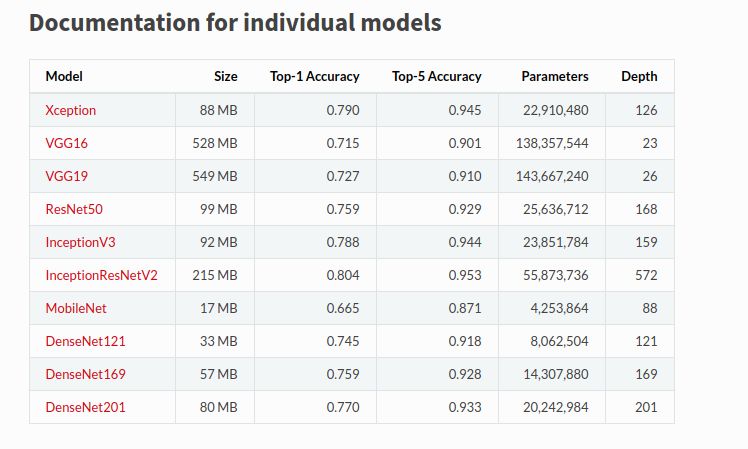
我們將使用Keras作為初始基準,因為Keras提供了許多預訓練模型。我們將使用ResNet50和InceptionResNetV2來完成我們的任務。使用一個簡單的模型和一個非常高的終端模型對數(shù)據(jù)集進行基準測試是很重要的,可以了解我們是否在給定模型上過擬合/欠擬合數(shù)據(jù)集。

此外,我們可以在ImageNet數(shù)據(jù)集上檢查這些模型的性能,并檢查每個模型的參數(shù)數(shù)量,以選擇我們的基準模型。
對于第一個基準測試,我刪除了最后一個輸出層,只添加了一個帶有12個類的最終輸出層。此外,還打印了模型摘要和參數(shù)的數(shù)量,下面是最后幾層的截圖。

添加一個dense層以得到第一個基準
模型運行了10個epochs,6個epochs后結果達到飽和。訓練精度達到88%,驗證精度達到87%。

為了進一步提高性能,我們從底部解凍了一些層,并以指數(shù)衰減的學習率訓練了更多的層。這個過程將精度提高了2%。

從底層開始訓練幾層后的結果
此外,該過程中還使用了以下超參數(shù):

