 詳細分析網絡、存儲、RAM和緩存的融合
詳細分析網絡、存儲、RAM和緩存的融合
自文明的曙光乍現以來,磁盤驅動器和RAM(隨機存取存儲器)之間不堪的I/O關系一直是計算瓶頸。SSD(固態硬盤)的出現松緩但卻并沒有改變這一I/O瓶頸。有三項進展正在密謀將這個瓶頸推向CPU(中央處理器)。
首先,近十年,訪問速率和聯網速率分別登頂25Gb/s和58Gb/s,且在向100Gb/s逼近。計算機可以像訪問自己的磁盤一樣快地將數據從遠程系統移動到自己的磁盤上。其次,磁盤和RAM之間的I/O屏障即將消失;在這之后,RAM和緩存之間的障礙也就隨之土崩瓦解。
想象一下你所有的內容都在RAM硬盤中,但不僅僅在RAM中,還在L1緩存內。你可花不到2000美元買一臺帶64GB RAM的上好電腦,但想象一下艾字節(EB)大的緩存容量。這是個很大的數,只需5EB就可裝下人類所說過的所有話。來看下圖1中的圖表。
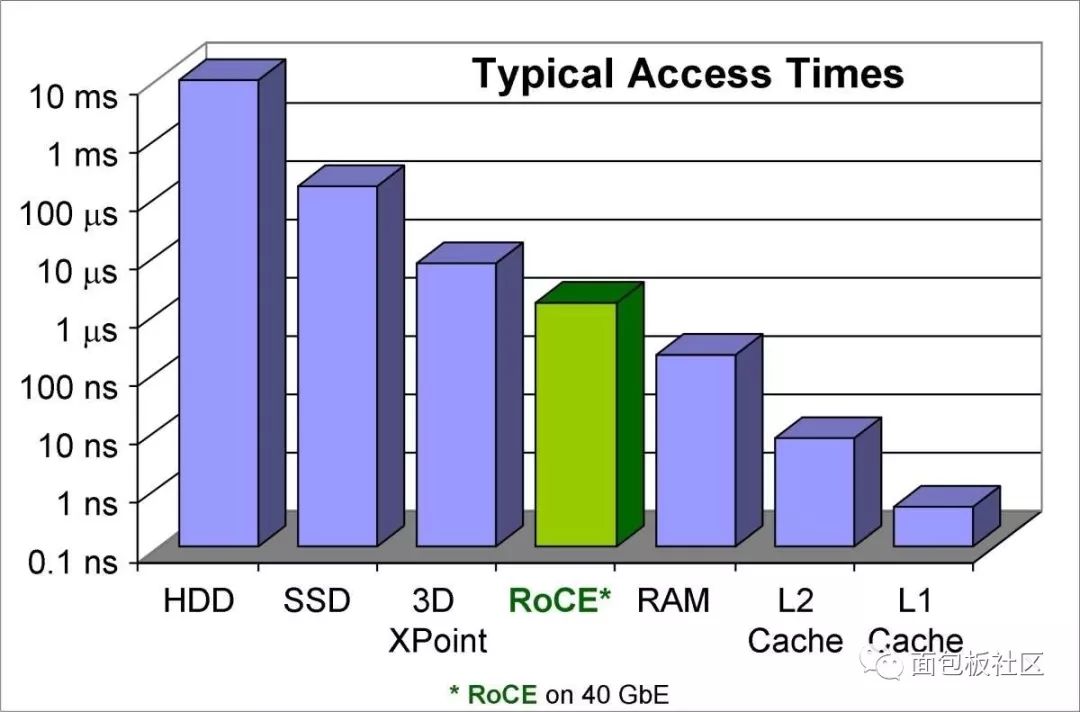
圖1:HDD(硬盤驅動器)、SSD、新型超高速存儲器、融合以太網上的RDMA(RoCE)、L2緩存和L1緩存的訪問時間。(圖片來自Infiniband 行業協會。)
硬盤和固態硬盤的磁盤訪問時間在左側,RAM和高速緩存訪問時間在右側。美光(Micron)公司的3D Xpoint NVM(非易失性存儲器)技術凸顯了這一趨勢:新的數據存儲技術在朝著RAM存取時間的方向發展。
綠色的RoCE(發音為“Rocky”)列是該難題的第二部分:將網絡上的許多NVM“磁盤”直接連接到RAM。 (我給“磁盤”加個引號,是因為固態硬盤與旋轉磁盤驅動器的差別就像手機上的按鍵與 “撥號盤”一樣大。)可以肯定的是,RoCE并不是唯一能夠實現這個的技術,它只是我所了解的一個。(免責聲明:我為Infiniband行業協會撰寫過一篇關于RoCE的白皮書《RoCE Accelerates Data Center Performance, Cost Efficiency, and Scalability(RoCE可加速數據中心的性能、成本效率和可擴展性)》;還有其他技術聲稱可以實現相同的奇跡,其中包括Infiniband本身和iWARP。)
RoCE是個復合縮寫詞——RDMA over converged Ethernet(融合以太網上的RDMA),其中RDMA代表遠程直接存儲器訪問。DMA(直接存儲器訪問)一直內置于個人電腦中。它使內部外圍器件(磁盤驅動器控制器、聲卡、圖形卡、網卡等)得以讀寫系統存儲器而不會麻煩到處理器。RDMA將DMA推廣到了網絡適配器,以便數據可以在不通過CPU或TCP/IP(傳輸控制協議)的主存儲器路徑的情況下,在不同服務器上的應用之間傳輸。也就是說,RDMA使網絡接口控制器(NIC)可以直接訪問RAM,從而繞過操作系統并且完全沒有TCP/IP開銷。
