 基于交錯組卷積的高效DNN詳解
基于交錯組卷積的高效DNN詳解
卷積神經網絡在近幾年獲得了跨越式的發展,雖然它們在諸如圖像識別任務上的效果越來越好,但是隨之而來的則是模型復雜度的不斷提升。越來越深、越來越復雜的卷積神經網絡需要大量存儲與計算資源,因此設計高效的卷積神經網絡是非常重要和基礎的問題,而消除卷積的冗余性是該問題主要的解決方案之一。
如何消除消除卷積的冗余性?我們邀請到了微軟亞洲研究院視覺計算組資深研究員王井東博士,為大家講解發表在 ICCV 2017 和 CVPR 2018 上基于交錯組卷積的方法。
▌深度學習大獲成功的原因
2006年《Science》上的一篇文章——Reducing the Dimensionality of Data with Neural Networks,是近十多年來促進深度學習發展非常重要的一篇文章。當時這篇文章出來的時候,很多機器學習領域的人都在關注這個工作,但是它在計算機視覺領域里并沒有取得非常好的效果,所以并沒有引起計算機視覺領域的人的關注。
深度學習的方法在計算機視覺領域真正得到關注是因為 2012 年的一篇文章——ImageNet Classification with Deep Convolutional Neural Networks。這個文章用深度卷積神經網絡的方法贏得了計算機視覺領域里一個非常重要的 ImageNet 比賽的冠軍。在 2012 年之前的冠軍都是基于 SVM(支持向量機)或者隨機森林的方法。
2012年 Hinton 和他的團隊通過深度網絡取得了非常大的成功,這個成功大到什么程度?比前一年的結果提高了十幾個百分點,這是非常可觀、非常了不起的提高。因為在 ImageNet 比賽上的成功,計算機視覺領域開始接受深度學習的方法。
比較這兩篇文章,雖然我們都稱之為深度學習,但實際上相差還挺大的。特別是 2012 年這篇文章叫“深度卷積神經網絡”,簡寫成 “CNN”。CNN 不是 2012 年這篇文章新提出來的,在九十年代,Yann LeCun 已經把 CNN 用在數字識別里,而且取得非常大的成功,但是在很長的時間里,大家都沒有拿 CNN 做 ImageNet 比賽,直到這篇文章。今天大家發現深度學習已經統治了計算機視覺領域。
為什么 2012 年深度學習能夠成功?其實除了深度學習或者 CNN 的方法以外,還有兩個東西,一個是 GPU,還有一個就是 ImageNet。
這個網絡結構是 2012 年 Hinton 跟他學生提出的,其實這個網絡結構也就8層,好像沒有那么深,但當時訓練這個網絡非常困難,需要一個星期才訓練出來,而且當時別人想復現它的結果也沒有那么容易。
這篇文章以后,大家都相信神經網絡越深,性能就會變得越好。這里面有幾個代表性的工作,簡單回顧一下。
深度網絡結構的兩個發展方向
▌越來越深
2014 年的 VGG,這個網絡結構非常簡單,就是一層一層堆積起來的,而且層與層之間非常相似。
同一年,Google 有一個網絡結構,稱之為“GoogLeNet”,這個網絡結構看起來比 VGG 的結構復雜一點。這個網絡結構剛出來的時候看起來比較復雜,今天看起來就是多分支的一個結構。剛開始,大家普遍的觀點是這個網絡結構是人工調出來的,沒有很強的推廣性。盡管 GoogLeNet 是一個人工設計的網絡結構,其實這里面有非常值得借鑒的東西,包括有長有短多分支結構。
2015 年時出了一個網絡結構叫 Highway。Highway 這篇文章主要是說,我們可以把 100 層的網絡甚至 100 多層的網絡訓練得非常好。它為什么能夠訓練得非常好?這里面有一個概念是信息流,它通過 SkipConnection 可以把信息很快的從最前面傳遞到后面層去,在反向傳播的時候也可以把后面的梯度很快傳到前面去。這里面有一個問題,就是這個 Skip Connection 使用了 gate function,使得深度網絡訓練困難仍然沒有真正解決。
