 原因分析:CPU拓撲差異導致Unixbench分數異常
原因分析:CPU拓撲差異導致Unixbench分數異常
本文通過實驗論證:Unixbench的Pipe-based Context Switching用例受操作系統調度算法的影響波動很大,甚至出現了虛擬機跑分超過物理機的情況。在云計算時代,當前的Unixbench已不能真實地反映被測系統的真實性能,需要針對多核服務器和云計算環境進行完善。
簡單的說,視操作系統多核負載均衡策略的差異,該用例可能表現出兩種截然不同的效果:
1?在惰性的調度策略環境下,測試得分較高,但是會導致系統中任務調度延遲,最終可能引起業務性能抖動。例如,在視頻播放、音頻處理的業務環境中,引起視頻卡頓、音頻視頻不同步等問題。
2?在積極的調度策略環境下,測試得分偏低,但是系統中任務運行實時性更高,業務運行更流暢。
后文將詳細說明Pipe-basedContext Switching用例的設計原理,測試其在不同系統中的運行結果,并提出測試用例改進建議。
1測試背景
近期,團隊在進行服務器選型的時候,需要對兩款服務器進行性能評估,其中一款服務器采用64核Xeon CPU,另一臺則采用16核Atom CPU。詳細配置信息如下:
| 指標名稱 | Xeon服務器 | Atom服務器 |
| Architecture | x86_64 | x86_64 |
| CPUs | 64 | 16 |
| Threads per core | 2 | 1 |
| Core(s) per socket | 16 | 16 |
| Socket(s) | 2 | 1 |
| NUMA node(s) | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz | Intel(R) Atom(TM) CPU C3958 @ 2.00GHz |
| CPU MHz | 2499.902 | 1999.613 |
| BogoMIPS | 4993.49 | 3999.22 |
| L1d cache | 32K | 24K |
| L1i cache | 32K | 32K |
| L2 cache | 256K | 2048K |
| L3 cache | 40960K | None |
根據硬件廠商的評測,Xeon服務器的綜合性能是Atom服務器的3倍。
我們采用了久負盛名的Unixbench性能測試套件,為我們最終的選擇提供參考。
Xeon的性能碾壓Atom是毋庸置疑的,畢竟Atom 更專注于功耗而不是性能,Atom服務器甚至沒有3級緩存,并且StoreBuffer、Message Queue的深度更低,流水線級數更少。
出于業務需求,在整個測試過程中我們更關注單核的性能。為了排除軟件的影響,兩臺服務器均安裝Centos 7操作系統。
測試命令很簡單,在控制臺中執行如下命令:
./Run -c 1 -v
執行時間比較久,我們可以到一邊去喝點燒酒。一杯燒酒下肚,神清氣爽:-)可以看看結果是否符合咱們的預期:
| 指標名稱 | Xeon服務器 | Atom服務器 |
| Dhrystone 2 using register variables | 2610.1 | 1283.7 |
| Double-Precision Whetstone | 651.2 | 489.4 |
| Execl Throughput | 447.9 | 361.5 |
| File Copy 1024 bufsize 2000 maxblocks | 2304.5 | 955.0 |
| File Copy 256 bufsize 500 maxblocks | 1494.5 | 711.2 |
| File Copy 4096 bufsize 8000 maxblocks | 4475.9 | 1396.2 |
| Pipe Throughput | 1310.9 | 614.4 |
| Pipe-based Context Switching | 428.4 | 339.8 |
| Process Creation | 461.7 | 159.6 |
| Shell Scripts (1 concurrent) | 1438.8 | 326.7 |
| Shell Scripts (8 concurrent) | 5354.5 | 789.8 |
| System Call Overhead | 2237.0 | 930.1 |
| System Benchmarks Index Score | 1390.9 | 588.4 |
