") LSTM的核心構(gòu)成,實(shí)際中“門”的效果如何?
LSTM的核心構(gòu)成,實(shí)際中“門”的效果如何?
長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)是序列建模中被廣泛使用的循環(huán)結(jié)構(gòu),LSTM利用門結(jié)構(gòu)來(lái)控制模型中信息的傳輸量。但在實(shí)際操作中,LSTM中的門通常都處于“半開(kāi)半關(guān)”的狀態(tài),沒(méi)有有效地控制信息的記憶與遺忘。為此,微軟亞洲研究院機(jī)器學(xué)習(xí)組提出了一種新的LSTM訓(xùn)練方法,讓模型的門接近“二值化”——0或1,可以更準(zhǔn)確地去除或者增加信息,進(jìn)而提高模型的準(zhǔn)確性、壓縮比以及可解釋性。
在很多實(shí)際場(chǎng)景中,深度學(xué)習(xí)模型都要面臨輸入長(zhǎng)度不固定或者說(shuō)輸入變長(zhǎng)(variable-length input)的問(wèn)題:例如在文本判別中,我們需要判斷一個(gè)句子的語(yǔ)義是積極還是消極的,這里輸入句子的長(zhǎng)度是多種多樣的;在時(shí)間序列預(yù)測(cè)問(wèn)題中,我們需要根據(jù)歷史上信息的變化預(yù)測(cè)當(dāng)前的數(shù)值,而歷史信息的長(zhǎng)度在不同時(shí)間點(diǎn)也是不同的。
普通的神經(jīng)網(wǎng)絡(luò)模型,比如卷積神經(jīng)網(wǎng)絡(luò)(CNN),無(wú)法解決此類輸入變長(zhǎng)的問(wèn)題。為此,人們首先提出了循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network),簡(jiǎn)稱RNN。循環(huán)神經(jīng)網(wǎng)絡(luò)的核心是通過(guò)循環(huán)的方式,將歷史信息和當(dāng)前信息不斷整合。例如,當(dāng)你看美劇第N集時(shí),需要通過(guò)對(duì)前N-1集的劇情的理解(記憶),以及當(dāng)前這一集的劇情(當(dāng)前輸入),更新自己對(duì)這部劇的理解。
