 圖像增強的主要方法及其Python實現
圖像增強的主要方法及其Python實現
編者按:倫敦帝國學院計算成像PhD學生Rob Robinson介紹了圖像增強的主要方法及其Python實現。
進行有效的深度學習網絡訓練的最大限制因素是訓練數據。為了很好地完成分類任務,我們需要給我們的CNN等模型盡可能多的樣本。然而,并不是所有情況下都可能做到這一點,特別是處于一些訓練數據很難收集的情形,比如醫學影像數據。在本文中,我們將學習如何應用數據增強策略至n維圖像,以充分利用數量有限的樣本。
介紹
如果我們將任何圖像(比如下面的機器人)整體向右移動一個像素,視覺上幾乎毫無差別。然而,數值上這是兩張完全不同的圖像!想象一下有一組10張這樣的圖像,每張相對前一張平移一個像素。現在考慮圖像[20, 25]處的像素或某個任意的位置。聚焦到這一點,每個像素有不同的顏色,不同的周邊平均亮度,等等。一個CNN在進行卷積和決定權重時,會將這些考慮在內。如果我們將這組10張圖像傳給CNN,應該能夠有效地讓CNN學習忽略這類平移。
原圖
向右平移1像素
向右平移10像素
當然,平移不是在保證視覺上看起來一樣的前提下改動圖像的唯一方式。考慮下將圖片旋轉1度,或者5度。它仍然是機器人。用不帶平移和旋轉版本的圖像訓練CNN可能導致CNN過擬合,認為所有機器人的圖像都是不偏不倚的。
給深度學習模型提供平移、旋轉、縮放、改變亮度、翻轉的圖像,我們稱之為數據增強。
在本文中,我們將查看如何應用這些變換至圖像,包括3D圖像,及其對深度學習模型表現的影響。我們將使用flickr用戶andy_emcee拍攝的照片作為2D自然圖像的樣本。由于這是一幅RGB(彩色)圖像,因此它的形狀為[512, 640, 3],每層對應一個色彩頻道。我們可以抽掉一層,將圖像轉為灰度圖像(真2D),不過我們處理的大部分圖像都是彩色圖像,因此我們這里保留原樣。我們將使用3D MRI掃描圖作為3D圖像的樣本。
RGB圖像
增強
我們將使用python編寫數據增強函數(基于numpy和scipy)。
平移
在我們的函數中,圖像是一個2D或3D數組——如果它是一個3D數組,我們需要小心地在offset參數中指定方向。我們并不想在z方向上移動,原因如下:首先,如果這是一個2D圖像,第三維將是色彩頻道,如果我們在這一維度上移動了-2、2或更多,整個圖像將變成全紅、全藍或全黑;其次,在全3D圖像中,第三維常常是最小的,例如,在大多數醫學掃描圖像中。在下面的平移函數中,offset是一個長度為2的數組,定義了y和x方向的平移。我們硬編碼z方向為0,不過,根據你的具體情況,你可以加以改動。為了確保我們平移的像素是整數,我們強制使用int。
def translateit(image, offset, isseg=False):
order = 0if isseg == Trueelse5
return scipy.ndimage.interpolation.shift(image, (int(offset[0]), int(offset[1]), 0), order=order, mode='nearest')
當我們平移圖像時,會在圖像邊緣留下一條縫隙。我們需要找到填補這一縫隙的方式:shift默認將使用一個常量(0)。但在某些情況下,這可能無濟于事,所以最好將mode設為nearest,使用鄰近的像素值填充。平移值較小時,幾乎難以察覺這一點。不過平移值較大時,看起來就不對勁了。所以我們需要小心,僅對我們的數據應用較小的平移。
另外,我們提供了一個布爾值選項isseg,供選擇order參數的值。isseg為真時(處理分割圖),order為0,也就是直接使用最近的像素值填充;isseg為假時,order為5,也就是進行5次B樣條插值(綜合考量目標周圍的許多像素)。
原圖
右移5像素
右移25像素
原圖、分割圖
平移[-3, 1]像素
平移4, -5像素
縮放
我們根據一個特定的倍數(factor)縮放圖像。倍數大于1.0時,放大圖像;倍數小于1.0時,縮小圖像。注意我們需要為每個維度指定倍數:其中,最后一個維度(2D圖像中為色彩頻道)倍數為1.0。我們使用柵格(網格)來決定結果圖像每個像素的亮度(使用周圍像素的亮度進行插值)。scipy提供了一個方便的函數,稱為zoom。
定義大概要比你想象的復雜:
def scaleit(image, factor, isseg=False):
order = 0if isseg == Trueelse3
height, width, depth= image.shape
zheight = int(np.round(factor * height))
zwidth = int(np.round(factor * width))
zdepth = depth
if factor < 1.0:
newimg = np.zeros_like(image)
row = (height - zheight) // 2
col = (width - zwidth) // 2
