") 詳解跨鏡追蹤(ReID)應用分析與技術展望
詳解跨鏡追蹤(ReID)應用分析與技術展望
跨鏡追蹤(Person Re-Identification,簡稱 ReID)技術是現在計算機視覺研究的熱門方向,主要解決跨攝像頭跨場景下行人的識別與檢索。該技術能夠根據行人的穿著、體態(tài)、發(fā)型等信息認知行人,與人臉識別結合能夠適用于更多新的應用場景,將人工智能的認知水平提高到一個新階段。
本期大本營公開課,我們邀請到了云從科技資深算法研究員袁余鋒老師,他將通過以下四個方面來講解本次課題:
1、ReID的定義及技術難點;
2、常用數據集與評價指標簡介;
3、多粒度網絡(MGN)的結構設計與技術實現;
4、ReID在行人跟蹤中的應用分析與技術展望
以下是公開課文字版整理內容
ReID 是行人智能認知的其中一個研究方向,行人智能認知是人臉識別之后比較重要的一個研究方向,特別是計算機視覺行業(yè)里面,我們首先簡單介紹 ReID 里比較熱門的幾項內容:
1、行人檢測。任務是在給定圖片中檢測出行人位置的矩形框,這個跟之前的人臉檢測、汽車檢測比較類似,是較為基礎的技術,也是很多行人技術的一個前置技術。
2、行人分割以及背景替換。行人分割比行人檢測更精準,預估每個行人在圖片里的像素概率,把這個像素分割出來是人或是背景,這時用到很多 P 圖的場景,比如背景替換。舉一個例子,一些網紅在做直播時,可以把直播的背景替換成外景,讓體驗得到提升。
3、骨架關鍵點檢測及姿態(tài)識別。一般識別出人體的幾個關鍵點,比如頭部、肩部、手掌、腳掌,用到行人姿態(tài)識別的任務中,這些技術可以應用在互動娛樂的場景中,類似于 Kinnect 人機互動方面,關鍵點檢測技術是非常有價值的。

4、行人跟蹤“ MOT ”的技術。主要是研究人在單個攝像頭里行進的軌跡,每個人后面拖了一根線,這根線表示這個人在攝像頭里行進的軌跡,和 ReID 技術結合在一起可以形成跨鏡頭的細粒度的軌跡跟蹤。
5、動作識別。動作識別是基于視頻的內容理解做的,技術更加復雜一點,但是它與人類的認知更加接近,應用場景會更多,這個技術目前并不成熟。動作識別可以有非常多的應用,比如闖紅燈,還有公共場合突發(fā)事件的智能認知,像偷竊、聚眾斗毆,攝像頭識別出這樣的行為之后可以采取智能措施,比如自動報警,這有非常大的社會價值。

6、行人屬性結構化。把行人的屬性提煉出來,比如他衣服的顏色、褲子的類型、背包的顏色。
7、跨境追蹤及行人再識別 ReID 技術。

一、ReID 定義及技術難點
▌(一)ReID 定義
我們把 ReID 叫“跨鏡追蹤技術”,它是現在計算機視覺研究的熱門方向,主要解決跨攝像頭跨場景下行人的識別與檢索。該技術可以作為人臉識別技術的重要補充,可以對無法獲取清晰拍攝人臉的行人進行跨攝像頭連續(xù)跟蹤,增強數據的時空連續(xù)性。

給大家舉個例子,右圖由四張圖片構成,黃色這個人是之前新聞報道中的偷小孩事件的人,這個人會出現在多個攝像頭里,現在警察刑偵時會人工去檢索視頻里這個人出現的視頻段。這就是 ReID 可以應用的場景,ReID 技術可以根據行人的穿著、體貌,在各個攝像頭中去檢索,把這個人在各個不同攝像頭出現的視頻段關聯(lián)起來,然后形成軌跡,這個軌跡對警察刑偵破案有一定幫助。這是一個應用場景。

▌(二)ReID 技術難點
右邊是 ReID 的技術特點:首先,ReID 是屬于行人識別,是繼人臉識別后的一個重要研究方向。另外,研究的對象是人的整體特征,包括衣著、體形、發(fā)行、姿態(tài)等等。它的特點是跨攝像頭,跟人臉識別做補充。
二、常用數據集與評價指標簡介
很多人都說過深度學習其實也不難,為什么?只要有很多數據,基本深度學習的數據都能解決,這是一個類似于通用的解法。那我們就要反問,ReID 是一個深度認知問題,是不是用這種邏輯去解決就應該能夠迎刃而解?準備了很多數據,ReID 是不是就可以解決?根據我個人的經驗回答一下:“在 ReID 中,也行!但僅僅是理論上的,實際操作上非常不行!”
為什么?第一,ReID 有很多技術難點。比如 ReID 在實際應用場景下的數據非常復雜,會受到各種因素的影響,這些因素是客觀存在的,ReID 必須要嘗試去解決。

第一組圖,無正臉照。最大的問題是這個人完全看不到正臉,特別是左圖是個背面照,右圖戴個帽子,沒有正面照。
第二組圖,姿態(tài)。綠色衣服男子,左邊這張圖在走路,右圖在騎車,而且右圖還戴了口罩。
第三組圖,配飾。左圖是正面照,但右圖背面照出現了非常大的背包,左圖只能看到兩個肩帶,根本不知道背包長什么樣子,但右圖的背包非常大,這張圖片有很多背包的信息。
第四組圖,遮擋。左圖這個人打了遮陽傘,把肩部以上的地方全部擋住了,這是很大的問題。
圖片上只列舉了四種情況,還有更多情況,比如:
1、相機拍攝角度差異大;
2、監(jiān)控圖片模糊不清;
3、室內室外環(huán)境變化;
4、行人更換服裝配飾,如之前穿了一件小外套,過一會兒把外套脫掉了;
5、季節(jié)性穿衣風格,冬季、夏季穿衣風格差別非常大,但從行人認知來講他很可能是同一個人;
6、白天晚上的光線差異等。
從剛才列舉的情況應該能夠理解 ReID 的技術難點,要解決實際問題是非常復雜的。
ReID 常用的數據情況如何?右圖列舉了 ReID 學術界最常用的三個公開數據集:

