 一種稱為標簽映射(LM)的方法來解決大規模分類問題?
一種稱為標簽映射(LM)的方法來解決大規模分類問題?
近年來,深度學習已成為機器學習社區的一個主要研究領域。其中一個主要挑戰是這種深層網絡模型的結構通常很復雜。對于一般的多類別分類任務,所需的深度網絡參數通常隨著類別數量的增加而呈現超線性增長。如果類別的數量很大,多類別的分類問題將變得不可行,因為模型所需的計算資源和內存存儲將是巨大的。然而,如今的很多應用程序需要解決龐大數量的多分類問題,如詞級別的語言模型,電子商務中購物項目的圖像識別(如現在淘寶和亞馬遜上數百萬的購物項),以及 10K 中文手寫漢字的識別等。
為此,來自阿里巴巴的團隊提出了一種稱為標簽映射(LM)的方法:通過將原始的分類任務分解成幾個理論上可解決的子分類任務,來解決這個問題。
據介紹,這種方法類似糾錯輸出代碼(ECOC) 一樣的集成方法,但它還允許base learner不同標簽數量的多類別分類器。該團隊提出了LM 的兩種設計原則,一個是最大化基本分類器(可以對兩個不同類別進行分類)的數量,另一個是盡可能地保證所有base learner之間的獨立性以便減少冗余信息。由于每個base learner可以獨立地進行訓練,因此很容易能將該方法擴展到一個大規模的訓練體系。實驗表明,他們所提出的方法在準確性和模型復雜性方面,顯著優于標準的獨熱編碼和 ECOC 方法。
▌簡介
事實上,用于處理 N 類的深度神經網絡分類器通常可以被看作是將歐式空間中一些復雜的嵌入表示連接到最后一層的 softmax 分類器上。復雜的嵌入表示可以被解釋為是一種聚類過程,即根據類別的標簽將數據進行聚類并在最后一層將分離數據。聚類過程會根據類別標簽對數據進行聚類,并在最后一層嘗試將它們分開。如果歐式空間最后一層的維度大于或等于 N-1,那么將存在一個 softmax 分類器分離那些概率1的聚類。但是,如果歐式空間的維度小于 N-1,那么將不存在一個 softmax 分類器能夠將一個聚類從中分離出來并使其聚類中心位于其他聚類中心所構成的凸集平面內,因為凸集上的線性函數總是能夠在頂點處取得最大值。
解決這種 N 類別的分類問題,要么固定最后一層的維度,這將導致分類的性能變得很差;或者讓最后一層的維度隨著 N 的增長而增長,但這會導致最后兩層的模型參數隨著 N 的增加而呈現超線性增長。網絡大小的超線性增長將顯著增加訓練的時間和內存的使用量,這將嚴重限制模型在許多現實的多類別問題中的應用。
本文我們提出了一種稱為標簽映射(LM)的方法來解決這個矛盾。我們的想法是將一個多類別的分類問題,變成多個小類別的分類問題,并平行地訓練這些小類別的分類問題。分布式訓練將放緩計算量和內存的增加,同時不需要機器之間的通信。
▌方法(標簽映射)
如上所述,通常 N 類的深度神經網絡分類器通常可以被看作是將歐式空間中一些列復雜的嵌入表示連接到最后一層的 softmax 分類器上。在本文中,我們進行了如下的一些定義:
我們把歐式空間 V 中 N 個點的集合稱為 X,滿足凸集的性質,并保證當且僅當凸集 X 的閉合具有確切的 N 個頂點。換句話說,softmax 分類器能夠在歐式空間 V 中分離所有的 N 個聚類,并使得聚類中心落在凸集的內部。
對于一個多類別的分類問題,我們引入一種標簽映射的方法,將大規模的多類別分類問題轉化為一些子分類問題。一個映射序列的標簽映射定義如下:
其中,每個fi都代表一個地點位置函數 (site-position function),n表示標簽映射的長度,N表示類別數量。如果每個每個類別都相等的話,我們稱之為單一的標簽映射,否則則定義為混合的標簽映射。
一般來說,N是一個很大的數字,而Ni是中等大小的一些數字。 我們可以通過標簽映射將一個N類別的分類問題減小為n的中等尺寸的分類問題。假設訓練數據集是{xk, yk},其中xk表示特征,而yk表示標簽,有兩種方法可以在深度神經網絡模型中使用標簽映射。一種是使用一個具有n個輸出的網絡 (如圖1)。另一種是使用n個網絡,每個網絡都被訓練成數據集中的base learner (如圖2)。
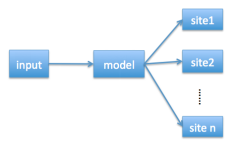
圖1: n個輸出的網絡
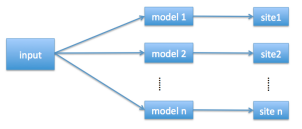
圖2:n個網絡,每個網絡有 n 個輸出
考慮到分布式訓練的便捷性,這里我們使用圖2中的方法。此外,我們還規定標簽映射應滿足如下性質:
類別的高度分離性:對于兩種不同的標簽,盡可能保證二者高度分離,這里我們通過一個地點位置函數fi來衡量。
基礎學習器的獨立性:類別的高度分離性保證了每個基礎學習器都能夠通過訓練將不同類別分離,而基礎學習器的獨立性保證了相同的信息能夠被盡可能少的學習器所學習。
與 ECOC 的差異性:我們的標簽映射方法不需要將多分類問題轉化成二分類問題 (如 ECOC 方法),也不需要轉化為相同類別數量的分類問題。
▌實驗過程
我們在 Cifar-100,CJK 字符和 Republic 三個數據集上測試了標簽映射的性能。
CIFAR-100 數據集由60000張100個類別的32x32彩色圖像構成,每個類別有500張訓練圖像和100張測試圖像。我們使用一個簡單的 CNN 網絡,其結構示意圖如下圖3,最后一層的維度是128,每個類別的標簽都是一個獨熱編碼。
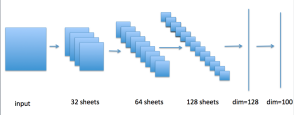
圖3:CNN 的模型結構示意圖
CJK 字符數據集由20901張139×139的灰度字符圖像構成。我們使用 Inception V3 模型,其最后一層的維度為2048,并使用獨熱編碼對應數據集中每個字符類別的標簽。
Republic 數據集由一個含118684個詞的文本構成,其中7409個詞是獨一無二的。我們使用一個 RNN 模型,其最后一層的維度為100,其結構示意圖如圖4所示。同樣,我們對類別標簽進行獨熱編碼。
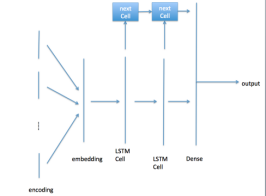
圖4:RNN 模型結構示意圖
▌結果分析
我們分別對三個數據集進行對比實驗,評估單一標簽映射、混合標簽映射及標簽映射與 ECOC 方法之間的優劣性。實驗結果表明,標簽映射的準確性將隨著數據集長度的增大而升高。在 Cifar-100 數據集上,使用獨熱編碼的標簽會給標簽映射的準確性帶來更大的提高,而對于其他兩個數據集的提升卻不是很明顯。這是因為獨熱編碼的引入能夠充分發揮簡單 CNN 結構的優勢,而對于 Inception V3 模型而言,其最后一層的維度小于 CJK 數據集的類別數量,因而獨熱編碼的作用沒能發揮出來。同樣地,對于最后一層的維度小于 Republic 數據集類別數的 RNN 模型,獨熱編碼的強大性也無法充分體現。
Cifar-100 數據集
下圖5、圖6、圖7分別表示單一標簽映射、混合標簽映射作用下的精度及標簽映射方法與 ECOC 方法的對比結果。
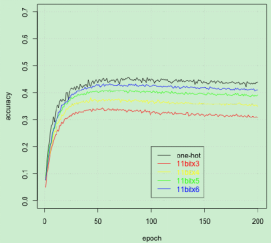
圖5:單一標簽映射下的精度
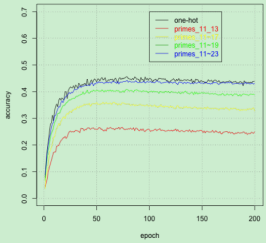
圖6:混合標簽映射下的精度
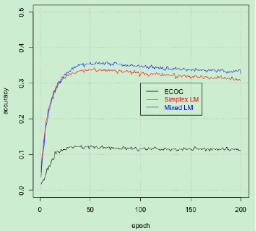
圖7:標簽映射與 ECOC 方法的對比結果
CJK 數據集
下表1、表2、表3分別表示單一標簽映射、混合標簽映射作用下的精度及標簽映射方法與 ECOC 方法的對比結果。

