 OpenAI:用可擴展的多任務系統,在多語言任務上取得了良好的成績
OpenAI:用可擴展的多任務系統,在多語言任務上取得了良好的成績
編者按:近日,OpenAI在博客上宣布,他們用可擴展的多任務系統,在多語言任務上取得了良好的成績。研究人員結合了transformer和無監督預訓練這兩種現有方法。結果證明,監督學習方法和無監督預訓練結合得非常好。以下是論智對原博文的編譯。
我們的系統工作分為兩個階段:首先,我們在大量數據上訓練一個transformer模型,利用語言建模作為訓練信號,然后在稍小的監督數據集上對模型進行微調,以幫助解決特殊任務。
在此之前我們曾發布了一篇有關“情感神經元”的研究,其中我們注意到無監督學習技術能產生非常明顯的特定。這里,我們想將這一技術進一步拓展:是否能創建一個模型,將其在大量數據上進行無監督訓練,之后再在多種不同任務上進行微調?結果證明,這一方法非常有效。模型只需要微小調整就能適應多種任務。
這項工作建立在論文Semi-supervised Sequence Learning所提出的方法上,它展示了如何用LSTM的無監督預訓練以及監督式的微調提高文本分類的性能。它還擴展了ULMFiT,該研究展示了單一無數據集的LSTM語言模型可以在多種文本分類數據集上微調后達到最優性能。
而我們的研究展示了一個基于Transformer的模型可以通過這種方法做到除了文本分類以外的事,例如常識推理、語義相似度、閱讀理解。它也有點像ELMo,同樣也是加入預訓練,再用特定任務框架得到最優結果。
為了達到我們的結果只需要微調,并且所有數據集只用了一個前向語言模型,沒有任何集成,并且大部分結果用的參數都是相通的。
令人激動的是,我們的方法在COPA、RACE和ROCStories三個數據集上都表現的很好,這三種數據集是用來測試常識推理和閱讀理解的。我們的模型在這些數據集上表現出了頂尖的結果,與其他方法的對比十分明顯。通常人們認為這些數據集需要多語句推理和豐富的知識,這也表明我們的模型只能靠無監督學習提升水準。這也意味著未來也許能通過無監督技術讓模型理解復雜語言。
為什么用無監督學習?
監督學習最近在機器學習的很多方面都取得了成功。然而,成功的背后需要大型、經過清洗的數據集。無監督學習不會有這些問題,也是它受歡迎的原因。由于無監督學習無需人類對數據進行標注,所以在目前計算量增加并且有可用元數據的趨勢下,它仍然適應得很好。無監督學習是很受歡迎的研究領域,但是付諸實踐的卻很少。
最近我們嘗試用無監督學習增強系統,進一步研究語言能力。無監督技術訓練能通過含有巨大信息量的數據庫訓練單詞的表示,與監督學習結合后,模型的性能會進一步提高。最近,這些NLP領域的無監督技術(例如GLoVe和word2vec)利用了簡單模型(詞向量)和訓練信號。Skip-Thought向量是一種是對這種提升的早期展示。但是目前在用的技術讓性能得到了進一步提升。這些都包括了使用預訓練句子的模型表示、語境化的詞向量、用定制架構連接無監督預訓練和監督微調的方法。

