 如何對互聯網圖像實現像素級別的語義識別
如何對互聯網圖像實現像素級別的語義識別
“天街小雨潤如酥,草色遙看近卻無。”從韓愈的這兩句詩可以看出,人對圖像內容的語義理解,并不依賴于細粒度監督信息做輔助。與之相比,在機器學習領域,現階段的語義分割任務,則依賴于大量的精細標注數據。互聯網,作為最為豐富的數據源,吸引著相關從業人員的目光,然而要想利用這些數據,則面臨著巨大的標注壓力。
因此,引發了兩點思考:第一,能否結合關鍵詞信息作輔助,從web中直接學習知識,而不需要精細的人工標注呢?第二,能否利用類別無關的線索,在標注少量類別的數據集上訓練好后,將其泛化到其他所有類別物體呢?
本文中,來自南開大學的程明明教授,將從這兩點展開介紹目前的研究進展。


傳統像素級語義理解方法,通常需要大量精細標注的圖像訓練。上圖所示的是ADE20K數據集中的一個例子,該數據集包含21萬個精細標注的物體的圖像,是由Antonio教授的母親花了很長時間標注的。

Antonio教授曾在CVML2012上開玩笑的說:“我的母親標注了這樣一個優質的數據集,真希望我有更多的母親”。這是一句玩笑話,但也說明了構建數據集的重要性,以及構建它所需時間和精力之大。
回顧我們的成長過程,從小到大,我們的父母從未給我們做過如此精細的標注,去幫助我們識別和認知周圍的世界。通常的學習方式是,父母給我們看一朵花并告訴我們這是朵花,然后我們就能很輕易的知道哪些區域、哪些像素對應著這朵花。那么我們是怎樣利用這些信息,學習到每個像素所代表的語義內容呢?同時,這樣一種信息能否幫我們更好的去理解圖像的內容,對圖像進行精細的語義理解?

我們的研究內容就是怎樣去利用類似機制移除對精細標注信息的依賴。在生活中,當我們想要了解一種我們不熟悉的物體時,比如一種水果,通常我們只需要在網上搜索一下,觀察幾張圖片,就能對這種水果有充分的認識,并能輕松識別對應目標及目標區域。能不能讓計算機擁有從web中直接學習知識的能力,而不需要精細的人工標注呢?

可以幫助像素級語義理解的相關的工作有很多,比如說顯著性物體檢測:給定一張圖像,發現并找到圖像中的顯著性物體,這些信息是很關鍵的。舉個例子,當我們使用關鍵詞在網上檢索圖像的時候,通常檢索的圖像和關鍵詞之間有很強的相關性,通過顯著性目標檢測,我們可以假設檢測結果對應的顯著性區域語義信息就是其關鍵詞,當然這種假設是存在噪聲或者說錯誤的。

除了顯著性目標(saliency)檢測以外,還有圖像的邊緣檢測,圖像的過分割(over segmentation)等信息。這些信息都是類別無關的,可以從很少的數據集中訓練出一個很好的通用模型。如邊緣檢測,我們可以從只有500個數據的BSD數據集中訓練出一個很好的邊緣檢測模型。邊緣能夠很好描述物體的邊界,從而能夠減少對精細標注的依賴。同樣的,過分割以及顯著性檢測也有同樣的效果。一個直接的想法就是能否利用這些類別無關的線索(cues),在標注少量類別的數據集上訓練好后,將其泛化到其他所有類別物體呢?哪怕是我們沒有見過的物體,在不知道該物體類別的情況下,我們也能找到該物體所對應的區域。

沿著這個想法,有了我們的第一個工作:顯著性物體檢測,該工作發表在2017 CVPR以及2018 TPAMI上。下面我們介紹下該工作。
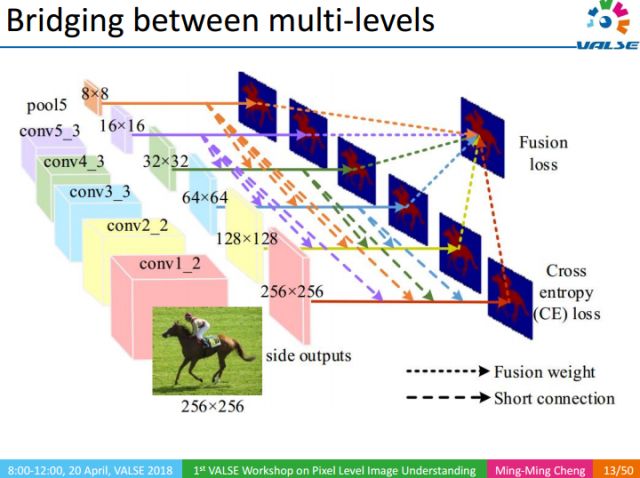
該工作的核心思想是以多尺度Deeply Supervised的方式,把不同尺度的信息融合起來,從多個尺度去檢測顯著性物體的區域。由于CNN中底層的特征和高層特征分別更擅長做細節描述和全局定位,而不夠全面,因而難以獲得高質量的分割結果。我們通過將頂層信息往下傳遞的方式去豐富底層的信息,這樣既能夠很好的定位又能保持細節。

