

編者按:考慮到原作者寫的“面向新手的CNN入門指南(二)”沒有太多實(shí)質(zhì)性的計(jì)算內(nèi)容,而是直接推薦論文建議讀者閱讀,因此論智決定跳過這一部分,直接總結(jié)過去幾年中計(jì)算機(jī)視覺和卷積神經(jīng)網(wǎng)絡(luò)領(lǐng)域的一些重大發(fā)展。本文主要介紹了從AlexNet到ResNet的網(wǎng)絡(luò)架構(gòu)進(jìn)步,對(duì)原文提到的包括GAN在內(nèi)的一些有趣的論文不做具體翻譯。
AlexNet(2012)
雖然許多人會(huì)認(rèn)為Yann LeCun在1989年和1998年發(fā)表的論文是CNN的開山之作,但真正讓它廣泛地為人所知并進(jìn)入科研領(lǐng)域的確實(shí)是這篇論文:ImageNet Classification with Deep Convolutional Neural Networks。截至目前,它的引用次數(shù)已經(jīng)高達(dá)23324。
2012年,來自多倫多大學(xué)的Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton創(chuàng)建了一個(gè)“大而深的卷積神經(jīng)網(wǎng)絡(luò)”,一舉贏得ILSVRC(ImageNet大規(guī)模視覺識(shí)別挑戰(zhàn))。對(duì)于不熟悉計(jì)算機(jī)視覺領(lǐng)域的人來說,ImageNet大賽在CV界的地位可以類比體育界的奧運(yùn)會(huì),每年來自世界各地的團(tuán)隊(duì)會(huì)在大賽中競(jìng)相角逐,看誰擁有能用于分類、檢測(cè)等任務(wù)的最佳CV模型。
就在那一年,CNN的Top-5錯(cuò)誤率穩(wěn)定在15.4%,而原比賽記錄是26.2%,這是一個(gè)令整個(gè)行業(yè)都為之震驚的進(jìn)步。可以肯定地說,從那之后,CNN在競(jìng)賽中已經(jīng)成為一個(gè)家喻戶曉的名字。
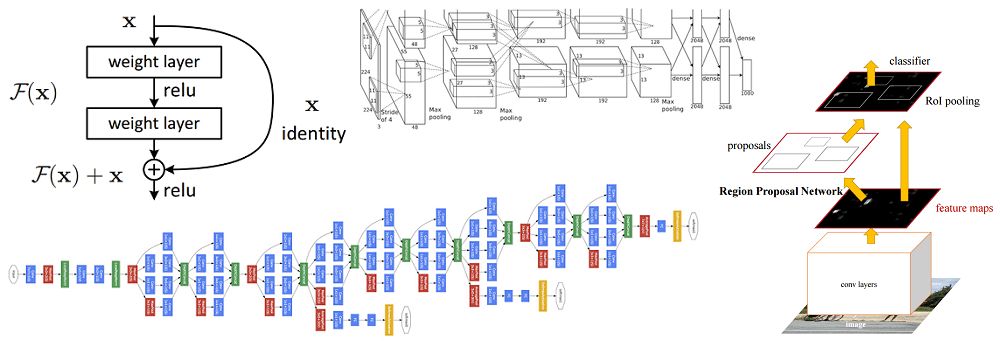
在論文中,Hinton等人提出了一種名為AlexNet的新型網(wǎng)絡(luò)架構(gòu)。和當(dāng)時(shí)的已有CNN相比,AlexNet布局精簡(jiǎn),由5個(gè)卷積層、最大池化層、dropout層和3個(gè)全連接的層組成,可以對(duì)1000種目標(biāo)進(jìn)行分類。
AlexNet整體架構(gòu)
提要
在ImageNet數(shù)據(jù)上訓(xùn)練網(wǎng)絡(luò),其中包含超過22000個(gè)類別的超過1500萬張注釋圖像。
把ReLu作為激活函數(shù)(可以縮短訓(xùn)練用時(shí),因?yàn)镽eLU比傳統(tǒng)tanh函數(shù)快幾倍)。
使用了圖片轉(zhuǎn)換、水平翻轉(zhuǎn)和改變顏色通道等圖像增強(qiáng)技術(shù)。
加入Dropout層以解決過擬合問題。
用批量隨機(jī)梯度下降訓(xùn)練模型,并手動(dòng)調(diào)試了momentum和權(quán)重衰減率的值。
