 卷積神經網絡的介紹和應用用歐姆蛋來詳細介紹
卷積神經網絡的介紹和應用用歐姆蛋來詳細介紹
▌介紹
關于卷積神經網絡從交通燈識別到更實際的應用,我經常聽到這樣一個問題:“會否出現一種深度學習“魔法”,它僅用圖像作為單一輸入就能判斷出食物質量的好壞?”簡而言之,在商業中需要的就是這個:
當企業家面對機器學習時,他們是這樣想的:歐姆蛋的“質量(quality)”是好的。
這是一個不適定問題的例子:解決方案是否存在,解決方案是否唯一且穩定還沒辦法確定,因為“完成”的定義非常模糊(更不用說實現了)。雖然這篇文章并不是關于高效溝通或是項目管理,但有一點是很有必要的:永遠不要對沒有明確范圍的項目作出承諾。解決這種模棱兩可的問題,一個好辦法是先構建一個原型模式,然后再專注于完成后續任務的架構,這就是我們的策略。
▌問題定義
在我的原型實現中關注的是歐姆蛋(omelette),并構建了一個可擴展的數據管道,該管道輸出煎蛋的感知“質量”。可以這樣來概括:
問題類型:多類別分類,6 種離散的質量類別:[good, broken_yolk, overroasted, two_eggs, four_eggs, misplaced_pieces]。
數據集:人工收集了 351 個 DSLR 相機拍攝的各種煎蛋,其中:訓練集包含 139 張圖像;訓練過程中的測試集包含 32 張圖像;測試集包含 180 張圖像。
標簽:每張照片都標有主觀的質量等級。
度量標準:分類交叉熵。
必要的知識:三個蛋黃沒有破損,有一些培根和歐芹,沒有燒焦或殘碎的食物,則可以定義為“好的”煎蛋。
完成的定義:在兩周的原型模式設計后,測試集上產生的最佳交叉熵。
結果可視化:用于測試集上低維度數據展示的 t-SNE 算法。
相機采集的輸入圖像
