") DeepMind分享了他們?cè)诙嘀悄荏w學(xué)習(xí)方面的進(jìn)展
DeepMind分享了他們?cè)诙嘀悄荏w學(xué)習(xí)方面的進(jìn)展
繼OpenAI之后,DeepMind也在多智能體強(qiáng)化學(xué)習(xí)方面秀肌肉:首次在第一人稱射擊游戲的多人模式中完勝人類,而且沒(méi)有使用大量訓(xùn)練局?jǐn)?shù),輕松超過(guò)了人類水平。
就在OpenAI宣布在5v5 DOTA 2中戰(zhàn)勝人類玩家后沒(méi)多久,今天,DeepMind也分享了他們?cè)诙嘀悄荏w學(xué)習(xí)(multi-agent learning)方面的進(jìn)展。
CEO Hassabis在Twitter上分享:“我們最新的工作展示了智能體在復(fù)雜的第一人稱多人游戲中達(dá)到人類水平,還能與人類玩家合作!”
Hassbis說(shuō)的這個(gè)游戲,就是《雷神之錘III競(jìng)技場(chǎng)》,這也是很多現(xiàn)代第一人稱射擊游戲的鼻祖,玩家或獨(dú)立或組隊(duì)在地圖中廝殺,死亡后數(shù)秒在地圖某處重生。當(dāng)某一方達(dá)到勝利條件(在DeepMind的實(shí)驗(yàn)里就是搶奪更多的旗幟),或者游戲持續(xù)一定時(shí)間后即宣告回合結(jié)束。勝利條件取決于選擇的游戲模式。
雖然Hassbis在Twitter里說(shuō)他們的AI“達(dá)到了人類水平”,實(shí)際上,從實(shí)驗(yàn)結(jié)果看,他們的AI已經(jīng)超越了人類:在與由40個(gè)人類玩家組成的隊(duì)伍對(duì)戰(zhàn)時(shí),純AI的隊(duì)伍完勝純?nèi)祟惖年?duì)伍(平均多搶到16面旗),并且有95%的幾率戰(zhàn)勝AI與人混合組成的隊(duì)伍。
這個(gè)AI名叫“為了贏”(For the Win,F(xiàn)TW),只玩了將近45萬(wàn)場(chǎng)游戲,理解了如何有效地與人和其他的機(jī)器合作與競(jìng)爭(zhēng)。
研究人員對(duì)AI的唯一限定是,在5分鐘時(shí)間里盡可能取得多的旗幟。對(duì)戰(zhàn)的游戲地圖是隨機(jī)生成的,每場(chǎng)都會(huì)變,室內(nèi)與室外的地形也不相同。組隊(duì)的時(shí)候,AI可能與人組隊(duì),也可能與其他AI組隊(duì)。對(duì)戰(zhàn)的模式分為慢速和高速兩種。
在訓(xùn)練過(guò)程中,AI發(fā)展出了自己的獎(jiǎng)勵(lì)機(jī)制,學(xué)會(huì)了基地防守、尾隨隊(duì)友,或者守在敵人營(yíng)地外偷襲等策略。
DeepMind在他們今天發(fā)表的博客文章中寫(xiě)道,從多智能體的角度說(shuō),玩《雷神之錘III》這種多人視頻游戲,需要與隊(duì)友合作,與敵方競(jìng)爭(zhēng),還要對(duì)遭遇到的任何對(duì)戰(zhàn)風(fēng)格/策略保持魯棒性。
分析發(fā)現(xiàn),游戲中,AI在“tagging”(碰觸對(duì)方,將其送回地圖上的初始地點(diǎn))上比人類更加高效,80%的情況下能夠成功(人類為48%)。