在兩臺(tái)GTX 580 GPU上訓(xùn)練5-6天。
評(píng)價(jià)
Krizhevsky、Sutskever和Hinton在2012年提出的AlexNet稱得上是計(jì)算機(jī)視覺領(lǐng)域的一次狂歡,這是CNN模型首次在ImageNet數(shù)據(jù)集上表現(xiàn)出驚人的性能,他們也為以后的研究貢獻(xiàn)了大量技巧,其中圖像增強(qiáng)技術(shù)和dropout層一直被沿用至今。總而言之,這篇論文真正展現(xiàn)了CNN的優(yōu)勢(shì),并在競(jìng)賽中創(chuàng)造了破紀(jì)錄的成績(jī)。
ZF Net(2013)
自從2012年AlexNet在競(jìng)賽中成功“超神”后,參加ILSVRC 2013的CNN模型數(shù)量大幅提升,其中紐約大學(xué)的Matthew Zeiler和Rob Fergus憑借ZF Net成為了競(jìng)賽的最終獲勝者。ZF Net的Top-5錯(cuò)誤率只有11.2%,雖然從結(jié)構(gòu)上看它和AlexNet大體差不多,但它提出了一些關(guān)于提升性能的關(guān)鍵想法,而且比賽結(jié)果確實(shí)也比AlexNet提高了不少。
而ZF Net的成功之處不限于此,Matthew Zeiler和Rob Fergus寫了一篇非常出色的論文:Visualizing and Understanding Convolutional Neural Networks。他們?cè)敿?xì)介紹了CNN背后的許多原理,并用可視化的方式說明了filter和權(quán)重所發(fā)揮的作用。
在論文中,他們首先討論了一個(gè)觀點(diǎn),即CNN的崛起離不開大型數(shù)據(jù)集的建立和計(jì)算機(jī)算力的大幅提升。他們也指出研究人員對(duì)模型內(nèi)部機(jī)制知之甚少的嚴(yán)峻現(xiàn)狀,并認(rèn)為如果研究人員對(duì)CNN缺乏洞察力,那他們其實(shí)是在本著“開發(fā)更好的模型的愿景去試錯(cuò)和不斷失敗”。
的確,比起2013年,現(xiàn)在我們對(duì)CNN了解得更深了,但不可否認(rèn)的是許多行業(yè)內(nèi)的人到現(xiàn)在還對(duì)它一知半解。所以像Zeiler和Fergus這樣的工作還是很有意義的,這篇論文稍微修改了AlexNet模型的細(xì)節(jié),并用可視化的方式揭示了許多有趣的問題。
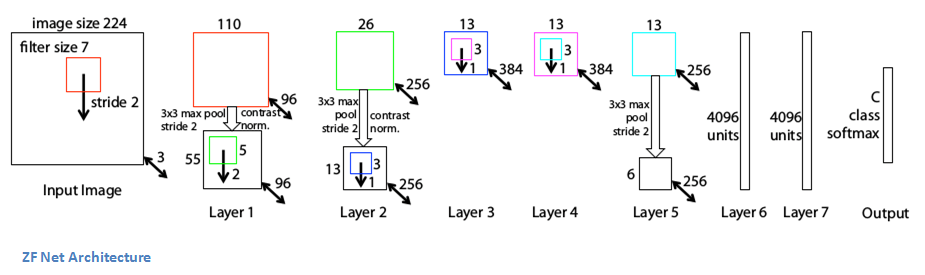
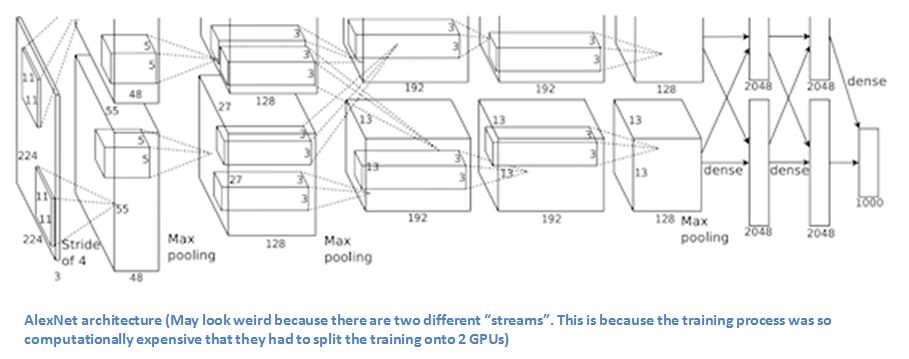
ZF Net整體架構(gòu)
提要
除了一些小修改,大體和AlexNet相同。
AlexNet在1500萬張圖片上進(jìn)行訓(xùn)練,而ZF Net只用了130萬張圖片。
ZF Net沒有在第一層用11× 11的filter,而是把尺寸改成了7×7并減少步長(zhǎng)。這么做的原因是在卷積層中,用更小的filter有利于保留更多原始像素信息,而保留大量信息對(duì)第一個(gè)卷積層來說尤為重要。