在深度學(xué)習(xí)早期,RNN結(jié)構(gòu)在很多應(yīng)用中取得了成功,但同時(shí),這個(gè)簡(jiǎn)單模型的瓶頸也不斷顯現(xiàn),這不僅涉及到優(yōu)化本身(如梯度爆炸、梯度消失)的問(wèn)題,還有模型的復(fù)雜度的問(wèn)題。例如一句話“小張已經(jīng)吃過(guò)飯了,小李呢?”,這句話是在詢問(wèn)“小李是否吃過(guò)飯”,但在RNN看來(lái),信息是從左到右不斷流入的,所以最后很難分清到底是在問(wèn)小張是否過(guò)飯,還是在問(wèn)小李是否吃過(guò)飯。于是帶有遺忘機(jī)制的新結(jié)構(gòu)就誕生了——長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(Long Short Term Memory Network,LSTM)。
LSTM是由Hochreiter & Schmidhuber在1997年提出的RNN的一種特殊類型,可以學(xué)習(xí)長(zhǎng)期依賴(long-term dependency)信息。在很多自然語(yǔ)言處理問(wèn)題以及增強(qiáng)學(xué)習(xí)問(wèn)題中,LSTM都取得相當(dāng)巨大的成功,并得到了廣泛的使用。
LSTM的核心構(gòu)成
LSTM的關(guān)鍵構(gòu)成是一種被稱作“門”的結(jié)構(gòu),LSTM通過(guò)精心設(shè)計(jì)的門結(jié)構(gòu)去除或者增加信息。門是一種讓信息選擇通過(guò)的方法。一般情況下,在一個(gè)維度上,一個(gè)門是一個(gè)輸出范圍在0到1之間的數(shù)值,用來(lái)描述這個(gè)維度上的信息有多少量可以通過(guò)這個(gè)門——0代表“不許任何量通過(guò)”,1代表“全部通過(guò)”。
LSTM擁有三類門,分別是輸入門、輸出門、和遺忘門。
首先,LSTM需要通過(guò)遺忘門決定應(yīng)該從歷史中丟棄什么信息。在每一維度,遺忘門會(huì)讀取歷史信息和當(dāng)前信息,輸出一個(gè)在0到1之間的數(shù)值,1表示該維度所攜帶的歷史信息“完全保留”,0表示該維度所攜帶的歷史信息“完全舍棄”。例如在前面的例子中,當(dāng)我們讀到“小張已經(jīng)吃過(guò)飯了,小李呢?”時(shí),我們會(huì)把“主語(yǔ)”信息中的小張忘掉,這個(gè)操作就是通過(guò)遺忘門實(shí)現(xiàn)的。