步驟3
準備好基本的基準后,就可以改進它了。我們可以從增加更多數(shù)據(jù)開始,增加數(shù)據(jù)集中圖像的數(shù)量。
沒有數(shù)據(jù),就沒有機器學習!
但首先這個數(shù)據(jù)集不均衡,需要進行均衡,以便每批都使用偶數(shù)個圖像作為模型的訓練數(shù)據(jù)。
現(xiàn)實生活中的數(shù)據(jù)集從來都不是均衡的,模型在少數(shù)類上的性能也不是很好。因此,將少數(shù)類的樣本錯誤地歸類到正常類樣本的成本通常要比正常類錯誤的成本高得多。
我們可以用兩種方法來均衡數(shù)據(jù):
1.ADASYN采樣方法:
ADASYN為樣本較少的類生成合成數(shù)據(jù),其生成的數(shù)據(jù)與更容易學習的樣本相比,更難學習。
ADASYN的基本思想是根據(jù)學習難度的不同,對不同的少數(shù)類的樣本使用加權分布。其中,更難學習的少數(shù)類的樣本比那些更容易學習的少數(shù)類的樣本要產(chǎn)生更多的合成數(shù)據(jù)。因此,ADASYN方法通過以下兩種方式改善了數(shù)據(jù)分布的學習:(1)減少由于類別不平衡帶來的偏差;(2)自適應地將分類決策邊界轉移到困難的例子[5]。
2.合成少數(shù)類過采樣技術(SMOTE):
SMOTE涉及對少數(shù)類進行過采樣(over sampling),并對大多數(shù)類進行欠采樣(under sampling)以獲得最佳結果。
對少數(shù)(異常)類進行過采樣和對大多數(shù)(正常)類進行欠采樣的方法的組合,相比僅僅對大多數(shù)類進行欠采樣可以得到更好的分類器性能(在ROC空間中)。
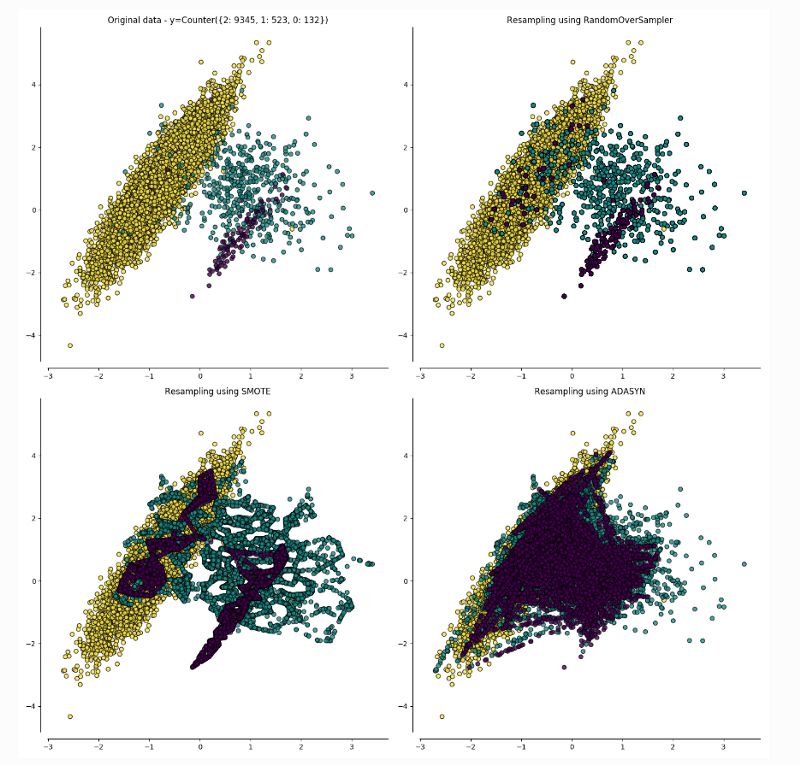
對于這個用例,SMOTE的結果被證明更好,因此SMOTE比ADASYN更受歡迎。一旦數(shù)據(jù)集達到平衡,我們就可以繼續(xù)進行數(shù)據(jù)增強(data augmentation)。
有幾種方法可以實行數(shù)據(jù)增強。比較重要的一些是:
縮放
裁剪
翻轉
旋轉
平移
添加噪音
改變照明條件
先進的技術,如GAN
已經(jīng)有一些很好的博客解釋了這些技術[8][9],所以本文不再詳細解釋。在這個任務中,除GAN外,以上所有數(shù)據(jù)增強技術都使用到。