表1 單一標簽映射作用下的性能

表2 混合標簽映射作用下的性能

表3 標簽映射與 ECOC 方法的對比結果
Republic 數據集
表4顯示標簽映射方法在 Republic 數據集上的性能。
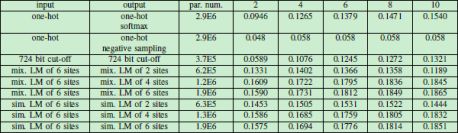
表4 標簽映射作用下的性能
▌結論
我們提出了一種方法稱為標簽映射(LM),能夠將大規模的多類別分類問題到分解成多個小規模的子分類問題,并為每個子分類問題訓練base learner。而所需的base learner數量隨著類別數量的增加而增加。此外,我們提出兩個設計原則,即類別高可分離性和base learner 的獨立性,并提出兩類滿足該原則的標簽映射,即單一標簽映射和混合標簽映射。我們分別在Cifar-100、CJK 和 Republic 三個數據集上展示了標簽映射的性能。實驗結果表明,標簽映射的性能隨長度的增加而增加。當類別數量很大時(如 CJK 字符數據集和 Republic 數據集),特別當數量遠大于模型最后一層的維度時,標簽映射的性能更佳。此外,我們還對比了標簽映射與 ECOC 方法的性能,發現在更少參數量的情況下,我們的方法還遠遠優于 ECOC 方法。
-
圖像
+關注
關注
2文章
1084瀏覽量
40459 -
數據集
+關注
關注
4文章
1208瀏覽量
24695 -
深度學習
+關注
關注
73文章
5503瀏覽量
121137
原文標題:阿里團隊最新實踐:如何解決大規模分類問題?
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一種工作于Sub-6G的5G大規模天線的系統架構探討
大規模MIMO的性能
一種先分割后分類的兩階段同步端到端缺陷檢測方法
一個benchmark實現大規模數據集上的OOD檢測
STEP模式映射的一種實用方法
一種多重映射的自動短文摘方法

科學家找到一種化學方法來儲存和操作大量的數據
一種新方法來檢測這些被操縱的換臉視頻的“跡象”
一種處理多標簽文本分類的新穎推理機制
一種基于光滑表示的半監督分類算法







 工商網監
工商網監
評論