然后,要確定需要把什么新信息存放在當(dāng)前內(nèi)容中,例如前面的例子中,我們把小張“忘掉”后,需要把主語(yǔ)信息換成小李,這個(gè)“增加”操作是通過(guò)輸入門實(shí)現(xiàn)的。而對(duì)于不同任務(wù)而言,我們需要將當(dāng)前信息整理輸出以方便做決策,這個(gè)整理輸出信息的過(guò)程,是通過(guò)輸出門實(shí)現(xiàn)的。LSTM如下圖右所示。
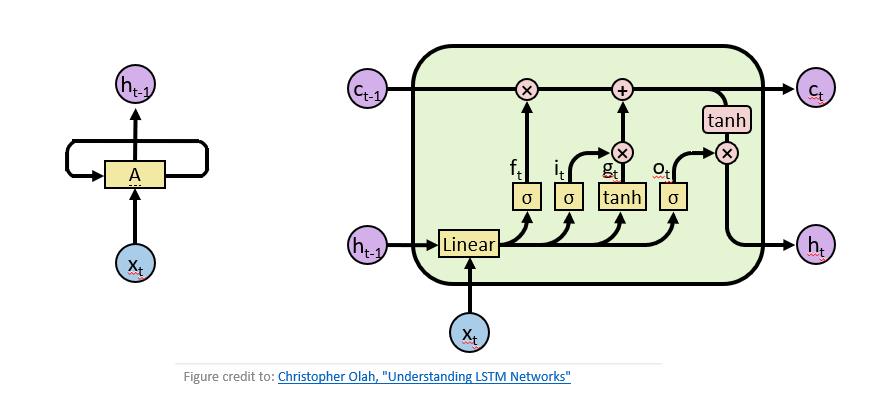
圖1 左:經(jīng)典循環(huán)神經(jīng)網(wǎng)絡(luò),右:長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)
在實(shí)際操作中,門是通過(guò)激活函數(shù)實(shí)現(xiàn)的:給定一個(gè)輸入值x,通過(guò)sigmoid變換,可以的到一個(gè)值域在[0,1]之間的值,若x大于0,則輸出值大于0.5,若x小于0,則輸出值小于0.5。
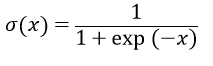
實(shí)際中“門”的效果如何?
門是否真的具有我們上述描述的意義呢?這也是我們這篇論文的出發(fā)點(diǎn)。為了探究這個(gè)問(wèn)題,我們分析了IWSLT14德語(yǔ)-英語(yǔ)的翻譯任務(wù),這個(gè)翻譯任務(wù)的模型是基于LSTM的端到端(sequence-to-sequence)結(jié)構(gòu)。
我們?cè)谟?xùn)練集中隨機(jī)抽取10000對(duì)平行語(yǔ)料,畫出在這些語(yǔ)料上LSTM輸入門與遺忘門的取值分布直方圖,如下圖所示。
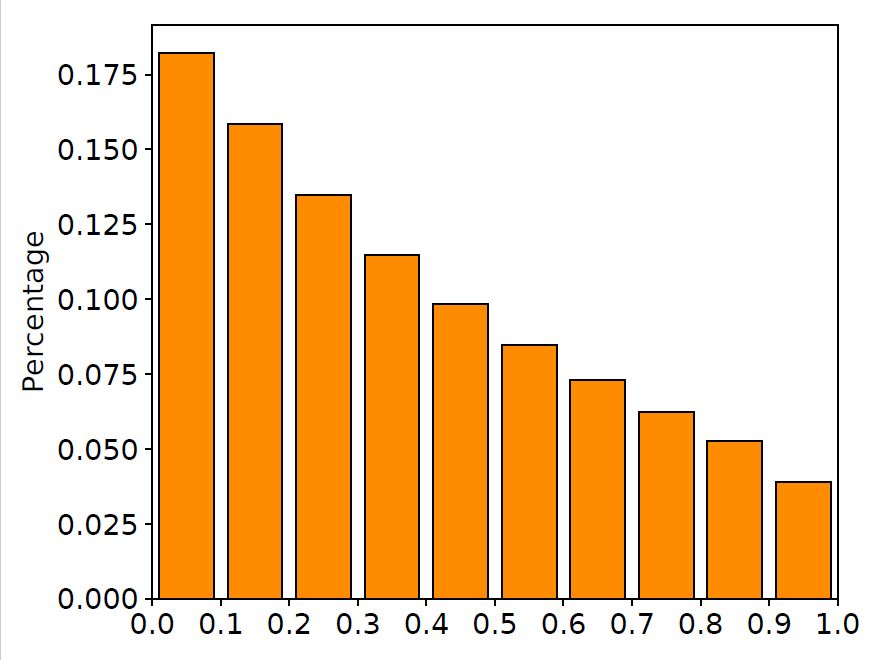
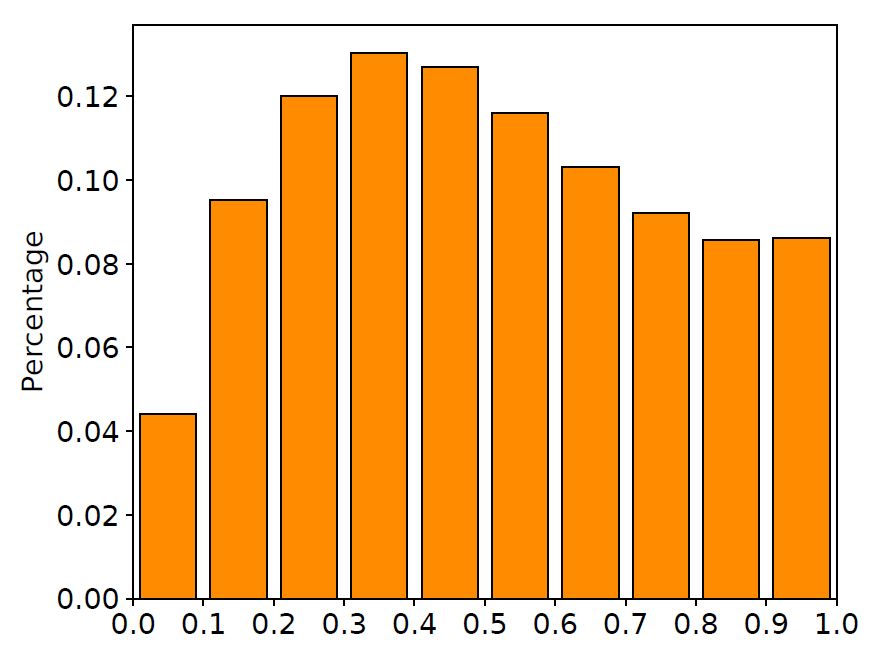
圖2 輸入門與遺忘門取值分布
從圖中可以清晰地看到,很大一部分門的取值都在0.5附近。換句話說(shuō),LSTM中的門都處于一種模棱兩可的“半開(kāi)半關(guān)”的狀態(tài)。這種現(xiàn)象與LSTM網(wǎng)絡(luò)的設(shè)計(jì)有所出入:這些門并沒(méi)有顯式地控制信息的記憶與遺忘,而是以某種方式“記住”了所有的信息。與此同時(shí),許多工作也指出LSTM中的大部分門都很難找到實(shí)際意義,這也進(jìn)一步印證了我們的發(fā)現(xiàn)(相關(guān)討論詳見(jiàn)文末論文)。
“二值化”的門結(jié)構(gòu)