這一難題的另一個關鍵部分是新的NVM技術,如3D XPoint,它是由英特爾與美光合作開發的基于相變的固態NVM,速度會比閃存快1,000倍。該想法是在具有垂直線連接亞微觀柱體的三維設計中創建隨機存取技術——這些柱體的密度要比傳統存儲器高10倍。XPoint(crosspoint,交叉點)裸片(圖2)具有兩個層和一個交叉開關矩陣設計。NAND數據是按數kB的塊尋址的,而3D XPoint NVM可以逐字節尋址,延遲時間不超過7μs。由于XPoint芯片可以安裝在DIMM上——就在存儲器總線上,因此可以消除“磁盤”與RAM之間的差異。
圖2:3D Xpoint設計使用堆疊裸片來增加密度。
當3D XPoint和其他新的持久性存儲器技術(如3D Super-NOR)將RAM存儲器與我們所認為的磁盤存儲技術結合在一起時,一切都會改變。在3D XPoint等技術實現其承諾的同時,RoCE將在400Gb/s網絡上運行,到那時,磁盤和RAM之間的區別將不復存在。
我們將不再遵循從遠程磁盤到本地磁盤、到RAM、到緩存、再到數據處理的供應鏈,而是直接從“磁盤”到數據處理。我們不僅會將“磁盤”視作甚至比“撥號盤”更過時,而且隨著全球的數據都高效存儲在RAM中,數據處理將不再受主板和物理位置所限制。本地和云計算之間的區別將會消失,光速將成為設備可做可為的決定性因素,而CPU本身會成為處理瓶頸,摩爾定律也將繼續起支配作用。
-
存儲
+關注
關注
13文章
4320瀏覽量
85897 -
RAM
+關注
關注
8文章
1368瀏覽量
114751 -
網絡
+關注
關注
14文章
7571瀏覽量
88865 -
緩存
+關注
關注
1文章
240瀏覽量
26693
原文標題:探討網絡、存儲、RAM和緩存的融合
文章出處:【微信號:gh_bee81f890fc1,微信公眾號:面包板社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
緩存對大數據處理的影響分析
Web緩存的類型及功能分析
什么是緩存(Cache)及其作用
美國站群vps云服務器缺點詳細分析
ram存儲的數據在斷電后會丟失嗎
外部存儲器是ROM還是RAM
存儲芯片和邏輯芯片的差異

NMOS LDO原理概括 NMOS LDO原理詳細分析

鴻蒙原生應用元服務開發WEB-緩存與存儲管理
矢量網絡分析儀的常見故障和原因分析
ram內部存儲器電路組成
ram中存儲的數據在斷電后是否會丟失?
詳細分析算力網絡的發展






 工商網監
工商網監
評論