而且有趣的是,對(duì)參與對(duì)戰(zhàn)的人類玩家進(jìn)行調(diào)查后發(fā)現(xiàn),大家普遍認(rèn)為AI是更好的team player,更善于合作。
第一人稱射擊游戲多人模式重大突破
啟元世界首席算法官、前Netflix資深算法專家王湘君告訴新智元:
之前第一人稱射擊(FPS)游戲的研究更多是單人模式,這次DeepMind在FPS多人模式做出了重大突破,在沒(méi)有使用大量訓(xùn)練局?jǐn)?shù)的情況下就超過(guò)了人類水平。和之前OpenAI Five相比,DeepMind的Capture the Flag (CTF) 模型直接從pixel學(xué)習(xí),沒(méi)有作feature engineering和為每個(gè)agent單獨(dú)訓(xùn)練模型,得益于以下創(chuàng)新:
去年DeepMind Max Jaderberg 提出的Population-based training 的應(yīng)用極大提高了訓(xùn)練效率,并且提供了多樣化的exploration,幫助模型在不同地形隊(duì)友環(huán)境中的適應(yīng)性,實(shí)驗(yàn)結(jié)果顯示比self-play的結(jié)果更好更高效。
For The Win agent 的分層reward機(jī)制來(lái)解決credit assignment問(wèn)題。
用fast and slow RNN 和內(nèi)存機(jī)制達(dá)到類似Hierarchical RL的作用。
不過(guò),F(xiàn)PS在策略學(xué)習(xí)上面的難度還是比Dota,星際這種RTS游戲小很多,CTF模型在長(zhǎng)期策略游戲上效果還有待觀察。
在和人類對(duì)戰(zhàn)模式之外,CTF模型同時(shí)在人機(jī)協(xié)作上有很好的效果。值得一提的是,啟元世界在今年4月份北大ACM總決賽期間發(fā)布的基于星際爭(zhēng)霸2的人機(jī)協(xié)作挑戰(zhàn)賽,其智能體也率先具備了與人和AI組隊(duì)協(xié)作的能力。人機(jī)協(xié)作在未來(lái)的人工智能研究領(lǐng)域?qū)⒊蔀榉浅V匾囊画h(huán)。
掌握策略,理解戰(zhàn)術(shù)和團(tuán)隊(duì)合作
在多人視頻游戲中掌握策略、戰(zhàn)術(shù)理解和團(tuán)隊(duì)合作是人工智能研究的關(guān)鍵挑戰(zhàn)。現(xiàn)在,由于強(qiáng)化學(xué)習(xí)取得的新進(jìn)展,我們的智能體已經(jīng)在《雷神之錘III競(jìng)技場(chǎng)》(Quake III Arena)游戲中達(dá)到了人類級(jí)別的表現(xiàn),這是一個(gè)經(jīng)典的3D第一人稱多人游戲,也是一個(gè)復(fù)雜的多智能體環(huán)境。這些智能體展現(xiàn)出同時(shí)與人工智能體和人類玩家合作的能力。
我們居住的星球上有數(shù)十億人,每個(gè)人都有自己的個(gè)人目標(biāo)和行動(dòng),但我們?nèi)匀荒軌蛲ㄟ^(guò)團(tuán)隊(duì)、組織和社會(huì)團(tuán)結(jié)起來(lái),展現(xiàn)出顯著的集體智慧。這是我們稱之為多智能體學(xué)習(xí)(multi-agentlearning)的設(shè)置:許多個(gè)體的智能體必須能夠獨(dú)立行動(dòng),同時(shí)還要學(xué)會(huì)與其他智能體交互和合作。這是一個(gè)極其困難的問(wèn)題——因?yàn)橛辛斯策m應(yīng)智能體,世界在不斷地變化。