總分整體符合預期:Xeon服務器單核性能是Atom服務器的2.36倍(1390/588.4)
但是,這里出現了一個異常,細心的讀者應該已經發現:Pipe-based Context Switching測試用例的結果比較反常!從上表可以看出,無論是總分還是單項分數,Xeon服務器均遠遠超過Atom服務器。其中也包括Pipe Throughput這項用例。然而“Pipe-based Context Switching”這項指標顯得有點與眾不同:在這項指標中,Xeon服務器的優勢并不明顯,僅領先25%左右。
為了排除測試誤差,我們反復進行了幾次測試,均發現同樣的規律。“Pipe-based Context Switching”項的分數差異并不明顯,沒有體現出Xeon服務器的性能優勢。
這一問題引起了我們的興趣,Unixbench這樣的權威測試軟件的結果居然和廠商宣稱的出入這么大。為了找出原因,我們使用其他測試環境,進行了一系列的對比測試。首先,我們找了更多物理機進行對比分析。
1.1物理機對比測試
為此,我們使用另一組服務器進行對比測試,其型號分別為:HP ProLiantDL360p Gen8?DELL PowerEdge R720xd。配置如下:
| 指標名稱 | HP ProLiant DL360p Gen8 | DELL PowerEdge R720xd |
| Architecture | x86_64 | x86_64 |
| CPUs | 24 | 32 |
| Threads per core | 2 | 2 |
| Core(s) per socket | 6 | 16 |
| Socket(s) | 2 | 2 |
| NUMA node(s) | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2630 0 @ 2.30GHz | Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz |
| CPU MHz | 1200.000 | 2300.000 |
| BogoMIPS | 4594.05 | 4615.83 |
| L1d cache | 32K | 32K |
| L1i cache | 32K | 32K |
| L2 cache | 256K | 256K |
| L3 cache | 15360K | 20480K |
分別在兩臺服務器的控制臺中輸入如下命令,單獨對“Pipe-based Context Switching”用例進行測試:
./Run index2 -c1
得到該測試項的分數為:
| 指標名稱 | ProLiant DL360p Gen8 | PowerEdge R720xd |
| Pipe-based Context Switching | 381.4 | 432.1 |
測試結果與上面相似,硬件參數明顯占優的DELLL跑分僅領先HP不到20%:-(
1.2物理機VS虛擬機
測試似乎陷入了迷途,然而我們一定需要將加西亞的信送到目的地,并且堅信“柳暗花明又一村”的那一刻終究會到來。
為此,我們使用三組云虛擬機來進行測試。這三組虛擬機配置如下:
| 指標名稱 | 虛擬機A | 虛擬機B | 虛擬機C |
| Architecture | x86_64 | x86_64 | x86_64 |
| CPUs | 4 | 4 | 4 |
| Threads per core | 2 | 1 | 1 |
| Core(s) per socket | 2 | 4 | 4 |
| Socket(s) | 1 | 1 | 1 |
| NUMA node(s) | 1 | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz | Intel(R) Xeon(R) CPU E5-26xx v4 | Intel(R) Xeon(R) CPU E5-2676 v3 @2.40 GHz |
| CPU MHz | 2494.222 | 2394.454 | 2400.102 |
| BogoMIPS | 4988.44 | 4788.90 | 4800.07 |
| L1d cache | 32K | 32K | 32k |
| L1i cache | 32K | 32K | 32k |
| L2 cache | 256K | 4096K | 256K |
| L3 cache | 40960K | none | 30720K |