隨著網(wǎng)絡(luò)不斷發(fā)展,filter的數(shù)量也逐漸增加了。
把ReLU作為激活函數(shù),把交叉熵?fù)p失作為損失函數(shù),并用批量隨機(jī)梯度下降訓(xùn)練模型。
在GTX 580 GPU上訓(xùn)練了12天。
開發(fā)了一種名為Deconvolutional Network的可視化技術(shù),有助于檢查不同特征激活與輸入像素值的關(guān)系。之所以稱它“Deconvenet”(反卷積),是因?yàn)樗鼘⑻卣饔成浠叵袼乜臻g(與卷積層正好相反)。
DeConvNet
DeConvNet背后的基本思想是在訓(xùn)練好的CNN的每一層后,在某個(gè)位置附加一個(gè)“反卷積”(DeConvNet)的操作,它有一個(gè)通道能把提取到的特征反過來映射回圖像像素。
往CNN里輸入一張圖像,然后在每一層的計(jì)算激活,這是我們熟知的前向傳遞。現(xiàn)在,假設(shè)我們想檢查第四個(gè)卷積層中某個(gè)特征的激活情況,我們可以先把其他所有激活設(shè)置為0,只把目標(biāo)特征映射作為DeConvNet的輸入。DeConvNet和CNN共享filter,所以只要網(wǎng)絡(luò)確實(shí)都訓(xùn)練好了,這些特征映射就能通過一系列反池化(unpooling)、整流(rectify)和反濾波重新還原為原始輸入圖像的像素值。
它的出發(fā)點(diǎn)是研究圖像中能激活特征映射的結(jié)構(gòu)類型。讓我們看看第一層和第二層的可視化。
第一層和第二層的可視化:很容易看出對(duì)于給定filter,哪部分激活得最強(qiáng)
正如面向新手的CNN入門指南(一)中介紹的,CNN的第一層始終是一個(gè)低層次特征檢測(cè)器,它在上圖中只能檢測(cè)到簡(jiǎn)單的邊緣和顏色,而第二個(gè)卷積層明顯比上一個(gè)捕捉到了更多特征。趁熱打鐵,我們來看第3、4、5層。
第三層、第四層和第五層的可視化
這些層檢測(cè)到了更多更高層次的特征,如狗臉和鮮花。需要注意的一點(diǎn)是,第一個(gè)卷積層后通常都有一個(gè)池化層對(duì)圖像做下采樣,它的作用是在保留更多的細(xì)節(jié)特征的前提下減少冗余,比如把32×32×3轉(zhuǎn)成16×16×3。所以第二個(gè)卷積層的filter在原始圖像中“看”到的范圍其實(shí)是更廣了。
評(píng)價(jià)
ZF Net不僅是2013年ImageNet大賽的冠軍,它還提供了有關(guān)CNN的大量可視化原理解釋,為后期研究貢獻(xiàn)了提高性能的多種路徑。這些可視化方法既能被用于解釋CNN的內(nèi)部工作原理,又提供了改進(jìn)網(wǎng)絡(luò)架構(gòu)的諸多見解,這樣的貢獻(xiàn)使它成為一篇當(dāng)之無愧的優(yōu)秀論文。
VGG Net(2014)
簡(jiǎn)單而深入,這是VGG Net給所有人的普遍印象。和AlexNet、ZF Net不同,VGG Net并不是ILSVRC 2014的獲勝者,但這并不妨礙它在11.2%的基礎(chǔ)上進(jìn)一步把Top-5錯(cuò)誤率降低到7.3%。