同一年,微軟的同事發明了一個網絡,叫“ResNet”,這個網絡跟 Highway 在某種意義上很相像,相像在什么地方?它同樣用了 Skip Connection,從某一層的 output 直接跳到后面層的 output 去。這個跟 Highway 相比,它把 gate function 扔掉了,原因在于在訓練非常深的網絡里 gate 不是一個特別好的東西。通過這個設計,它可以把 100 多層的網絡訓練得非常好。后來發現,通過這招 1000 層的網絡也可以訓練得非常好,非常了不起。
2016年,GoogLeNet、Highway、ResNet出現以后,我們發現這里面的有長有短的多分支結構非常重要,比如我們的工作 deeply-fused nets,在多個 Branch 里面,每個分支深度是不一樣的這樣的好處在于,如果我們把從這個結構看成一個圖的話,發現從這個輸入點到那個輸出點有多條路徑,有的路徑長,有的路徑短,從這個意義上來講,我們認為有長有短的路徑可以把深度神經網絡訓練好。
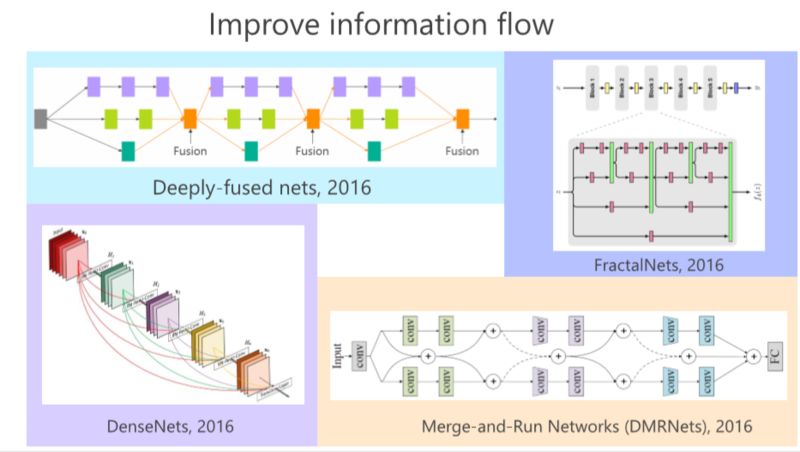
同年,我們發現有個類似的工作,叫 FractalNets,它跟我們的 deeply-fused nets 非常相像。
這條路都是通過變深,希望把網絡結構訓練得非常好,使它的性能非常好,加上 Skip Connection 等等形式來使得信息流非常好。盡管我們通過 Skip Connection 把深度網絡訓練得很不錯,但深度還是帶來一些問題,就是并沒有把性能發揮得很好,所以有另外一個維度,大家希望變得更寬一點。
除此之外,大的網絡用在實際中會遇到一些問題。比如部署到手機上時希望計算量不要太大,模型也不要太大,性能仍然要很好,所以識別率做的非常高的但是很龐大的網絡結構在實際應用里面臨一些困難。
▌簡化結構的幾種方法

另外一條路是簡化網絡結構,消除里面的冗余性。因為大家都認為現在深度神經網絡結構里有很強的冗余性,消除冗余性是我近幾年發現非常值得做的一個領域,因為它的實際用處很大。
卷積操作
CNN 里面的卷積操作實際上對應的就是矩陣向量相乘,大家做的基本就是消除卷積里的冗余性。
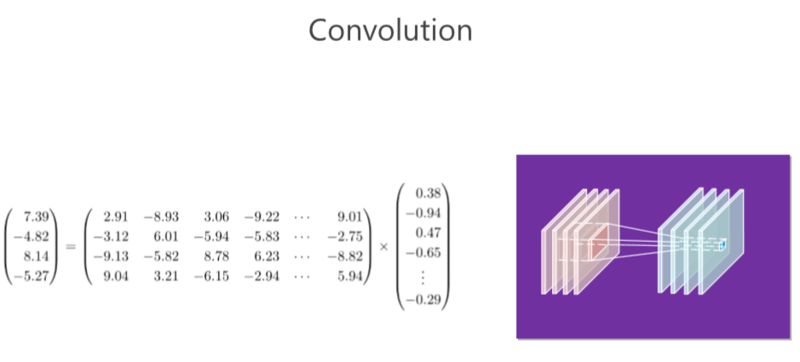
我們回顧一下卷積。右邊的圖:在 CNN 里面有若干個通道,每個通道實際上是一個二維的數組,每個位置都有一個數值,在這里面我們稱為“響應值”。這里面有四個通道,實際上就相當于三維的數組一樣。以這里(每個位置)為中心,取一個 3×3 的小塊出來,3×34 個通道,那就有 3×3×4 這么多個數值,然后我們把這么多個數值拉成一個 3×3×4=36 維向量。卷積有個卷積核,卷積核對應一個橫向量,這個橫向量和列向量一相乘,就會得到響應的值,這是第一個卷積核。通過第二個卷積核又會得到第二個值,類似地可以得到第三個第四個值。
總結起來,卷積操作就是是矩陣和向量相乘,矩陣對應的是若干個卷積核,向量對應的是周圍方塊的響應值(ResponseValue)。
大家都知道矩陣跟向量相乘占了很大的計算量。我在這里舉的例子并沒有那么大,但大家想一想,如果輸入輸出 100個 通道,,假如這個卷積核是3×3×100,那就是 100×900 的計算量,這個計算量非常大,所以有大部分工作集中在解決這里面(卷積操作)冗余性的問題。
Low-precision kernels(低精度卷積核)
有什么辦法解決冗余性的問題呢?