layer = (depth - zdepth) // 2
newimg[row:row+zheight, col:col+zwidth, layer:layer+zdepth] = interpolation.zoom(image, (float(factor), float(factor), 1.0), order=order, mode='nearest')[0:zheight, 0:zwidth, 0:zdepth]
return newimg
elif factor > 1.0:
row = (zheight - height) // 2
col = (zwidth - width) // 2
layer = (zdepth - depth) // 2
newimg = interpolation.zoom(image[row:row+zheight, col:col+zwidth, layer:layer+zdepth], (float(factor), float(factor), 1.0), order=order, mode='nearest')
extrah = (newimg.shape[0] - height) // 2
extraw = (newimg.shape[1] - width) // 2
extrad = (newimg.shape[2] - depth) // 2
newimg = newimg[extrah:extrah+height, extraw:extraw+width, extrad:extrad+depth]
return newimg
else:
return image
我們需要考慮三種可能性——放大、縮小、不變。在每種情形下,我們想要返回與輸入圖像尺寸相等的數組。縮小時,這牽涉創建一張大小形狀和輸入圖像一致的空圖像,并在當中相應的位置放入縮小后的圖像。放大時,不需要放大整張圖像,只需放大“縮放”的區域——因此我們只將數組的一部分傳給zoom函數。取整可能造成最終形狀中的一些誤差,所以我們在返回圖像前進行了一些修剪。不縮放時,我們返回原圖。
原圖
原圖、分割圖
縮放倍數1.07
縮放倍數0.95
重采樣
有時我們需要修改圖像,使其符合CNN的輸入格式要求。例如,對大多數圖像和照片而言,一個維度比另一個維度大,或者分辨率參差不齊。而大多數CNN需要尺寸一致的正方形輸入。我們同樣可以使用scipy函數interpolation.zoom辦到這一點:
def resampleit(image, dims, isseg=False):
order = 0if isseg == Trueelse5
image = interpolation.zoom(image, np.array(dims)/np.array(image.shape, dtype=np.float32), order=order, mode='nearest')
if image.shape[-1] == 3: # rgb圖像
return image
else:
return image if isseg else (image-image.min())/(image.max()-image.min())
這里的關鍵部分是我們將factor參數替換為類型為列表的dims參數。dims的長度應當和圖像的維度相等,即,2或3. 我們計算每個維度需要改變的倍數以將整個圖像變動到dims目標。
在這一步中,當圖像不是分割圖時,我們同時將圖像的亮度轉換至0.0至1.0區間,以確保所有圖像的亮度位于同一區間。
旋轉
我們利用了另一個scipy函數rotate。它的theta參數接受一個浮點數,用來指定旋轉的角度(負數表示逆時針旋轉)。我們想要返回和輸入圖像大小和形狀相同的圖像,因此使用了reshape = False。同樣,我們需要指定order決定插值方法。rotate函數支持3D圖像,使用相同的theta值旋轉每個切片。
def rotateit(image, theta, isseg=False):
order = 0if isseg == Trueelse5
return rotate(image, float(theta), reshape=False, order=order, mode='nearest')
原圖
theta = -10.0
theta = 10.0
原圖、分割圖
theta = 6.18
theta = -1.91
亮度變動
我們還可以縮放像素的亮度,也就是加亮或壓暗圖像。我們指定一個倍數:倍數小于1.0將壓暗圖像;倍數大于1.0將加亮圖像。注意倍數不能為0.0,否則會得到全黑的圖像。
def intensifyit(image, factor):
return image*float(factor)
翻轉
對自然圖像(狗、貓、風景等)而言,最常見的圖像增強過程是翻轉。其依據是不管狗朝向哪一邊,始終是狗。不管樹在右邊還是在左邊,它仍然是一棵樹。