第一列,Market1501。用得比較多,拍攝地點在清華大學,圖片數量有 32000 張左右,行人數量是 1500 個,相當于每個人差不多有 20 張照片,它是用 6 個攝像頭拍的。
第二列,DukeMTMC-reID,拍攝地點是在 Duke 大學,有 36000 張照片,1800 個人,是 8 個攝像頭拍的。
第三列,CUHK03,香港中文大學,13000 張照片,1467 個 ID,10 個攝像頭拍的。
看了這幾個數據集之后,應該能有一個直觀的感受,就是在 ReID 研究里,現在圖片的數量集大概在幾萬張左右,而 ID 數量基本小于 2000,攝像頭大概在 10 個以下,而且這些照片大部分都來自于學校,所以他們的身份大部分是學生。
這可以跟現在人臉數據集比較一下,人臉數據集動輒都是百萬張或者千萬張照片,一個人臉的 ID 多的數據集可以上百萬,而且身份非常多樣。這個其實就是 ReID 面對前面那么復雜的問題,但是數據又那么少的一個比較現實的情況。

這里放三個數據集的照片在這里,上面是 Market1501 的數據集,比如紫色這個人有一些照片檢測得并不好,像第二張照片的人只占圖片的五分之三左右,并不是一個完整的人。還有些照片只檢測到了局部,這是現在數據集比較現實的情況。
總結一下 ReID 數據采集的特點:
1、必須跨攝像頭采集,給數據采集的研發(fā)團隊和公司提出了比較高的要求;
2、公開數據集的數據規(guī)模非常小;
3、影響因素復雜多樣;
4、數據一般都是視頻的連續(xù)截圖;
5、同一個人最好有多張全身照片;
6、互聯(lián)網提供的照片基本無法用在 ReID;
7、監(jiān)控大規(guī)模搜集涉及到數據,涉及到用戶的隱私問題。

這些都是 ReID 數據采集的特點,可以歸結為一句話:“數據獲取難度大,會對算法提出比較大的挑戰(zhàn)。”問題很復雜,數據很難獲取,那怎么辦?現在業(yè)內盡量在算法層面做更多的工作,提高 ReID 的效果。
這里講一下評價指標,在 ReID 用得比較多的評價指標有兩個:
第一個是 Rank1
第二個是 mAP
ReID 終歸還是排序問題,Rank 是排序命中率核心指標。Rank1 是首位命中率,就是排在第一位的圖有沒有命中他本人,Rank5 是 1-5 張圖有沒有至少一張命中他本人。更能全面評價ReID 技術的指標是 mAP 平均精度均值。

這里我放了三個圖片的檢索結果,是 MGN 多粒度網絡產生的結果,第一組圖 10 張,從左到右是第 1 張到第 10 張,全是他本人圖片。第二組圖在第 9 張圖片模型判斷錯了,不是同一個人。第三組圖,第 1 張到第 6 張圖是對的,后面 4 張圖檢索錯了,不是我們模型檢索錯了,是這個人在底庫中總共就 6 張圖,把前 6 張檢索出來了,其實第三個人是百分之百檢索對的。
詳細介紹評價指標 mAP。因為 Rank1 只要第一張命中就可以了,有一系列偶然因素在里面,模型訓練或者測試時有一些波動。但是 mAP 衡量 ReID 更加全面,為什么?因為它要求被檢索人在底庫中所有的圖片都排在最前面,這時候 mAP 的指標才會高。

