 Magic Leap終于向我們演示了通過Magic Leap One的AR
Magic Leap終于向我們演示了通過Magic Leap One的AR
Magic Leap在Twitch上的幾次直播演示可以說都在畫餅,對于實機以及操作并沒有進行深入的講解,這也讓大家對于它如何運作充滿了各種假設以及好奇心。
在前幾天,也就是6月21日的Unite Berlin大會上,Magic Leap講解了如何開發Magic Leap One,在其中包含了諸多Magic Leap One工作及運行的細節,那就讓我們一起來看看吧。最關鍵的是,Magic Leap終于向我們演示了通過Magic Leap One的AR。
首先他們提出的是通過他們的技術,Magic Leap One的AR會真實的融入到環境當中去,可以讓用戶和平時一樣觀看,而不是與現在的AR眼鏡一樣疊加在視野的上方。不過他們并沒有講解他們用的是什么技術,就當成他們畫的另外一張大餅算了。
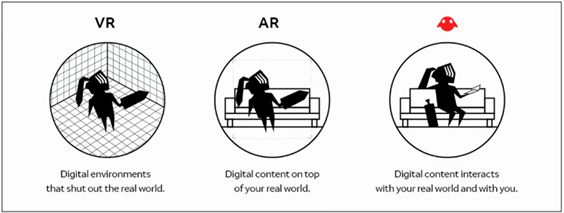
不過得到了一張餅也要失去一張餅,這就是大餅守恒定律。
Magic Leap交互實驗室的負責人Schwab表示,Magic Leap One的視場是有限的,并沒有此前宣稱的那么神奇。不過他也沒有具體說明有限到多少,而是告訴開發者再知道Magic Leap One有限的視場后如何改變他們的開發思路。
Schwab提出了四個觀點他認為開發者應該注意的,分別為“Less is More”、“Respect The Real World”、“Getting your Attention”、“Reality Considerations”。
“少即是多”用在這里實在是太取巧了,Schwab提出的這三點其實都很中肯。在AR體驗當中,應當以讓用戶體驗到虛擬與現實之間的融合,將AR作為現實世界的延伸,而在視場中過多的填充就會造成反效果。
不過考慮到這是對于MLO有限的視場而做出的策略改變,只能拍著手說有道理了。
這條也是對于“少即是多”的闡述,Schwab做了一個比喻,AR就好比現實世界中的客人,主角任然是現實世界,AR不能喧賓奪主,可以使用更多的線索引導用戶。
不過對于有限的視場也可以用其他方法補救。通過眼動追蹤我們可以知道用戶正在看什么,當用戶視線不在目標上的時候,我們可以通過空間化音頻或者是外圍視場中的運動來引導用戶的視線。
在設計的同時,也要考慮到用戶的安全。比如你正在走一個下坡路,而AR信息在上方,這就很容易造成事故。而且在沉浸感強烈的情境下,人們的聽覺會下降,甚至什么都聽不到,這將會造成十分嚴重的結果,這也是Schwab提醒開發者需要十分注意的事情。

在用戶數據方面,MLO會從五方面進行收集。分別是頭部姿勢、雙手、雙眼、語音還有地理/臨時信息。
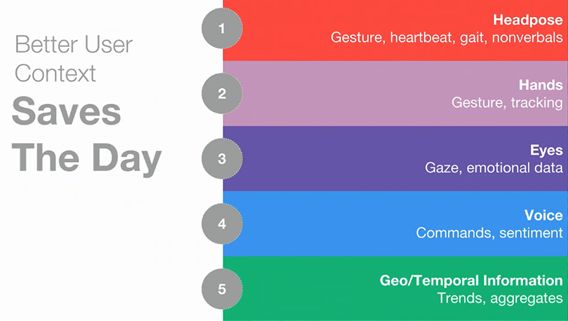
頭部姿勢能夠搜集不僅能分析搖頭和點頭和其他的頭部運動,還能檢測心跳、步姿和你走路的速度等。
對于眼睛的眼動追蹤和語音命令這兩個功能,除了本職工作以外,還能夠通過眼睛的形態和聲調的高低大小來判斷用戶的情緒。
通過眼睛收集的信息主要來自于眼睛停止轉動的時刻,我們的眼睛一直在不斷地轉動(這期間的速度很快,幾乎采集不到什么信息),如果它沒動說明我們正在經歷某些事情。這時就會采用到心理學的知識,比如眼睛向下看說明在思考,向左上方看時在思考。
最令人意外的還是第一次被透露的地理信息和臨時信息的收集,通過收集用戶之間交互的地理信息與臨時信息來分析趨勢,來為用戶判斷更好的選擇。不過如何運行這項功能,并未透露。
至于手部姿勢,MLO可以識別八種手勢,如下圖所示。
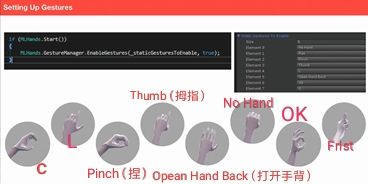
在識別手勢時,將會先由頭部姿勢判斷,然后開啟深度攝像頭掃描近場來識別手勢,能夠同時識別雙手的手勢。在手勢識別的時候,會有八個點跟蹤,這將會把八個特定的手勢和平常的手勢區分開來。
說到這里就要談一下MLO的交互模式了。MLO對于指令的輸入是對綜合頭部、眼動追蹤、手勢信息進行的綜合,將頭部姿勢與視線還有手勢相結合。
比如眼前有三個方塊,通過頭部姿勢和眼動追蹤能夠知道你正在看的是哪一個方塊,然后再識別手勢例如Thumb就能夠選中那個方塊了,也就是說能夠預判用戶的選擇。
通過之前所講對于用戶心理的分析,MLO可以判斷用戶是有目的的選擇,而不是隨便瞎選,從而達到準確的預判。
這種操作設置其實也比較符合人本身的運動規律,在同一時間是多個器官同時運作的。
而與之配套的,Magic Leap開發了一套多式交互模型——TAMDI。