為了研究這個(gè)問(wèn)題,我們選擇了3D第一人稱多人視頻游戲。這些游戲是最流行的電子游戲類型,由于它們身臨其境的游戲設(shè)計(jì),以及它們?cè)诓呗浴?zhàn)術(shù)、手眼協(xié)調(diào)和團(tuán)隊(duì)合作方面的挑戰(zhàn),吸引了數(shù)以百萬(wàn)計(jì)的玩家。我們的智能體面臨的挑戰(zhàn)是直接從原始像素中學(xué)習(xí)以產(chǎn)生操作。這種復(fù)雜性使得第一人稱多人游戲成為人工智能社區(qū)一個(gè)非常活躍而且得到許多成果的研究領(lǐng)域。
我們的這項(xiàng)工作關(guān)注的游戲是《雷神之錘III競(jìng)技場(chǎng)》(我們對(duì)其進(jìn)行了一些美術(shù)上的修改,但所有游戲機(jī)制保持不變)。《雷神之錘III競(jìng)技場(chǎng)》是為許多現(xiàn)代第一人稱視頻游戲奠定了基礎(chǔ),并吸引了長(zhǎng)期以來(lái)競(jìng)爭(zhēng)激烈的電子競(jìng)技場(chǎng)面。我們訓(xùn)練智能體作為個(gè)體學(xué)習(xí)和行動(dòng),但必須能夠與其他智能體或人類組成團(tuán)隊(duì)作戰(zhàn)。
CTF(Capture The Flag)的游戲規(guī)則很簡(jiǎn)單,但是動(dòng)態(tài)很復(fù)雜。在Quake3里分成藍(lán)紅兩隊(duì)在給定的地圖中競(jìng)賽。競(jìng)賽的目的是將對(duì)方的旗子帶回來(lái),并且碰觸未被移動(dòng)過(guò)的我方旗子,我隊(duì)就得一分,稱作一個(gè)capture。為了獲得戰(zhàn)術(shù)上的優(yōu)勢(shì),他們可以會(huì)碰觸地方的隊(duì)員(tagging),把他們送回自己的地盤(pán)。在五分鐘內(nèi)capture到最多旗子的隊(duì)伍獲勝。
從多智能體的角度看,CTF要求隊(duì)員既要成功地與隊(duì)友合作,又要與對(duì)方敵手競(jìng)爭(zhēng),同時(shí)在可能遇到的任何比賽風(fēng)格中保持穩(wěn)健性。
FTW智能體:等級(jí)分遠(yuǎn)超基線方法和人類玩家
為了使事情更有趣,我們?cè)O(shè)計(jì)了CTF的一種變體,令地圖的布局在每一場(chǎng)競(jìng)賽中發(fā)生改變。這樣,我們的智能體被迫要采用一般性策略,而不是記住地圖的布局。此外,為了讓游戲更加公平,智能體要以類似于人類的方式體驗(yàn)CTF的世界:它們觀察一系列的像素圖像,并通過(guò)模擬游戲控制器發(fā)出動(dòng)作。
CTF是在程序生成的環(huán)境中執(zhí)行的,因此,智能體必須要適應(yīng)不可見(jiàn)的地圖。