從上面的例子中可以看到,雖然LSTM在翻譯任務(wù)中取得了很好的效果,但是門并沒(méi)有想象中的明顯作用。同時(shí)也有一些前人的工作指出:LSTM的絕大多數(shù)維度并沒(méi)有明顯的可解釋信息。那么如何能夠?qū)W到一個(gè)更好的LSTM呢?這個(gè)問(wèn)題引領(lǐng)我們?nèi)ネ诰蜷T結(jié)構(gòu)更大的價(jià)值:既然門是一個(gè)開(kāi)關(guān)的概念,那么有沒(méi)有可能學(xué)習(xí)出一個(gè)接近“二值化”(binary-valued)的LSTM呢?一個(gè)接近“二值化”的門(binary-valued gate)有以下幾點(diǎn)好處:
1.門的作用更加符合真實(shí)意義下門的概念:通常意義下,門其實(shí)更多的是指其“開(kāi)”、“關(guān)”兩種狀態(tài)。而我們?nèi)W(xué)習(xí)一個(gè)接近“二值化”的門的目的,也與LSTM的核心思想非常一致。
2. “二值化”更適合模型壓縮:如果門的值非常接近0或者1,說(shuō)明sigmoid函數(shù)的輸入值x是個(gè)很大的正數(shù),或者很小的負(fù)數(shù)。這時(shí)輸入值x的微小改變對(duì)輸出值影響甚微,由于輸入值x通常也是參數(shù)化的,所以“二值化”可以方便對(duì)于這部分參數(shù)的壓縮。通過(guò)實(shí)驗(yàn)我們發(fā)現(xiàn),即使達(dá)到很大的壓縮比,我們的模型仍然有很好的效果。
3. “二值化”帶來(lái)更好的可解釋性:要求門的輸出值接近0或1,會(huì)對(duì)模型本身有更高的要求。在信息取舍的過(guò)程中,某個(gè)節(jié)點(diǎn)保留或者遺忘掉該維度全部信息。我們認(rèn)為這種學(xué)習(xí)得到的門更能體現(xiàn)自然語(yǔ)言的結(jié)構(gòu)、內(nèi)容以及內(nèi)部邏輯,如前面提到的關(guān)于吃飯的例子。
如何讓訓(xùn)練后的模型的門接近二值化?我們借鑒了ICLR17上關(guān)于變分法(variantional method)的一個(gè)新進(jìn)展:Categorical Reparameterization with Gumbel-Softmax。簡(jiǎn)單而言,將門的輸出“二值化”的最好辦法是訓(xùn)練一個(gè)隨機(jī)神經(jīng)網(wǎng)絡(luò)(stochastic neural network),其中門的輸出是一個(gè)概率p,在伯努利分布中得到0/1的隨機(jī)采樣,借此去得到不同位置取0/1時(shí)的損失,進(jìn)而優(yōu)化參數(shù)得到最優(yōu)p。