代表著五個步驟,分別為Targeting(目標)、Activation(獲取)、Manipulation(操縱)、Deactivation(失活)、Integration(整合),五個步驟構成一個循環過程,對頭、眼、手三個部位的信息進行整合判斷。
說了半天終于要講到MLO的演示視頻了,不過在此之前我們先來看看公布的Magic Leap的工具包——Magic Kit。受限于信息與篇幅(最主要還是丸子醬不懂),就不介紹具體的使用教程,讓我們一起來看看這個工具包里面都有些什么。
首先是Environment Toolkit,能夠說明現實空間中物體的位置,識別遮掩物背后被藏起來的識別點,還有房間的角落。
使得虛擬內容能夠更符合現實世界規則,增強沉浸感。源代碼則會放在在GitHub上,供開發者下載。

空間中那些點是Magic Leap提出的環境映射概念——BlockMesh,這是Lumin SDK for Unity中MLSpatialMapper預制件的可用網絡類型。
網格在內部重建,物體都將會表現為互聯的三角形網格。但這些網格之間并沒有相互連接,是為了在轉換目標的時候能夠快速更新網格。同時帶來的好處是MLO的識別更加緊密、貼近邊界,你可以看到虛擬對象是結結實實的踩在地上的,這會帶來更好的沉浸感。
在揮手時,虛擬人也能夠同樣向我們揮手,MLO的姿勢API有以下這些。
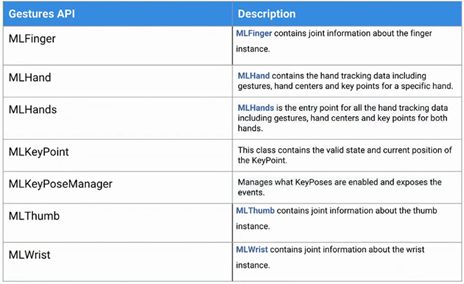
SDK API則有一下幾種。

開發包包括的工具以下。

這些就是大致的內容了,除此之外他們還透露控制器將會繼續保留,在手勢與控制器之間,控制器能夠帶來更好的觸感和反饋。在一項Magic Leap的專利里面我們可以找到控制器的樣子。
這次大會上給我們帶來了諸多MLO的信息,雖說戳穿了餅并沒有畫的那么大,但是更加的真實了,最終效果如何還是讓我們一起期待吧。
-
Ar
+關注
關注
24文章
5095瀏覽量
169470 -
Magic Leap
+關注
關注
0文章
88瀏覽量
10988 -
AR眼鏡
+關注
關注
4文章
528瀏覽量
23143
原文標題:Magic Leap公布透過MLO的演示視頻,以及其他更多細節
文章出處:【微信號:ARchan_TT,微信公眾號:AR醬】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
榮耀Magic7系列搭載驍龍8至尊版移動平臺
榮耀推出新品Magic V3與Magic Vs3折疊屏手機
榮耀Magic Vs3正式發布,采用天馬新一代HTD技術
Magic Leap與谷歌攜手打造增強現實新篇章
谷歌與Magic Leap達成戰略合作
Magic Leap與谷歌結盟,致力于拓寬AR應用領域
中軟國際亮相沙特LEAP全球頂級科技展,加速海外業務布局
榮耀MWC將發布Magic6系列及Magic V2 RSR保時捷設計折疊機

榮耀Magic6系列首發自研射頻增強芯片C1+
榮耀Magic6及Magic V2 RSR獲SGS Premium Performance金標認證






 工商網監
工商網監
評論