") 對(duì)常用的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)算法進(jìn)行總結(jié)
對(duì)常用的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)算法進(jìn)行總結(jié)
很多人在學(xué)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的時(shí)候都有一個(gè)感受:所學(xué)的知識(shí)零散、不系統(tǒng),缺乏整體感,這是普遍存在的一個(gè)問題。這篇文章對(duì)常用的機(jī)器學(xué)習(xí)和深度學(xué)習(xí)算法進(jìn)行了總結(jié),整理出它們之間的關(guān)系,以及每種算法的核心點(diǎn),各種算法之間的比較。由此形成了一張算法地圖,以幫助大家更好的理解和記憶這些算法。
下面先看這張圖:
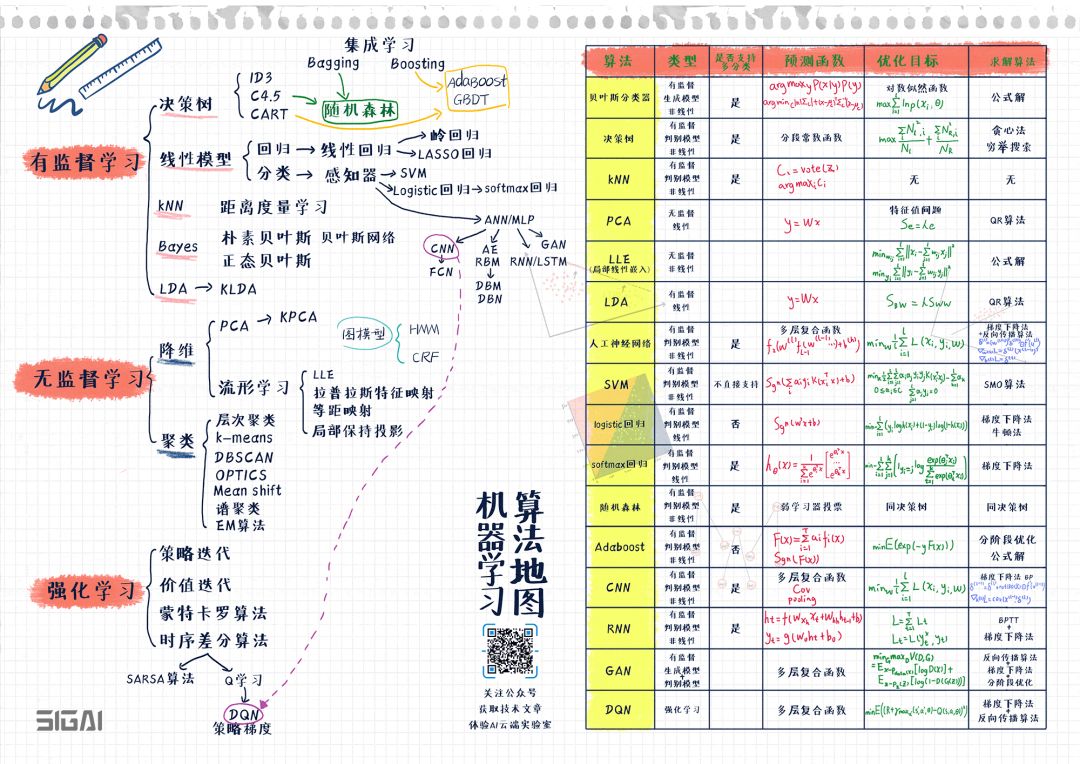
(關(guān)注公眾號(hào)SIGAICN,回復(fù)“算法地圖”,即可獲得高清原圖鏈接)
圖的左半部分列出了常用的機(jī)器學(xué)習(xí)算法與它們之間的演化關(guān)系,分為有監(jiān)督學(xué)習(xí),無監(jiān)督學(xué)習(xí),強(qiáng)化學(xué)習(xí)3大類。右半部分列出了典型算法的總結(jié)比較,包括算法的核心點(diǎn)如類型,預(yù)測函數(shù),求解的目標(biāo)函數(shù),求解算法。
理解和記憶這張圖,對(duì)你系統(tǒng)化的掌握機(jī)器學(xué)習(xí)與深度學(xué)習(xí)會(huì)非常有幫助!
我們知道,整個(gè)機(jī)器學(xué)習(xí)算法可以分為有監(jiān)督學(xué)習(xí),無監(jiān)督學(xué)習(xí),強(qiáng)化學(xué)習(xí)3大類。除此之外還有半監(jiān)督學(xué)習(xí),但我們可以把它歸到有監(jiān)督學(xué)習(xí)中。算法的演變與發(fā)展大多在各個(gè)類的內(nèi)部進(jìn)行,但也可能會(huì)出現(xiàn)大類間的交叉,如深度強(qiáng)化學(xué)習(xí)就是深度神經(jīng)網(wǎng)絡(luò)與強(qiáng)化學(xué)習(xí)技術(shù)的結(jié)合。
根據(jù)樣本數(shù)據(jù)是否帶有標(biāo)簽值(label),可以將機(jī)器學(xué)習(xí)算法分成有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)兩類。如果要識(shí)別26個(gè)英文字母圖像,我們要將每張圖像和它是哪個(gè)字符即其所屬的類型對(duì)應(yīng)起來,這個(gè)類型就是標(biāo)簽值。
有監(jiān)督學(xué)習(xí)(supervised learning)的樣本數(shù)據(jù)帶有標(biāo)簽值,它從訓(xùn)練樣本中學(xué)習(xí)得到一個(gè)模型,然后用這個(gè)模型對(duì)新的樣本進(jìn)行預(yù)測推斷。它的樣本由輸入值x與標(biāo)簽值y組成:
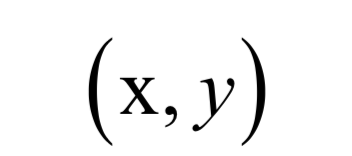
其中x為樣本的特征向量,是模型的輸入值;y為標(biāo)簽值,是模型的輸出值。標(biāo)簽值可以是整數(shù)也可以是實(shí)數(shù),還可以是向量。有監(jiān)督學(xué)習(xí)的目標(biāo)是給定訓(xùn)練樣本集,根據(jù)它確定映射函數(shù):
