 建立一個源于StackExchange的新數據集
建立一個源于StackExchange的新數據集
ACL、EMNLP、NAACL和COLING是NLP領域的四大國際頂會,其中ACL(Annual Meeting of the Association for Computational Linguistics)一直以受關注度更廣、論文投遞數量多著稱。7月15日至20日,第56屆年度ACL會議將在澳大利亞墨爾本舉辦,辛苦碼論文的你,準備好了嗎?
作為頂會,評選“最佳論文”和“終身成就獎”幾乎已經是一項“標配”,ACL也不例外。往年會議通常會在正會上宣布獲獎論文/嘉賓,但今年主辦單位計算語言學協會卻一反常態,在會議前一個月就提前放出了“最佳論文”的評選結果——三篇“最佳長論文”和兩篇“最佳短論文”。
Best Long Papers

Best Short Papers

雖然Finding syntax in human encephalography with beam search(用集束搜索在人體腦電圖中尋找語法)這篇論文從標題上看起來似乎更具吸引力,但考慮到這5篇論文中只公開了2、3兩篇長論文,因此論智在這里只能簡要介紹這兩篇的內容。如果讀者有條件看到會場海報,歡迎隨時分享。
論文2:Learning to Ask Good Questions

詢問是溝通的基礎,如果一臺機器連提問都不會,那它也絕對做不到高效地和人類溝通。在日常交流中,提問的主要目標是進一步澄清問題,填補信息空白,如當用戶在論壇上向機器人詢問Ubuntu操作系統使用問題時,為了篩選原因,機器人會根據條件產生幾個提問選項:
(a) 您的系統是哪個版本的?
(b) 您的無線網卡有哪些功能?
(c) 您是在64位操作系統上運行的嗎?
在這種情況下,機器人不該問(b),因為這是個無效問題;它也不該選(c),因為這個問題的答案面太狹窄了,如果用戶的回復是“不是”“不知道”,這也成了個無效問題。所以這三個選項中唯一符合人類風格的只有(a)。
本文主要做了兩方面工作,一是構建了一個新型神經網絡模型,它能基于獲得完美信息的期望值為問題排序;二是建立了一個源于StackExchange的新數據集,它是模型的學習基礎。
新型神經網絡模型
這個神經模型的靈感來自完全信息期望值(EVPI),即擁有此隨機事件的完全信息時的最大期望值與未擁有此隨機事件完全信息時的最大期望值之差。當然這里不用算最大,通俗來講,本文關注的是如果我們對Ubuntu操作問題有一個已知信息X,那X的用處到底有多大?
因為現在沒有這個X,所以我們要先找出所有可能的X,并根據似然值加權計算。在提問場景中,對于模型的給定問題qi(前提是能回答),用戶可能有A個可能的回答;對于每個可能的回答aj∈A,模型有概率從中抽取信息,能為得出最終答案提供作用。因此qi的期望值是:

其中,
p是用戶發表的提問帖;
qi是候選問題集Q中的一個可能的問題;
aj是針對Q的候選回答集A里的一個答案;
P[aj|p, qi]計算了對于帖子p和提問qi,模型獲得回答aj的概率;
U(p+aj)是微觀經濟學中常見的效用函數,用來描述獲得答案aj后,它對帖子p的信息補充程度;
下圖展示了模型在測試期間的邏輯:

給定一個帖子p,模型先檢索10個類似p的帖子,并生成相應的問題集Q和答案集A。然后輸入p和提問qi,獲得神經網絡的輸出,也就是回答表征F(p, qi),計算P[aj|F(p, qi)]和P[aj|p, qi]的接近程度。之后,用U(p+aj)計算把回答改成aj后,p的信息補充提升效果。最后,再根據這個期望效果對問題集Q里的問題一一排序。
看到這里,這個模型要解決的問題就只剩下兩個了:
概率分布P[aj|p, qi];
效用函數U(p+aj)。
那么它們背后的原理是什么呢?考慮到篇幅有限,小編這里不再展開介紹了,如果好奇,請大家去讀原文——結構清晰美觀,強烈推薦。
新數據集
關于這個數據集,內容不多。它的原型是StackExchange上的評論數據,共77,097條內容。論文作者圍繞【帖子】【問題】【答案】三個內容創建了一個數據集,其中帖子都是未經編輯的原帖,問題是包含問題的評論,答案是作者對帖子的修改和他對其他留言的評論。
實驗結果
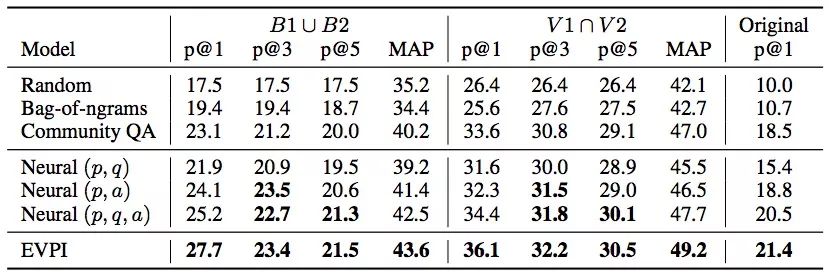
從上圖數據可以看出,論文提出的EVPI模型表現不錯,它在問題生成任務上非常有前景,能切實幫助機器人在論壇上寫出高質量回復。
論文地址:arxiv.org/pdf/1805.04655.pdf
論文3:Let’s do it “again”