因為卷積核通常是浮點型的數,浮點型的數計算復雜度要大一點,同時它占得空間也會大一點。最簡單的一招是什么?假設把卷積核變成二值的,比如 1、-1,我們看看 1、-1轉成以后有什么好處?這個向量 1、-1(使得)本來相乘的操作變成加減了,這樣一來計算量就減少了很多。除此以外,模型和存儲量也減少很多。

也有類似相關的工作,就是把浮點型的變成整型的,比如以前 32 位浮點數的變成 16 位的整型數,同樣存儲量會小,或者模型會小。除了卷積核進行二值化化以外或者進行整數化以外,也可以把 Response 變成二值數或者整數。

還有一類研究得比較多的是量化。比如把這個矩陣聚類,比如 2.91、3.06、3.21,聚成一類,我用 3 來代替它量化有什么好處?首先,你的存儲量減少了,不需要存儲原來的數值,只需要存量化以后的每個中心的索引值就可以了。除此之外,計算量也變小了,你可以想辦法讓它減少乘的次數,這樣就模型大小就會減少了。
Low-rank kernels(低秩卷積核)


另外一條路,矩陣大怎么辦?把矩陣變小一點,所以很多人做了這件事情, 100 個(輸出)通道,我把它變成 50 個,這是一招。另外一招, input(輸入)很多, 100 個通道,變成了 50 個。
低秩卷積核的組合

把通道變少會不會降低性能?所以有人做了這件事情:把這個矩陣變成兩個小矩陣相乘,假如這個矩陣是 100×100 的,我把它變成 100×10 和10×100 兩個矩陣相乘,(相乘得到的矩陣)也變成 100×100 的矩陣,近似原來 100×100 那個矩陣。這樣想想,100×100 變成 100×10 跟 10×100,顯然模型變小了,變成五分之一。此外計算量也降到五分之一。
稀疏卷積核
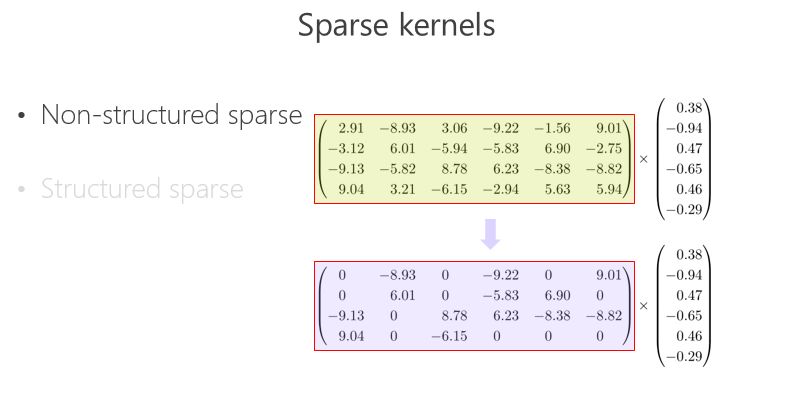
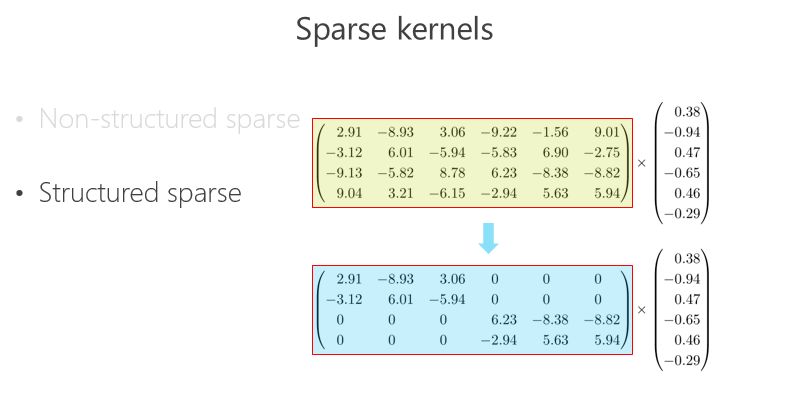