給大家舉個例子,這里放了兩組圖,圖片 1 和圖片 2 是檢索圖,第一組圖在底庫中有 5 張圖,下面有 5 個數字,我們假設它的檢索位置,排在第 1 位、第 3 位、第 4 位、第 8 位,第 20 位,第二張圖第 1 位、第 3 位、第 5 位。
它的 mAP 是怎么算的?對于第一張圖平均精度有一個公式在下面,就是 0.63 這個位置。第一張是 1 除以 1,第二張是除以排序實際位置,2 除以 3,第三個位置是 3 除以 4,第四個是 4 除以 8,第五張圖是 5 除以 20,然后把它們的值求平均,再總除以總的圖片量,最后得出的 mAP 值大概是 0.63。
同樣的算法,算出圖片 2 的精度是 0.756。最后把所有圖片的 mAP 求一個平均值,最后得到的 mAP 大概是 69.45。從這個公式可以看到,這個檢索圖在底庫中所有的圖片都會去計算 mAP,所以最好的情況是這個人在底庫中所有的圖片都排在前面,沒有任何其他人的照片插到他前面來,就相當于同一個人所有的照片距離都是最近的,這種情況最好,這種要求是非常高的,所以 mAP 是比較能夠綜合體現這個模型真實水平的指標。
再來看一下 ReID 實現思路與常見方案。ReID 從完整的過程分三個步驟:
第一步,從攝像頭的監(jiān)控視頻獲得原始圖片;
第二步,基于這些原始圖片把行人的位置檢測出來;
第三步,基于檢測出來的行人圖片,用 ReID 技術計算圖片的距離,但是我們現在做研究是基于常用數據集,把前面圖像的采集以及行人檢測的兩個工作做過了,我們 ReID 的課題主要研究第三個階段。
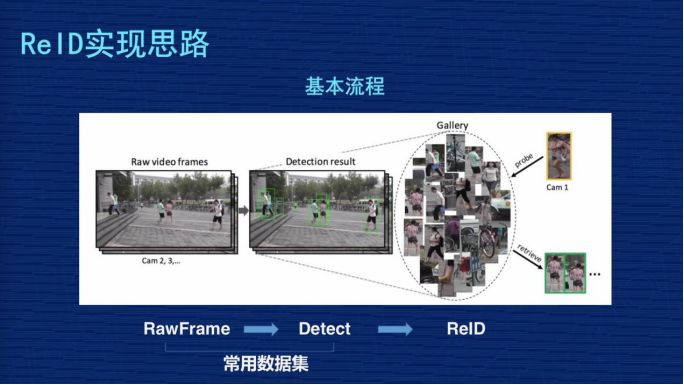
ReID 研究某種意義上來講,如果抽象得比較高,也是比較清晰的。比如大家看下圖,假設黃色衣服的人是檢索圖,后面密密麻麻很多小圖組成的相當于底庫,從檢索圖和底庫都抽出表征圖像的特征,特征一般都抽象為一個向量,比如 256 維或者 2048 維,這個 Match 會用距離去計算檢索圖跟庫里所有人的距離,然后對距離做排序,距離小的排在前面,距離大的排在后面,我們理解距離小的這些人是同一個人的相似度更高一點,這是一個比較抽象的思維。
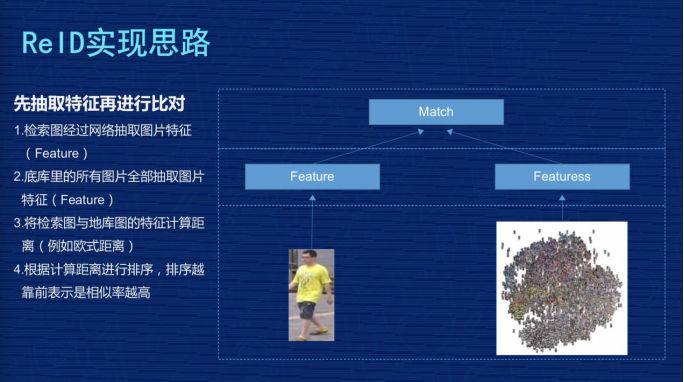
剛才講到核心是把圖像抽象成特征的過程,我再稍微詳細的畫一個流程,左圖的這些圖片會經過 CNN 網絡,CNN 是卷積神經網絡,不同的研究機構會設計自己不同的網絡結構,這些圖片抽象成特征 Feature,一般是向量表示。
然后分兩個階段,在訓練時,我們一般會設計一定的損失函數,在訓練階段盡量讓損失函數最小化,最小化過程反向把特征訓練得更加有意義,在評估階段時不會考慮損失函數,直接把特征抽象出來,用這個特征代表這張圖片,放到前面那張 PPT 里講的,去計算它們的距離。
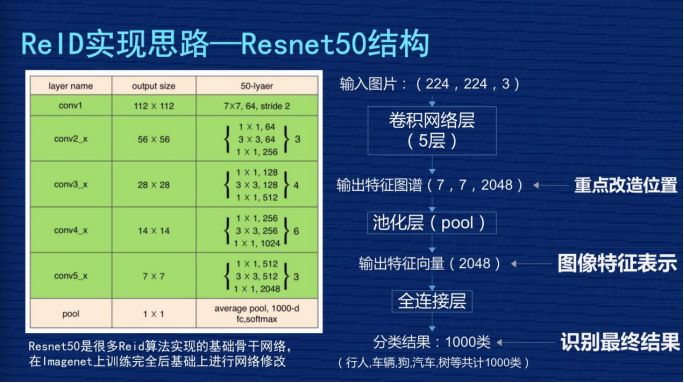
因為現在 ReID 的很多研究課題都是基于 Resnet50 結構去修改的。Resnet 一般會分為五層,圖像輸入是 (224,224,3),3 是 3 個通道,每層輸出的特征圖譜長寬都會比上一層縮小一半,比如從 224 到 112,112 到 56,56 到 28,最后第五層輸出的特征圖譜是 (7,7,2048)。
最后進行池化,變成 2048 向量,這個池化比較形象的解釋,就是每個特征圖譜里取一個最大值或者平均值。最后基于這個特征做分類,識別它是行人、車輛、汽車。我們網絡改造主要是在特征位置(7,7,2048)這個地方,像我們的網絡是 384×128,所以我們輸出的特征圖譜應該是 (12,4,2048)的過程。
下面,我講一下 ReID 里面常用的算法實現:
▌第一種,表征學習。
給大家介紹一下技術方案,圖片上有兩行,上面一行、下面一行,這兩行網絡結構基本是一樣的,但是兩行中間這個地方會把兩行的輸出特征進行比較,因為這個網絡是用了 4096 的向量,兩個特征有一個對比 Loss,這個網絡用了兩種 Loss,第一個 Loss 是 4096 做分類問題,然后兩個 4096 之間會有一個對比 Loss。
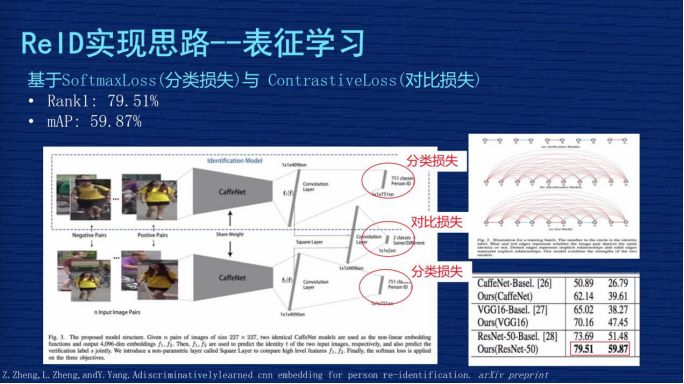
這個分類的問題是怎么定義的?在我們數據集像 mark1501 上有 751 個人的照片組成,這個分類相當于一張圖片輸入這個網絡之后,判斷這個人是其中某一個人的概率,要把這個圖片分類成 751 個 ID 中其中一個的概率,這個地方的 Loss 一般都用 SoftmaxLoss。機器視覺的同學應該非常熟悉這個,這是非常基本的一個 Loss,對非機器視覺的同學,這個可能要你們自己去理解,它可以作為分類的實現。
這個方案是通過設計分類損失與對比損失,來實現對網絡的監(jiān)督學習。它測試時取的是 4096 這個向量來表征圖片本人。這個文章應該是發(fā)在 2016 年,作者當時報告的效果在當時的時間點是有一定競爭力的,它的 Rank1 到了 79.51%,mAP 是 59.87%
▌第二種,度量學習方案。
基于TripletLoss 三元損失的 ReID 方案。TripletLoss 是計算機視覺里另外一個常用的 Loss。