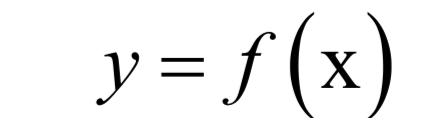
確定這個(gè)函數(shù)的依據(jù)是函數(shù)能夠很好的解釋訓(xùn)練樣本,讓函數(shù)輸出值f(x)與樣本真實(shí)標(biāo)簽值y之間的誤差最小化,或者讓訓(xùn)練樣本集的對(duì)數(shù)似然函數(shù)最大化。這里的訓(xùn)練樣本數(shù)是有限的,而樣本所有可能的取值集合在很多情況下是一個(gè)無限集,因此只能從中選取一部分樣本參與訓(xùn)練。
日常生活中的很多機(jī)器學(xué)習(xí)應(yīng)用,如垃圾郵件分類,手寫文字識(shí)別,人臉識(shí)別,語音識(shí)別等都是有監(jiān)督學(xué)習(xí)。這類問題需要先收集訓(xùn)練樣本,對(duì)樣本進(jìn)行進(jìn)行標(biāo)注,用標(biāo)注好的訓(xùn)練樣本訓(xùn)模型,然后根據(jù)模型對(duì)新的樣本進(jìn)行預(yù)測。
無監(jiān)督學(xué)習(xí)(unsupervised learning)對(duì)沒有標(biāo)簽的樣本進(jìn)行分析,發(fā)現(xiàn)樣本集的結(jié)構(gòu)或者分布規(guī)律。無監(jiān)督學(xué)習(xí)的典型代表是聚類和數(shù)據(jù)降維。
強(qiáng)化學(xué)習(xí)是一類特殊的機(jī)器學(xué)習(xí)算法,它根據(jù)輸入數(shù)據(jù)確定要執(zhí)行的動(dòng)作,在這里。輸入數(shù)據(jù)是環(huán)境參數(shù)。和有監(jiān)督學(xué)習(xí)算法類似,這里也有訓(xùn)練過程中。在訓(xùn)練時(shí),對(duì)于正確的動(dòng)作做出獎(jiǎng)勵(lì),對(duì)錯(cuò)誤的動(dòng)作做出懲罰,訓(xùn)練完成之后就用得到的模型進(jìn)行預(yù)測。
在有監(jiān)督學(xué)習(xí)算法中,我們列出了5個(gè)分支:
(關(guān)注公眾號(hào)SIGAICN,回復(fù)“算法地圖”,即可獲得高清原圖鏈接)
分別是決策樹,貝葉斯,線性模型,kNN,LDA(線性判別分析),集成學(xué)習(xí)。LDA也可以歸類到線性模型中,但因?yàn)樗且环N有監(jiān)督的投影技術(shù),我們單獨(dú)列出。
決策樹是一種基于規(guī)則的方法,它的規(guī)則是通過訓(xùn)練樣本學(xué)習(xí)得到的,典型的代表是ID3,C4.5,以及分類與回歸樹。
集成學(xué)習(xí)是機(jī)器學(xué)習(xí)中一類重要的算法,它通過將多個(gè)簡單的模型進(jìn)行集成,得到一個(gè)更強(qiáng)大的模型,簡單的模型稱為弱學(xué)習(xí)器。決策樹與集成學(xué)習(xí)算法相結(jié)合,誕生了隨機(jī)森林,Boosting這兩類算法(事實(shí)上,Boosting算法的弱學(xué)習(xí)器不僅可以用決策樹,還可以用其他算法)。
線性模型是最大的一個(gè)分支,從它最后衍生除了一些復(fù)雜的非線性模型。如果用于分類問題,最簡單的線性模型是線性回歸,加上L2和L1正則化項(xiàng)之后,分別得到嶺回歸和LASSO回歸。對(duì)于分類問題,最簡單的是感知器模型,從它衍生出了支持向量機(jī),logistic回歸,神經(jīng)網(wǎng)絡(luò)3大分支。而神經(jīng)網(wǎng)絡(luò)又衍生出了各種不同的結(jié)構(gòu)。包括自動(dòng)編碼器,受限玻爾茲曼機(jī),卷積神經(jīng)網(wǎng)絡(luò),循環(huán)神經(jīng)網(wǎng)絡(luò),生成對(duì)抗網(wǎng)絡(luò)等。當(dāng)然,還有其他一些類型的神經(jīng)網(wǎng)絡(luò),因?yàn)槭褂煤苌伲栽谶@里不列出。