而在隱層節(jié)點(diǎn)上進(jìn)行離散操作時(shí),梯度回傳遇到問(wèn)題,我們采用的方法就是用Gumbel-Softmax Estimator近似多項(xiàng)分布的概率密度函數(shù),進(jìn)而達(dá)到既可學(xué)習(xí)又方便優(yōu)化的目的(具體方法見(jiàn)文末論文)。我們將這一方法命名為Gumbel-Gate LSTM,簡(jiǎn)稱G2-LSTM。
準(zhǔn)確率、可壓縮性與可解釋性
我們?cè)贚STM網(wǎng)絡(luò)的兩個(gè)經(jīng)典應(yīng)用——語(yǔ)言模型和機(jī)器翻譯上測(cè)試了這一方法,在準(zhǔn)確率、可壓縮性與可解釋性三方面與之前的LSTM模型進(jìn)行比較。
準(zhǔn)確率
語(yǔ)言模型是LSTM網(wǎng)絡(luò)最基本的應(yīng)用之一。語(yǔ)言模型要求LSTM網(wǎng)絡(luò)根據(jù)一句話當(dāng)中之前已知的詞語(yǔ)準(zhǔn)確預(yù)測(cè)下一個(gè)詞的選取。我們使用廣泛使用的Penn Treebank數(shù)據(jù)集作為訓(xùn)練語(yǔ)料,該訓(xùn)練集總共包含約一百萬(wàn)個(gè)詞。語(yǔ)言模型一般使用perplexity作為評(píng)價(jià)指標(biāo),perplexity越小說(shuō)明模型越精準(zhǔn),實(shí)驗(yàn)結(jié)果如下圖所示。
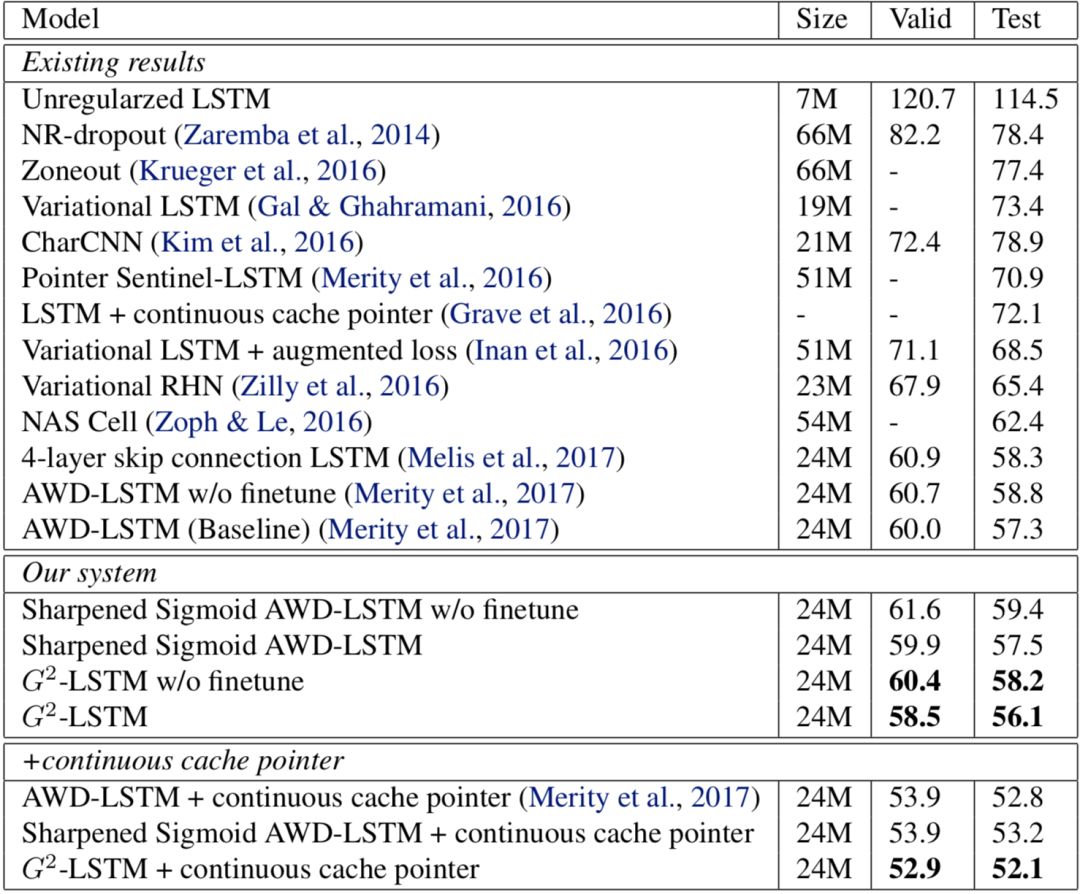
圖3語(yǔ)言模型實(shí)驗(yàn)結(jié)果
從圖中可以看到,通過(guò)將LSTM中的門進(jìn)行“二值化”,模型的表現(xiàn)有所提升:我們模型的perplexity為56.1,與基線模型的perplexity57.3相比,有1.2的提升。而在加入了測(cè)試時(shí)后處理(continuous cache pointer)的情況下,我們的模型達(dá)到了52.1,較基線模型的52.8有0.7的提升。