我們可以進行左右翻轉,也可以進行上下翻轉。有可能只有一種翻轉有意義(比如,我們知道狗不能通過它們的頭行走)。我們通過由2個布爾值組成的列表指定如何進行翻轉:如果每個值都是1,那么同時進行兩種翻轉。我們使用numpy函數fliplr和flipup。
def flipit(image, axes):
if axes[0]:
image = np.fliplr(image)
if axes[1]:
image = np.flipud(image)
return image
剪切
這可能是一個小眾的函數,但在我的案例中很重要。處理自然圖像時,常常在圖像上進行隨機剪切,以得到補丁——這些補丁常常包含大部分圖像數據,例如,基于299 x 299圖像得到的224 x 224補丁。這不過是另一種給網絡提供視覺上非常相似而數值上完全不同的圖像的方法。同時也進行中央剪切。我的案例有一個不同的需求,我希望提供給網絡的圖像中,分割永遠是完全可見的(我處理的是3D心臟MRI分割)。
所以下面的函數查找分割,然后創建一個包圍盒。我們將生成“正方形”分割,邊長等于圖像的寬度(最短邊之長,不計入深度)。在這一情形下,創建了包圍盒之后,如有必要,上下移動窗口以確保整個分割可見。函數同時確保輸出總是正方形的,即使包圍盒部分移出圖像數組的界限。
def cropit(image, seg=None, margin=5):
fixedaxes = np.argmin(image.shape[:2])
trimaxes = 0if fixedaxes == 1else1
trim = image.shape[fixedaxes]
center = image.shape[trimaxes] // 2
print image.shape
print fixedaxes
print trimaxes
print trim
print center
if seg isnotNone:
hits = np.where(seg!=0)
mins = np.argmin(hits, axis=1)
maxs = np.argmax(hits, axis=1)
if center - (trim // 2) > mins[0]:
while center - (trim // 2) > mins[0]:
center = center - 1
center = center + margin
if center + (trim // 2) < maxs[0]:
while center + (trim // 2) < maxs[0]:
center = center + 1
center = center + margin
top = max(0, center - (trim //2))
bottom = trim if top == 0else center + (trim//2)
if bottom > image.shape[trimaxes]:
bottom = image.shape[trimaxes]
top = image.shape[trimaxes] - trim
if trimaxes == 0:
image = image[top: bottom, :, :]
else:
image = image[:, top: bottom, :]
if seg isnotNone:
if trimaxes == 0:
seg = seg[top: bottom, :, :]
else:
seg = seg[:, top: bottom, :]
return image, seg
else:
return image
注意,即使在不給定分割的情況下,該函數仍能剪切出正方形圖像。
原圖
剪切后
原圖、分割圖
剪切后
應用
應用轉換函數時需要小心。例如,如果我們對同一圖像應用多種轉換,我們需要確保不在“改變亮度”后進行“重采樣”,否則將重置圖像的亮度區間,抵消“改變亮度”的效果。不過,由于我們通常希望數據處于同一區間,全圖亮度平移很少見。我們同時也希望確保我們對數據增強不過分狂熱——倍數和其他參數需要設定限制。
當我實現數據增強時,我將所有轉換函數放在一個腳本transform.py中,之后在其他腳本中調用該腳本的函數。
我們在一定范圍內隨機抽取增強參數(避免過于極端的增強參數),以及需要進行的增強類型(我們并不打算每次應用所有增強)。
np.random.seed()
numTrans = np.random.randint(1, 6, size=1)
allowedTrans = [0, 1, 2, 3, 4]
whichTrans = np.random.choice(allowedTrans, numTrans, replace=False)
我們每次分配一個新的random.seed,以確保每次運行和上次運行不同。共有5種可能的增強類型,所以numTrans是1到5之間的隨機整數。我們不想重復應用相同類型的增強,所以replace設為False。
經過一些試錯,我發現以下參數比較好:
旋轉theta ∈ [?10.0,10.0]度
縮放factor ∈ [0.9,1.1],即,10%的放大或縮小
亮度factor ∈ [0.8,1.2],即,20%的增減
平移offset ∈ [?5,5]像素
邊緣我傾向于設置為5到10個像素
來看一個例子吧。假設圖像為thisim,分割為thisseg:
if0in whichTrans:
theta = float(np.around(np.random.uniform(-10.0,10.0, size=1), 2))
thisim = rotateit(thisim, theta)
thisseg = rotateit(thisseg, theta, isseg=True) if withseg else np.zeros_like(thisim)
if1in whichTrans:
scalefactor = float(np.around(np.random.uniform(0.9, 1.1, size=1), 2))
thisim = scaleit(thisim, scalefactor)
thisseg = scaleit(thisseg, scalefactor, isseg=True) if withseg else np.zeros_like(thisim)
if2in whichTrans:
factor = float(np.around(np.random.uniform(0.8, 1.2, size=1), 2))
thisim = intensifyit(thisim, factor)
# 不改變分割圖的亮度
if3in whichTrans:
axes = list(np.random.choice(2, 1, replace=True))
thisim = flipit(thisim, axes+[0])
thisseg = flipit(thisseg, axes+[0]) if withseg else np.zeros_like(thisim)
if4in whichTrans:
offset = list(np.random.randint(-5,5, size=2))
currseg = thisseg
thisim = translateit(thisim, offset)
thisseg = translateit(thisseg, offset, isseg=True) if withseg else np.zeros_like(thisim)
在每種情形下,尋找一組隨機參數,傳給轉換函數。圖像和分割圖分別傳給轉換函數。在我的例子中,我只通過隨機選擇0或1進行水平翻轉,并附加[0]使轉換函數忽略第二軸。另外加入了一個布爾值變量withseg,其為真時增強分割圖,否則返回一張空圖像。
最后,我們剪切圖像為正方形,然后重采樣至所需dims。
thisim, thisseg = cropit(thisim, thisseg)
thisim = resampleit(thisim, dims)
thisseg = resampleit(thisseg, dims, isseg=True) if withseg else np.zeros_like(thisim)
將這些都放在同一腳本中,以便于測試增強。關于這個腳本,有一些需要說明的地方:
腳本接受一個必選參數(圖像文件名)和一個可選分割圖文件名
腳本中包含一點檢測錯誤的邏輯——文件能否加載?它是rgb圖像還是全3D圖像(第三維大于3)?
我們指定最終圖像的維度,例如[224, 224, 8]
我們同時為參數聲明了一些默認值……
……以便在最后打印出應用的轉換及其參數
定義了一個plotit函數,該函數創建一個2 x 2矩陣,其中上面兩張圖像是原圖,下面兩張為增強圖像
注釋掉的部分是我用來保存本文創建的圖像的代碼
在一個在線設定下,我們希望即時進行數據增強。基本上,我們將調用這一腳本,接受一些待增強的文件名或圖像矩陣,然后創建我們想要的增強。
-
圖像增強
+關注
關注
0文章
54瀏覽量
10033 -
python
+關注
關注
56文章
4792瀏覽量
84628 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:N維圖像的數據增強方法概覽
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
labview 實現圖像增強
基于Matlab的圖像增強與復原技術在SEM圖像中的應用
基于DSP的夜間圖像實時增強系統
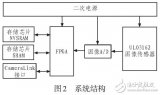
改進的紅外圖像增強算法及其在FPGA上的實現
MATLAB如何實現圖像增強灰度變換直方圖均衡匹配

利用模擬技術進行圖像增強的方法設計詳解

如何使用Python和Numpy等技術實現圖像處理

如何使用FPGA實現實時圖像增強算法





 工商網監
工商網監
評論