步驟4
現(xiàn)在,為了進一步提高成績,我們使用了學習率,包括周期性學習率(cyclical learning rate)和熱重啟學習率(learning rate with warm restarts)。但在此之前,我們需要找到模型的最佳學習率。這是通過繪制學習率和損失函數(shù)之間的圖,來檢查損失從哪里開始減少。
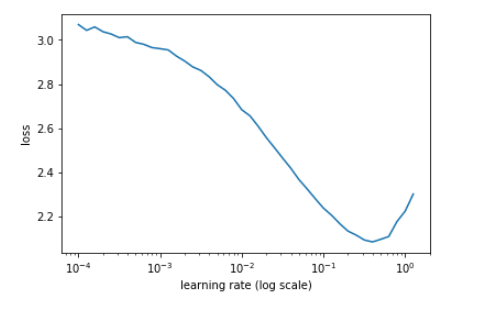
學習率與損失的關系圖
在我們的例子中,1e-1看起來是一個完美的學習率。但是,隨著我們越來越接近全局最小值,我們希望采取更短的步驟。一種方法是學習率退火(learning rate annealing),但是我采用了熱重啟學習率,啟發(fā)自SGDR: Stochastic Gradient Descent with Warm Restarts[10]這篇論文。同時將優(yōu)化器從Adam改為SGD,實現(xiàn)SGDR。
現(xiàn)在,可以使用上述技術來訓練多個架構,然后將結果合并在一起。這稱為模型融合(Model Ensemble),是流行的技術之一,但是計算量非常大。
因此,我決定使用一種稱為snapshot ensembling[12]的技術,通過訓練單個神經(jīng)網(wǎng)絡,使其沿著優(yōu)化路徑收斂到多個局部最小值,并保存模型參數(shù),從而實現(xiàn)集成的目的。
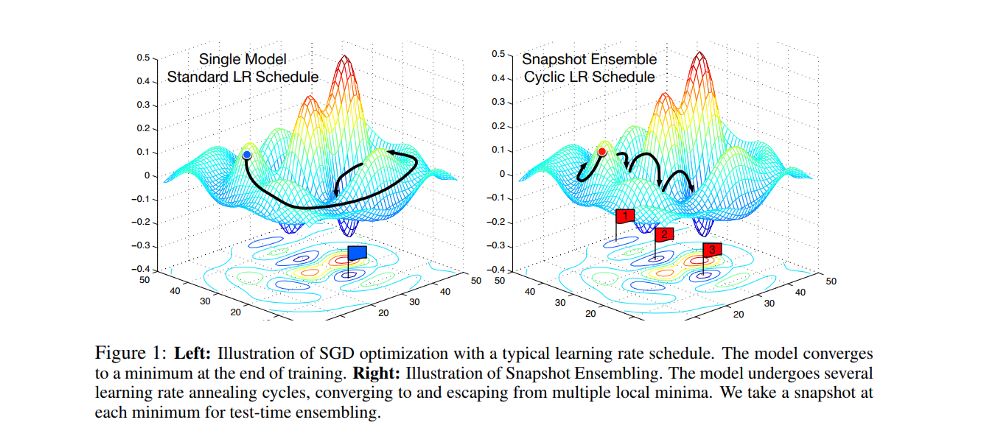
一旦確定了學習率的方法,就可以考慮圖像的大小。我用64 * 64大小的圖像(微調(diào)了ImageNet)訓練模型,解凍了一些層,應用 cyclic learning rate和snapshot ensembling,采用模型的權重,改變圖片尺寸為299 * 299,再以64*64圖像的權重進行微調(diào),執(zhí)行snapshot ensembling和熱重啟學習率。
如果我們改變圖像大小,需要再次運行學習率vs損失函數(shù)以獲得最佳學習率。
步驟5
最后一步是將結果可視化,以檢查哪些類具有最佳性能,哪些表現(xiàn)最差,并且可以采取必要的步驟來改進結果。
理解結果的一個很好的方法是構造一個混淆矩陣(confusion matrix)。