它的設計思路是左圖下面有三個點,目的是從數據里面選擇三個圖片,這三個圖片由兩個人構成,其中兩張圖片是同一個人,另外一張圖片不是同一個人,當這個網絡在沒有訓練的時候,我們假設這同一個人的兩張照片距離要大于這個人跟不是同一個人兩張圖片的距離。
它強制模型訓練,使得同一個人兩張圖片的距離小于第三張圖片,就是剛才那張圖片上箭頭表示的過程。它真正的目的是讓同類的距離更近,不同類的距離更遠。這是TripletLoss的定義,大家可以去網上搜一下更詳細的解釋。
在 ReID 方案里面我給大家介紹一個 Batchhard的策略,因為 TripletLoss 在設計時怎么選這三張圖是有很多文章在實現不同算法,我們的文章里用的是 Batchhard算法,就是我們從數據集隨機抽取 P 個人,每個人 K 張圖片形成一個 Batch,每個人的 K 張圖片之間形成一個 K×(K-1)個 ap 對,再在剩下其他人里取一個與該 ap 距離最近的 negtive,組成 apn 組,然后我們這個模型使得 apn 組成的 Loss 盡量小。
這個 Loss 怎么定義?右上角有一個公式,就是 ap 距離減 an距離,m 是一個gap,這個值盡量小,使得同類之間盡量靠在一起,異類盡量拉開。右圖是 TripletLoss 的實驗方案,當時這個作者報告了一個成果,Rank1 到了 84.92%,mAP 到了 69%,這個成果在他發(fā)文章的那個階段是很有競爭力的結果。
▌第三種,局部特征學習。
1、基于局部區(qū)域調整的 ReID 解決方案。多粒度網絡也是解決局部特征和全局特征的方案。這是作者發(fā)的一篇文章,他解釋了三種方案。
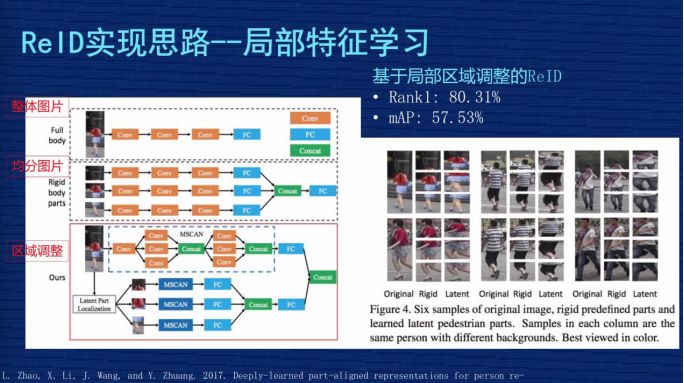
左圖第一種方案是把整張圖輸進網絡,取整張圖的特征;
第二種方案是把圖從上到下均分為三等,三分之一均分,每個部分輸入到網絡,去提出一個特征,把這三個特征又串連起來;
第三種方案是文章的核心,因為他覺得第二種均分可能出現問題,就是有些圖片檢測時,因為檢測技術不到位,檢測的可能不是完整人,可能是人的一部分,或者是人在圖里面只占一部分,這種情況如果三分之一均分出來的東西互相比較時就會有問題。
所以他設計一個模型,使得這個模型動態(tài)調整不同區(qū)域在圖片中的占比,把調整的信息跟原來三分的信息結合在一起進行預估。作者當時報告的成果是 Rank1為80% 左右,mAP為57%,用現在的眼光來講,這個成果不是那么顯著,但他把圖片切分成細粒度的思路給后面的研究者提供了啟發(fā),我們的成果也受助于他們的經驗。
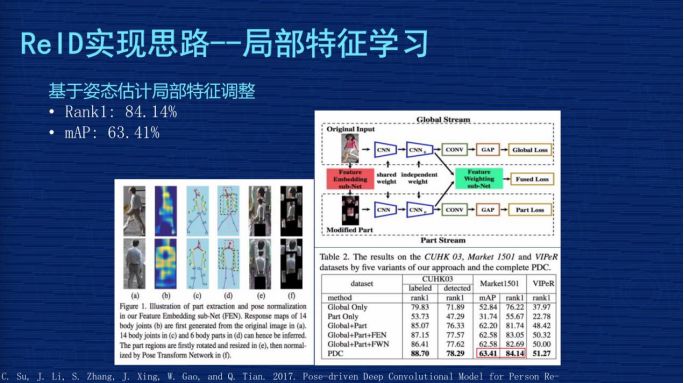
2、基于姿態(tài)估計局部特征調整。局部切割是基于圖片的,但對里面的語義不了解,是基于姿態(tài)估計局部位置的調整怎么做?先通過人體關鍵點的模型,把這個圖片里面人的關節(jié)位置取出來,然后按照人類對人體結構的理解,把頭跟頭比較,手跟手比較,按照人類的語義分割做一些調整,這相對于剛才的硬分割更加容易理解。基于這個調整再去做局部特征的優(yōu)化,這個文章是發(fā)表在 2017 年,當時作者報告的成果 Rank1為84.14%,mAP為63.41%。
3、PCB。發(fā)表在 2018 年 1 月份左右的文章,我們簡稱為 PCB,它的指標效果在現在來看還是可以的,我們多粒度網絡有一部分也是受它的啟發(fā)。下圖左邊這個特征圖較為復雜,可以看一下右邊這張圖,右圖上部分藍色衣服女孩這張圖片輸入網絡后有一個特征圖譜,大概個矩形體組成在這個地方,這是特征圖譜。這個圖譜位置的尺寸應該是 24×8×2048,就是前面講的那個特征圖譜的位置。