另外一條路,怎么把矩陣跟向量相乘變得快一點、模型的參數少一點?可以把里面的有些數變成 0,比如 2.91 變成 0,3.06 變成 0,變成 0 以后就成了稀疏的矩陣,這個稀疏矩陣存儲量會變小,如果你足夠稀疏的話,計算量會小,因為直接是 0 就不用乘了。還有一種 Structured sparse(結構化稀疏),比如這種對角形式,矩陣跟向量相乘,可以優化得很好。這里 Structured sparse 對應我后面將要講的組卷積(Groupconvolution)。
稀疏卷積核的組合
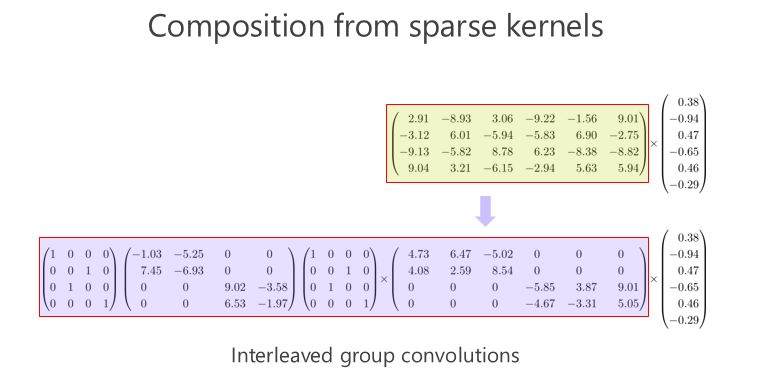
我們來看看這個矩陣能不能通過多個稀疏矩陣相乘來近似,這是我今天要講的重點,我們的工作也是圍繞這一點在往前走。在我們做這個方向之前,大家并沒有意識到一個矩陣可以變成兩個稀疏矩陣相乘甚至多個稀疏矩陣相乘,來達到模型小跟計算量小的目標。
從IGCV1到IGCV3
▌IGCV1
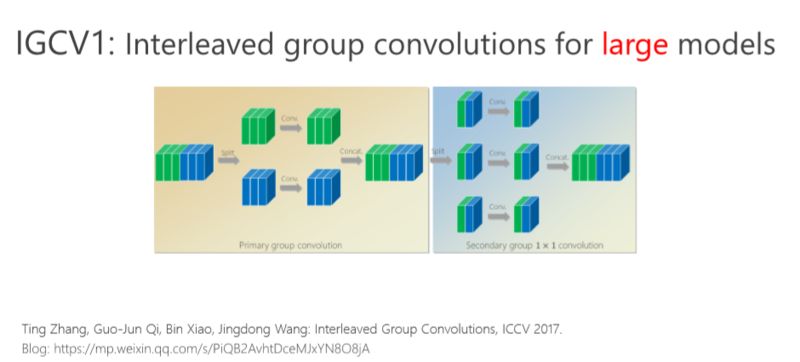
首先我給大家介紹一下我們去年在 ICCV 2017 年會議上的文章,交錯組卷積的方法。
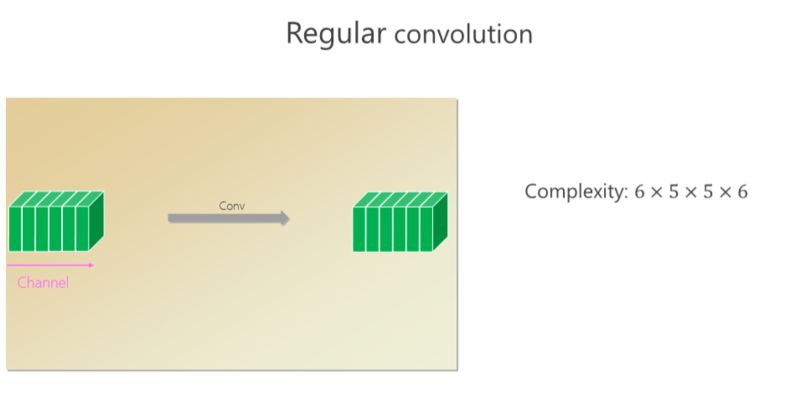
這個卷積里面有六個通道,通過卷積出來的也是六個小方塊(通道),假如 spatial kernel 的尺寸是5×5,對每個位置來講,它的計算量是6×5×5×6。
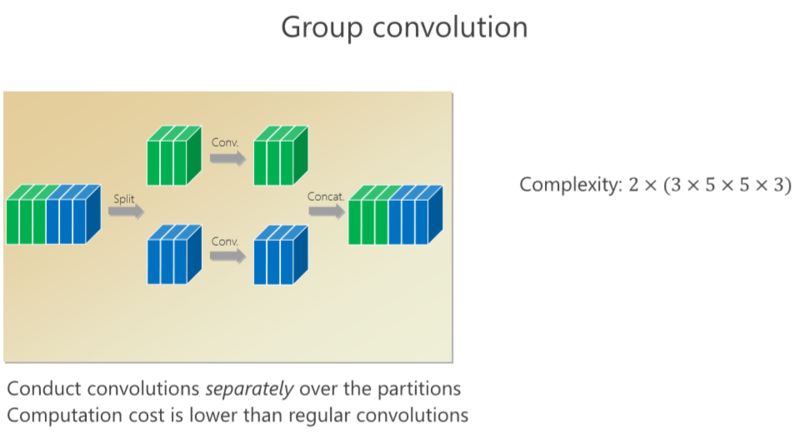
我剛才講了(一種結構化)稀疏的形式,對應的就是組卷積的形式,組卷積是什么意思?我把這 6 個通道分成上面 3 個通道和下面 3 個通道,分別做卷積,做完以后把它們拼在一起,最后得到的是6個通道。看看計算量,上面是 3×5×5×3,下面也是一樣的,整個計算復雜度跟前面的 6×5×5×6 相比就小了一半,但問題是參數利用率可能不夠。
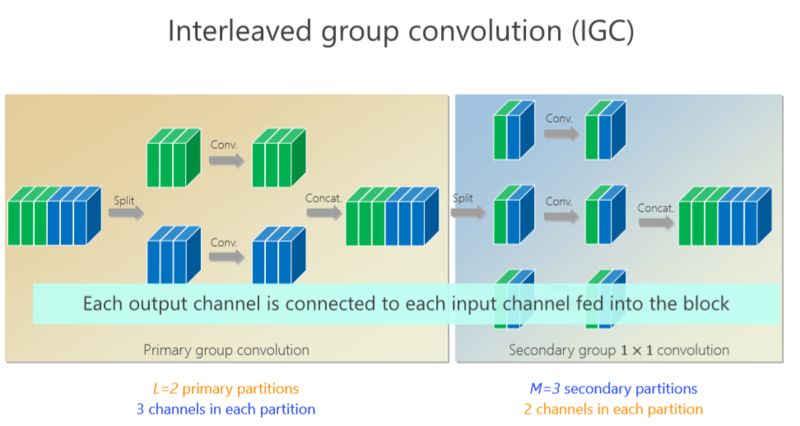