本文的主要目標就是用一個神經網絡分類器獲取提取的信號,并對其進行融合,讓分類器就測試集上每一項的類概率進行 softmax 預測。下面是一些我們提取并發現有用的信號:
關鍵成分掩碼(Mask R-CNN):Signal #1.
按照每個成分分組的關鍵成分計數(基本上是不同成分計數的矩陣):Signal #2.
移除盛歐姆蛋盤子的 RGB 顏色和背景,不添加到模型中。這就比較明顯了:只需用損失函數在這些圖像上訓練一個卷積網絡分類器,在低維嵌入一個選定模型圖像到當前圖像之間的 L2 距離。但是這次訓練只用了 139 張圖像,因此無法驗證這一假設。
▌通用 50K 管道視圖(50K Pipeline Overview)
我省略了幾個重要步驟,諸如數據發現和探索性分析,基線和 MASK R-CNN 的主動標記管道(這是我為半監督的實例注釋所起的名稱,啟發來自Polygon-RNN demo video-https://www.youtube.com/watch?v=S1UUR4FlJ84)。50K 管道視圖如下:
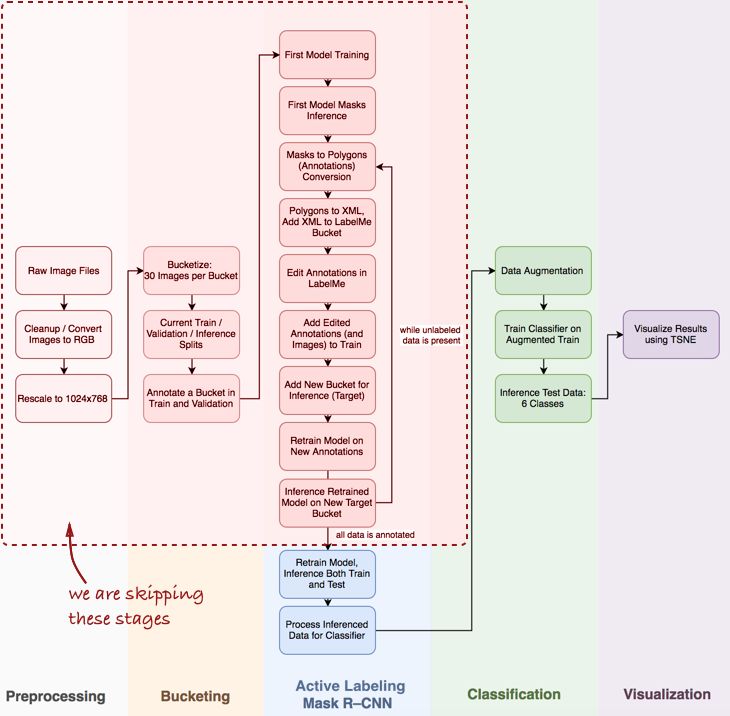
Mask R-CNN 以及管道的分類步驟
主要有三個步驟:[1]用于成分掩碼推斷的 MASK R-CNN,[2]基于 Keras 的卷積網絡分類器,[3]t-SNE 算法的結果數據集可視化。
步驟一:Mask R-CNN 和掩碼推斷
MaskR-CNN 最近較為流行。從最初的Facebook’s 論文開始,再到 Kaggle 上的 Data Science Bowl 2018,MASK R-CNN 證明了其強大的體系結構,比如分割(對象感知分割)。本文所使用的基于 Keras 的MRCNN代碼結構良好、文檔完整、工作迅速,但是速度比預期的要慢。
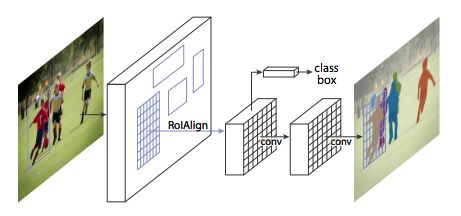
