

編者按:對圖像中的文字進行識別已經有很多種方法了,但是大多是水平方向上的識別,一旦有了旋轉角度,這些方法可能就“失靈”了。來自復旦大學和中國科學院的幾位研究人員就提出了一種框架,可以識別圖像中經過旋轉的文本。以下為論智對論文的編譯。
摘要
本文介紹了一種全新的基于旋轉的框架,能對自然場景中任意方向的文字進行檢測辨認。我們提出了Rotation Region Proposal Networks(RRPN),用于生成傾斜的框架,同時還帶有圖像旋轉角度的信息。之后,這些信息會適應邊界框,從而能更精確地在不同方向上確定文本區域。Rotation Region-of-Interest(RRoI)池化層是將隨機方向的候選窗口映射到文本區域分類器的特征映射上。
整個框架是基于區域候選框的結構上搭建的,它與之前的文本檢測系統相比,能保證在隨機方向的文本檢測上有更高的計算效率。我們在三種現實場景中對該框架進行了實驗,發現了相較于之前的方法它所表現出的效率。
背景介紹
文本檢測是CV領域一大熱門話題,它的目標是在給定圖像中定位文字區域,這項任務是很多復雜任務的前提,例如視覺分類、視頻分析和其他移動應用。雖然已有很多商業產品落地,但是由于場景的復雜性,自然場景下的文字識別仍然受到很多限制,例如光線不均、圖片模糊、角度扭曲、方向不同等等。而本文正是關注現實生活中不水平的文字區域。
最近一些研究提出了針對隨機方向文本的檢測方法,總的來說,這些方法大致包括兩個步驟:分割網絡(全卷積網絡)以及用于傾斜候選框的幾何方法。然而,對圖像進行分割通常很耗時,并且一些系統需要多次后處理才能生成最終的文本區域候選框,所以并不如直接的檢測網絡高效。
在這篇論文中,我們提出了一種基于旋轉的方法,和端到端的文本檢測系統,該系統能生成任意方向的候選框。相較于之前的方法,我們的主要成果有:
這次的框架可以用基于候選框區域的方法預測文本線的方向,使候選框能更好地適應文本區域。框架中加入的新元素,例如RRoI池化層和旋轉的候選框都整合到了架構中,保證高效的計算力。
我們還提出了對候選框區域新型的微調方法,提高任意方向文本檢測的性能。
我們將新的框架應用到三種場景數據集上,發現它比此前的方法更精確、更高效。
具體框架
首先,框架的整體結構如下圖所示:
框架的前部是VGG-16的卷積層,其中由兩部分組成:RRPN和最后一個卷積層的特征映射的復制品。RRPN可以為文本樣本生成隨機方向的候選框,之后會對候選框進行回歸處理以更好地適應文本區域。而從RRPN分出去的兩個圖層是分類層(cls)和回歸層(reg)。
cls的分數和reg中的候選框信息組成了兩個圖層的輸出結果,并且他們的損失通過計算總結構會形成一個多任務的損失函數。之后,RRoI池化層會扮演一個最大池化層的角色,將RRPN上任意方向的文本候選框投射到特征映射上。
最后,兩個全卷積層結合成一個分類器,具有RRoI特征的區域被分為文本或者背景。
在訓練階段,真實的文本區域用五個元組表示旋轉后的邊界框,分別是(x, y, h, w, θ),(x, y)代表邊界框幾何中心的坐標,h和w分別代表邊界框較短和較長的兩邊,θ表示夾角。
旋轉連接點(anchors)
傳統的連接點利用比例尺和長寬比參數表示,通常對現實中的文本檢測并不有效。所以我們通過調整設計了旋轉連接點(R-anchors)。具體表示可看下圖:
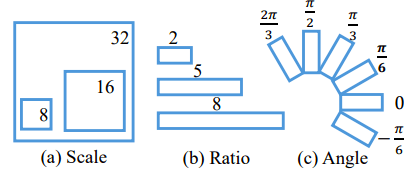
其中有六個不同的旋轉方向,是綜合考慮覆蓋和計算效率之后得出的結果。其次,由于文本區域經常有特殊的形狀,長寬比改成了1:2、1:5、1:8,以覆蓋更寬的文本。
學習旋轉候選框
R-anchors生成后,為了執行網絡學習,就需要對R-anchors進行采樣。候選框的損失函數形成了多任務損失,定義為:
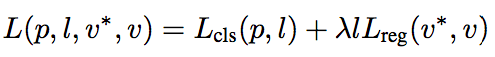
其中l是類別標簽的表示器,參數p時softmax函數計算出的類別概率,v表示文本標簽的預測元組,v*表示真實數值。
下圖可以看到經過回歸后的圖像與未回歸的對比:
(a)是輸入的圖像,(b)是沒有經過回歸處理的方向和連接點,(c)是經過處理的點
白線的方向就表示R-anchors的方向,白線的長短表示連接點對文字的反饋。
下圖是不同多任務損失值的對比:
實驗效果
我們分別在三個數據集上進行了實驗:MSRA-TD500、ICDAR2015和ICDAR2013。三個數據集都是文本檢測常用的數據集。首先我們對比了旋轉和水平的候選框:
結果顯示,基于旋轉的方法能更精確地確定文字區域,不會包含太多的背景,這說明在框架中加入旋轉策略的有效性。但是雖然檢測效率有所提高,在MSRA-TD500中仍有檢測失敗的案例:
在不平衡的光線下(a)、非常小的字體上(b)以及過長的文本上(c)都會出現檢測失敗的情況
但最終在三種數據集上的表現還是很不錯的:
-
圖像
+關注
關注
2文章
1092瀏覽量
41008 -
分類器
+關注
關注
0文章
152瀏覽量
13398 -
數據集
+關注
關注
4文章
1222瀏覽量
25270
原文標題:復旦&中科院成果:對任意方向的文字進行識別
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
一種基于圖像平移的目標檢測框架
一種專門用于檢測小目標的框架Dilated Module
如何對運動中的車輪進行測定
一種名片圖像的文字區塊分割方法
一種改進的CAMShift跟蹤算法及人臉檢測框架
一種新型分割圖像中人物的方法,基于人物動作辨認

如何提取和檢測視頻中的文字?數字視頻中文字的檢測提取技術的分析
一種硅片旋轉甩干裝置,它的應用優勢是什么
如何對typo 進行檢測和糾正
一種基于HOG+SVM的行人檢測算法
一種適用于動態場景的多層次地圖構建算法
OpenVINO場景文字檢測與文字識別教程

一種利用幾何信息的自監督單目深度估計框架





 工商網監
工商網監

評論