這里是一些示例結果。我們的重點不是想說明怎樣去做顯著性物體檢測,而是想傳達一個重要的信息,即通過顯著性物體檢測,我們能夠將圖像中的顯著性物體分割得很好。這個發現能幫助機器直接從web學習像素級語義分割。

上圖展示了我們的方法在不同場景下的檢測結果,可以看到,即使在對比度很低、物體很復雜的情況下,我們的顯著性物體檢測方法仍能很好地找到物體的區域。
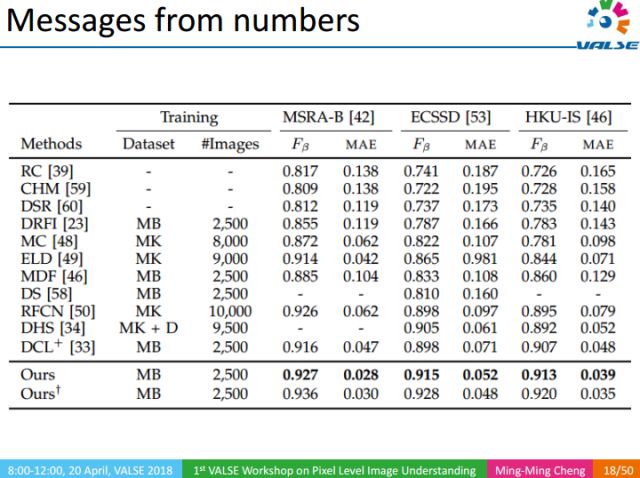
同時,在常見的數據集里面,我們算法的Fβ性能指標都超過了90%。為了驗證算法的泛化能力,我們在不同數據集之間進行交叉驗證,實驗結果表明,我們的顯著性目標檢測方法,能夠從少量類別標注(如1000類)的數據中學到類別無關的工具,而這種工具在不知道物體的類別的情況下,也能很好的將其從圖像中分割出來。
該方法也存在一些不足,例如,在場景特別復雜(如摩托車)或者顯著性物體特別含糊(如貓的右半邊)的情況下,我們的方法也會失敗。
前文提到,我們的方法在多個數據集上的Fβ性能均能超過90%,能夠很好的定位出顯著性物體。上圖是我們這個工作的一個應用,它被應用于華為手機的智能拍照:在拍照的過程中自動找到前景目標,使得相機能夠實現大光圈拍照。而傳統大光圈拍照需要用到單反相機(額外物理負擔)來得到前清后虛、虛實結合的藝術效果。

另外一個很重要的類別無關信息是邊緣檢測。邊緣有助于定位物體的位置。如上圖所示,在不知道動物具體類別的情況下,只需知道圖像中有動物(關鍵詞級別的label),我們就能找到動物所對應的區域。下面我們介紹發表在CVPR 2017上的工作(RCF)。
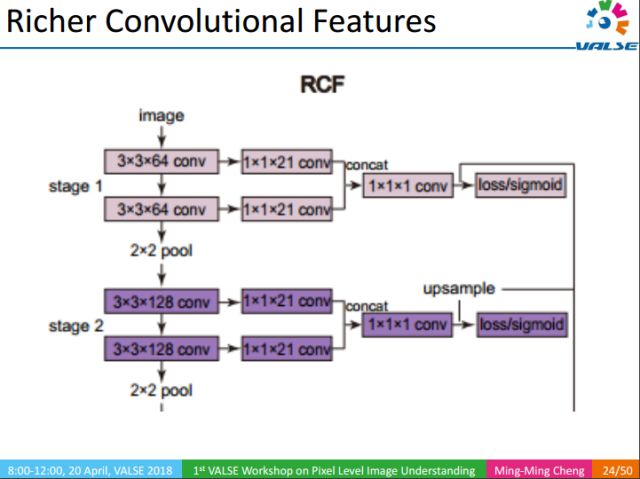
RCF的核心思想是利用豐富的多尺度的特征去檢測自然圖像中的邊緣。在早期分類任務中,中間層往往被忽略掉了,后來人們通過1x1卷積層對中間層加以利用。但這些工作只使用了每個stage的最后一個卷積層,實際上每個卷積層對于最終結果都是有用的。RCF將所有卷積層通過1x1卷積層進行融合。這種融合有效的提升了邊緣檢測的效果。