VGG是牛津大學(xué)的Oxford Visual Geometry Group的名稱縮寫。2014年,牛津大學(xué)的Karen Simonyan和Andrew Zisserman創(chuàng)建了一個(gè)19層的CNN,它的每一層都使用大小為3×3、pad=1、stride=1的filter,同時(shí)網(wǎng)絡(luò)的池化核也不再是3×3,而是2×2、stride=2。憑借這個(gè)新型架構(gòu),牛津大學(xué)當(dāng)年在ImageNet大賽上斬獲分類第二、定位任務(wù)第一的佳績(jī)。
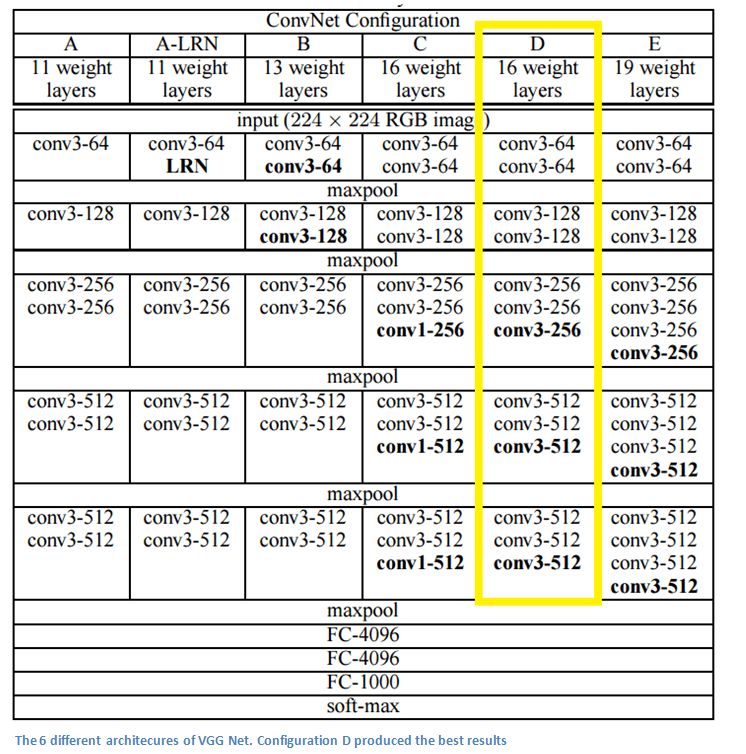
6種不同的VGG Net架構(gòu),其中D性能最好
提要
不同于AlexNet的11×11和ZF Net的7×7,VGG Net把卷積核全部替換成了3×3,因?yàn)樽髡甙l(fā)現(xiàn)2個(gè)3×3filter的感受野和1個(gè)5×5filter的相同。這樣做的好處是既能保持較小的filter尺寸,又能模擬更大的filter的性能。此外,它也減少了參數(shù)數(shù)量,允許使用更多的激活函數(shù)——多了兩個(gè)卷積意味著能多用兩次ReLU。
3個(gè)3×3filter的堆疊所獲得的感受野相當(dāng)于一個(gè)7×7的filter。
隨著網(wǎng)絡(luò)層數(shù)遞增,feature map的寬度高度會(huì)逐漸減小(卷積層和池化層的結(jié)果),但由于filter數(shù)量增加,它的深度會(huì)不斷加深。
VGG Net在圖像分類和目標(biāo)定位這兩個(gè)任務(wù)上表現(xiàn)得尤為出色。
用Caffe構(gòu)建模型。
數(shù)據(jù)增強(qiáng)技術(shù):Scale Jittering。
在每個(gè)卷積層后把ReLU作為激活函數(shù),并用批量隨機(jī)梯度下降訓(xùn)練模型。
在4塊Nvidia Titan Black GPU上訓(xùn)練了兩到三周。
評(píng)價(jià)
VGG Net是最有影響力的論文之一,因?yàn)樗撟C了卷積神經(jīng)網(wǎng)絡(luò)必須依靠足夠深的深度才能使視覺數(shù)據(jù)的分層表示發(fā)揮作用的觀點(diǎn)。
GoogLeNet(2015)
在GoogLeNet出現(xiàn)之前,上述這些架構(gòu)在提升CNN性能上的做法就是加深、拓寬神經(jīng)網(wǎng)絡(luò),為了防止過擬合,他們還要盡可能減少參數(shù)數(shù)量。但Google顯然不吃這一套,在ILSVRC 2014上,它往一堆CNN中丟了一個(gè)Inception,以6.7%的Top-5錯(cuò)誤率成了最后贏家。
據(jù)不完全統(tǒng)計(jì),這應(yīng)該是第一個(gè)真正不再繼續(xù)往CNN里懟卷積層和池化層的成熟架構(gòu)。此外,作者還強(qiáng)調(diào)新模型已經(jīng)針對(duì)內(nèi)存和計(jì)算量做了優(yōu)化,讓研究人員開始注意到加深網(wǎng)絡(luò)帶來的各種硬件上的不良影響。