它的優(yōu)化主要是在這個位置,它干了個什么事?它沿著縱向將24 平均分成 6 份,縱向就是 4,而橫向是 8,單個特征圖譜變?yōu)?×8×2048,但它從上到下有 6 個局部特征圖譜。6個特征圖譜變?yōu)?個向量后做分類,它是同時針對每個局部獨立做一個分類,這是這篇文章的精髓。這個方式看起來非常簡單,但這個方法跑起來非常有效。作者報告的成果在 2018 年 1 月份時 Rank1 達到了 93.8%,mAP 達到了 81.6%,這在當時是非常好的指標了。
三、多粒度網絡(MGN)的結構設計與技術實現
剛才講了 ReID 研究方面的 5 個方案。接下來要講的是多粒度網絡的結構設計與實現。有人問 MGN 的名字叫什么,英文名字比較長,中文名字是對英文的一個翻譯,就是“學習多粒度顯著特征用于跨境追蹤技術(行人在識別)”,這個文章是發(fā)表于 4 月初。

▌(一)多粒度網絡(MGN)設計思路。
設計思想是這樣子的,一開始是全局特征,把整張圖片輸入,我們提取它的特征,用這種特征比較 Loss 或比較圖片距離。但這時我們發(fā)現有一些不顯著的細節(jié),還有出現頻率比較低的特征會被忽略。比如衣服上有個 LOGO,但不是所有衣服上有 LOGO,只有部分人衣服上有 LOGO。全局特征會做特征均勻化,LOGO 的細節(jié)被忽略掉了。

我們基于局部特征也去嘗試過,用關鍵點、人體姿態(tài)等。但這種有一些先驗知識在里面,比如遮擋、姿態(tài)大范圍的變化對這種方案有一些影響,效果并不是那么強。
后來我們想到全局特征跟多粒度局部特征結合在一起搞,思路比較簡單,全局特征負責整體的宏觀上大家共有的特征的提取,然后我們把圖像切分成不同塊,每一塊不同粒度,它去負責不同層次或者不同級別特征的提取。
相信把全局和局部的特征結合在一起,能夠有豐富的信息和細節(jié)去表征輸入圖片的完整情況。在觀察中發(fā)現,確實是隨著分割粒度的增加,模型能夠學到更詳細的細節(jié)信息,最終產生 MGN 的網絡結構。
下面演示一下多粒度特征,演示兩張圖,左邊第一列有 3 張圖,中間這列把這3張圖用二分之一上下均分,你可以看到同一個人有上半身、下半身,第三列是把人從上到下分成三塊——頭部、腹胸、腿部,它有 3 個粒度,每個粒度做獨立的引導,使得模型盡量對每個粒度學習更多信息。

右圖表示的是注意力的呈現效果,這不是基于我們模型產生的,是基于之前的算法看到的。左邊是整張圖在輸入時網絡在關注什么,整個人看著比較均勻,范圍比較廣一點。第三欄從上到下相當于把它切成 3 塊,每一塊看的時候它的關注點會更加集中一點,亮度分布不會像左邊那么均勻,更關注局部的亮點,我們可以理解為網絡在關注不同粒度的信息。
▌(二)多粒度網絡(MGN)——網絡結構
這是 MGN 的網絡架構完整的圖,這個網絡圖比較復雜,第一個,網絡從結構上比較直觀,從效果來講是比較有效的,如果想復現我們的方案還是比較容易的。如果你是做深度學習其他方向的,我們這個方案也有一定的普適性,特別是關注細粒度特征時,因為我們不是只針對 ReID 做的。我們設計的結構是有一定普適性,我把它理解為“易遷移”,大家可以作為參考。