最新論文所展現的 MRCNN 框架
MRCNN 由兩個部分組成:主干網絡和網絡頭,它繼承了FasterR-CNN架構。不管是基于特征金字塔網絡(FPN)還是 ResNet 101,卷積主干網絡都是整個圖像的特征提取器。在此之上的是區域提議網絡(RPN),它為頭部采樣感興趣區域(ROI)。網絡頭部對每個 ROI 進行包圍盒識別和掩碼預測。在此過程中,RoIAlign 層精細地將 RPN 提取的多尺度特征與輸入內容進行匹配。
在實際應用中,特別是在原型設計中,經過預先訓練的卷積神經網絡是其關鍵所在。在許多實際場景中,數據科學家通常有數量有限的注釋數據集,有些甚至沒有任何注釋。相反,卷積網絡需要大量的標記數據集進行收斂(如 ImageNet 數據集包含 120 萬標記圖像)。這就是需要遷移學習的用處所在:凍結卷積層的權重,只對分類器進行再訓練。對于小型數據集來說,凍結卷積層權重可以避免過擬合。
經過一次(epoch )訓練所取得的樣本如下圖所示:
實例分割的結果:所有關鍵成分都被檢測到
下一步是裁剪碟子部分,并從中為每一成分提取二維二進制掩碼:
帶有目標碟子及如二進制掩碼一樣關鍵成分部分
這些二進制掩碼緊接著組成一個 8 通道圖像( MRCNN 定義了 8 個掩碼類別)。Signal #1 如下圖所示:
Signal #1:由二進制掩碼組成的 8 通道圖像。不同的顏色只為了能更好進行可視化觀察。
對于 Signal #2,MRCNN 推斷出每一種成分的量,并將其打包成一個特征向量。
步驟二:基于 Keras 的卷積神經網絡分類器
我們已經使用 Keras 從頭構建了一個 CNN 分類器。其目標是整合幾個信號(Signal#1 和 Signal#2,未來還會再添加更多數據),并讓網絡對食物的質量類別做出預測。真實的體系結構如下:
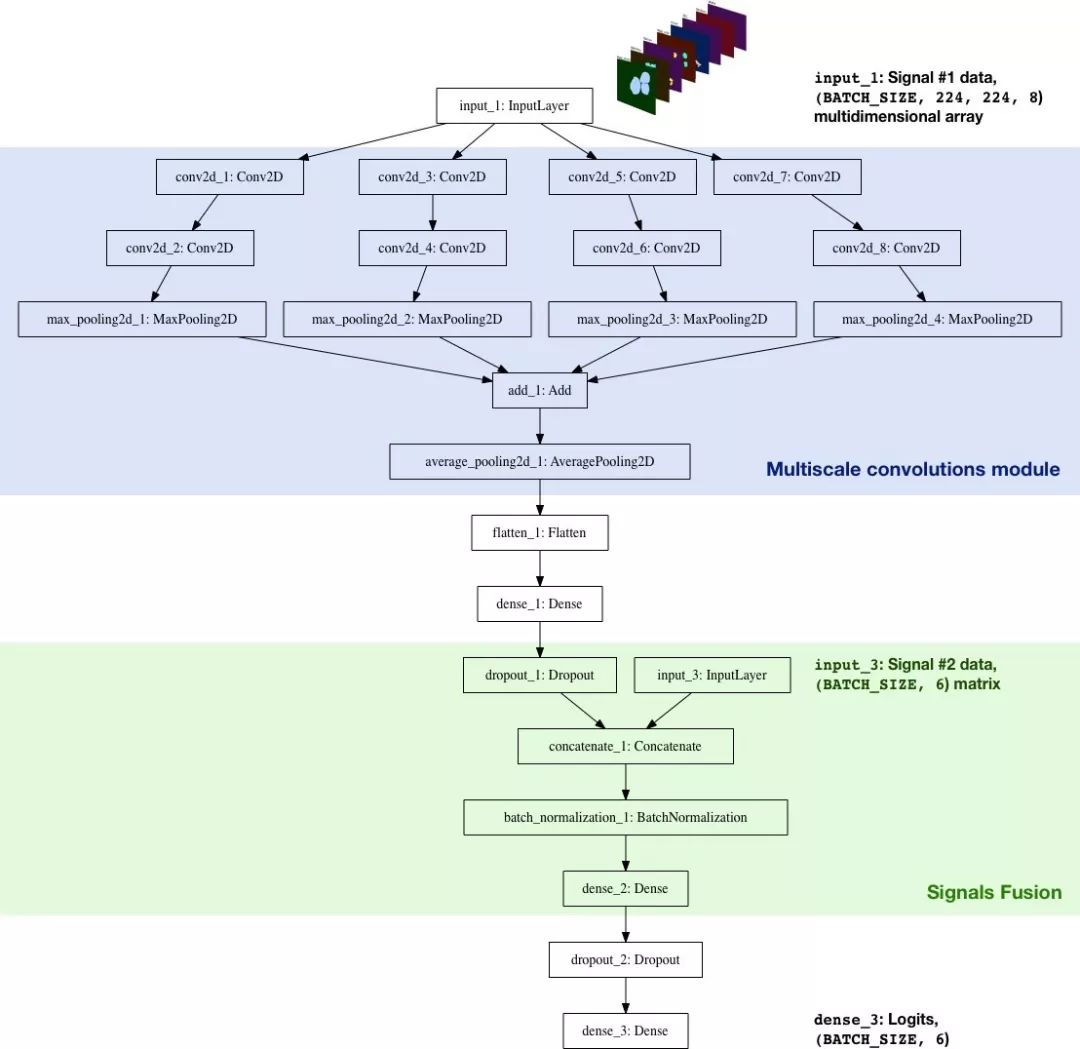
分類器架構的特點如下:
多尺度卷積模塊:最初,卷積層的內核大小為 5*5,結果不如人意,但有幾種不同內核(3*3,5*5,7*7,11*11)的卷積層的 AveragePooling2D 效果更好。另外,在每層前增加了大小為 1*1 的卷積層來降低維度,它類似于Inception 模塊。
更大的內核:更大的內核更容易從輸入圖像中提取更大范圍的特征(本身可以看作一個具有 8 個濾波器的激活層:每個部分的二進制掩碼基本上就是一個濾波器)。
信號整合:該模型只使用了一個非線性層對兩個特征集合:處理過的二進制掩碼(Signal#1)和成分數(Signal#2)。Signal#2 提高了交叉熵(將交叉熵從 0.8 提高到[0.7,0.72]))
Logits:在 TensorFlow 中,這是tf.nn.softmax_cross_entropy_with_logits計算 batch 損失的層。
步驟三:使用 t-SNE 對結果進行可視化處理
使用 t-SNE 算法對結果進行可視化處理,它是一種較為流行的數據可視化技術。t-SNE 最小化了低維嵌入數據點和原始高維數據(使用非凸損失函數)的聯合概率之間的 KL 散度。
為了將測試集的分類結果可視化,我導出了測試集圖像,提取了分類器的 logits 層,并將 t-SNE 算法應用于結果數據集。效果相當不錯,如下圖所示:
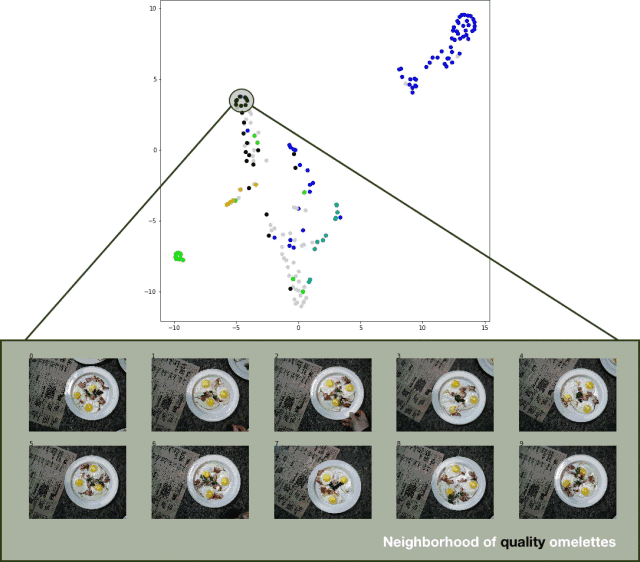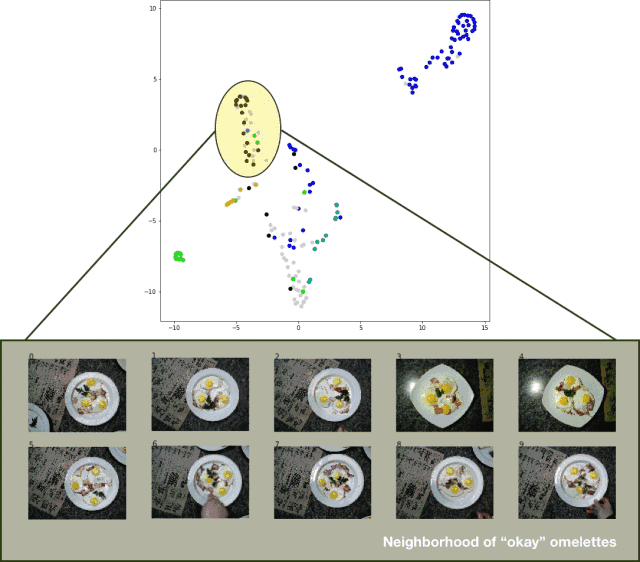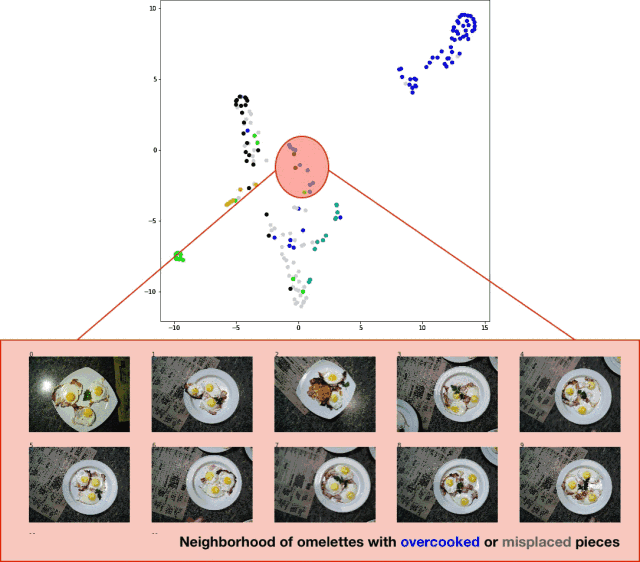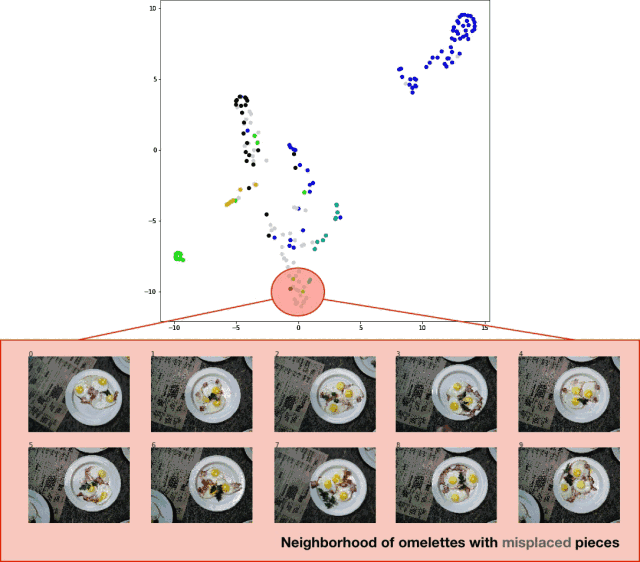