我們的工作是基于組卷積的,剛才提到了上面的三個通道和這三個通道不相關,那有沒有辦法讓它們相關?所以我們又引進了第二個組卷積,我們把這6個通道重新排了序,1、4 放到這(第一個分支),2、5 放到這(第二個分支),3、6 放到那(第三個分支),這樣每一分支再做一次 1×1 的convolution,得出新的兩個通道、兩個通道、兩個通道,拼在一起。通過交錯的方式,我們希望達到每個 output(輸出)的通道(綠色的通道或者藍色的通道)跟前面6個通道都相連。
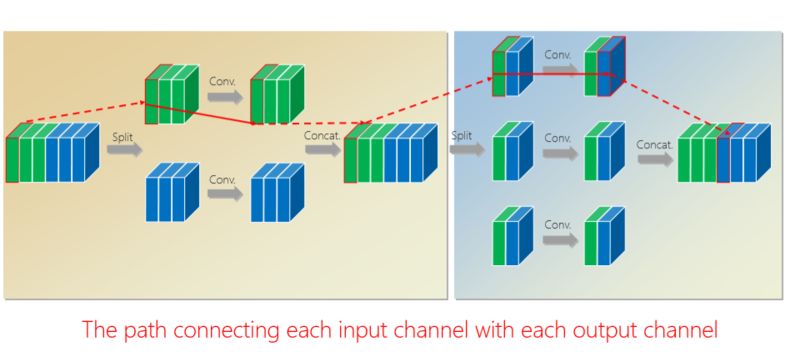
有什么好處?通過第二組的組卷積可以達到互補的條件,或者使得任何一個 output(輸出通道)和任何一個 input(輸入通道)連起來。

這里面我們引進了一個嚴格的互補條件,直觀來講就是,如果有兩個通道在第一組卷積里面,落在同一個 Branch(分支),我希望在第二組里面落在不同的 Branch(分支)。第二組里面比如一個 Branch(分支)里面的若干個通道,要來自于第一個組卷積里面的所有 Branches(分支),這個稱為互補條件。這個互補條件帶來什么?它會帶來(任何一對輸入輸出通道之間存在) path,也就是說相乘矩陣是密集矩陣。為什么稱之為“嚴格的”?就是任何一個 input 和 output 之間有一條 path,而且有且只有一條path。

嚴格的準則引進來以后,參數量變小了、模型變小了,帶來什么好處?這里我給一個結論,L 是(第)一個組卷積里面的 partitions(分支)的數目或者卷積的數目,M是第二組組卷積卷積的數目,S 是卷積核的大小,通常都是大于 1 的。這樣的不等式幾乎是恒成立的,這個不等式意味著什么?結論是:如果跟普通標準的卷積去比,通過我們的設計方式可以讓網絡變寬。跟網絡變深相比起來,網絡變寬是另外一個維度,變寬有什么好處?會不會讓結果變好?我們做了一些實驗。
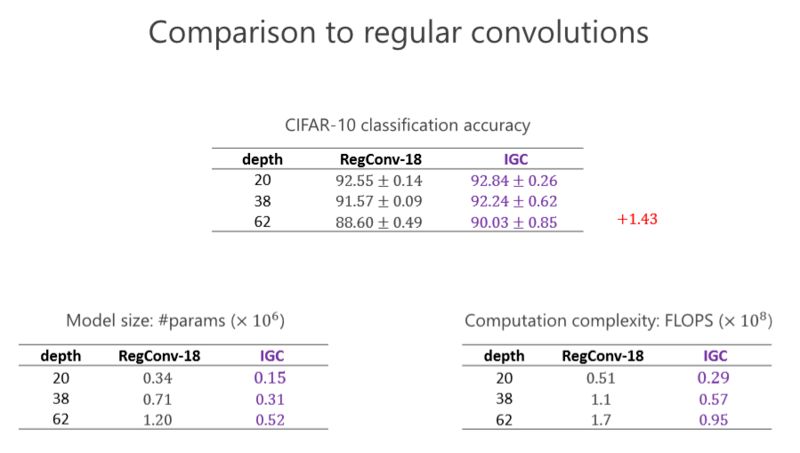
這個實驗是跟標準的卷積去比,大家看看左下角的表格,這個表格是參數量,我們設計的網絡幾乎是標準(卷積)參數量的一半。然后看看右下角這個網絡,我們的的計算量幾乎也是一半。在 CIFAR-10 標準的圖像分類數據集里(上面的表格),我們的結果比前面的一種好。我們甚至會發現越深越好,在 20 層有些提升并沒有那么明顯,但深的時候可以達到 1.43 的提高量。