機(jī)器翻譯是目前深度學(xué)習(xí)應(yīng)用最為成功的領(lǐng)域之一,而基于LSTM的端到端(sequence-to-sequence)結(jié)構(gòu)是機(jī)器翻譯中被廣泛應(yīng)用的結(jié)構(gòu)。我們?cè)趦蓚€(gè)公開(kāi)數(shù)據(jù)集:IWSLT14德語(yǔ)到英語(yǔ)數(shù)據(jù)集和WMT14英語(yǔ)到德語(yǔ)數(shù)據(jù)集上測(cè)試了我們的方法。IWSLT14德英數(shù)據(jù)集包含約15萬(wàn)句平行語(yǔ)料,WMT14英德數(shù)據(jù)集包含約450萬(wàn)句平行語(yǔ)料。對(duì)于IWSLT14德英數(shù)據(jù)集,我們使用了兩層編碼器-解碼器(encoder-decoder)結(jié)構(gòu);而由于WMT14英德數(shù)據(jù)集大小更大,我們使用了更大的三層編碼器-解碼器結(jié)構(gòu)。機(jī)器翻譯任務(wù)一般由測(cè)試集上的BLEU值作為最后的評(píng)價(jià)標(biāo)準(zhǔn),BLEU值越高說(shuō)明翻譯質(zhì)量越高,機(jī)器翻譯的實(shí)驗(yàn)結(jié)果下圖所示。
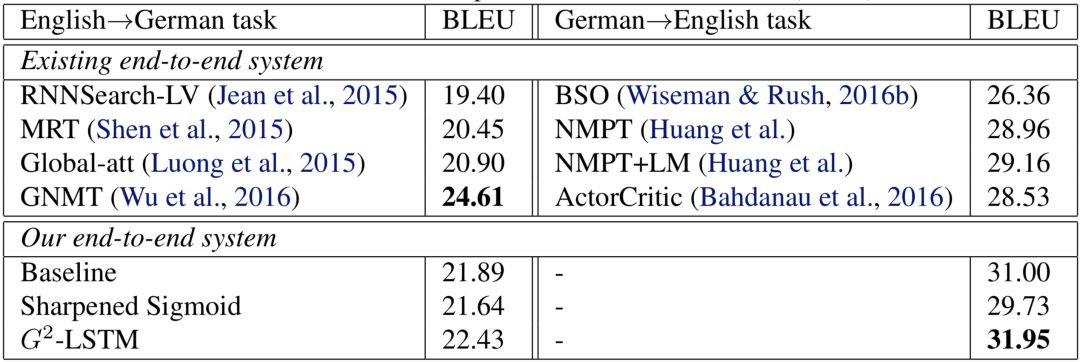
圖4機(jī)器翻譯實(shí)驗(yàn)結(jié)果
與語(yǔ)言模型的實(shí)驗(yàn)結(jié)論類似,我們的模型在機(jī)器翻譯上的表現(xiàn)同樣有所提升:在IWSLT14德英數(shù)據(jù)集上,我們模型的BLEU值達(dá)到了31.95,比基線模型高0.95;而在WMT14德英數(shù)據(jù)集上,我們模型的BLEU值為22.43,比基線模型高0.54。
可壓縮性
將模型進(jìn)行“二值化”能夠使得我們的模型對(duì)于參數(shù)的擾動(dòng)更加魯棒。因此,我們比較了不同模型在參數(shù)壓縮下的性能。我們采用了兩種方式對(duì)與門相關(guān)的參數(shù)進(jìn)行壓縮:
精度壓縮。我們首先限制了參數(shù)的精度(使用round函數(shù)),例如當(dāng)公式中的r取0.1時(shí),所有的模型參數(shù)都僅被保留一位小數(shù)精度。在這之后,我們進(jìn)一步控制了參數(shù)取值的范圍(使用clip函數(shù)),將所有取值大于c的參數(shù)都變?yōu)閏,將所有取值小于-c的參數(shù)都變?yōu)?c。由于兩個(gè)任務(wù)的參數(shù)取值范圍不太相同,在語(yǔ)言模型上,我們?cè)O(shè)置r=0.2,c=0.4;在機(jī)器翻譯上,我們?cè)O(shè)置r=0.5,c=1.0。這使得所有的參數(shù)最終將只能取5個(gè)值