分類器測試集預測結果的 t-SNE 算法可視化效果
雖然結果并不是特別完美,但這種方法確實有效。 亟待改進的地方如下:
更多數據。卷積神經網絡需要大量的數據,而這里用于訓練的樣本只有 139 個,本文使用的數據增強技術特別好(使用 D4 或 dihedral, symmetry產生 2 千多張增強圖像)。但是,想要一個良好的性能,更多真實的數據尤為重要。
合適的損失函數。為了簡單起見,本文使用了分類交叉熵損失函數。也可以使用更合適的損失函數——三重損失函數(triplet loss),它能夠更好地利用類內差異。
更全面的分類器體系結構。當前的分類器基本上是一個原型模式,旨在解釋輸入二進制掩碼,并將多個特征集整合到單個推理管道。
更好的標簽。我在手動圖像標記(6 種類別的質量)方面的確不在行:分類器在十幾個測試集圖像上的表現超出了我的預期。
▌反思
在實際應用中,企業沒有數據、注釋,也沒有需要完成的明確任務,但這種現象非常普遍,這不可否認。這對你來說是一件好事:你要做的就是擁有工具和足夠多的 GPU 硬件、商業和技術知識、預訓練模型以及其他對企業有價值的東西。
從小事做起:一個可以用 LEGO 代碼塊構建的原型模式,可以進一步提高交流的效率——為企業提供這種方案,這是作為一位數據科學家的職責。
-
分類器
+關注
關注
0文章
152瀏覽量
13179 -
cnn
+關注
關注
3文章
352瀏覽量
22203 -
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11863 -
ROI
+關注
關注
0文章
14瀏覽量
6233
原文標題:雞蛋煎的好不好?Mask R-CNN幫你一鍵識別
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論