kNN算法基于模板匹配的思想,是最簡單的一種機(jī)器學(xué)習(xí)算法,它依賴于距離定義,而距離同樣可以由機(jī)器學(xué)習(xí)而得到,這就是距離度量學(xué)習(xí)。
貝葉斯也是有監(jiān)督學(xué)習(xí)算法中的一個(gè)大分支,最簡單的是貝葉斯分類器,更復(fù)雜的有貝葉斯網(wǎng)絡(luò)。而貝葉斯分類器又有樸素貝葉斯和正態(tài)貝葉斯兩種實(shí)現(xiàn)。
接下來說無監(jiān)督學(xué)習(xí),它可以分為數(shù)據(jù)降維算法和聚類算法兩大類。演變關(guān)系如下圖所示:
(關(guān)注公眾號(hào)SIGAICN,回復(fù)“算法地圖”,即可獲得高清原圖鏈接)
無監(jiān)督的降維算法可以分為線性降維和非線性降維兩大類。前者的典型代表是主成分分析(PCA),通過使用核技術(shù),可以把它擴(kuò)展為非線性的版本。流形學(xué)習(xí)是非線性降維技術(shù)的典型實(shí)現(xiàn),代表性的算法有局部線性嵌入(LLE),拉普拉斯特征映射,等距映射,局部保持投影,它們都基于流形假設(shè)。流形假設(shè)不僅在降維算法中有用,在半監(jiān)督學(xué)習(xí)、聚類算法中同樣有使用。
聚類算法可以分為層次距離,基于質(zhì)心的聚類,基于概率分布的距離,基于密度的聚類,基于圖的聚類這幾種類型。它們從不同的角度定義簇(cluster)。基于質(zhì)心的聚類典型代表是k均值算法。基于概率分布的聚類典型代表是EM算法。基于密度的聚類典型代表是DBSCAN算法,OPTICS算法,Mean shift算法。基于圖的聚類典型代表是譜聚類算法。
強(qiáng)化學(xué)習(xí)是機(jī)器學(xué)習(xí)中的一個(gè)特殊分支,用于決策、控制問題。這類算法的演變關(guān)系如下圖所示:
(關(guān)注公眾號(hào)SIGAICN,回復(fù)“算法地圖”,即可獲得高清原圖鏈接)
整個(gè)強(qiáng)化學(xué)習(xí)的理論模型可以抽象成馬爾可夫決策過程。核心任務(wù)是求解使得回報(bào)最大的策略。如果直接用動(dòng)態(tài)規(guī)劃求解,則有策略迭代和價(jià)值迭代兩類算法。他們都要求有精確的環(huán)境模型,即狀態(tài)轉(zhuǎn)移概率和獎(jiǎng)勵(lì)函數(shù)。如果做不到這一點(diǎn),只能采用隨機(jī)算法,典型的代表是蒙特卡羅算法和時(shí)序差分算法。強(qiáng)化學(xué)習(xí)與深度學(xué)習(xí)相結(jié)合,誕生了深度強(qiáng)化學(xué)習(xí)算法,典型代表是深度Q網(wǎng)絡(luò)(DQN)以及策略梯度算法(策略梯度算法不僅可用神經(jīng)網(wǎng)絡(luò)作為策略函數(shù)的近似,還可以用其他函數(shù))。
下面我們來分別介紹每種算法的核心知識(shí)點(diǎn)以及它們之間的關(guān)系。
有監(jiān)督學(xué)習(xí)
先看有監(jiān)督學(xué)習(xí)算法,它是當(dāng)前實(shí)際應(yīng)用中使用最廣的機(jī)器學(xué)習(xí)算法。進(jìn)一步可以分為分類問題與回歸問題兩大類。前面說過,有監(jiān)督學(xué)習(xí)算法的預(yù)測函數(shù)為:
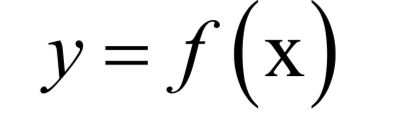
即根據(jù)輸入數(shù)據(jù)x預(yù)測出輸出數(shù)據(jù)y。如果y是整數(shù)的類別編號(hào),則稱為分類問題;如果y是實(shí)數(shù)值,則為回歸問題。
