 身體的運動可以通過音樂信號進行計算預測嗎?
身體的運動可以通過音樂信號進行計算預測嗎?
根據音樂信號預測身體的運動是一個極具挑戰性的計算問題。來自Facebook、斯坦福大學和華盛頓大學的研究人員開發了一種基于深度學習的方法,該方法可以將樂器的聲音轉換成對骨骼關鍵點的預測,并可以用于制作動畫角色。
鋼琴家在彈奏鋼琴曲時,他們的身體會對音樂產生反應。他們的手指在琴鍵上敲擊,他們揮動手臂在不同的八度音階上演奏。小提琴演奏者用一只手在琴弦上拉弓,另一只手的手指輕觸或撥動琴弦。弓法越快,產生音樂節奏也越快。
一個有趣的問題是:身體的運動可以通過音樂信號進行計算預測嗎?這是一個極具挑戰性的計算問題。我們需要有一套很好的訓練視頻,需要能夠準確地預測這些視頻中的身體姿勢,然后建立一個能夠找到音樂和身體之間的相關性的算法,以進一步預測運動。
來自Facebook、斯坦福大學和華盛頓大學的研究人員開發了一種基于深度學習的方法,該方法可以將樂器的聲音轉換成對骨骼關鍵點的預測,并可以用于制作動畫角色。
受唇語預測和視頻對象檢測啟發
人體動力學是很復雜的,尤其是考慮到學習音頻相關性所需要的質量。傳統上,通過視頻序列(而不是音頻)來預測人體自然運動的最優方法是采用實驗室狀態下拍攝的動作捕捉序列。在我們的場景中,我們需要帶一位鋼琴家到實驗室,在他們的手指和身體關節處安裝傳感器,然后請他們演奏幾個小時。
這種方法在實踐中很難執行,也不容易推廣。如果我們能夠利用優秀鋼琴家演奏的公開視頻,我們就有可能在數據上實現更高程度的多樣性。但直到最近,從視頻中準確地估計身體姿勢才成為可能。今年出現了幾種方法,可以讓我們從“自然狀態下”的數據中學習。
此外,有一些方法顯示出預測唇語的顯著結果。也就是說,給定一個人說話的音頻,他們可以預測出這個人說話時嘴唇的運動。
這兩個方向取得的進步啟發了我們,我們試圖去解決僅僅從音樂中預測身體和手指運動的挑戰。這篇論文的目標是探索是否有可能,以及我們是否能從音頻中創造出自然和符合邏輯的身體運動。注意,我們沒有使用MIDI文件之類的信息,而是試圖了解鋼琴琴鍵和音樂之間的關系。我們專注于創造一個能像鋼琴家那樣運動他的手和手指的角色(avatar)。
我們考慮了兩組數據,鋼琴和小提琴獨奏(如圖3)。我們分別收集了這兩類音樂的視頻,通過視頻每一幀里的上半身和手指來處理視頻。每一幀共50個關鍵點,其中21個點表示每只手的手指,8個點表示上半身。
圖3:訓練數據
除了預測點之外,我們的另一個目標是通過動畫形象的方式來可視化這些點,讓動畫人物根據給定的音頻輸入自主活動。為了解決這個問題,我們提出兩個步驟。首先,構建一個長短期記憶(LSTM)網絡,學習音頻特征和身體骨架界標(body skeleton landmarks)之間的相關性。其次,我們使用預測的landmark自動給一個動畫形象賦予生命。最后的輸出是能根據音頻輸入活動的動畫人物。
關鍵點估計
我們對兩種關鍵點感興趣:身體和手指。通常情況下,由于相機、燈光和快速運動產生的巨大變化,在自然的視頻中估計關鍵點的估計是具有挑戰性的。不過,最近出現了許多方法可以更好地處理自然的視頻。
我們獲取相對精確的關鍵點的過程如下:
我們首先通過三個庫來運行視頻:提供臉部、身體和手的關鍵點的OpenPose,MaskRCNN,以及人臉識別算法DeepFace。這三個庫在基準測試上表現很好,但是在我們的視頻中,它們在某些幀上會失敗。
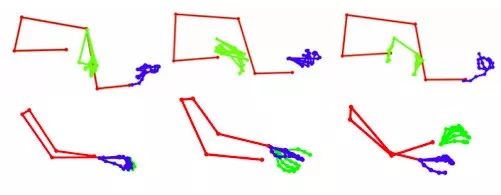
圖4:在預處理步驟中自動刪除的關鍵點檢測器的失敗案例
從音頻到身體關鍵點的預測
我們的目標是學習音頻特征和身體運動之間的關聯性。為此,我們構建了一個LSTM(長短期記憶)網絡。架構如圖5所示:
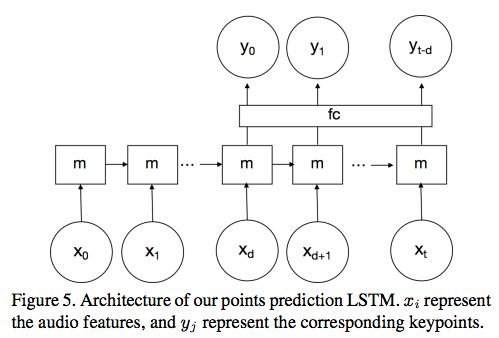