在大量文本語料上對模型進行預訓練顯著提高了它在自然語言處理上的表現
我們還注意到,我們可以用基礎的語言模型直接執行任務,不用訓練它們。例如,隨著基礎語言模型的升級,選擇題模型的表現也有了提升。雖然這種方法和監督方法相比結果還是有差距,但是無監督學習方法能在多種任務上執行任務已經很讓人興奮了。
我們還能用模型中現有的語言功能執行情感分析。斯坦福的Sentiment Treebank數據集中包含了許多積極和消極的電影評論,如果在一句話的結尾添加“very”這個詞,我們可以用語言模型猜測評論的屬性。這種方法完全沒用對模型進行適應調整,最終達到了約80%的準確度。
我們的方法也是驗證transformer架構的魯棒性和有用性的標準,這說明想在多種任務上達到頂尖的結果,同時不需要定制化或調參是非常靈活的。
目前存在的缺點
這一項目同時還存在著一些不足之處:
計算需求:此前NLP任務中的許多方法都是從零開始在單個GPU上訓練,模型比較小。我們的方法在預訓練時需要一個月左右的時間,并且要用8個GPU。幸運的是,預訓練只要做一次。不過跟之前的其他工作相比,這算是比較大的計算量和內存了。我們用了一個37層的Transformer架構,訓練了最多有512個token的序列,大多數都是在4個或8個GPU系統上進行的。模型可以快速地針對新問題進行微調,這也減少了額外所需要的資源。
在學習時通過文本對世界的理解有偏差和偏見:網絡上所能看見的書或文字也許不能涵蓋世界所有的信息,也許不準確。最近的研究表明,用文本和通過數據分布建立的模型學習特定的信息很困難。
生成時很脆弱:雖然我們的方法在很多任務中都提高了性能,目前的深度學習NLP模型仍然表現出令人驚訝的反常行為,尤其是系統地進行對抗測試時更加明顯。但是我們的方法在這些測試面前很脆弱,盡管有一些進步。對比之前完全用神經網絡的方法,我們的方法在詞匯魯棒性上更勝一籌。在Glockner等人的數據集上,我們的模型達到了83.75%的方法,和KIM接近。
未來方向
擴展我們的方法:我們看到在語言模型和其相關的模型上已經有了很大提升。目前我們正在用一個8個GPU的機器和含有上千本書的訓練集進行實驗,說明還有很大的擴展空間。
改進微調方法:我們的方法目前很簡潔。也許未來我們會用更加復雜的調整和遷移技術進行改進。
深入了解為什么生成預訓練很有幫助:雖然我們對研究成果做出了解釋,但是只有對比其他實驗和研究才能有更清晰的認知。例如,技術提升后到底有多少好處?
具體案例


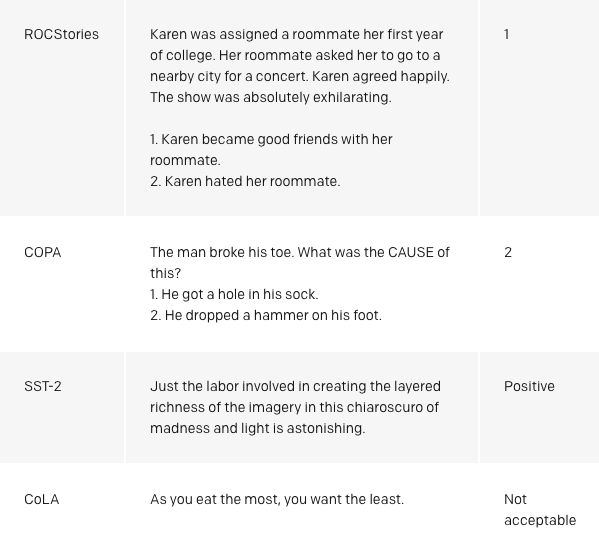
-
機器學習
+關注
關注
66文章
8424瀏覽量
132766 -
數據集
+關注
關注
4文章
1208瀏覽量
24737
原文標題:OpenAI:無監督訓練加微小調整,只用一個模型即可解決多種NLP任務
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
多語言開發的流程詳解
setjmp構建簡單協作式多任務系統
實時多任務操作系統(RTOS)
多任務編程多任務處理是指什么
多語言綜合信息服務系統研究與設計
SoC多語言協同驗證平臺技術研究
OpenAI介紹可擴展的,與任務無關的的自然語言處理(NLP)系統

多語言翻譯新范式的工作:機器翻譯界的BERT
Multilingual多語言預訓練語言模型的套路
多語言任務在內的多種NLP任務實現

基于LLaMA的多語言數學推理大模型





 工商網監
工商網監
評論