智能體必須從頭開(kāi)始學(xué)習(xí)如何在不可見(jiàn)(unseen)的環(huán)境中觀察、行動(dòng)、合作和競(jìng)爭(zhēng),所有這些都來(lái)自每場(chǎng)比賽的一個(gè)強(qiáng)化信號(hào):他們的團(tuán)隊(duì)是否獲勝。這是一個(gè)具有挑戰(zhàn)性的學(xué)習(xí)問(wèn)題,它的解決方法基于強(qiáng)化學(xué)習(xí)的三個(gè)一般思路:
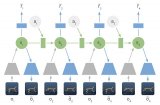
我們不是訓(xùn)練一個(gè)智能體,而是訓(xùn)練一群智能體,它們通過(guò)組隊(duì)玩游戲來(lái)學(xué)習(xí),提供了多樣化的隊(duì)友和敵手。
群體中的每個(gè)智能體都學(xué)習(xí)自己的內(nèi)部獎(jiǎng)勵(lì)信號(hào),這些信號(hào)使得智能體能夠產(chǎn)生自己的內(nèi)部目標(biāo),例如奪取一面旗子。雙重優(yōu)化過(guò)程可以直接為了獲勝優(yōu)化智能體的內(nèi)部獎(jiǎng)勵(lì),并使用內(nèi)部獎(jiǎng)勵(lì)的強(qiáng)化學(xué)習(xí)來(lái)學(xué)習(xí)智能體的策略。
智能體在兩個(gè)時(shí)間尺度上運(yùn)行,快速和慢速,這提高了它們使用內(nèi)存和產(chǎn)生一致動(dòng)作序列的能力。
圖: For The Win (FTW)智能體架構(gòu)的示意圖。該智能體將快速和慢速兩個(gè)時(shí)間尺度的循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)相結(jié)合,包括一個(gè)共享記憶模塊,并學(xué)習(xí)從游戲點(diǎn)到內(nèi)部獎(jiǎng)勵(lì)的轉(zhuǎn)換。
由此產(chǎn)生的智能體,我們稱之為For The Win(FTW)智能體,它學(xué)會(huì)了以非常高的標(biāo)準(zhǔn)玩CTF。最重要的是,學(xué)會(huì)的智能體策略對(duì)地圖的大小、隊(duì)友的數(shù)量以及團(tuán)隊(duì)中的其他參與者都具有穩(wěn)健性。
下面演示了FTW智能體互相競(jìng)爭(zhēng)的室外程序環(huán)境游戲,以及人類和智能體競(jìng)爭(zhēng)的室內(nèi)程序環(huán)境的游戲。
圖:交互式CTF游戲?yàn)g覽器,分別有室內(nèi)和室外的程序生成環(huán)境。室外地圖游戲是FTW智能體相互之間的競(jìng)賽,而室內(nèi)地圖上的游戲則是人類與FTW智能體之間的競(jìng)賽(見(jiàn)圖標(biāo))。
我們舉辦了一場(chǎng)比賽,包括40名人類玩家。在比賽中,人類和智能體都是隨機(jī)配對(duì)的——可以作為敵手或者作為隊(duì)友。
一場(chǎng)早期的測(cè)試比賽,由人類與訓(xùn)練好的智能體一起玩CTF。
FTW智能體學(xué)會(huì)的比強(qiáng)大的基線方法更強(qiáng),并超過(guò)人類玩家的勝率。事實(shí)上,在一項(xiàng)對(duì)參與者的調(diào)查中,它們被認(rèn)為比人類參與者更具有合作精神。
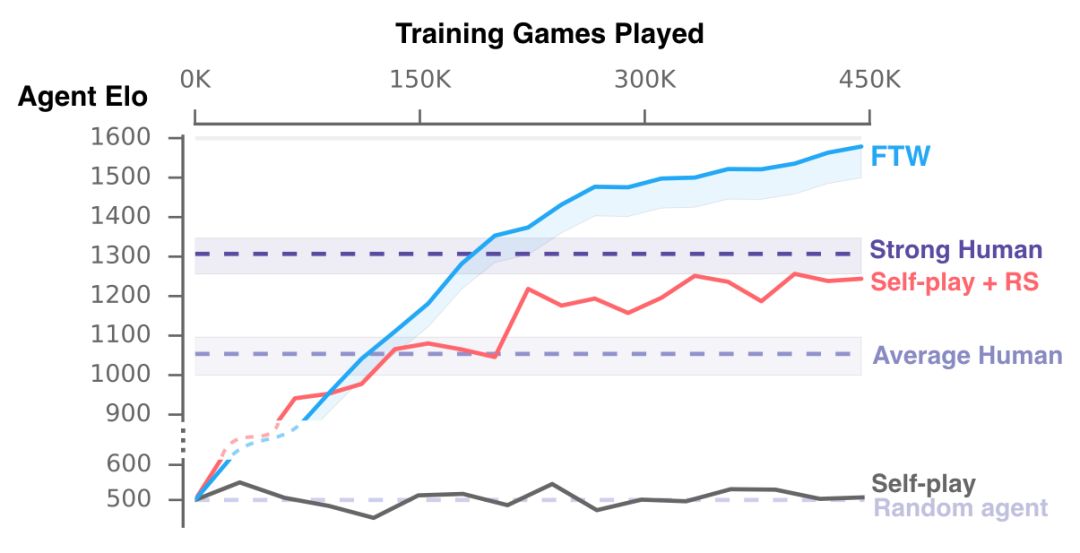