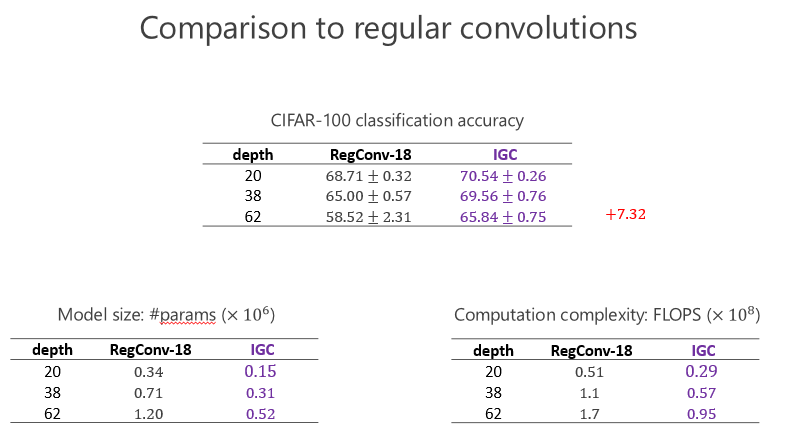
后來 CIFRA-100 我們也做了同樣的實驗,發現我們提升仍然是一致的,甚至跟前面的比起來提高得更大,因為分 100 類比分 10 類困難一點,說明越困難的任務,我們的優勢越明顯。這個變寬了以后(性能)的確變好了,通過 IGC 實現,網絡結構變寬的確會帶來好處。
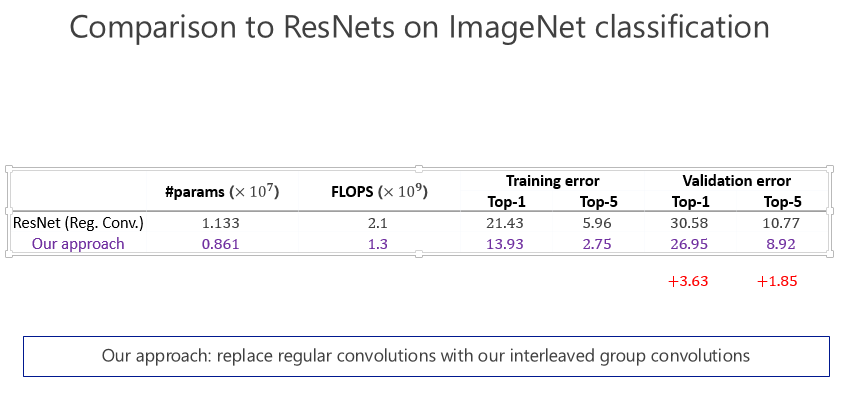
這是兩個小的數據集,其實在計算機視覺領域里小數據集上的結果是不能(完全)說明問題的,一定要做非常大的數據集。所以我們當時也做了 ImageNet 數據集,跟 ResNet 比較了一下,參數量少了近五分之二,計算量小了將近一半了,錯誤率也降低了,這證明通過 IGC 的實現,讓模型變寬,在大的網絡模型上取得非常不錯的效果。
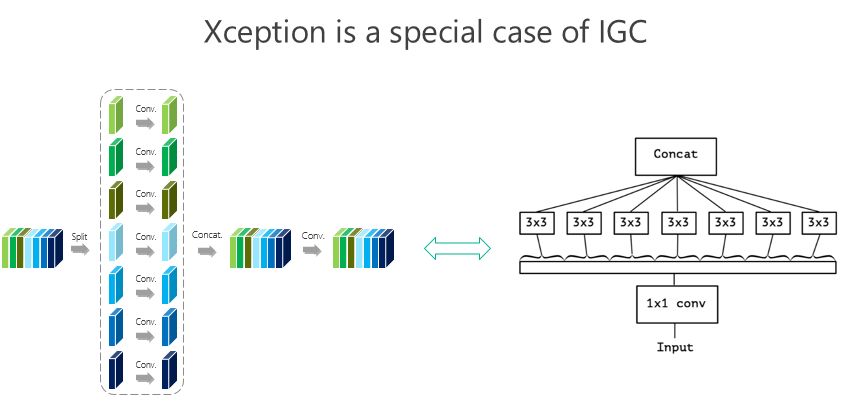
我們大概是前年 8、9 月份開始做這個事情,10 月份發現 Google 有一個工作是 Xception,這個是它的結構圖,這個形式非常接近(我們的結構),跟我們前面所謂的 IGC 結構非常像,實際上就是我們的一個特例。當時我們覺得這個特例有沒有可能結果最好,所以我們做了些驗證,整體上我們結構好一點。
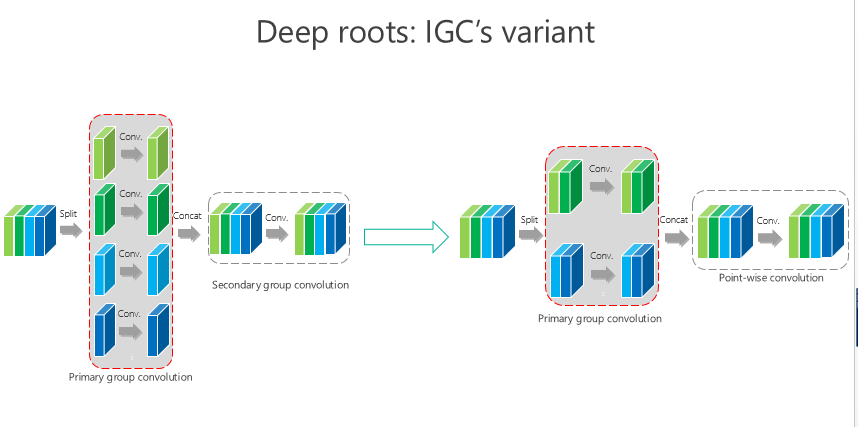
IGC 可能還有變體,比如我要是把這個 channel-wise 也變成組卷積,第二個是 1×1 的,這樣的結果會怎樣?我們做了類似同樣的實驗,仍然發現我們的方法是最好的。
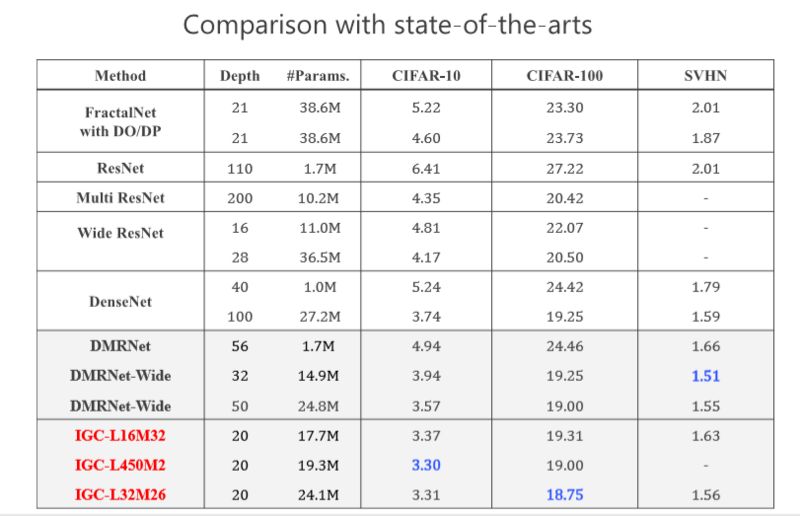
當時我們做的時候,希望在網絡結構上跟 state-of-the-arts 的方法去比較,我們取得了非常不錯的結果,當時我們的工作是希望通過消除冗余性提高模型性能或者準確率。
▌IGCV2