舉個例子,在圖像中的稻草區域,傳統的方法如canny算子等在這些區域都會有非常高的響應,但RCF能夠很好的抑制掉這些響應。還有如沙發,茶幾等人都很難觀測到邊緣的區域,RCF都能魯棒的檢測到邊緣,其結果甚至比原圖結構看的更清晰。這給我們實現直接從Web中學習提供了一個基礎。
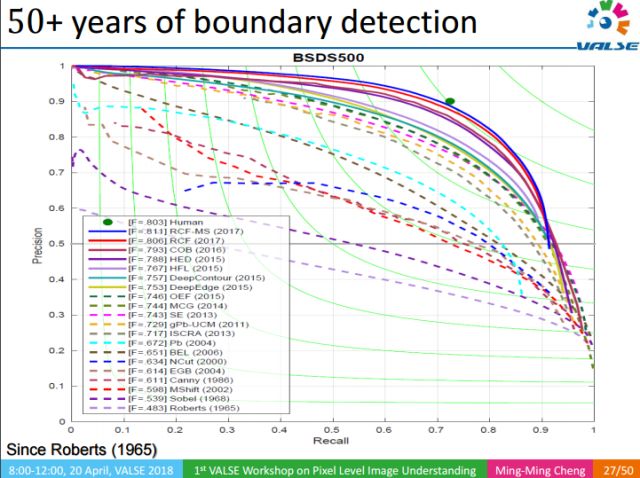
作為計算機視覺最早開始研究的問題之一,邊緣檢測經歷了50多年的發展,但RCF是第一個能夠做到實時檢測,同時性能超過伯克利數據集上的人工標注的工作。當然這并不意味著RCF超過了人類,只要給人足夠的時間仔細思考,人能標注的更好,但RCF無疑算是取得了重大突破。而且訓練如此強大的邊緣檢測模型,僅僅使用了一個含有500張圖像的數據集,這對于我們直接從Web學習是非常有啟發的。

好的過分割結果,能夠有效的輔助像素級語義理解(特別是在人工標注數據少的情況下)。過分割(over segmentation)也是一種重要的類別無關的信息,上圖的過分割結果雖然形似語義分割(semantic segmentation),但又有本質的區域。在語義分割中,每一個像素都有明確的語義標簽,因此我們可以通過神經網絡去學習每個像素具體的語義信息。而過分割只是將圖像劃分成很多不同的區域,每個區域對應一個標簽。這些標簽沒有確定的語義信息,因此給定一幅圖像,我們無法確定每個圖像能產生多少的區域,也不能確定每個圖像能產生多少標簽(100, 1000 或1000?),這個問題給學習帶來了很多大的困難。下面介紹我們發表在IJCAI2018上的工作。

我們的方法并不直接把像素和標注對應起來,而是先將圖像進行超像素化,以提高計算速度,然后提取超像素的卷積特征,再將每個超像素的特征pooling為固定長度的向量,最后學習每兩個超像素之間的距離。當超像素之間的距離小于一個閾值的時候將其合并(merge)。相比傳統方法,我們的方法簡單、有效,取得了很好的結果,且能實時處理(50fps/s)。這也給直接從互聯網學習像素級語義理解提供了支撐。