首先,輸入圖的尺寸是 384×128,我們用的是 Resnet50,如果在不做任何改變的情況下,它的特征圖譜輸出尺寸,從右下角表格可以看到,global 這個地方就相當于對 Resnet 50不做任何的改變,特征圖譜輸出是 12×4。
下面有一個 part-2 跟 part-3,這是在 Res4_1 的位置,本來是有一個stride等于 2 的下采樣的操作,我們把 2 改成1,沒有下采樣,這個地方的尺寸就不會縮小 2,所以 part-2 跟 part-3 比 global 大一倍的尺寸,它的尺寸是 24×8。為什么要這么操作?因為我們會強制分配 part-2 跟 part-3 去學習細粒度特征,如果把特征尺寸做得大一點,相當于信息更多一點,更利于網絡學到更細節(jié)的特征。
網絡結構從左到右,先是兩個人的圖片輸入,這邊有 3 個模塊。3 個模塊的意思是表示 3 個分支共享網絡,前三層這三個分支是共享的,到第四層時分成三個支路,第一個支路是 global 的分支,第二個是 part-2 的分支,第三個是 part-3 的分支。在 global 的地方有兩塊,右邊這個方塊比左邊的方塊大概縮小了一倍,因為做了個下采樣,下面兩個分支沒有做下采樣,所以第四層和第五層特征圖是一樣大小的。
接下來我們對 part-2 跟 part-3 做一個從上到下的縱向分割,part-2 在第五層特征圖譜分成兩塊,part-3 對特征圖譜從上到下分成三塊。在分割完成后,我們做一個 pooling,相當于求一個最值,我們用的是 Max-pooling,得到一個 2048 的向量,這個是長條形的、橫向的、黃色區(qū)域這個地方。
但是 part-2 跟 part-3 的操作跟 global 是不一樣的,part-2 有兩個 pooling,第一個是藍色的,兩個 part 合在一起做一個 global-pooling,我們強制 part-2 去學習細節(jié)的聯(lián)合信息,part-2 有兩個細的長條形,就是我們剛才引導它去學細節(jié)型的信息。淡藍色這個地方變成小方體一樣,是做降維,從 2048 維做成 256 維,這個主要方便特征計算,因為可以降維,更快更有效。我們在測試的時候會在淡藍色的地方,小方塊從上到下應該是 8 個,我們把這 8 個 256 維的特征串連一個 2048 的特征,用這個特征替代前面輸入的圖片。
▌(三)多粒度網絡(MGN)——Loss設計
Loss 說簡單也簡單,說復雜也復雜也復雜,為什么?簡單是因為整個模型里只用了兩種Loss,是機器學習里最常見的,一個是 SoftmaxLoss 一個是 TripletLoss。復雜是因為分支比較多,包括 global 的,包括剛才 local 的分支,而且在各個分支的 Loss 設計上不是完全均等的。我們當時做了些實驗和思考去想 Loss 的設計。現在這個方案,第一,從實踐上證明是比較好的,第二,從理解上也是容易理解的。
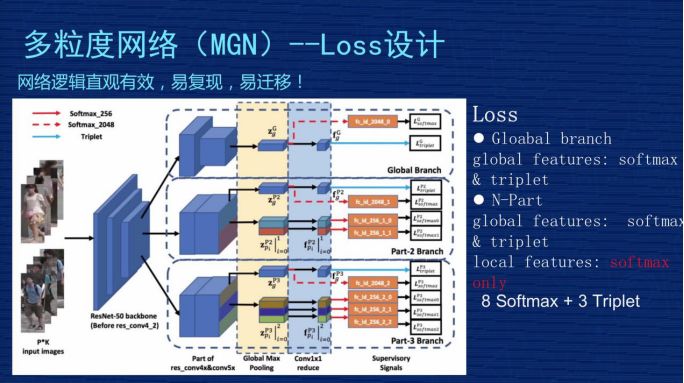
首先,看一下 global 分支。上面第一塊的 Loss 設計。這個地方對 2048 維做了SoftmaxLoss,對 256 維做了一個 TripletLoss,這是對 global 信息通用的方法。下面兩個部分 global 的處理方式也是一樣的,都是對 2048 做一個 SoftmaxLoss,對 256 維做一個 TripletLoss。中間 part-2 地方有一個全局信息,有 global 特征,做 SoftmaxLoss+TripletLoss。
但是,下面兩個 Local 特征看不到 TripletLoss,只用了 SoftmaxLoss,這個在文章里也有討論,我們當時做了實驗,如果對細節(jié)當和分支做 TripletLoss,效果會變差。為什么效果會變差?
一張圖片分成從上到下兩部分的時候,最完美的情況當然是上面部分是上半身,下面部分是下半身,但是在實際的圖片中,有可能整個人都在上半部分,下半部分全是背景,這種情況用上、下部分來區(qū)分,假設下半部分都是背景,把這個背景放到 TripletLoss 三元損失里去算這個 Loss,就會使得這個模型學到莫名其妙的特征。
比如背景圖是個樹,另外一張圖是某個人的下半身,比如一個女生的下半身是一個裙子,你讓裙子跟另外圖的樹去算距離,無論是同類還是不同類,算出來的距離是沒有任何物理意義或實際意義的。從模型的角度來講,它屬于污點數據,這個污點數據會引導整個模型崩潰掉或者學到錯誤信息,使得預測的時候引起錯誤。所以以后有同學想復現我們方法的時候要注意一下, Part-2、part-3 的 Local 特征千萬不要加 TripletLoss。
▌(四)多粒度網絡(MGN)——實驗參數
圖片展示的是一些實驗參數,因為很多同學對復現我們的方案有一定興趣,也好奇到底這個東西為什么可以做那么好。其實我們在文章里把很多參數說得非常透,大家可以按照我們的參數去嘗試一下。
我們當時用的框架是 Pytorch。TripletLoss 復現是怎么選擇的?我們這個 batch是選 P=16,K=4,16×4,64 張圖作為 batch,是隨機選擇16 個人,每個人隨機選擇 4 張圖。