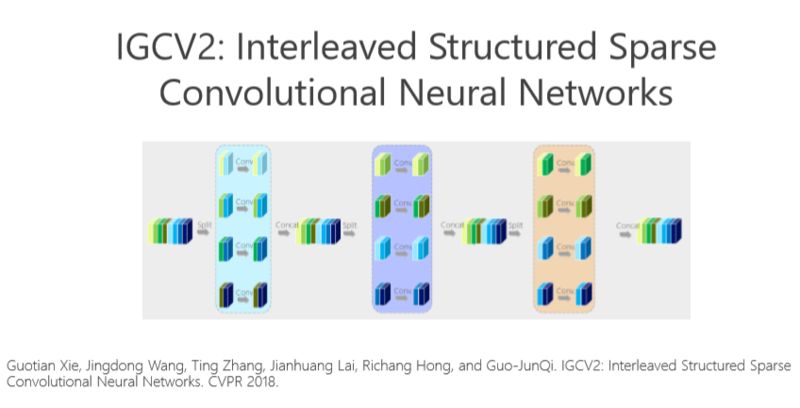
后來我們嘗試利用消除冗余性帶來的好處,把這個模型部署到手機上去。我們去年又沿著這個方向繼續往前走,把這個問題理解得更深,希望進一步消除冗余性。
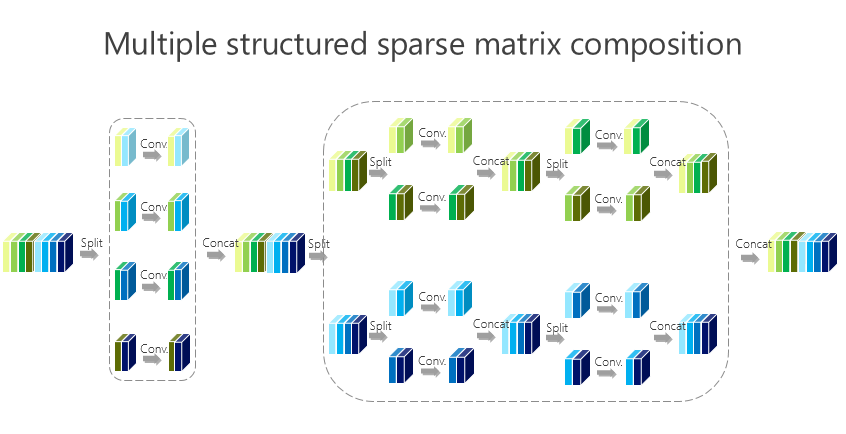
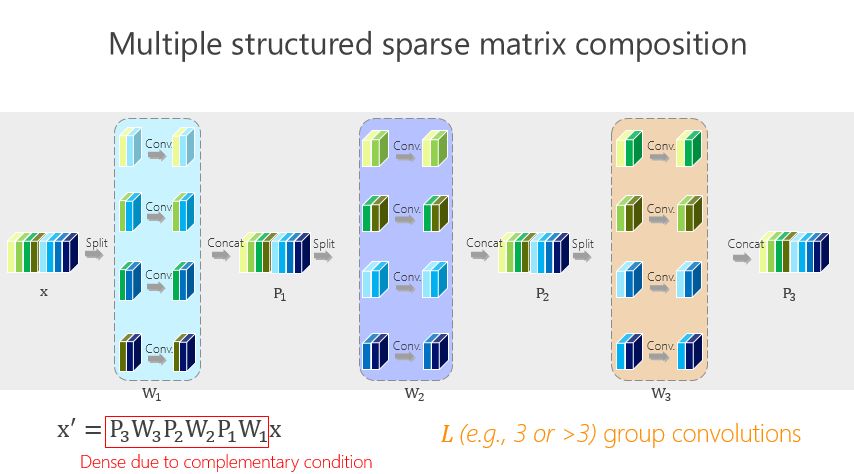
這個講起來比較直接或簡單一點,前面的網絡結構是兩個組卷積或者兩個矩陣相乘得到的,我們有沒有辦法變得多一點?實際上很簡單,如上圖所示。

這種方法帶來的好處很直接,就是希望參數量盡量小,那怎么才能(使)參數量盡量小?我們引進了所謂的平衡條件。雖然這里面我們有 L-1 個 1×1 的組卷積,但 L-1 個 1×1 的組卷積之間有區別嗎?誰重要一點、誰不重要一點?其實我們也不知道。不知道怎么辦?就讓它一樣。一樣了以后,我們通過簡單的數學推導就會得出上面的數學結果。
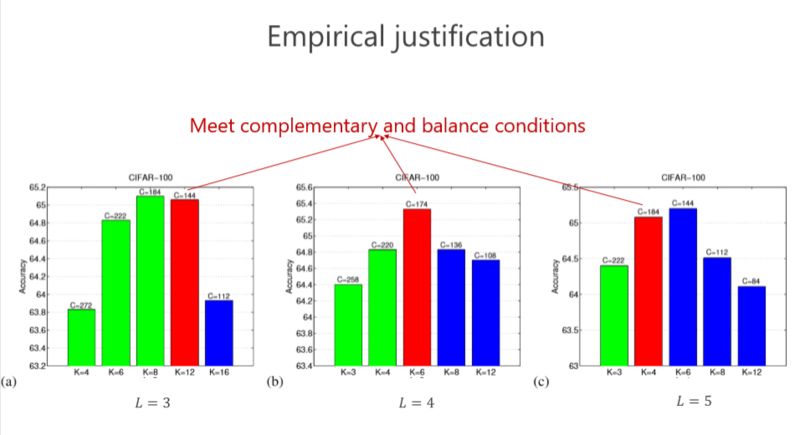
現在再驗證一下,前面講了互補條件、平衡條件,那這個結果是不是最好的?或者是不是有足夠的優勢?我們做了些實驗,這個紅色的是對應滿足我們條件的,發現這個情況下(L=4)結果是最好的。其實是不是總是最好?不見得,因為實際問題跟理論分析還是有點距離。但我們總體發現基本上紅色的不是最好也排在第二,說明這種設計至少給了我們很好的準則來幫助設計網絡結構。這個雖然不總是最好的,但和最好的是差不多的。

第二個問題,我們究竟要設計多少個組卷積(L 設成多少)?同樣我們的準則也是通過參數量最小來進行分析,以前是兩個組卷積,我們可以通過 3 個、4 個達到參數量更小,但其實最終的結論發現,并不是參數量最優的情況下性能是最好的。
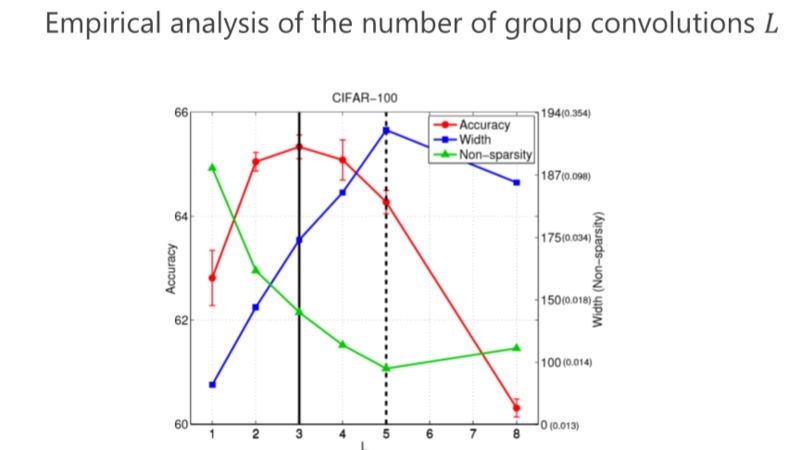
▌IGCV3