有了上述提到的類別無關的底層視覺知識后,我們可以對圖像做很多有意思的分析。例如,我們使用關鍵詞在互聯網上檢索圖像,通過顯著性目標檢測,可以檢測出物體在圖像中大概的位置,然后通過邊緣、過分割等信息可以進一步精確物體的區域信息。最終可以生成proxy groundtruth(GT),這種GT不是人工標注的,是我們用自動化的方法對互聯網圖像GT的一種猜測。這種猜測很可能覆蓋了關鍵詞在圖像中對應的區域,當然這些區域中會存在很多誤差。例如對上圖中的自行車進行分割時,我們的方法往往把人也標記出來了,因為通常自行車是和人一起出現的。
那么怎么去剔除掉這些誤差呢?
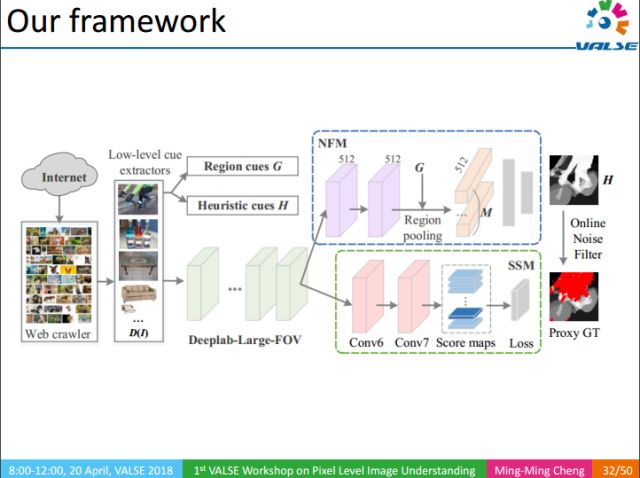
整個方法的流程如下:1利用關鍵詞檢索得到大量圖像;2利用底層視覺知識,得到圖像對應proxy GT;3利用NFM去除proxy GT中的噪聲區域對訓練過程的影響;4最終通過SSM部分得到語義分割結果。

NFM(Noise Filtering Module):噪聲濾波模塊,給定輸入圖像,利用圖像級的標注以及相應的heuristic map,過濾圖像Proxy GT中的噪聲區域。

上圖中紅色區域為識別出來的噪聲區域。
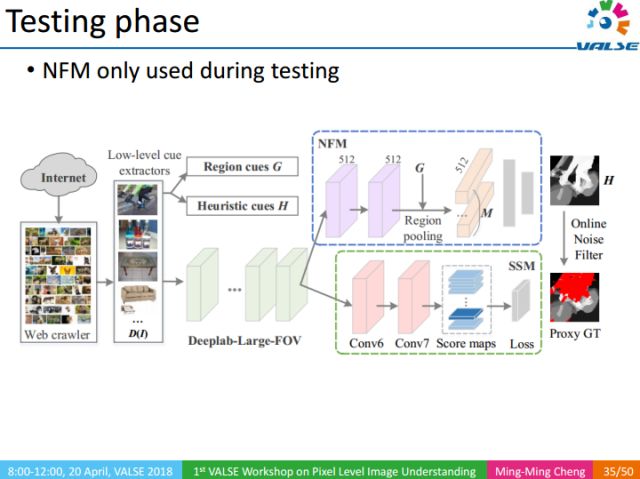
NFM作為一種輔助訓練的方法,只在測試階段使用。
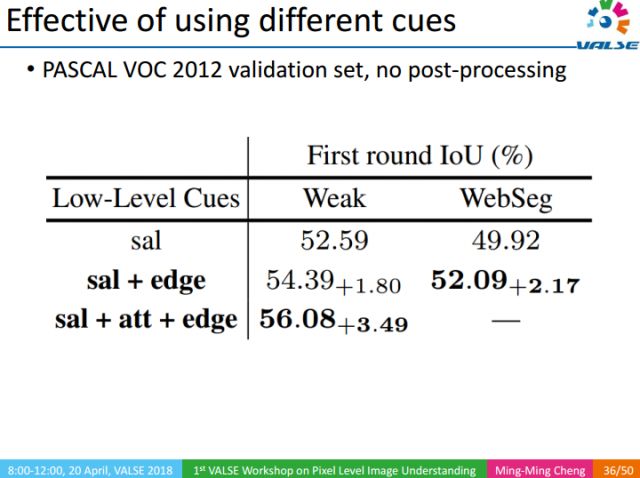
我們通過實驗,分別驗證了底層視覺知識的重要性。實驗分為兩類,Weak表示圖像只有一個關鍵詞級別的標注,WebSeg則表示圖像沒有任何人工標注。實際上,底層視覺知識有很多類,我們這里只展示了3類,分別是Saliency object Detection(sal),Edge,Attention(att)。Attention是一種自頂向下的信息,需要有關鍵詞級別的標注信息,由于WebSeg沒有使用任何人工標注,所以在WebSeg的實驗中沒有attention。