然后用 SGD 去訓練,我們的參數用的是 0.9。另外,我們做了weightdecay,參數是萬分之五。像 Market1501 是訓練 80epochs,是基于 Resnet50 微調了。我們之前實驗過,如果不基于 Resnet50,用隨機初始化去訓練的話效果很差,很感謝 Resnet50 的作者,對這個模型訓練得 非常有意義。
初始學習率是百分之一,到 40 個 epoch 降為千分之一,60 個 epoch 時降為萬分之一。我們評估時會對評估圖片做左右翻轉后提取兩個特征,這兩個特征求一個平均值,代表這張圖片的特征。剛才有人問到我們用了什么硬件,我們用了 2 張的 TITAN 的 GPU。
在 Market1501 上訓練 80 epoch的時間大概差不多是 2 小時左右,這個時間是可以接受的,一天訓練得快一點可以做出 5-10 組實驗。
▌(五)多粒度網絡(MGN)——實驗結果
我們發(fā)表成果時,這個結果是屬于三個數據集上最好的。
1、Market1501。我們不做 ReRank 的時候,原始的 Rank1 是 95.7%,mAP 是 86.9%,跟剛才講的業(yè)內比較好的 PCB 那個文章相比,我們的 Rank1 提高差不多 1.9 個點,mAP 整整提高 5.3 個點,得到非常大的提升。
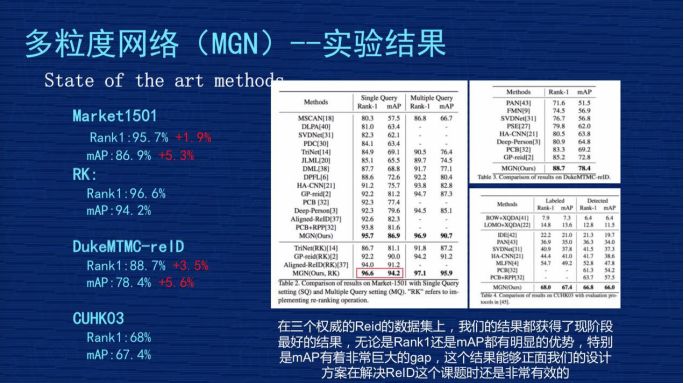
2、RK。Rank1 達到 96.6%,mAP 是 94.2%。RK 是 ReRank 重新排序的簡稱,ReID 有一篇文章是專門講 ReRank 技術的,不是從事 ReID 的同學對 ReRank 的技術可能有一定迷惑,大家就理解為這是某種技術,這種技術是用在測試結果重新排列的結果,它會用到測試集本身的信息。因為在現實意義中很有可能這個測試集是開放的,沒有辦法用到測試集信息,就沒有辦法做ReRank,前面那個原始的 Rank1 和 mAP 比較有用。
但是對一些已知道測試集數據分布情況下,可以用 ReRank 技術把這個指標有很大的提高,特別是 mAP,像我們方案里從 86.9% 提升到 94.2%,這其中差不多 7.3% 的提升,是非常顯著的。
3、DukeMTMC-reID和 CUHKO3這兩個結果在我們公布研究成果時算是最好的,我們是4月份公布的成果,現在是 6 月份了,最近 2 個月 CEPR 對關于 ReID 的文章出了差不多 30 幾篇,我們也在關注結果。現在除了我們以外最好的成果,原始 Rank1 在 93.5%-94% 之間,mAP 在83.5%-84% 之間,很少看到 mAP 超過 84% 或者 85% 的關于。
▌(六)多粒度網絡(MGN)——有趣的對比實驗
因為網絡結構很復雜,這么復雜的事情能說得清楚嗎?里面各個分支到底有沒有效?我們在文章里做了幾組比較有意思的實驗,這里跟大家對比一下。
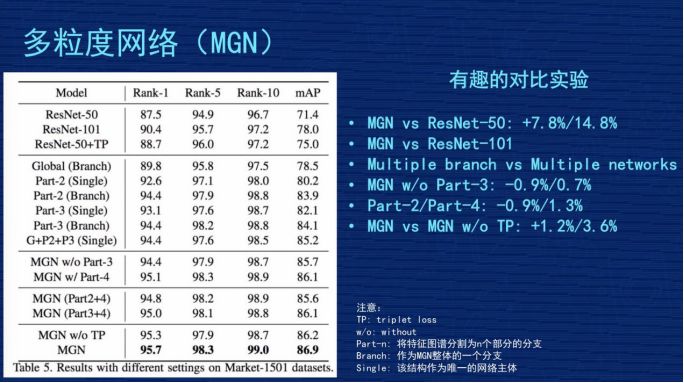
第一個對比,對比 MGN 跟 Resnet50,這倒數第二行,就是那個 MGN w/o TP,跟第一行對比,發(fā)現我們的多粒度網絡比 Resnet50 水平,Rank1 提高了 7.8%,mAP 提高了14.8%,整體效果是不錯的。
第二個對比,因為我們的網絡有三個分支,里面參數量肯定會增加,增加的幅度跟 Resnet101的水平差不多,是不是我們網絡成果來自于參數增加?我們做了一組實驗,第二行有一個 Resnet101,它的 rank1 是 90.4%,mAP 是 78%,這個比 Resnet50 確實好了很多,但是跟我們的工作成果有差距,說明我們的網絡也不是純粹堆參數堆出來的結果,應該是有網絡設計的合理性在。
第三個對比,表格第二個大塊,搞了三個分支,把這三個分支做成三個獨立的網絡,同時獨立訓練,然后把結果結合在一起,是不是效果跟我們差不多,或者比我們好?我們做了實驗,最后的結果是“G+P2+P3(single)”,Rank1 有 94.4%,mAP85.2%,效果也不錯,但跟我們三個網絡聯(lián)合的網絡結構比起來,還是我們的結構更合理。我們的解釋是不同分支在學習的時候,會互相去督促或者互相共享有價值的信息,使得大家即使在獨立運作時也會更好。
▌(七)多粒度網絡(MGN)——多粒度網絡效果示例
這是排序圖片的呈現效果,左圖是排序位置,4 個人的檢索結果,前 2 個人可以看到我們的模型是很強的,無論這個人是側身、背身還是模糊的,都能夠檢測出來。尤其是第 3 個人,這張圖是非常模糊的,整個人是比較黑的,但是我們這個模型根據他的綠色衣服、白色包的信息,還是能夠找出來,盡管在第 9 位有一個判斷失誤。第 4 個人用了一張背面的圖,背個包去檢索,可以發(fā)現結果里正臉照基本被搜出來了。

右邊是我們的網絡注意力模型,比較有意思的一個結果,左邊是原圖,右邊從左到右有三列,是 global、part2、part3 的特征組,可以看到 global 的時候分布是比較均勻的,說明它沒有特別看細節(jié)。
越到右邊的時候,發(fā)現亮點越小,越關注在局部點上,并不是完整的整個人的識別。第 4 個人我用紅圈圈出來了,這個人左胸有一個 LOGO,看 part3 右邊這張圖的時候,整個人只有在 LOGO 地方有一個亮點或者亮點最明顯,說明我們網絡在 part3 專門針對這個 LOGO 學到非常強的信息,檢索結果里肯定是有這個 LOGO 的人排列位置比較靠前。
四、應用場景與技術展望
▌(一)ReID 的應用場景
第一個,與人臉識別結合。
之前人臉識別技術比較成熟,但是人臉識別技術有一個明顯的要求,就是必須看到相對清晰的人臉照,如果是一個背面照,完全沒有人臉的情況下,人臉識別技術是失效的。
但 ReID 技術和人臉的技術可以做一個補充,當能看到人臉的時候用人臉的技術去識別,當看不到人臉的時候用 ReID 技術去識別,可以延長行人在攝像頭連續(xù)跟蹤的時空延續(xù)性。右邊位置2、位置3、位置4 的地方可以用 ReID 技術去持續(xù)跟蹤。跟人臉識別結合是大的 ReID 的應用方向,不是具象的應用場景。