后來我們發現,如果遵循嚴格互補條件,模型的結構變得非常稀疏、非常寬,結果不見得是最好的。所以我們變成了 Loose。Loose 是什么意思?以前 output(輸出通道)和 input (輸入通道)之間是有且只有一個 path,我們改得非常簡單,能不能多個path?多個 path 就沒那么稀疏了,它好處在于每個 output (輸出通道)可以多條路徑從 input (輸入通道)那里拿到信息,所以我們設計了 Loose condition。

實際上非常簡單,我們就定義兩個超級通道(super-channels)只能在一個 Branch 里面同時出現,不能在兩個 Branch 里同時出現,來達到 Loose condition。
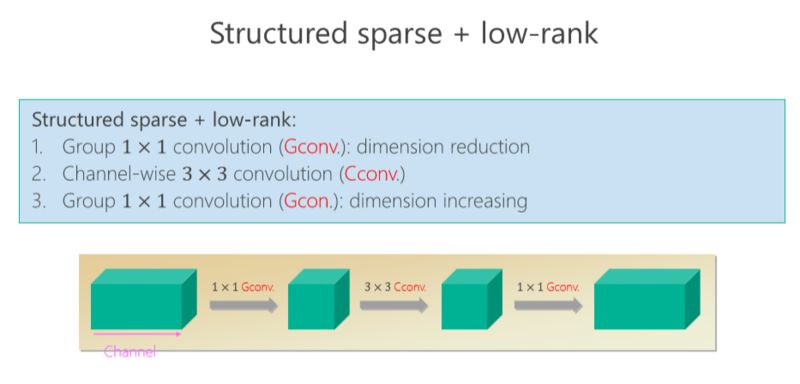
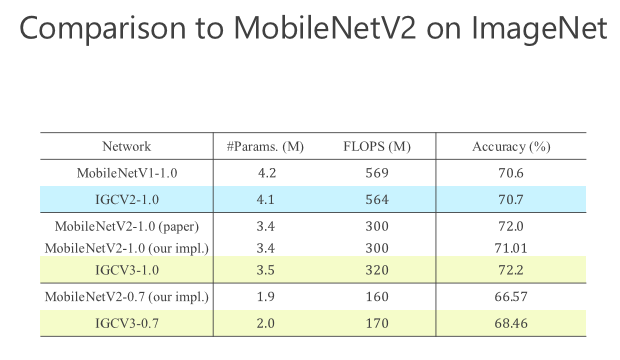
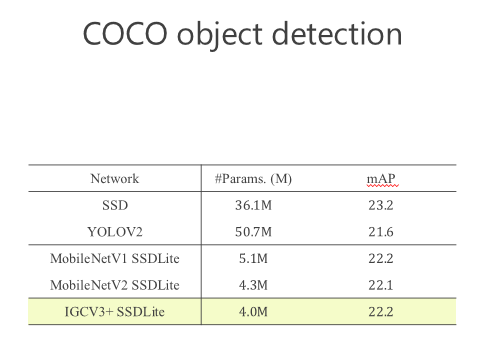
后來我們進一步往前走,把 structured sparse 和 low-rank 兩個組起來。我們在 ImageNet 上比較,同時跟 MobileV2 去比,在小的模型我們優勢是越來越明顯的。比較結果,見下圖。

這就是今天的主要內容,這個工作是我跟很多學生和同事一起做的,前面這5個是我的學生,Ting Zhang現在在微軟研究院工作,Bin Xiao 是我的同事,Guojun Qi 是美國的教授,我們一起合作了這篇文章。
-
卷積神經網絡
+關注
關注
4文章
367瀏覽量
11863 -
dnn
+關注
關注
0文章
60瀏覽量
9051
發布評論請先 登錄
相關推薦
什么是卷積碼? 什么是卷積碼的約束長度?
【我是電子發燒友】如何加速DNN運算?
CNN之卷積層
詳解時間交錯技術
可分離卷積神經網絡在 Cortex-M 處理器上實現關鍵詞識別
卷積碼,卷積碼是什么意思
卷積碼,什么是卷積碼
什么是DNN_如何使用硬件加速DNN運算
淺談卷積編碼在通信中的應用 詳解卷積編碼設計應用
詳解卷積神經網絡卷積過程
卷積神經網絡詳解 卷積神經網絡包括哪幾層及各層功能
AI芯片設計DNN加速器buffer管理策略
基于FPGA進行DNN設計的經驗總結






 工商網監
工商網監
評論