貝葉斯分類器
分類問題中樣本的特征向量取值x與樣本所屬類型y具有因果關(guān)系。因?yàn)闃颖緦儆陬愋蛓,所以具有特征值x。分類器要做的則相反,是在已知樣本的特征向量為x的條件下反推樣本所屬的類別y。根據(jù)貝葉斯公式有:
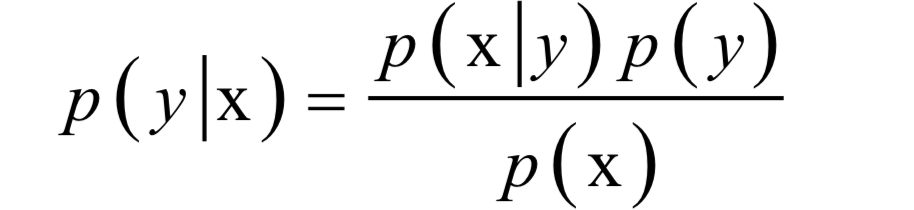
只要知道特征向量的概率分布p(x),每一類出現(xiàn)的概率p(y),以及每一類樣本的條件概率p(x|y),就可以計(jì)算出樣本屬于每一類的概率p(y|x)。如果只要確定類別,比較樣本屬于每一類的概率的大小,找出該值最大的那一類即可。因此可以忽略p(x),因?yàn)樗鼘?duì)所有類都是一樣的。簡化后分類器的判別函數(shù)為:
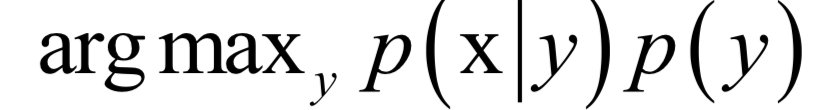
訓(xùn)練時(shí)的目標(biāo)是確定p(x|y)的參數(shù),一般使用最大似然估計(jì)。如果假設(shè)樣本特征向量的各個(gè)分量之間相互獨(dú)立,則稱為樸素貝葉斯分類器。如果假設(shè)特征向量x服從多維正態(tài)分布,則稱為正態(tài)貝葉斯分類器。正態(tài)貝葉斯分類器的預(yù)測函數(shù)為:
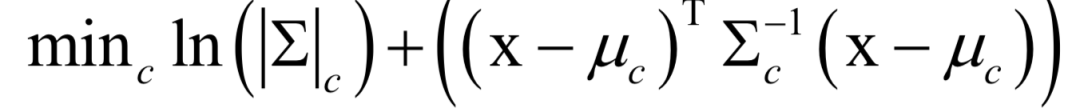
貝葉斯分類器是一種生成模型,是非線性模型,它天然的支持多分類問題。下圖是正態(tài)貝葉斯分類器對(duì)異或問題的分類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
決策樹家族
決策樹是基于規(guī)則的方法,它用一組嵌套的規(guī)則進(jìn)行預(yù)測,在樹的每個(gè)決策節(jié)點(diǎn)處,根據(jù)判斷結(jié)果進(jìn)入一個(gè)分支,反復(fù)執(zhí)行這種操作直到到達(dá)葉子節(jié)點(diǎn),得到?jīng)Q策結(jié)果。決策樹的這些規(guī)則通過訓(xùn)練得到,而不是人工制定的。下圖是決策樹的一個(gè)例子:
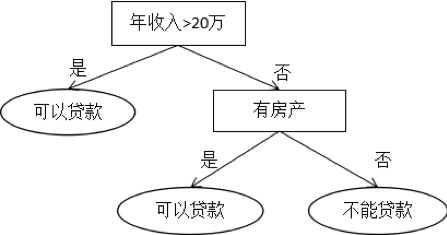
決策樹是一種判別模型,也是非線性模型,天然支持多類分類問題。它既可以用于分類問題,也可以用于回歸問題,具有很好的解釋性,符合人類的思維習(xí)慣。常用的決策樹有ID3,C4.5,分類與回歸樹(CART)等。
分類樹對(duì)應(yīng)的映射函數(shù)是多維空間的分段線性劃分,即用平行于各個(gè)坐標(biāo)軸的超平面對(duì)空間進(jìn)行切分;回歸樹的映射函數(shù)是一個(gè)分段常數(shù)函數(shù)。決策樹是分段線性函數(shù)但不是線性函數(shù),它具有非線性建模的能力。只要?jiǎng)澐值淖銐蚣?xì),分段常數(shù)函數(shù)可以逼近閉區(qū)間上任意函數(shù)到任意指定精度,因此決策樹在理論上可以對(duì)任意復(fù)雜度的數(shù)據(jù)進(jìn)行分類或者回歸。
下圖是決策樹進(jìn)行空間劃分的一個(gè)例子。在這里有紅色和藍(lán)色兩類訓(xùn)練樣本,用下面兩條平行于坐標(biāo)軸的直線可以將這兩類樣本分開(來自SIGAI云端實(shí)驗(yàn)室):
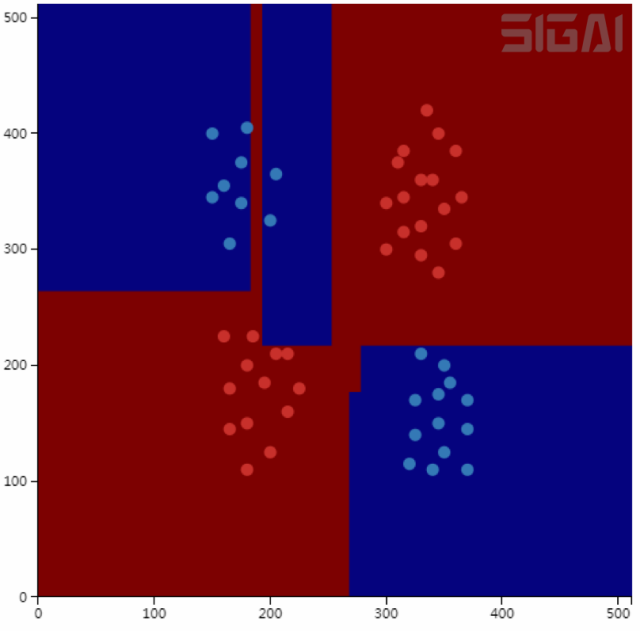
這個(gè)劃分方案對(duì)應(yīng)的決策樹如下圖所示:
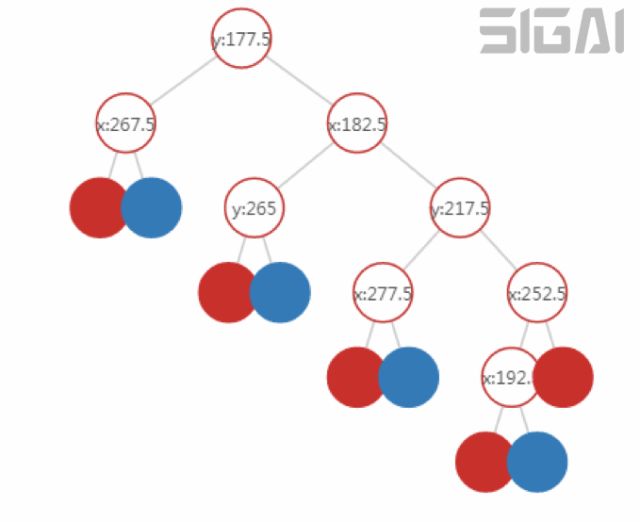
對(duì)于分類與回歸樹,訓(xùn)練每個(gè)節(jié)點(diǎn)時(shí)的目標(biāo)是要讓Gini不純度最小化,這等價(jià)于讓下面的值最大化:
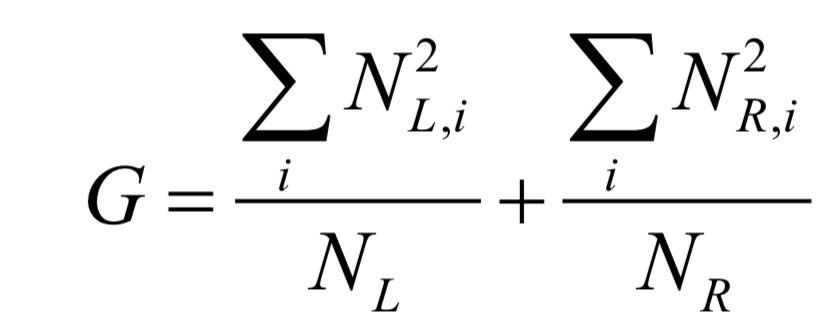
決策樹訓(xùn)練求解時(shí)采用了枚舉搜索和貪婪法的思想,找到的不一定是結(jié)構(gòu)最優(yōu)的樹。如果想要了解決策樹的原理,請(qǐng)閱讀SIGAI之前的公眾號(hào)文章“理解決策樹”。
kNN算法
kNN算法基于以下思想:要確定一個(gè)樣本的類別,可以計(jì)算它與所有訓(xùn)練樣本的距離,然后找出和該樣本最接近的k個(gè)樣本,統(tǒng)計(jì)這些樣本的類別進(jìn)行投票,票數(shù)最多的那個(gè)類就是分類結(jié)果。因?yàn)橹苯颖容^樣本和訓(xùn)練樣本的距離,kNN算法也被稱為基于實(shí)例的算法,這實(shí)際上是一種模板匹配的思想。
下圖是使用k近鄰思想進(jìn)行分類的一個(gè)例子:
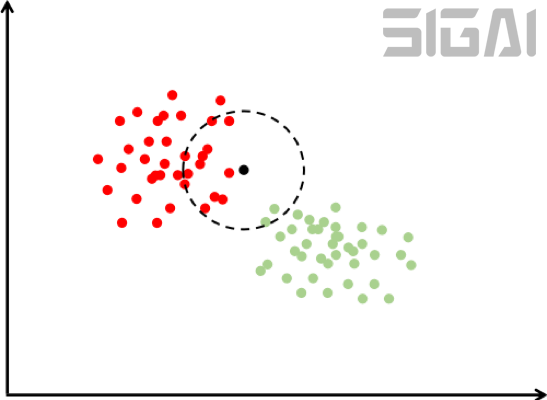
在上圖中有紅色和綠色兩類樣本。對(duì)于待分類樣本即圖中的黑色點(diǎn),我們尋找離該樣本最近的一部分訓(xùn)練樣本,在圖中是以這個(gè)矩形樣本為圓心的某一圓范圍內(nèi)的所有樣本。然后統(tǒng)計(jì)這些樣本所屬的類別,在這里紅色點(diǎn)有12個(gè),圓形有2個(gè),因此把這個(gè)樣本判定為紅色這一類。上面的例子是二分類的情況,我們可以推廣到多類,k近鄰算法天然支持多類分類問題,它是一種判別模型,也是非線性模型。下圖是kNN算法對(duì)異或問題的分類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
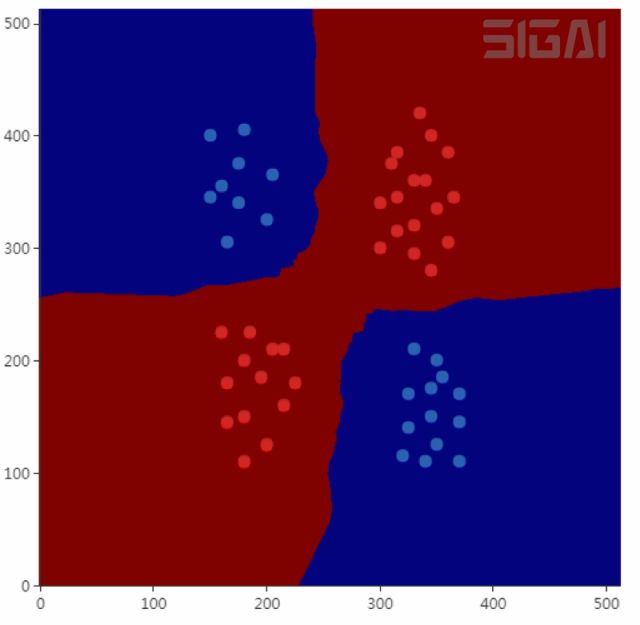
kNN算法依賴于樣本距離值,常用的距離有歐氏距離,Mahalanobis距離等。這些距離定義中的參數(shù)可以通過學(xué)習(xí)得到,如Mahalanobis距離中的矩陣S,這稱為距離度量學(xué)習(xí)。
線性模型家族
線性模型的預(yù)測函數(shù)是線性函數(shù),既可以用于分類問題,也可以用于回歸問題,這是機(jī)器學(xué)習(xí)算法中的一個(gè)龐大家族。從線性模型中衍生出了多種機(jī)器學(xué)習(xí)算法,對(duì)于回歸問題問題,有嶺回歸,LASSO回歸;對(duì)于分類問題,有支持向量機(jī),logistic回歸,softmax回歸,人工神經(jīng)網(wǎng)絡(luò)(多層感知器模型),以及后續(xù)的各種深度神經(jīng)網(wǎng)絡(luò)。
對(duì)于分類問題,線性模型的預(yù)測函數(shù)為:
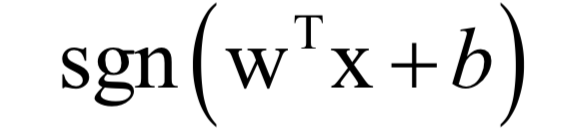
其中sgn是符號(hào)函數(shù)。最簡單的線性分類器是感知器算法,它甚至無法解決經(jīng)典的異或問題,不具有太多的實(shí)用價(jià)值。
對(duì)于回歸問題,線性模型的預(yù)測函數(shù)為:
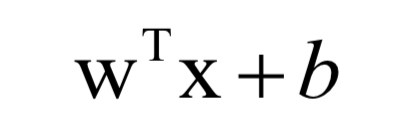
訓(xùn)練時(shí)的目標(biāo)是最小化均方誤差:
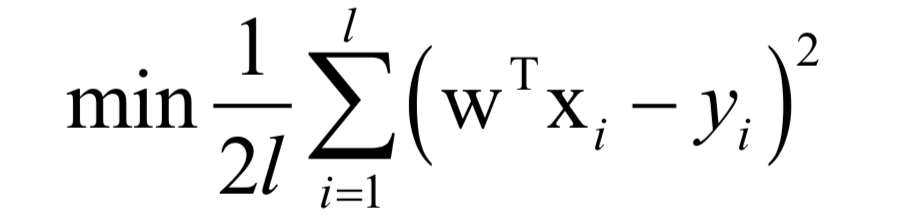
可以證明,這是一個(gè)凸優(yōu)化問題,可以得到全局極小值。求解時(shí)可以采用梯度下降法或者牛頓法。
嶺回歸是線性回歸的L2正則化版本,訓(xùn)練時(shí)求解的問題為:
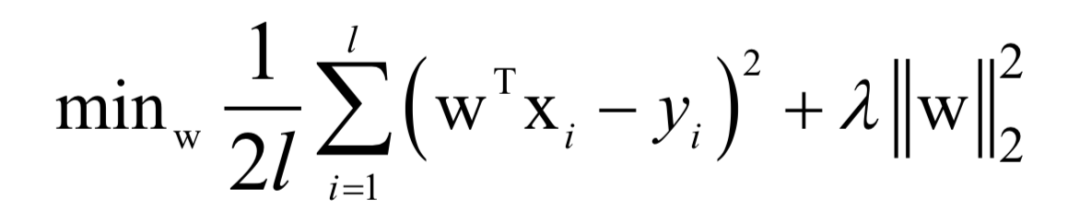
如果系數(shù)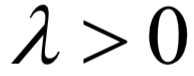 ,這個(gè)問題是一個(gè)嚴(yán)格凸優(yōu)化問題,可用用梯度下降法,牛頓法求解。