在機器學習領域,特別是統(tǒng)計分類問題中,混淆矩陣(也稱為誤差矩陣)是一種特定的表格布局,能夠可視化算法的性能,通常是監(jiān)督學習(在無監(jiān)督學習中通常稱為匹配矩陣)。矩陣的每一行表示預測類中的實例,而每列表示實際類中的實例(反之亦然)。這個名字源于這樣一個事實:它可以很容易地看出系統(tǒng)是否混淆了兩個類別。
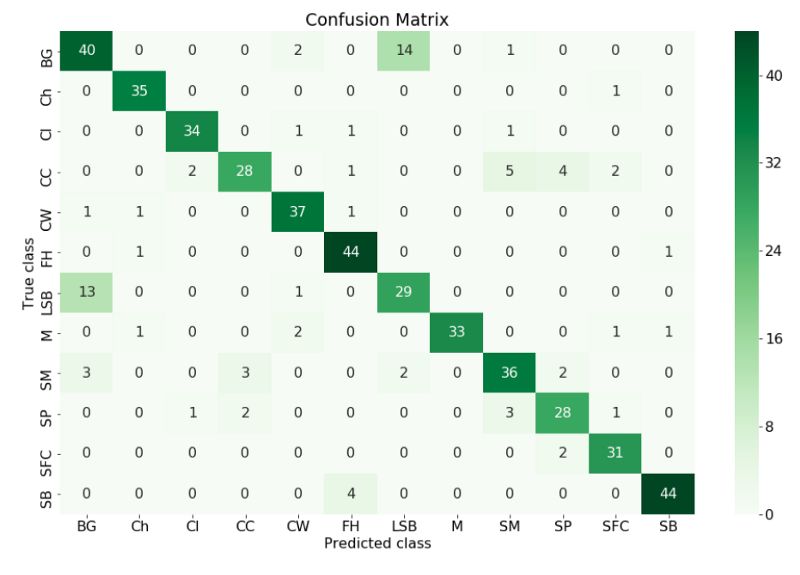
真實類vs在混淆矩陣中預測類
我們可以從混亂矩陣中看出模型預測標簽與真實標簽不同的所有類,我們可以采取措施來改進它。我們可以做更多的數(shù)據(jù)增強來嘗試讓模型學習這個類。
最后,將驗證集合并到訓練數(shù)據(jù)中,利用所獲得的超參數(shù)對模型進行最后一次訓練,并在最終提交之前對測試數(shù)據(jù)集進行評估。
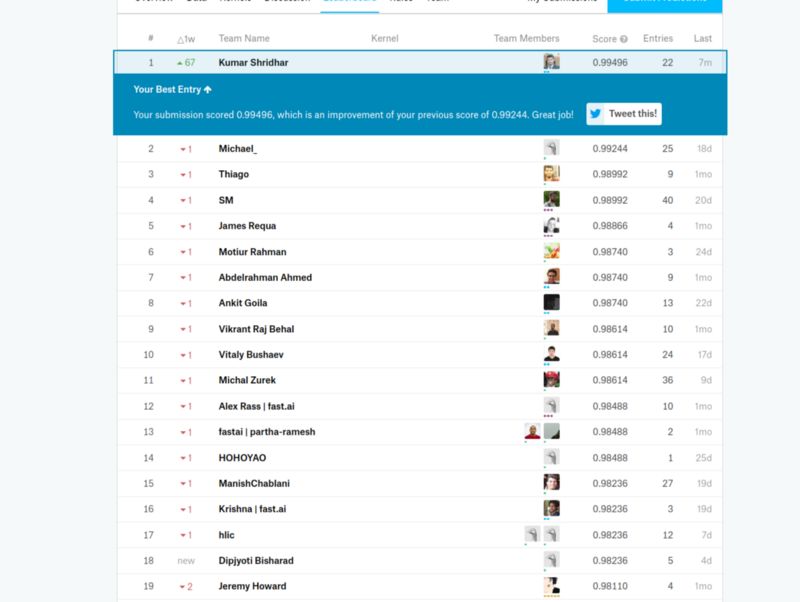
最終提交后排名第一
注意:在訓練中使用的增強需要出現(xiàn)在測試數(shù)據(jù)集中,以獲得最佳結果。
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4771瀏覽量
100715 -
圖像分類
+關注
關注
0文章
90瀏覽量
11914 -
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24689
原文標題:從0上手Kaggle圖像分類挑戰(zhàn):冠軍解決方案詳解
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
一種新的圖像定位和分類系統(tǒng)實現(xiàn)方案
基于Brushlet和RBF網(wǎng)絡的SAR圖像分類
一種基于Web挖掘的音樂流派分類方法
一種改進的小波變換圖像壓縮方法
一種具有反饋機制的名片信息分類方法
一種Spark高光譜遙感圖像稀疏表分類并行化方法
基于數(shù)據(jù)挖掘的醫(yī)學圖像分類方法
一種旋正圖像使用中心點進行指紋分類的方法

一種堅固特征級融合和決策級融合的分類方法
一種基于人臉圖像陰影集的二級分類模型

一種全新的遙感圖像描述生成方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論