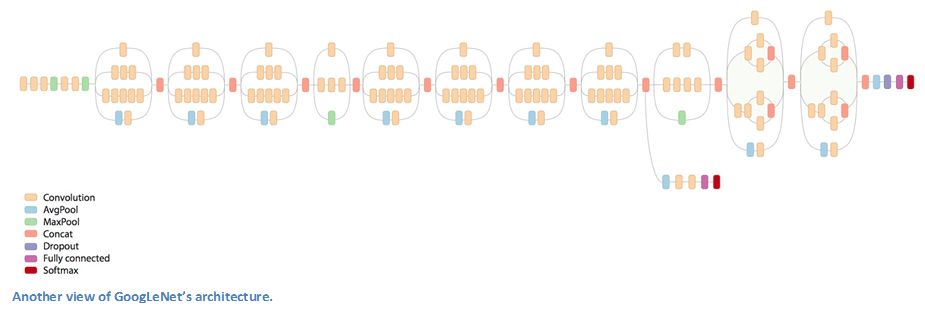
GoogLeNet整體架構(gòu)
Inception
當(dāng)?shù)谝淮慰吹紾oogLeNet的整體架構(gòu)時(shí),我們一眼就能發(fā)現(xiàn)這是一個(gè)按順序進(jìn)行的神經(jīng)網(wǎng)絡(luò)。當(dāng)然,其中也有不少并行網(wǎng)絡(luò)。
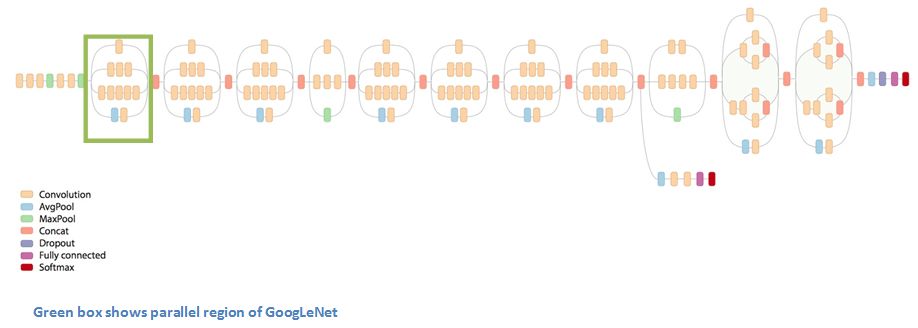
上圖的這個(gè)模塊被稱為Inception,下面是它的具體構(gòu)成:
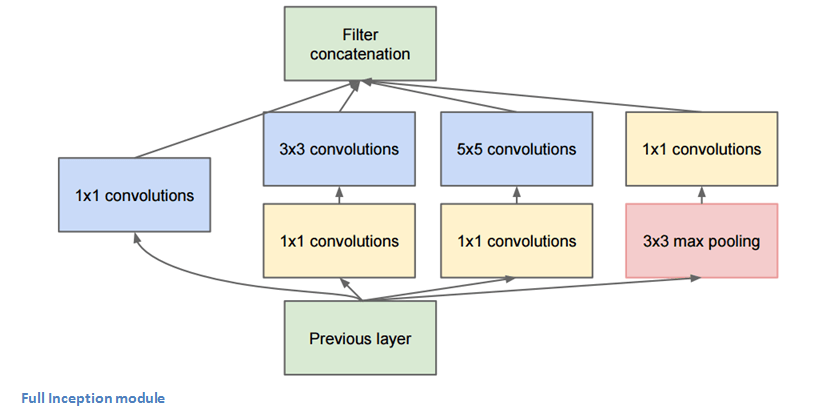
Inception模塊全貌
圖片底部的綠色框是輸入,最上面的綠色框是輸出。如果是一個(gè)傳統(tǒng)的CNN,它在每一層只能執(zhí)行一個(gè)操作,比如池化和卷積(還要選filter大小),但I(xiàn)nception模塊允許網(wǎng)絡(luò)以并行的方式同時(shí)完成所有操作——這也正是作者“naive”的地方。
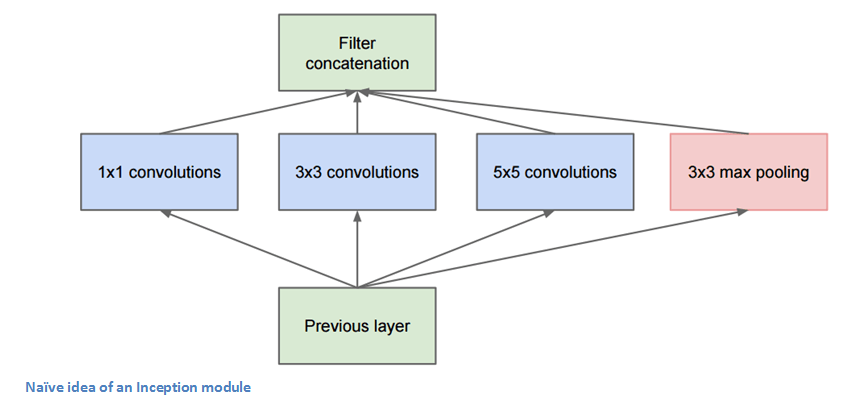
Naive版Inception
上圖其實(shí)是作者的最初想法,但為什么這個(gè)Naive版的Inception不起作用?如圖所示,隨著層數(shù)的加深,feature map中特征的空間集中度會(huì)下降,這就需要更多5×5的filter,相應(yīng)的網(wǎng)絡(luò)也需要更多的參數(shù)。因此作者在3×3和5×5的filter前加了一個(gè)1×1的filter,它可以幫助降維。假設(shè)我們有一個(gè)100×100×60的輸入,這時(shí)20個(gè)1×1的卷積核就能把它降維到100×100×20,無論后面的filter是3×3還是5×5,它們輸入的數(shù)組就遠(yuǎn)沒有原始數(shù)據(jù)那么高維了。
換句話說,這也可以被看做是在對(duì)特征做池化,因?yàn)樗闹苯咏Y(jié)果是減小特征深度,和最大池化層減小feature map的寬度和高度類似。
那么這樣的結(jié)構(gòu)真的有效嗎?GoogLeNet(Inception v1)包含一個(gè)Network In Network層、一個(gè)中等大小的filter、一個(gè)大型的filter和一個(gè)池化操作。Network In Network層可以從圖像中提取非常精細(xì)的紋理細(xì)節(jié)信息;而5×5的filter能覆蓋大范圍的感受野,也能從中提取大量信息。通過聯(lián)合操作,研究人員能控制輸入的尺寸并防止過擬合。更重要的是,每個(gè)卷積層后都跟有ReLU,它能提高網(wǎng)絡(luò)的非線性。
簡(jiǎn)而言之,這個(gè)架構(gòu)能在減小輸入空間的同時(shí)防止過擬合,并兼顧內(nèi)存占用和計(jì)算量的節(jié)約。
提要
在整個(gè)架構(gòu)中用了9個(gè)Inception模塊,總共超過100層!