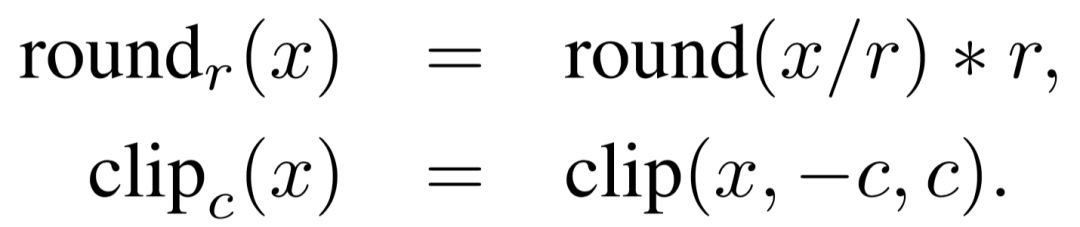
低秩壓縮。我們利用奇異值分解(singular value decomposition),將參數(shù)矩陣分解為兩個(gè)低秩矩陣的乘積,這能夠顯著減少模型大小,并且能夠加快矩陣乘法,從而提高模型運(yùn)行速度。
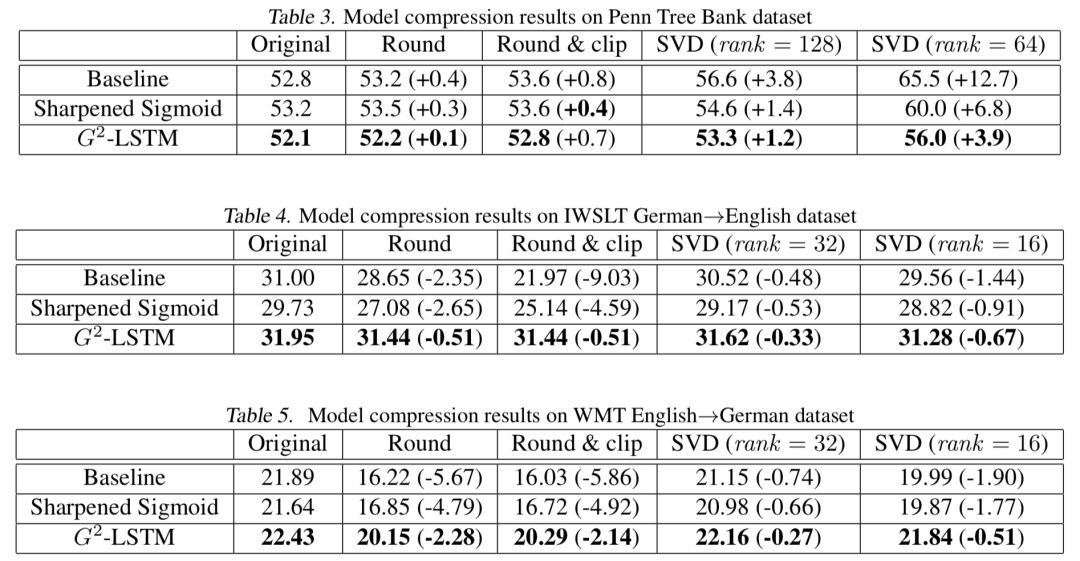
圖5壓縮后實(shí)驗(yàn)結(jié)果
具體的實(shí)驗(yàn)結(jié)果如上圖所示。我們可以看到,不論在哪種情況下,我們的模型都顯著優(yōu)于壓縮后的模型,這說(shuō)明這一模型的魯棒性較之前的LSTM有大幅度的提升。
可解釋性
除了比較數(shù)值實(shí)驗(yàn)結(jié)果外,我們進(jìn)一步地觀察了模型中門的取值,用同樣的語(yǔ)料畫出了我們的模型中門的取值分布直方圖,如下圖所示。
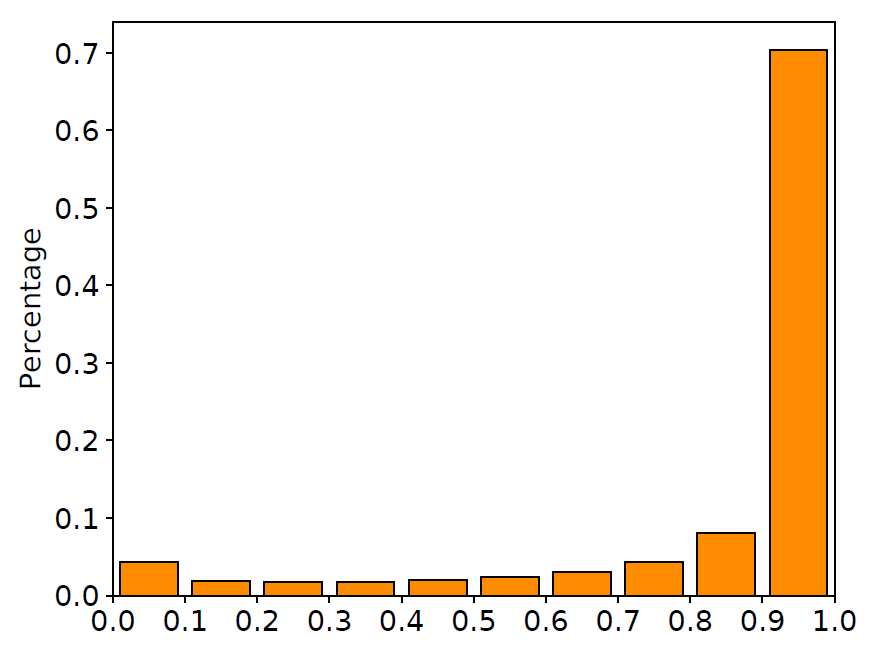
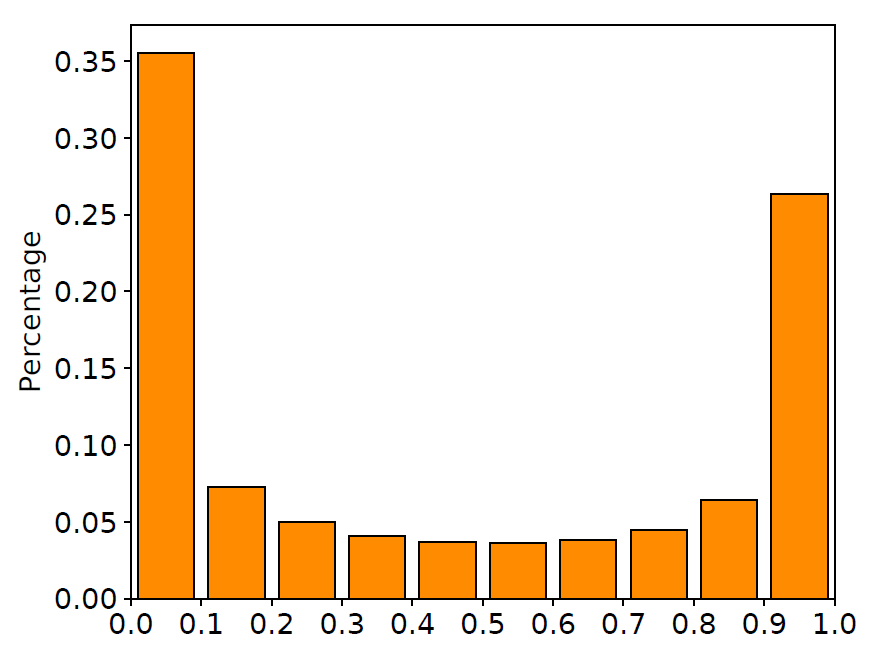
圖6 輸入門與遺忘門取值分布
從圖中我們可以看到,大部分輸入門的取值都在1.0附近,這意味著我們的模型接受了大部分的輸入信息;而遺忘門的取值都集中在0.0或1.0附近,這意味著我們訓(xùn)練后得到的遺忘門確實(shí)做到了選擇性地記憶/遺忘信息。這些觀察都證明了我們的訓(xùn)練算法確實(shí)能夠讓門的取值更加靠近0/1兩端。
除了觀察網(wǎng)絡(luò)中門的取值在數(shù)據(jù)集上的分布情況,我們還在訓(xùn)練集中隨機(jī)抽取的幾條句子上觀察了每個(gè)時(shí)刻門的平均取值,如下圖所示。
圖7樣例分析
從圖中我們可以看到,傳統(tǒng)LSTM網(wǎng)絡(luò)的輸入門取值較為平均,并且對(duì)于一些有意義的詞(例如“wrong”),傳統(tǒng)LSTM的平均輸入門取值都較小,這很不利于模型獲取關(guān)于這個(gè)詞的信息,最終將使模型產(chǎn)生不好的翻譯效果。而在我們的模型中,輸入門的取值都很大,這意味著大部分詞的信息都被LSTM網(wǎng)絡(luò)接受。另一方面,在我們提出的模型中,遺忘門取值較小的詞都是一些功能詞,例如連詞(“and”)或標(biāo)點(diǎn)符號(hào),這說(shuō)明我們的模型能夠正確判斷句子的邊界,來(lái)清空模型的之前的記憶,來(lái)獲取新的信息。