,這個(gè)問題是一個(gè)嚴(yán)格凸優(yōu)化問題,可用用梯度下降法,牛頓法求解。
LASSO回歸是線性回歸的L1正則化版本,訓(xùn)練時(shí)求解的問題為:
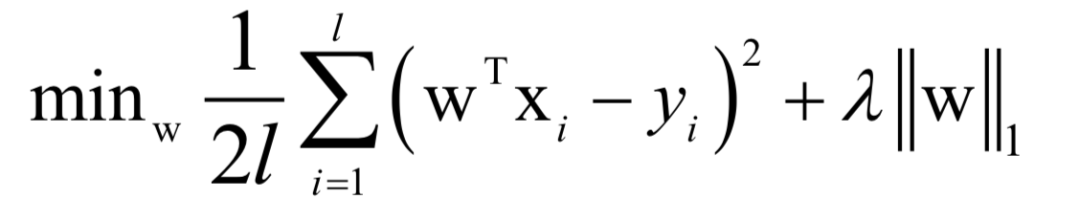
同樣的,這是一個(gè)凸優(yōu)化問題,可以用梯度下降法和牛頓法求解。
線性判別分析(LDA)是一種有監(jiān)督的線性投影技術(shù),它尋找向低維空間的投影矩陣W,樣本的特征向量x經(jīng)過投影之后得到的新向量y:
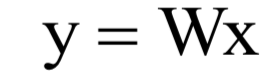
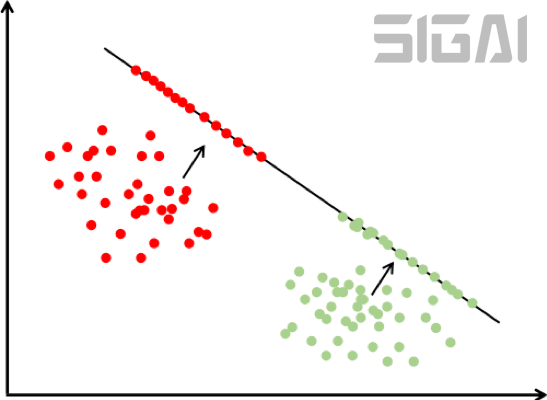
投影的目標(biāo)是同一類樣投影后的結(jié)果向量差異盡可能小,不同類的樣本差異盡可能大。直觀來看,就是經(jīng)過這個(gè)投影之后同一類的樣本進(jìn)來聚集在一起,不同類的樣本盡可能離得遠(yuǎn)。下圖是這種投影的示意圖:
訓(xùn)練時(shí)的求解目標(biāo)是最大化類間差異與類內(nèi)差異的比值:
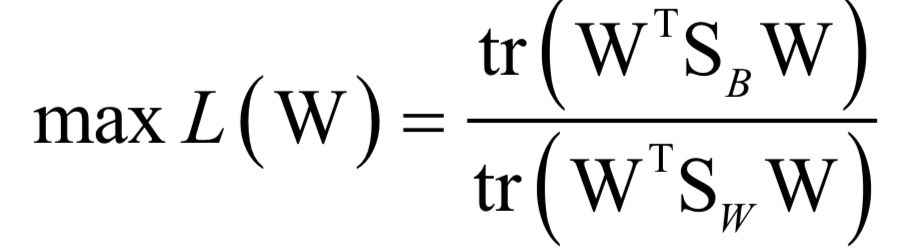
最后歸結(jié)為求解矩陣的特征值和特征向量:
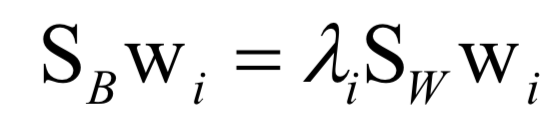
如果我們要將向量投影到c-1維,則挑選出最大的c-1個(gè)特征值以及它們對(duì)應(yīng)的特征向量,組成矩陣W。線性判別分析不能直接用于分類問題,它只是完成投影,投影之后還需要用其他算法進(jìn)行分類,如kNN。下圖是LDA降維之后用最小距離分類器分類的結(jié)果:
從這張圖可以看出,決策面是直線。LDA是一種線性模型,也是判別模型,只能用于分類問題。
logistic回歸即對(duì)數(shù)幾率回歸,它的名字雖然叫“回歸”,但卻是一種用于二分類問題的分類算法,它用sigmoid函數(shù)估計(jì)出樣本屬于某一類的概率。這種算法可以看做是對(duì)線性分類器的改進(jìn)。
預(yù)測函數(shù)為:
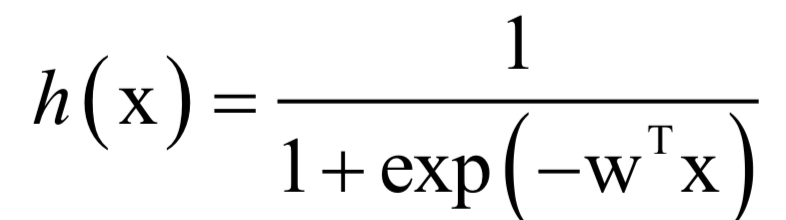
其中為線性映射權(quán)向量,由訓(xùn)練算法確定。訓(xùn)練時(shí)的優(yōu)化目標(biāo)是最大化對(duì)數(shù)似然函數(shù):
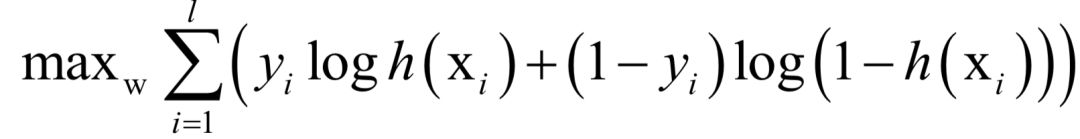
這是一個(gè)凸優(yōu)化問題,可以得到全局最優(yōu)解,求解時(shí)可以采用梯度下降法或者牛頓法。分類時(shí)的判斷規(guī)則為:
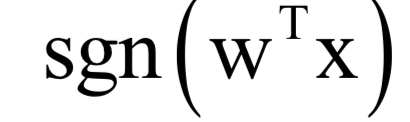
logistic回歸是一種判別模型,也是線性模型,它只支持二分類問題。下圖是用logistic回歸進(jìn)行分類的結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
從上圖可以看到,分界面是一條直線,這也說明了它是一個(gè)線性模型。
logistic回歸只能用于二分類問題,將它進(jìn)行推廣可以得到處理多類分類問題的softmax回歸。softmax回歸按照下面的公式估計(jì)一個(gè)樣本屬于每一類的概率:
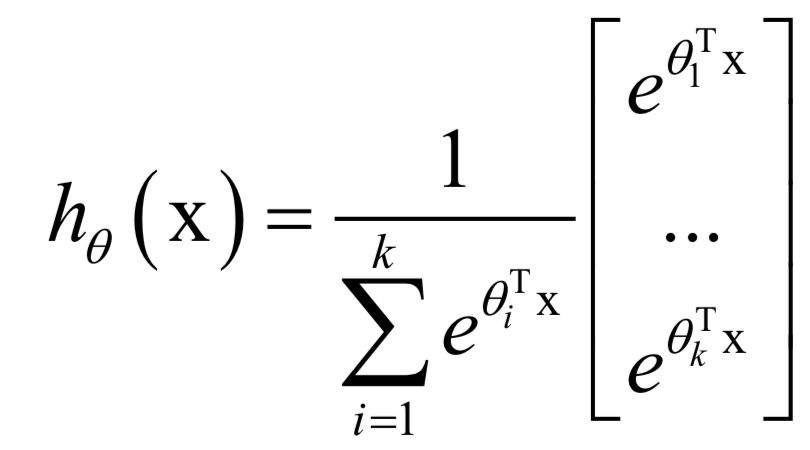
模型的輸出為一個(gè)k維向量,其元素之和為1,每一個(gè)分量為樣本屬于該類的概率。訓(xùn)練時(shí)的損失函數(shù)定義為:
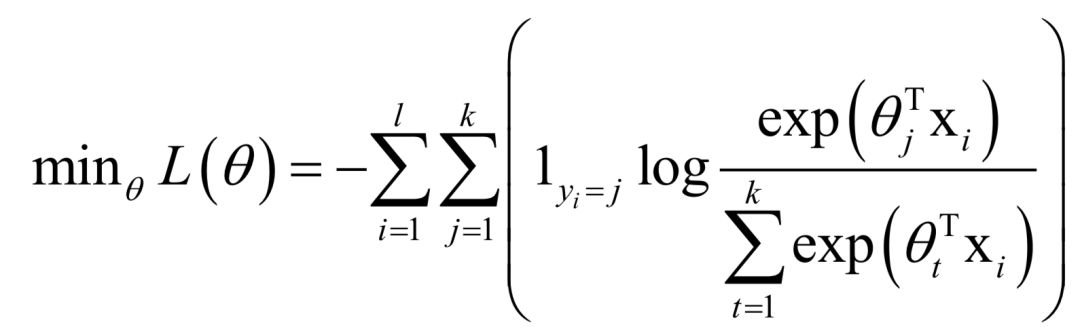
上式是對(duì)logistic回歸損失函數(shù)的推廣。這個(gè)損失函數(shù)是凸函數(shù),可以采用梯度下降法求解。Softmax回歸是一種判別模型,也是線性模型,它支持多分類問題。