這同樣是一篇有趣的論文,它在2010年Layth Muthana Khaleel那篇An Analysis of Presupposition Triggers in English Journalistic Texts的基礎上再次研究了語用學中的“預設”(Presupposition)問題。
什么是語用預設?
預設一詞來自英國著名哲學家Strawson的《邏輯理論導論》:“一個命題S預設P,而且僅當P是S有真值或價值的必要條件。”在語用學中,預設指的是參與對話者在言語交流時都已經知道的信息和假設,同時這些共知信息無需被說出來。它在日常自然對話中隨處可見,如:
(1) John is going to the restaurant again.
(2) John has been to the restaurant.
在這個例子中,因為存在一個“again”,所以只有當(2)為真時,(1)的表述才是合理的。表示因為John之前去過一次飯店,所以他能“再”去一次。語用預設和語義預設不同,其中最明顯的是它不會因在句子中添加否定而改變,如John is not going to the restaurant again,(2)同樣是這句話的預設。
我們把像“again”這樣表示預設存在的表達稱為預設觸發語,它可以是實際的副詞、動詞,也可以是一段明確的表述。而本文的研究內容則是一個可以檢測狀語預設觸發語的模型。
新數據集
為了訓練模型,論文作者也自制了數據集。他們從Penn Treebank(PTB)和English Gigaword第三版子集這兩個語料庫里提取數據,其中PTB里的22、23兩章和Gigaword里的700-760章是測試集,剩余數據里的90%是訓練集,最后的10%則被用來提升模型。

對于每個數據集,他們的關注目標是這5個副詞:too、again、also、still和yet。由于它們在英語中一般就充當預設觸發語,這就相當于整個學習問題被簡化成了副詞預設觸發語是否存在——一個二元分類問題。他們把包含這些副詞的句子標記為positive,不包含的則是negative。
學習模型
這是一個引入了注意力機制的模型,從某種程度上來說,它擴展了雙向LSTM模型,通過計算每個時間步的隱藏狀態之間的相關性,在這些相關性上應用注意力機制。
下圖是論文提出的加權池化(WP)神經網絡架構:

模型輸入序列u = {u1, u2,..., uT}在數據集原始序列基礎上經過one-hot編碼而來,時間步長為T;
輸入網絡后,序列中的每個單詞ut會嵌入預訓練的嵌入矩陣We∈R|V|×d,其中V表示數據集V中的單詞數,d則是嵌入空間大小;
嵌入后所得的單詞向量xt∈Rd可以簡單地用xt= utWe來表示,其中,因為xt可能還包含單詞的詞性標注,所以其實這個等式還應該加上經one-hot編碼的詞性標注pt:xt= utWe||pt(||:向量級聯運算符)。
我們獲得了雙向LSTM的輸入,之后用LSTM進行編碼;
將編碼饋送進注意力機制,計算出注意力權重后,對編碼狀態進行加權平均;
將輸出依次連接到全連接層,預測狀語預設觸發語。
(上述過程中的雙向LSTM和注意力機制運算非常常規,請看原文)
實驗結果

從結果上看他們的模型還是不錯的,但考慮到我們使用的是中文,語用預設更加復雜,英語語境下的這種二元分類方法可能并不適用,但這也為其他語言研究提供了一個比較可行的思路。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100744 -
數據集
+關注
關注
4文章
1208瀏覽量
24695
原文標題:ACL 2018:最佳論文評選結果提前出爐
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一個benchmark實現大規模數據集上的OOD檢測
中國建立自主可控技術體系的一個機遇
一個完整的MNIST測試集,其中包含60000個測試樣本
Facebook AI發布了一個包含編碼問題和代碼片段答案的數據集
數據科學平臺cnvrg.io攜手NetApp用深度學習改變MLOps數據集緩存
GitHub上開源了個集眾多數據源于一身的爬蟲工具箱——InfoSpider
如何用PHP做一個機器學習數據集
建立計算模型來預測一個給定博文的抱怨強度
最全自動駕駛數據集分享系列一:目標檢測數據集






 工商網監
工商網監
評論