訓(xùn)練期間我們的智能體的表現(xiàn)。我們新的FTW智能體相比人類玩家和Self-play + RS和Self-play的基線方法獲得了更高的Elo等級(jí)分——獲勝的概率也更高。
除了性能評(píng)估之外,理解這些智能體的行為和內(nèi)部表示的復(fù)雜性是很重要的。
為了理解智能體如何表示游戲狀態(tài),我們研究了在平面上繪制的智能體的神經(jīng)網(wǎng)絡(luò)的激活模式。下圖中的點(diǎn)表示游戲過(guò)程中的情況,近處的點(diǎn)表示類似的激活模式。這些點(diǎn)是根據(jù)高級(jí)CTF游戲狀態(tài)進(jìn)行著色的,在這些狀態(tài)中智能體要問(wèn)自己:智能體在哪個(gè)房間?旗子的狀態(tài)是怎樣的?可以看到哪些隊(duì)友和敵手?我們觀察到相同顏色的集群,表明智能體以類似的方式表示類似的高級(jí)游戲狀態(tài)。
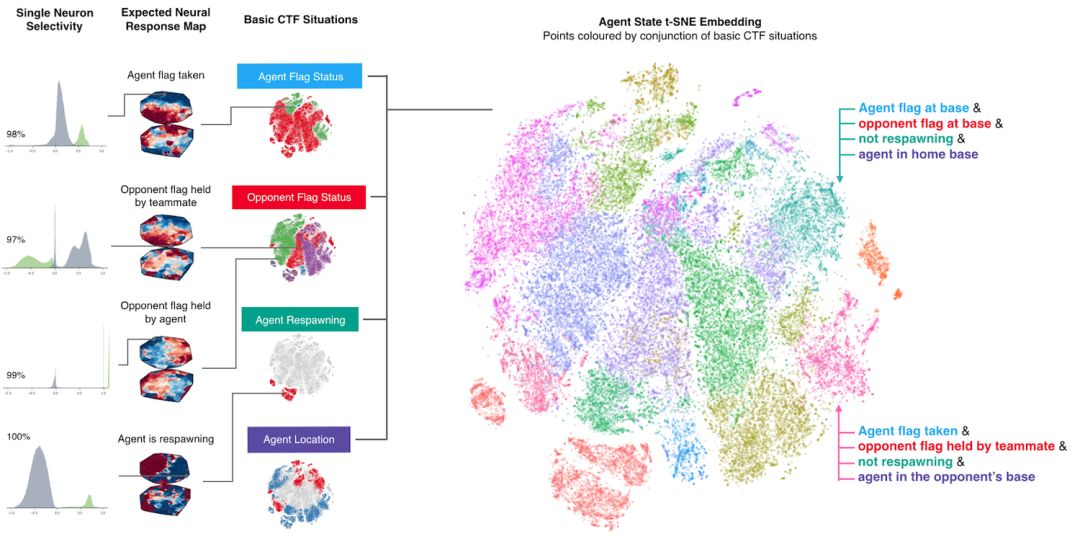
智能體如何表示游戲世界。不同的情形在概念上對(duì)應(yīng)于同一游戲情境,并由智能體相似地表示出來(lái)。訓(xùn)練好的智能體甚至展示了一些人工神經(jīng)元,這些神經(jīng)元直接為特定情況編碼。
智能體從未被告知游戲的規(guī)則,但是它可以學(xué)習(xí)基本的游戲概念,并能有效地建立CTF直覺(jué)。事實(shí)上,我們可以找到一些特定的神經(jīng)元,它們可以直接編碼一些最重要的游戲狀態(tài),比如當(dāng)智能體的旗子被奪走時(shí)激活的神經(jīng)元,或者當(dāng)它的隊(duì)友奪到對(duì)方的旗子時(shí)激活的神經(jīng)元。我們?cè)谡撐闹羞M(jìn)一步分析了智能體對(duì)記憶和視覺(jué)注意力的使用。
除了這種豐富的表示,智能體還會(huì)如何行動(dòng)呢?首先,我們注意到這些智能體的反應(yīng)時(shí)間非常快,tagging也非常準(zhǔn)確,這可以解釋為它們的性能。但是,通過(guò)人為地降低tagging的準(zhǔn)確度和反應(yīng)時(shí)間,我們發(fā)現(xiàn)這只是它們成功的因素之一。
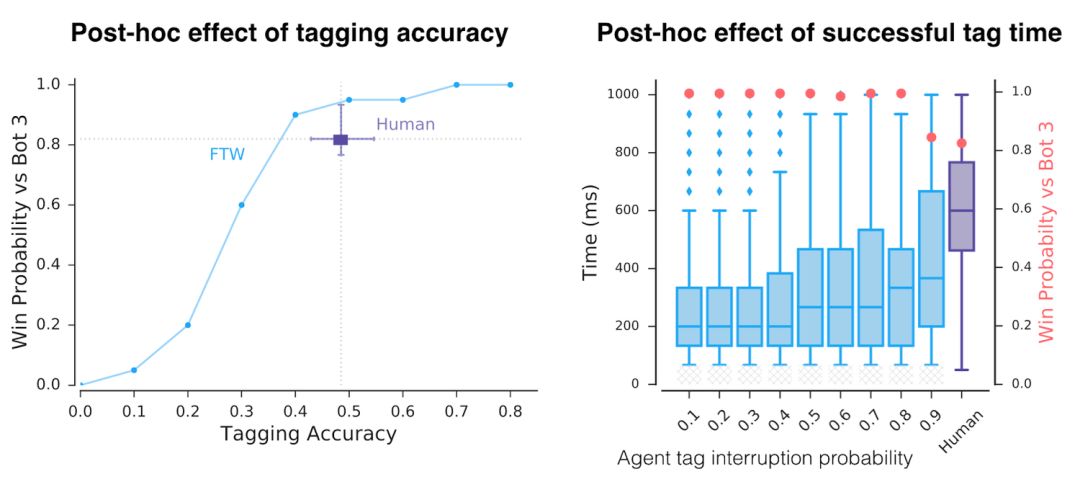
訓(xùn)練后人為地降低了智能體的tagging精度和tagging反應(yīng)時(shí)間。即使在具有于人類相當(dāng)?shù)臏?zhǔn)確度和反應(yīng)時(shí)間下,智能體的性能仍高于人類。
通過(guò)無(wú)監(jiān)督學(xué)習(xí),我們建立了智能體和人類的原型行為( prototypical behaviours),發(fā)現(xiàn)智能體實(shí)際上學(xué)習(xí)了類似人類的行為,例如跟隨隊(duì)友并在對(duì)手的基地扎營(yíng)。

訓(xùn)練好的智能體表現(xiàn)出來(lái)的自動(dòng)發(fā)現(xiàn)行為的3個(gè)例子。
這些行為出現(xiàn)在訓(xùn)練過(guò)程中,通過(guò)強(qiáng)化學(xué)習(xí)和群體層面的進(jìn)化,一些行為——比如跟隨隊(duì)友——隨著智能體學(xué)會(huì)以更加互補(bǔ)的方式合作而減少。