這三款虛擬機與此前的物理機參數相差不大,如果不出意外的話,分數應當介于300~400之間。
然而測試結果出人意料,以至于筆者的鏡片摔了一地:
| 指標名稱 | 虛擬機A | 虛擬機B | 虛擬機C |
| Pipe-based Context Switching | 109.4 | 589.1 | 105.1 |
特別令人吃驚的是:第二組虛擬機的測試分數,竟然是物理主機的1.5倍,并且是第一組虛擬機和第三組虛擬機的5.4倍。
1.3單核和多核對比測試
為此,我們認真分析不同系統中的CPU占用率。發現一個特點:在Pipe-based Context Switching用例運行期間,在得分高的環境中,兩個context線程基本上運行在同一CPU上。而在得分低的環境中中,兩個context線程則更多的運行在不同的CPU上。這說明:測試結果差異可能與Guest OS中的調度算法及CPU負載均衡策略有關。
我們不得不啟用了排除法,先看單核和多核之間的差異。
為了驗證猜想是否正確,我們臨時修改了Guest OS中內核調度算法。修改原理是:在喚醒線程時,不管其他CPU核是否空閑,優先將被喚醒任務調度到當前CPU中運行。這樣的調度算法,其缺點是:被喚醒任務將不能立即運行,必須等待當前線程釋放CPU后才能獲得CPU,這將導致被喚醒線程的實時性較弱。
經過測試,在打上了Linux內核調度補丁的系統中,Pipe-based Context Switching在虛擬機和物理機上,得分大大提升。實際測試的結果如下:
| 指標名稱 | 虛擬機A |
| Pipe-based Context Switching | 530.2 |
很顯然,我們不能將上述補丁直接應用到生產環境中,因為該補丁會影響任務運行的實時性。因此我們將Linux內核調度補丁回退,并修改“Pipe-based ContextSwitching”測試用例的代碼,強制將context線程綁定到CPU 0中運行,這樣可以避免Guest OS中的調度算法及CPU負載均衡算法的影響。測試結果如下:
| 指標名稱 | 虛擬機A | 虛擬機B | 虛擬機C |
| Pipe-based Context Switching | 761.0 | 953.7 | 675.3 |
我們再次修改“Pipe-based Context Switching”測試用例的代碼,強制將context線程分別綁定到CPU 0和CPU 1中運行,這樣也可以避免Guest OS中的調度算法及CPU負載均衡算法的影響。測試結果如下:
| 指標名稱 | 虛擬機A | 虛擬機B | 虛擬機C |
| Pipe-based Context Switching | 109.1 | 133.6 | 105.1 |
可以看到,應用了新的“Pipe-basedContext Switching”補丁之后,所有測試結果都恢復了正常,離真相越來越近了。
2原因分析: CPU拓撲差異導致Unixbench分數異常
通過前面針對“Pipe-based Context Switching”單實例用例的測試,帶給我們如下疑問:
為什么在該用例中,虛擬機B得分接近600,遠高于虛擬機A、虛擬機C,甚至高于虛擬機A所在的物理機?
為了分析清楚該問題,我們分析了Pipe-based Context Switching用例, 這個用例的邏輯是:測試用例創建一對線程A/B,并創建一對管道A/B。線程A寫管道,線程B讀A管道;并且線程B寫B管道,線程A程讀B管道。兩個線程均同步執行。
經過仔細分析,虛擬機A和虛擬機B在該用例上的性能差異的根本原因是:在虛擬機環境下,底層Host OS向Guest OS透傳的cpu拓撲不同,導致虛擬機系統中的調度行為不一致, 最終引起很大的性能差異。其中虛擬機A是按照Host主機的實際情況,將真實的CPU拓撲傳遞給Guest OS。而虛擬機B的主機則沒有將真實的物理主機CPU拓撲傳遞給Guest OS。這會導致虛擬機內所見到的CPU拓撲和共享內存布局有所不同。
在真實的物理服務器上,每個物理核會有各自的FLC和MLC,同一個Core上的CPU共享LLC。這樣的CPU拓撲允許同一Core上的CPU之間更積極的進行線程遷移,而不損失緩存熱度,并且能夠提升線程運行的實時性。這個特性,更利于視頻播放這類實時應用場景。
下圖是虛擬機A和虛擬機B中看到的CPU視圖:
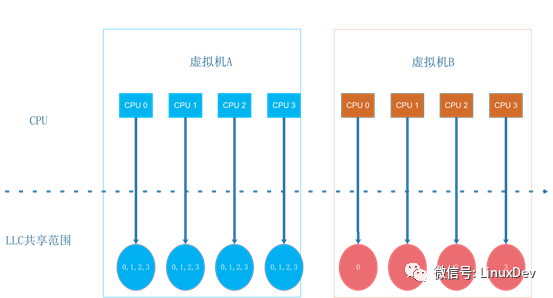