了解更多細(xì)節(jié),請(qǐng)?jiān)L問(wèn)下面鏈接或點(diǎn)擊閱讀原文訪問(wèn)我們的論文:
Zhuohan Li, Di He, Fei Tian, Wei Chen, Tao Qin,Liwei Wang, and Tie-Yan Liu. "Towards Binary-Valued Gates for Robust LSTM Training."ICML 2018.
論文鏈接:https://arxiv.org/abs/1806.02988
作者簡(jiǎn)介:
李卓翰,北京大學(xué)信息科學(xué)技術(shù)學(xué)院2015級(jí)本科生,在微軟亞洲研究院機(jī)器學(xué)習(xí)組實(shí)習(xí)。主要研究方向?yàn)闄C(jī)器學(xué)習(xí)。主要關(guān)注深度學(xué)習(xí)算法設(shè)計(jì),及其在不同任務(wù)場(chǎng)景下的應(yīng)用。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4771瀏覽量
100720 -
機(jī)器翻譯
+關(guān)注
關(guān)注
0文章
139瀏覽量
14880 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
288瀏覽量
13347
原文標(biāo)題:ICML 2018 | 訓(xùn)練可解釋、可壓縮、高準(zhǔn)確率的LSTM
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何實(shí)現(xiàn)在圖標(biāo)圖像中實(shí)現(xiàn)一個(gè)點(diǎn),效果如下圖
LabVIEW中圖像濾波Vi以及實(shí)現(xiàn)效果如何實(shí)現(xiàn)
當(dāng)無(wú)凸輪軸發(fā)動(dòng)機(jī)真的裝在車上時(shí),究竟實(shí)際效果如何?
i9-9900K開(kāi)蓋 使用了釬焊散熱后實(shí)際效果如何
一種具有強(qiáng)記憶力的 E3D-LSTM網(wǎng)絡(luò),強(qiáng)化了LSTM的長(zhǎng)時(shí)記憶能力

EE-26:AD184x Sigma Delta轉(zhuǎn)換器:它們使用直流輸入的效果如何?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論