沒有使用全連接層,而是用了平均池化,把大小從7×7×1024降到了1×1×1024,減少了大量參數(shù)。
使用的參數(shù)量是AlexNet的十二分之一。
在測(cè)試過程中對(duì)同一張圖像進(jìn)行多次裁剪,輸入網(wǎng)絡(luò)用softmax計(jì)算平均值后再給出結(jié)果。
沿用R-CNN的思路檢測(cè)模型。
Inception模塊的后期更新。
用“一些高端GPU”訓(xùn)練了一周。
評(píng)價(jià)
GoogLeNet是第一個(gè)不按尋常套路堆疊層次的模型,而對(duì)于Inception模塊,作者也表示創(chuàng)造層次結(jié)構(gòu)可以提高CNN的性能和計(jì)算效率。
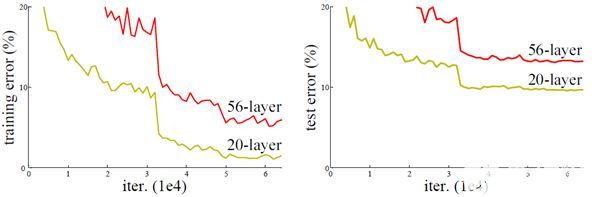
ResNet(2015)
8層、19層、22層,之后數(shù)年,CNN在深度這條路上越走越遠(yuǎn)。想象一個(gè)普通的CNN,我們把它的層數(shù)翻倍,然后再加幾個(gè)層次,這已經(jīng)很深了,但很可惜,它還是遠(yuǎn)遠(yuǎn)比不上微軟亞洲研究院何凱明團(tuán)隊(duì)于2015年年底提出的ResNet。
ResNet是一個(gè)深度達(dá)152層的新型CNN架構(gòu),除了在層數(shù)上打破了原有的記錄,它在分類、檢測(cè)和定位任務(wù)上也成績(jī)斐然,以3.6%的錯(cuò)誤率贏得了2015年的ILSVRC。這是一個(gè)令人驚嘆的成果,因?yàn)槟壳叭祟愐揽孔陨碚J(rèn)知能力和專業(yè)水平所達(dá)到的平均成績(jī)一直徘徊在5%-10%。
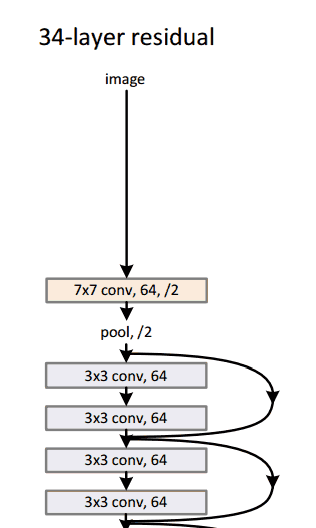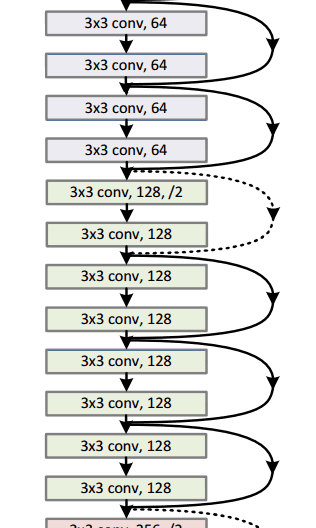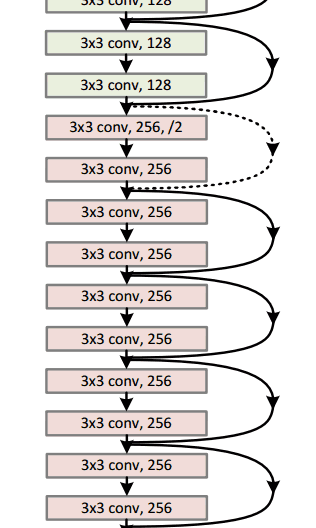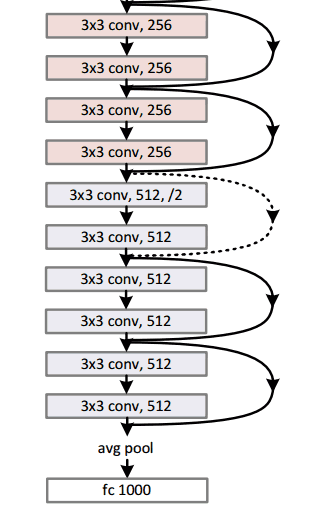
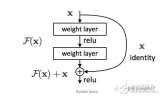
殘差塊(Residual Block)
ResNet的核心是殘差塊,而殘差塊背后的思路是當(dāng)向網(wǎng)絡(luò)中輸入一個(gè)x后,x會(huì)經(jīng)歷一系列卷積—ReLU—卷積,我們把這過程中發(fā)生的的計(jì)算看做函數(shù)F(x),再加上輸入的x,實(shí)際上網(wǎng)絡(luò)要學(xué)會(huì)的函數(shù)應(yīng)該是H(x)=F(x)+x。
對(duì)于以往的CNN,當(dāng)訓(xùn)練完成后,H(x)應(yīng)該恰好等于F(x)。但何凱明團(tuán)隊(duì)認(rèn)為像這樣直接求H(x)太過困難,既然H(x)=F(x)+x,那不如就從它的的殘差形式F(x)+x開始進(jìn)行優(yōu)化。如下圖所示,通過加入一個(gè)identity mapping(恒等映射),殘差塊對(duì)原始輸入x做了一些細(xì)微的調(diào)整,這樣做的直接結(jié)果就是ResNet的優(yōu)化過程比普通CNN更簡(jiǎn)單。