拓撲結構的差異地方在LLC的共享方式,虛擬機A使用的拓撲結構與物理機一致,同一個Core內CPU共享LLC。而虛擬機B的配置是同一個Core內CPU不共享LLC。不共享LLC的場景下,Linux將每個CPU在LLC層次的調度域設置為空。這樣,虛擬機B的Guest OS會認為同一物理CPU內的兩個超線程是兩個獨立的CPU,處于不同的域之間(這與實際的物理機配置不一致),因此其負載均衡策略會更保守一些。喚醒一個進程時,內核會為其選擇一個運行的目標CPU,linux的調度策略會考慮親和性(提高cache命中率)和負載均衡。在Linux 3.10這個版本下,內核會優先考慮親和性,親和性的目標是優先選取同一個調度域內的CPU。虛擬機A共享LLC,所有的CPU都在同一個調度域內,內核為其選擇的是同一調度域內的空閑CPU。而虛擬機B因為LLC層次的調度域為空,在進入親和性選擇時,無法找到同一個調度域內的其它空閑CPU,這樣就直接返回了正在進行喚醒操作的當前CPU。
最終,在虛擬機B中,除了偶爾進行的CPU域間負載均衡以外,兩個測試線程基本上會一直在同一個CPU上運行。而虛擬機A的兩個進程會并發的運行在兩個不同的CPU上。
這一特征下的運行時間軸如下:
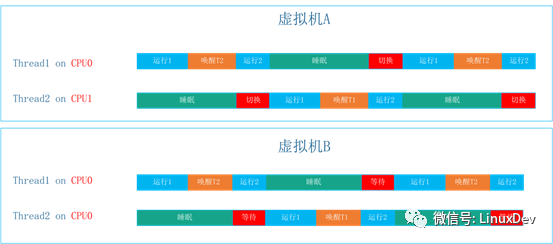
虛擬機B場景引入的開銷是喚醒和等待運行開銷,虛擬機A場景引入的開銷是喚醒和切換運行開銷。
在正常的工作負載下面,進程運行的時間會遠大于進程切換的開銷,而Pipe-based Context Switching用例模擬的是一個極限場景,一個線程在喚醒對端到進入睡眠之間只執行很簡單的操作,實際等待運行的開銷遠小于切換運行的開銷。
此外,在虛擬化場景下,兩種方式喚醒操作中也存在差異,在虛擬機A這個場景下,喚醒的開銷也遠大于虛擬機B場景中的喚醒開銷。最終出現虛擬機B上該用例的得分遠高于虛擬機A、虛擬機C,甚至高于物理機上的得分。
為了進一步驗證我們的分析是否正確。我們在HOST OS中,分別向虛擬機A的GuestOS和虛擬機B的Guest OS按照不同方式傳遞CPU拓撲。測試發現:在同樣的CPU拓撲結構下,二者的測試分數是一致的。換句話說,導致該項測試分數差異的原因,在于不同的HOST OS向Guest OS傳遞的CPU拓撲存在差異,進而導致Guest OS中任務調度行為的差異。
3 結論:Unixbench需要針對多核服務器和云環境進行優化
unixbench的Pipe-based Context Switching用例受操作系統調度算法的影響比較大。視操作系統多核負載均衡策略的差異,可能表現出兩種截然不同的效果:
1?在多核負載均衡策略不積極的系統中,測試線程更多的運行在同一個CPU中,線程之間的切換開銷更低。因此測試得分更高,但是會導致系統中任務調度延遲。在實時性要求比較高的系統中,這會引起業務抖動。例如,在視頻播放、音頻處理的業務環境中,這可能引起視頻卡頓、音頻視頻不同步等問題。
2?在多核負載均衡策略更積極的系統中,測試線程更多的運行在不同的CPU中,線程之間的切換開銷更高。因此測試分值更低,但是系統中任務調度延遲更低,業務的性能不容易產生波動。
換句話說:當前的Unixbench已不能真實地反映被測系統的真實性能,需要針對多核服務器和云計算環境進行完善。
4 修改建議
我們建議調整unixbench測試用例,將測試用例的線程綁定到Guest OS的CPU上。這樣就可以避免受到Guest OS調度策略和CPU負載均衡策略的影響。具體來說,有兩種方法:
1?將context1和context2兩個線程綁定在同一個CPU核上面。這樣可以反應出被測試系統在單核上的執行性能。
2?將context1和context2兩個線程分別綁定到不同CPU核上面。這樣可以反應出被測試系統在單核的執行性能,以及多核之間的核間通信性能。
(完)
-
cpu
+關注
關注
68文章
10855瀏覽量
211615 -
云計算
+關注
關注
39文章
7776瀏覽量
137369 -
服務器
+關注
關注
12文章
9129瀏覽量
85350
原文標題:燕青: Unixbench 測試套件缺陷深度分析
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
CYT2B7 SFlash被異常修改的原因?
【NanoPi NEO試用體驗】利用unixbench進行性能評估
導致STM32進入HardFault異常的原因
導致致命異常錯誤和無效頁錯誤的原因是什么?
導致MCU出現功能嚴重異常的幾個原因分析
CPU 拓撲中的SMP架構
分享排查Linux系統CPU占用的一個Shell腳本

拓撲視圖與實際拓撲結構間的差異





 工商網監
工商網監
評論