同樣,我們還驗證了NFM的有效性。可以看出,NMF能夠提升IoU準確度。

在訓練過程中,訓練的數據可以分為三類,D(S):圖像內容簡單,每個圖像有一個人工審核過的圖像級標注;D(C):圖像內容復雜,每個圖像有多個審核過的圖像級標注;D(W):圖像內容不定,每個圖像有一個未經審核的標注。
上表中列出了不同訓練集組合對應的不同性能。

使用CRF能進一步提高結果的精度。

上圖是我們的實驗結果,從左至右,分別可以看出NFM以及CRF的重要性。總體而言,我們的方法能直接從Web圖像中學習并得到很好的語義分割的結果。

上表是在PASCAL 2012上的實驗結果,在使用了大量的底層視覺知識后,我們方法平均IOU能達到63%,相比于去年CVPR上最好結果的58%有著很大的提升。
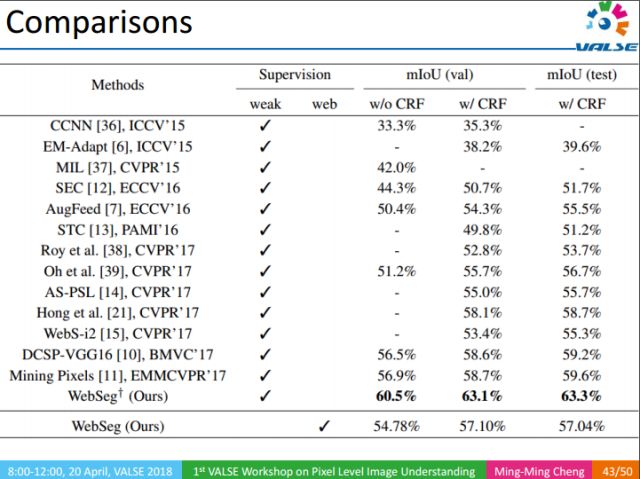
另一很有意義的結果是,在不使用顯式人工標注的情況下,我們仍然能取得57%的結果。這一結果實際上超過了CVPR 2017中很多弱監督的方法。事實上,弱監督信息的標注也是很花費時間和精力的,相比而言,我們的方法則無需要任何人工標注。在直接讓機器從Web學習像素級語義分割這個方向上,我們只是進行了初步的嘗試,但它能在PASCAL VOC這個量級的數據集上能超過CVPR 2017大部分弱監督的結果,是很令人興奮的。長遠來看,這是一個很有意義的研究方向。

總結整個報告,我們提出了一個很有意義且很有挑戰性的視覺問題:即在沒有人工標注的情況下,怎樣直接從Web中學習語義分割。同時我們還提出了一種在線的噪聲濾波機制,讓CNN學習如何剔除Web學習結果中的噪聲區域。整個工作的目的在于:降低或移除像素級語義理解任務對精細標注數據的依賴性。

我們目前只是觸及了純web式監督學習領域的皮毛,后續還有很多值得研究的工作,例如:
1. 怎樣把圖像有效利用起來,目前的工作,對Web圖像不分好壞直接處理,沒有做更多的學習,我們要思考是否能夠通過學習的方式提升web圖像的使用效率;
2. 又或者是否可以把底層視覺知識和其對應的關鍵詞關聯起來,如Salient Object Detection,之前是沒有與其對應的標注聯系起來的,這種相關性能否進一步提升結果?
3. 以及,提升類別無關的底層視覺知識本身的性能,如邊緣檢測、過分割等;
4. 此外還有其他一些純粹的Web監督的任務。

我們還做了許多與底層視覺知識相關的工作,如Over-segmentation。

Salient-Instance Segmentation,也是一種類別無關的信息,雖不知道物體類別,但它能把顯著的instance分割出來。
-
互聯網
+關注
關注
54文章
11148瀏覽量
103234 -
機器學習
+關注
關注
66文章
8406瀏覽量
132566
原文標題:互聯網圖像中的像素級語義識別
文章出處:【微信號:deeplearningclass,微信公眾號:深度學習大講堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種圖像語義分層處理框架,可以實現像素級別的圖像語義理解和操縱







 工商網監
工商網監
評論