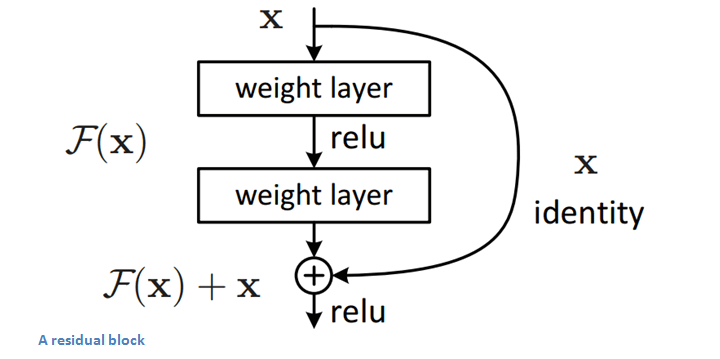
殘差塊
殘差塊能發(fā)揮作用的另一個(gè)原始是在反向傳播的反向傳遞過程中,因?yàn)镠(x)=F(x)+x中包含加法運(yùn)算,所以它們可以分配梯度,梯度傳播更加順暢。
提要
“超深!”——Yann LeCun。
152層……
僅在通過網(wǎng)絡(luò)的前兩層后,輸入的空間就從224×224被壓縮到了56×56。
何凱明團(tuán)隊(duì)嘗試過建立一個(gè)1202層的CNN,但可能是因?yàn)檫^擬合,模型準(zhǔn)確率較低。
用8塊GPU訓(xùn)練了兩到三周。
評(píng)價(jià)
3.6%的錯(cuò)誤率,這個(gè)數(shù)字本身就能說明不少問題。雖然距離提出已經(jīng)過去了2年多,但到目前為止,ResNet還是最好的CNN之一。同時(shí)它也開創(chuàng)了殘差塊這種偉大的做法。
福利:殘差塊里的殘差塊(好像有點(diǎn)暈)
基于CNN的其他網(wǎng)絡(luò)
這些CNN的目的是解決目標(biāo)檢測(cè)的問題。給定一個(gè)圖像,我們希望模型能夠在所有對(duì)象上繪制出檢測(cè)框,它一般分為兩步:一是用CNN從圖像區(qū)域中檢測(cè)出特征,二是利用分類器預(yù)測(cè)當(dāng)前區(qū)域包含目標(biāo)特征的置信度(圖像分類)。
R-CNN-2013
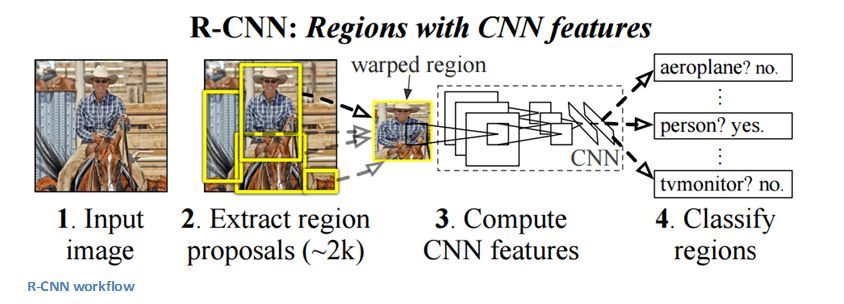
Fast R-CNN-2015
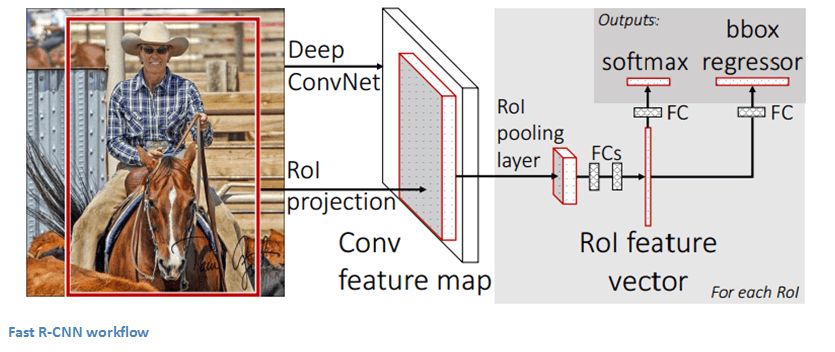
Faster R-CNN-2015
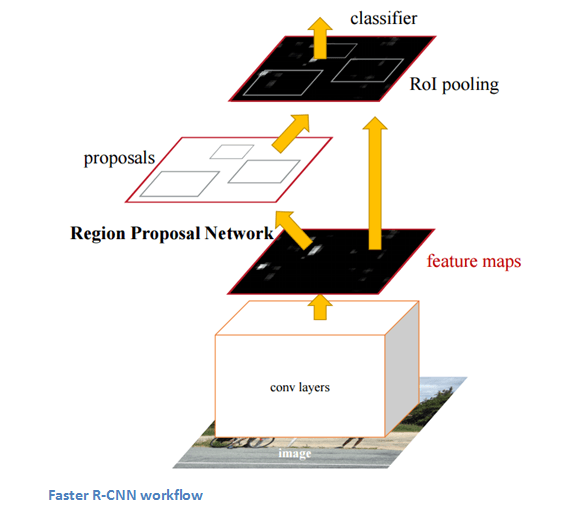
能夠確定圖像中包含特定對(duì)象是一回事,但確定它具體在哪一位置就是另一回事了。從R-CNN到Fast R-CNN再到Faster R-CNN,如今的物體檢測(cè)技術(shù)正趨于完善。
生成對(duì)抗網(wǎng)絡(luò)(2014)
這是被Yann LeCun譽(yù)為下一個(gè)重大發(fā)展的神經(jīng)網(wǎng)絡(luò)。它包含兩部分:一個(gè)生成模型和一個(gè)判別模型。其中判別模型的任務(wù)是確定輸入圖像的真實(shí)性:它是來自數(shù)據(jù)集的自然圖像,還是其他渠道生成的偽圖像。而生成模型的任務(wù)是通過判別模型的判定結(jié)果一遍遍提升自我,生成能愚弄對(duì)方的偽圖像。
如今圍繞GAN的研究有很多,但因?yàn)椴皇呛艹墒欤S多人會(huì)建議新人不要盲目去深入嘗試。但正如Yan Le Leun在他的Quora文章中所說的那樣,GAN的判別模型其實(shí)已經(jīng)意識(shí)到了數(shù)據(jù)的內(nèi)部表示,它了解真實(shí)圖像和生成圖像之間的差異,因此把它作為CNN的特征提取器也未嘗不可。如果不放手實(shí)踐,可能你將錯(cuò)失許多學(xué)習(xí)成長(zhǎng)的樂趣。
