") 基于卷積神經(jīng)網(wǎng)絡(luò)的組合模型處理NLP任務(wù)諷刺檢測
基于卷積神經(jīng)網(wǎng)絡(luò)的組合模型處理NLP任務(wù)諷刺檢測
編者按:NTU研究人員Soujanya Poria等提出了一個組合模型,基于預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)提取情感、情緒、個性特征,以進(jìn)行諷刺檢測。NTHU PhD學(xué)生Elvis Saravia簡明扼要地總結(jié)了論文的主要思路。
概覽
這篇論文使用基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的組合模型處理NLP任務(wù)諷刺檢測(sarcasm detection)。諷刺檢測對情感檢測和情感分析等領(lǐng)域而言十分重要,因為這一表達(dá)將翻轉(zhuǎn)句子的極性。
例子
人們可以認(rèn)為諷刺用來挖苦或奚落。比如“是你還是我該吃藥了”、“我每周工作40小時才這么窮”。(examples.yourdictionary.com上有更多例子。)
挑戰(zhàn)
理解和檢測諷刺很重要的一點就是理解關(guān)于事件的事實。這讓我們可以檢測客觀極性(通常是負(fù)面的)和作者的諷刺特征(通常是正面的)之間的反差。
考慮以下例子,“我愛分手之苦”,很難從中提取檢測其中是否存在諷刺的知識。例子中的“我愛其苦”提供了作者表達(dá)的情感的知識(在這個例子中是正面的),而“分手”描述了一個相反的情感(負(fù)面)。
諷刺語句中的其他挑戰(zhàn)包括指代多個事件,以及提取大量事實、常識、指代解析、邏輯推理。論文的作者依靠CNN從諷刺語料庫中自動學(xué)習(xí)特征。
貢獻(xiàn)
將深度學(xué)習(xí)應(yīng)用于諷刺檢測
利用用戶簡介、情緒、情感特征進(jìn)行諷刺檢測
應(yīng)用預(yù)訓(xùn)練模型自動提取特征
模型
情感轉(zhuǎn)移(sentiment shifting)在牽涉諷刺的交流中很常見。因此,論文作者首先訓(xùn)練基于CNN訓(xùn)練一個情感模型學(xué)習(xí)情感特定的特征提取。模型在低層學(xué)習(xí)局部特征,之后在高層轉(zhuǎn)換為全局特征。作者發(fā)現(xiàn)諷刺表達(dá)和用戶相關(guān)——某些用戶比其他用戶發(fā)布更多諷刺性內(nèi)容。
作者提出的框架整合了基于用戶個性的特征,情感特征,基于情緒的特征。每組特征通過獨立的模型學(xué)習(xí),成為從數(shù)據(jù)集中提取諷刺相關(guān)特征的預(yù)訓(xùn)練模型。
CNN框架
CNN能夠有效地建模局部特征以學(xué)習(xí)更全局的特征,本質(zhì)上,這是在學(xué)習(xí)上下文(learn context)。句子使用詞向量(嵌入)表示(基于Google的word2vec向量)。使用了非靜態(tài)表示,因此,詞向量的參數(shù)在訓(xùn)練階段學(xué)習(xí)。接著,在特征映射上應(yīng)用最大池化,以生成特征。然后是softmax層及全連接層,以輸出最終預(yù)測。(見下圖)

為了得到其他特征——情感(S)、情緒(E)、個性(P)——預(yù)訓(xùn)練了CNN模型,并使用這些預(yù)訓(xùn)練模型從諷刺數(shù)據(jù)集中提取特征。訓(xùn)練每個模型使用了不同的訓(xùn)練數(shù)據(jù)集。(參考論文了解更多細(xì)節(jié))
測試了兩個分類器——一個CNN分類器(CNN)和一個SVM分類器(CNN-SVM,使用CNN提取的特征作為輸入)。
另外還訓(xùn)練了一個基線分類器(B)——僅僅使用CNN模型,沒有結(jié)合其他模型(情緒、情感等)。
試驗
數(shù)據(jù)為均衡和失衡的諷刺推文數(shù)據(jù)集,取自Ptacek等2014年的工作和The Sarcasm Detector。移除了用戶名、URL、#標(biāo)記,使用了NLTK Twitter Tokenizer。(參考論文了解更多細(xì)節(jié))
下表顯示了CNN和CNN-SVM分類器的表現(xiàn)。我們可以觀測到結(jié)合了諷刺特征、情感特征、情緒特征、個性特征的模型(特別是CNN-SVM)的表現(xiàn)超過了其他模型。
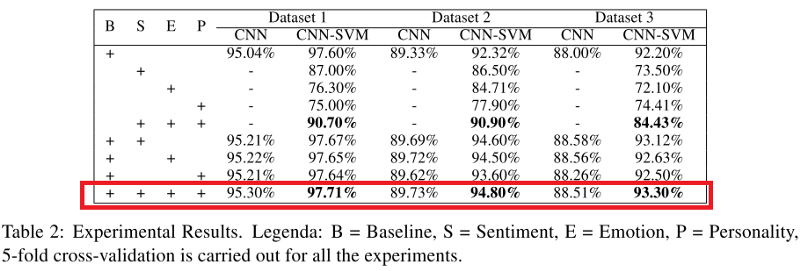
B = 基線,S = 情感,E = 情緒, P = 個性。所有試驗使用了五折交叉驗證
下表則是與當(dāng)前最先進(jìn)模型(第一行)和另一個知名的諷刺檢測模型(第二行)的比較。同樣,論文提出的模型的表現(xiàn)超過了其他模型。

D3 => D1意為在數(shù)據(jù)集3上訓(xùn)練,在數(shù)據(jù)集1上測試
論文測試了模型的概括能力,主要的發(fā)現(xiàn)是如果數(shù)據(jù)集本質(zhì)上很不相同,會顯著影響結(jié)果。(見下圖基于PCA可視化的數(shù)據(jù)集)。例如,在數(shù)據(jù)集1上訓(xùn)練,然后在數(shù)據(jù)集3上測試,模型的F1評分為33.05%.
結(jié)論
總體而言,論文作者發(fā)現(xiàn)諷刺高度依賴主題,并且高度上下文相關(guān)。因此,情感和其他上下文線索有助于從文本中檢測諷刺。使用預(yù)訓(xùn)練的情感、情緒、個性模型從文本中捕捉上下文信息。
手工構(gòu)造的特征(例如,n元語法),盡管某種程度上有助于諷刺檢測,會產(chǎn)生非常稀疏的特征向量表示。因此,使用詞嵌入作為輸入特征。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4774瀏覽量
100902 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24739 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5507瀏覽量
121298
原文標(biāo)題:基于深度卷積網(wǎng)絡(luò)進(jìn)行諷刺檢測
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論