圖5:關鍵點預測LSTM的架構。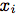 表示音頻特征,
表示音頻特征,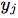 表示相應的關鍵點。
表示相應的關鍵點。
我們選擇使用具有時間延遲的單向的單層LSTM。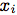 表示在特定時間i的音頻MFCC,
表示在特定時間i的音頻MFCC,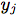 表示身體關鍵點的PCA系數,m表示memory。我們還添加了一個完全連接層“fc”,發現它可以提高性能。
表示身體關鍵點的PCA系數,m表示memory。我們還添加了一個完全連接層“fc”,發現它可以提高性能。
我們進行了300 epochs的訓練。該網絡在Caffe2上實現,并使用ADAM優化器。輸入和輸出都是通過減去平均值并除以方差而歸一化的。
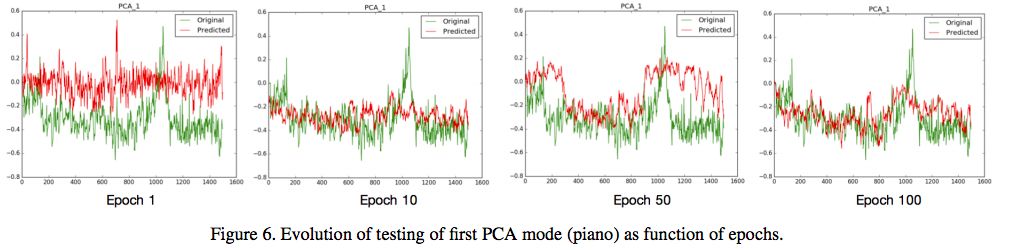
圖6:第一個PCA mode(piano)
從身體關鍵點到動畫形象
當身體的關鍵點預估出來后,我們用一個動畫形象來使用這些點。我們使用ARkit構建了一個增強現實應用程序,它可以在手機上實時運行。給定一系列2D預測點和身體的動畫化身,動作便被應用到化身上。我們使用的化身是帶有人體骨骼裝置的3D人體模型。
實驗
評估:
我們在網絡中嘗試了不同的參數選擇,并在表1和表2中提供了比較。為了找到最優參數,我們進行了超參數搜索。表中的誤差以像素表示,越低越好。
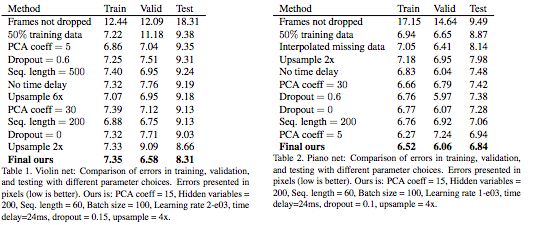
為了獲得好的結果,過濾掉訓練數據中的所有糟糕的幀(錯誤的骨架、錯誤的人體檢測、錯誤的人體識別)是很重要的。可以看到,只要過濾掉壞數據,誤差就會顯著減少。
通過使用較少的PCA系數,可以更好地適應訓練數據,但測試誤差大于使用較多的系數。在我們的案例中,使用dropout并不能改善結果。時間延遲有助于改善結果。
結果:
圖8和圖9給出了有代表性的結果。我們展示了不同身體姿勢的預測關鍵點,以及上下文的原始框架。對于關鍵點,我們將它們疊加在groud truth點上進行視覺對比。注意,我們并不期望這些點能完全一致,但是手指和手可以產生類似的令人滿意的運動,這是本文的目標。
圖8
圖9
在我們的案例中,groud truth是2D身體姿勢檢測器的結果,這可能是錯誤的。最后,我們在圖12中展示了失敗案例,第一行是鋼琴的,第二行是小提琴的。這些失敗案例表明我們的系統有局限性:目前我們的系統是訓練2D的姿勢,而訓練視頻中的實際姿勢是3D的。因此,被遮擋和看不見的點不能很好地預測。在視頻的高速度和高頻率部分,身體姿態檢測器可能會產生錯誤,運動模糊也是如此。
-
人臉識別
+關注
關注
76文章
4015瀏覽量
82171 -
增強現實
+關注
關注
1文章
712瀏覽量
45021 -
深度學習
+關注
關注
73文章
5512瀏覽量
121415
原文標題:神“樂”馬良:AI直接將音頻轉換成動畫
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何通過仿真準確的預測信號完整性

Xsens攜手ST展示3D身體運動跟蹤系統
支持 BLE 連接的接觸式身體成分測量儀參考設計
夏天運動不孤單,我有三星iconx運動私教
智能手環是如何收集身體數據的和相關工作原理
身體運動傳感器技術需求
身體運動傳感器
【HarmonyOS HiSpark AI Camera】運動身體姿態分析
榮耀智能體脂秤2評測 什么是身體運動智能

運動聽音樂用什么耳機、適合運動聽歌使用的運動耳機推薦

通過生物信號采集處理系統來分析胃腸運動





 工商網監
工商網監
評論