生成圖像注釋(2014)
如果把CNN和RNN結(jié)合在一起,我們會(huì)得到什么?反正肯定不是R-CNN :laughing: 。Andrej Karpathy和李飛飛在這篇論文里向我們展示了一個(gè)很有趣的成果,即用CNN和雙向RNN生成不同圖像區(qū)域內(nèi)的自然語言注釋。

具體內(nèi)容我們這里不做詳談。它的貢獻(xiàn)在于將計(jì)算機(jī)視覺和自然語言處理等領(lǐng)域結(jié)合起來,為構(gòu)建跨領(lǐng)域任務(wù)模型打開了一扇新的大門。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4806瀏覽量
102684 -
計(jì)算機(jī)視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46549 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122443
原文標(biāo)題:面向新手的CNN入門指南(二)——必讀的十篇深度學(xué)習(xí)論文
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
深度學(xué)習(xí)與圖神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)分享:CNN經(jīng)典網(wǎng)絡(luò)之-ResNet
一種利用光電容積描記(PPG)信號(hào)和深度學(xué)習(xí)模型對(duì)高血壓分類的新方法
從AlexNet到MobileNet,帶你入門深度神經(jīng)網(wǎng)絡(luò)
一文讀懂物體分類AI算法:LeNet-5 AlexNet VGG Inception ResNet MobileNet
【CANN訓(xùn)練營(yíng)第三季】基于Caffe ResNet-50網(wǎng)絡(luò)實(shí)現(xiàn)圖片分類
使用計(jì)算庫在Raspberry PI和HiKey 960上分析AlexNet
形象的理解深度網(wǎng)絡(luò)架構(gòu)?
用AlexNet對(duì)cifar-10數(shù)據(jù)進(jìn)行分類
卷積神經(jīng)網(wǎng)絡(luò)的特點(diǎn),優(yōu)缺點(diǎn),數(shù)據(jù)處理等詳細(xì)資料免費(fèi)下載
網(wǎng)絡(luò)架構(gòu)對(duì)ResNet訓(xùn)練時(shí)間有什么影響
基于改進(jìn)U-Net網(wǎng)絡(luò)建立HU-ResNet模型

PyTorch教程8.1之深度卷積神經(jīng)網(wǎng)絡(luò)(AlexNet)

PyTorch教程8.6之殘差網(wǎng)絡(luò)(ResNet)和ResNeXt





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論