第二個,智能安防。
它的應用場景是這樣子的,比如我已經知道某個嫌疑犯的照片,警察想知道嫌疑犯在監(jiān)控視頻里的照片,但監(jiān)控視頻是 24 小時不間斷在監(jiān)控,所以數據量非常大,監(jiān)控攝像頭非常多,比如有幾百個、幾十個攝像頭,但人來對攝像頭每秒每秒去看的話非常費時,這時可以用 ReID 技術。
ReID 根據嫌疑犯照片,去監(jiān)控視頻庫里去收集嫌疑犯出現的視頻段。這樣可以把嫌疑犯在各個攝像頭的軌跡串連起來,這個軌跡一旦串連起來之后,相信對警察的破案刑偵有非常大的幫助。這是在智能安防的具象應用場景。

第三個,智能尋人系統(tǒng)。
比如大型公共場所,像迪斯尼樂園,爸爸媽媽帶著小朋友去玩,小朋友在玩的過程中不小心與爸爸媽媽走散了,現在走散時是在廣播里播一下“某某小朋友,你爸爸媽媽在找你”,但小朋友也不是非常懂,父母非常著急。
這時可以用 ReID 技術,爸爸媽媽提供一張小朋友拍的照片,因為游樂園里肯定拍了小朋友拍的照片,比如今天穿得什么衣服、背得什么包,把這個照片輸入到 ReID 系統(tǒng)里,實時的在所有監(jiān)控攝像頭尋找這個小朋友的照片,ReID 有這個技術能力,它可以很快的找到跟爸爸媽媽提供的照片最相似的人,相信對立馬找到這個小朋友有非常大的幫助。
這種大型公共場所還有更多,比如超市、火車站、展覽館,人流密度比較大的公共場所。智能尋人系統(tǒng)也是比較具象的 ReID 應用場景。

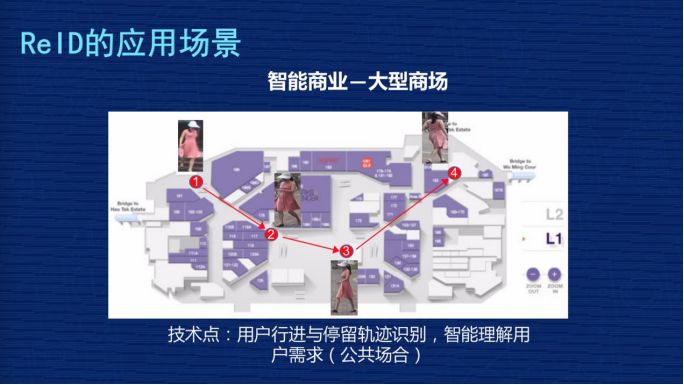
第四個,智能商業(yè)-大型商場。
想通過了解用戶在商場里的行為軌跡,通過行為軌跡了解用戶的興趣,以便優(yōu)化用戶體驗。ReID 可以根據行人外觀的照片,實時動態(tài)跟蹤用戶軌跡,把軌跡轉化成管理員能夠理解的信息,以幫助大家去優(yōu)化商業(yè)體驗。
這個過程中會涉及到用戶隱私之類的,但從 ReID 的角度來講,我們比較提倡數據源來自于哪個商場,那就應用到哪個商場。因為 ReID 的數據很復雜,數據的遷移能力是比較弱的,這個上場的數據不見得在另外一個商場里能用,所以我們提倡 ReID 的數據應用在本商場。
第五個,智能商業(yè)-無人超市。
無人超市也有類似的需求,無人超市不只是體驗優(yōu)化,它還要了解用戶的購物行為,因為如果只基于人臉來做,很多時候是拍不到客戶的正面,ReID 這個技術在無人超市的場景下有非常大的應用幫助。

第六個,相冊聚類。
現在拍照時,可以把相同人的照片聚在一起,方便大家去管理,這也是一個具象的應用場景。

第七個,家庭機器人。
家庭機器人通過衣著或者姿態(tài)去認知主人,做一些智能跟隨等動作,因為家庭機器人很難實時看到主人的人臉,用人臉識別的技術去做跟蹤的話,我覺得還是有一些局限性的。但是整個人體的照片比較容易獲得,比如家里有一個小的機器人,它能夠看到主人的照片,無論是上半年還是下半年,ReID 可以基于背影或者局部服飾去識別。

▌(二)ReID 的技術展望
第一個,ReID 的數據比較難獲取,如果用應用無監(jiān)督學習去提高 ReID 效果,可以降低數據采集的依賴性,這也是一個研究方向。右邊可以看到,GAN生成數據來幫助 ReID 數據增強,現在也是一個很大的分支,但這只是應用無監(jiān)督學習的一個方向。
第二個,基于視頻的 ReID。因為剛才幾個數據集是基于對視頻切好的單個圖片而已,但實際應用場景中還存在著視頻的連續(xù)幀,連續(xù)幀可以獲取更多信息,跟實際應用更貼近,很多研究者也在進行基于視頻 ReID 的技術。

第三個,跨模態(tài)的 ReID。剛才講到白天和黑夜的問題,黑夜時可以用紅外的攝像頭拍出來的跟白色采樣攝像頭做匹配。
第四個,跨場景的遷移學習。就是在一個場景比如 market1501 上學到的 ReID,怎樣在 Duke數據集上提高效果。
第五個,應用系統(tǒng)設計。相當于設計一套系統(tǒng)讓 ReID 這個技術實際應用到行人檢索等技術上去。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238253 -
REID
+關注
關注
1文章
18瀏覽量
10856
原文標題:云從科技資深算法研究員:詳解跨鏡追蹤(ReID)技術實現及難點 | 公開課筆記
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
電流鏡設計步驟詳解【全過程】
使用LabVIEW進行物體追蹤圖像處理分析
人工智能即將從“刷臉”跨到“識人”的新紀元
澎思科技ReID技術取得新突破
ReID行人重識別再破行業(yè)新高,多目標定位與追蹤精準呈現
Vulkan光線追蹤技術,實現跨平臺和跨系統(tǒng)
基于其自主知識產權的新一代商用級跨鏡追蹤Re-ID技術





 工商網監(jiān)
工商網監(jiān)
評論