左上方顯示的是30個(gè)智能體在訓(xùn)練和發(fā)展過(guò)程中的Elo等級(jí)分。右上角顯示了這些進(jìn)化事件的遺傳樹(shù)( genetic tree)。下方的圖表顯示了整個(gè)智能體訓(xùn)練過(guò)程中知識(shí)的發(fā)展,一些內(nèi)部獎(jiǎng)勵(lì),以及行為概率。
總結(jié)和展望
最近,研究界在復(fù)雜游戲領(lǐng)域做出了非常令人印象深刻的工作,例如星際爭(zhēng)霸2和Dota 2。我們的這篇論文聚焦于《雷神之錘III競(jìng)技場(chǎng)》的奪旗模式,它的研究貢獻(xiàn)是具有普遍性的。我們很希望看到其他研究人員在不同的復(fù)雜環(huán)境中重建我們的技術(shù)。未來(lái),我們還希望進(jìn)一步改進(jìn)目前的強(qiáng)化學(xué)習(xí)和群體訓(xùn)練方法。總的來(lái)說(shuō),我們認(rèn)為這項(xiàng)工作強(qiáng)調(diào)了多智能體訓(xùn)練對(duì)促進(jìn)人工智能發(fā)展的潛力:利用多智能體訓(xùn)練的自然設(shè)置,并促進(jìn)強(qiáng)大的、甚至能與人類合作的智能體的開(kāi)發(fā)。
-
人工智能
+關(guān)注
關(guān)注
1792文章
47404瀏覽量
238909 -
智能體
+關(guān)注
關(guān)注
1文章
154瀏覽量
10593 -
DeepMind
+關(guān)注
關(guān)注
0文章
130瀏覽量
10881
原文標(biāo)題:【DOTA之后新里程碑】DeepMind強(qiáng)化學(xué)習(xí)重大突破:AI在多人射擊游戲完勝人類!
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
深度學(xué)習(xí)在自然語(yǔ)言處理方面的研究進(jìn)展
未來(lái)的AI 深挖谷歌 DeepMind 和它背后的技術(shù)
介紹多智能體系統(tǒng)的解決方案以及應(yīng)用
華為公司在3G專利方面的進(jìn)展
機(jī)器學(xué)習(xí)簡(jiǎn)單運(yùn)用方面的基礎(chǔ)知識(shí)

袁進(jìn)輝:分享了深度學(xué)習(xí)框架方面的技術(shù)進(jìn)展
意法半導(dǎo)體展示其在功率GaN方面的研發(fā)進(jìn)展
谷歌在量子計(jì)算機(jī)學(xué)習(xí)任務(wù)方面取得新進(jìn)展
谷歌、DeepMind重磅推出PlaNet 強(qiáng)化學(xué)習(xí)新突破
DeepMind 綜述深度強(qiáng)化學(xué)習(xí) 智能體和人類相似度竟然如此高
DeepMind阿爾法被打臉,華為論文指出多項(xiàng)問(wèn)題

多智能體路徑規(guī)劃研究綜述
內(nèi)存計(jì)算IMC用于人工智能加速方面的研究進(jìn)展
黑芝麻智能在BEV感知方面的研發(fā)進(jìn)展
語(yǔ)言模型做先驗(yàn),統(tǒng)一強(qiáng)化學(xué)習(xí)智能體,DeepMind選擇走這條通用AI之路






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論