支持向量機(jī)
支持向量機(jī)是對(duì)線性分類器的改進(jìn),加上了最大化分類間隔的約束,另外還使用了核技術(shù),通過非線性核解決非線性問題。一般情況下,給定一組訓(xùn)練樣本可以得到不止一個(gè)可行的線性分類器,下圖就是一個(gè)例子:
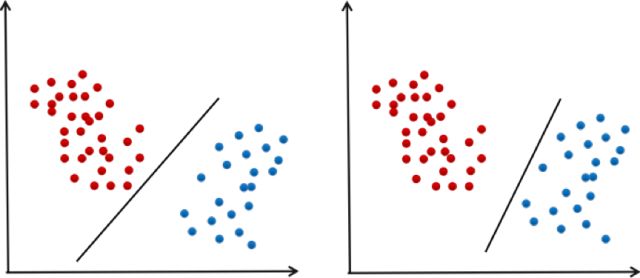
在上圖中兩條直線都可以將兩類樣本分開。問題是:在多個(gè)可行的線性分類器中,什么樣的分類器是好的?為了得到好的泛化性能,分類平面應(yīng)該不偏向于任何一類,并且離兩個(gè)類的樣本都盡可能的遠(yuǎn)。這種最大化分類間隔的目標(biāo)就是支持向量機(jī)的基本思想。支持向量機(jī)在訓(xùn)練時(shí)優(yōu)化的目標(biāo)是讓訓(xùn)練樣本盡量分類正確,而且決策面離兩類樣本盡可能遠(yuǎn)。原問題帶有太多的不等式約束,一般轉(zhuǎn)化為對(duì)偶問題求解,使用拉格朗日對(duì)偶,加上核函數(shù)之后,優(yōu)化的對(duì)偶問題為:
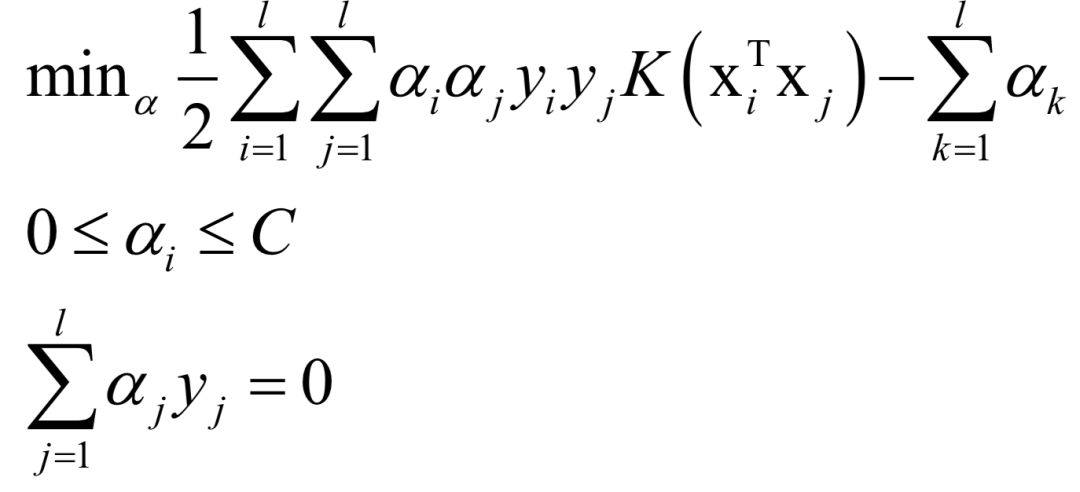
預(yù)測函數(shù)為:
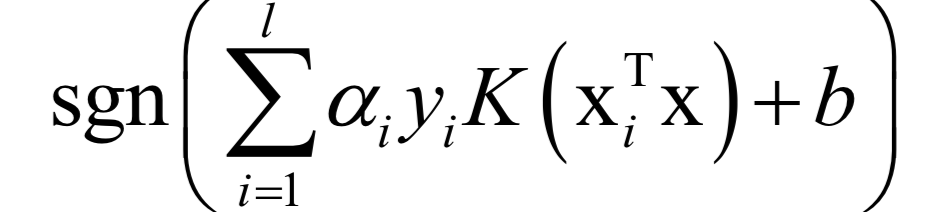
這是一個(gè)凸優(yōu)化問題,可以得到全局最優(yōu)解,求解時(shí)一般采用SMO算法,這是一種分治法,每次挑選出兩個(gè)變量進(jìn)行優(yōu)化,對(duì)這兩個(gè)變量的優(yōu)化問題求公式解。優(yōu)化變量的選擇使用了KKT條件。
支持向量機(jī)是一種判別模型,既支持分類問題,也支持回歸問題,如果使用非線性核,則是一種非線性模型,這從它的預(yù)測函數(shù)也可以看出來。標(biāo)準(zhǔn)的支持向量機(jī)只能解決二分類問題,通過多個(gè)二分類器組合,可以解決多分類問題,另外一種思路是直接構(gòu)造多類的損失函數(shù)來解決多分類問題。下圖是用支持向量機(jī)對(duì)異或問題進(jìn)行分類的結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
神經(jīng)網(wǎng)絡(luò)
人工神經(jīng)網(wǎng)絡(luò)是一種仿生方法,受啟發(fā)于人腦的神經(jīng)網(wǎng)絡(luò)。從數(shù)學(xué)上看,它本質(zhì)上是一個(gè)多層復(fù)合函數(shù)。如果使用sigmoid作為激活函數(shù),它的單個(gè)神經(jīng)元就是logistic回歸。假設(shè)神經(jīng)網(wǎng)絡(luò)的輸入是n維向量x,輸出是m維向量y,它實(shí)現(xiàn)了如向量到向量的映射:
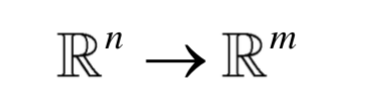
將這個(gè)函數(shù)記為:
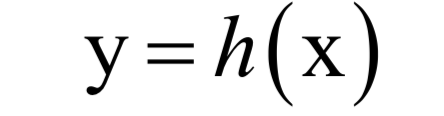
神經(jīng)網(wǎng)絡(luò)第層的變換寫成矩陣和向量形式為:
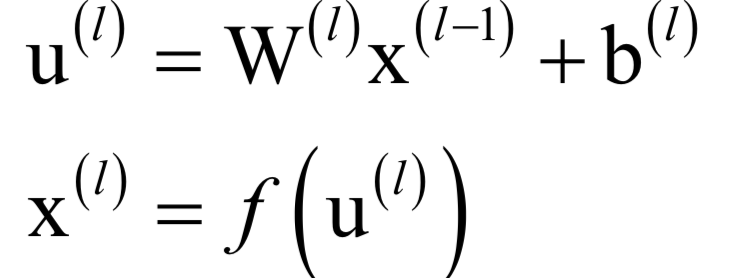
如果采用歐氏距離,訓(xùn)練時(shí)的優(yōu)化目標(biāo)為:
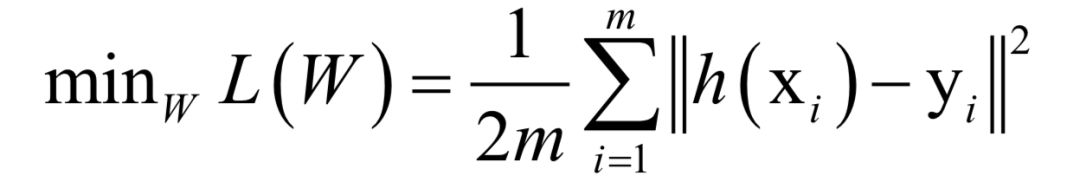
這不是一個(gè)凸優(yōu)化問題,因此不能保證得到全局極小值。可以采用梯度下降法求解,因?yàn)槭且粋€(gè)復(fù)合函數(shù),需要對(duì)各層的權(quán)重與偏置求導(dǎo),采用了反向傳播算法,它從多元函數(shù)求導(dǎo)的鏈?zhǔn)椒▌t導(dǎo)出。誤差項(xiàng)的計(jì)算公式為,對(duì)于輸出層:
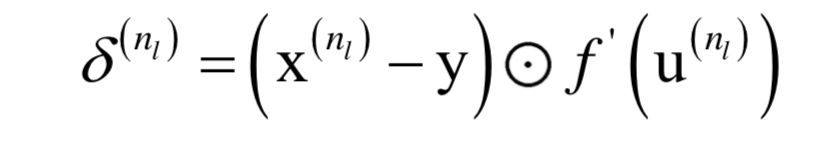
對(duì)于隱含層:
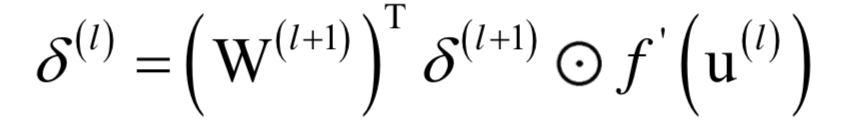
根據(jù)誤差項(xiàng)可以得到權(quán)重和偏置的梯度值:
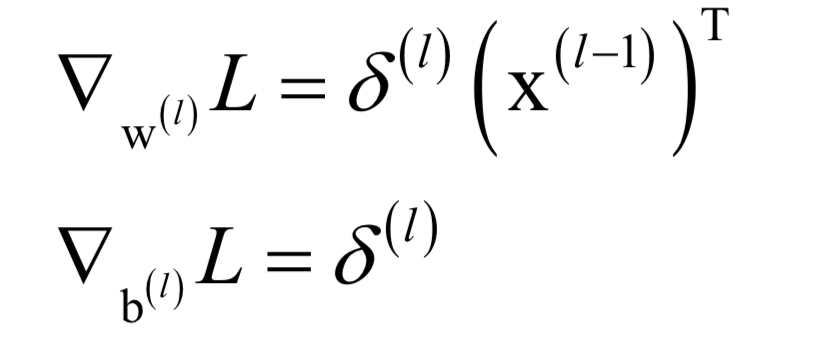
然后用梯度下降法更新。神經(jīng)網(wǎng)絡(luò)是一個(gè)判別模型,并且是非線性模型,它既支持分類問題,也支持回歸問題,并且支持多分類問題。下圖是用神經(jīng)網(wǎng)絡(luò)對(duì)異或問題的分類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
深度神經(jīng)網(wǎng)絡(luò)家族
深度神經(jīng)網(wǎng)絡(luò)是對(duì)多層感知器模型的進(jìn)一步發(fā)展,它可以完成自動(dòng)的特征提取,端到端的訓(xùn)練,是深度學(xué)習(xí)的核心技術(shù)。可以分為自動(dòng)編碼器,受限玻爾茲曼機(jī),卷積神經(jīng)網(wǎng)絡(luò),循環(huán)神經(jīng)網(wǎng)絡(luò),生成對(duì)抗網(wǎng)絡(luò)這幾種類型。
自動(dòng)編碼器用一個(gè)單層或者多層神經(jīng)網(wǎng)絡(luò)對(duì)輸入數(shù)據(jù)進(jìn)行映射,得到輸出向量,作為從輸入數(shù)據(jù)提取出的特征。在這種框架中,神經(jīng)網(wǎng)絡(luò)的前半部分稱為編碼器,用于從原始輸入數(shù)據(jù)中提取特征;后半部分稱為解碼器,訓(xùn)練時(shí)根據(jù)提取的特征重構(gòu)原始數(shù)據(jù),它只用于訓(xùn)練階段。
訓(xùn)練時(shí)的做法是先經(jīng)過編碼器得到編碼后的向量,然后再通過解碼器得到解碼后的向量,用解碼后的向量和原始輸入向量計(jì)算誤差。如果編碼器的映射函數(shù)為h,解碼器的映射函數(shù)為g,訓(xùn)練時(shí)優(yōu)化的目標(biāo)函數(shù)為:
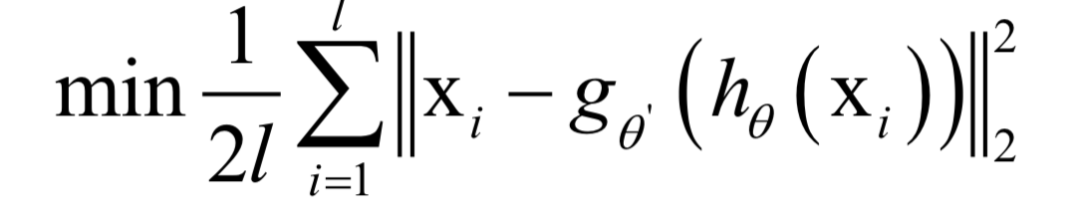
在這里同樣采用梯度下降法和反向傳播算法。自動(dòng)編碼器的改進(jìn)型有去噪自動(dòng)編碼器,收縮自動(dòng)編碼器,變分自動(dòng)編碼器,稀疏編碼等。
單個(gè)自動(dòng)編碼器只能進(jìn)行一層特征提取,可以將多個(gè)自動(dòng)編碼器組合起來使用,得到一種稱為層疊編碼器的結(jié)構(gòu)。層疊自動(dòng)編編碼器由多個(gè)自動(dòng)動(dòng)編碼器串聯(lián)組成,能夠逐層提取輸入數(shù)據(jù)的特征,在此過程中逐層降低輸入數(shù)據(jù)的維度,將高維的輸入數(shù)據(jù)轉(zhuǎn)化成低維的特征。
受限玻爾茲曼機(jī)由Hinton等人提出,是一種生成式隨機(jī)神經(jīng)網(wǎng)絡(luò),這是一種概率模型。在這種模型中,神經(jīng)元的狀態(tài)值是以隨機(jī)的方式確定的,而不像之前介紹的神經(jīng)網(wǎng)絡(luò)那樣是確定性的。
受限玻爾茲曼機(jī)的數(shù)據(jù)分為可見變量和隱變量兩種類型,并定義了它們之間的概率關(guān)系。可見變量是神經(jīng)網(wǎng)絡(luò)的輸入數(shù)據(jù),如圖像;隱變量是從輸入數(shù)據(jù)中提取的特征。在受限玻爾茲曼機(jī)中,可見變量和隱藏變量都是二元變量,即其取值只能為0或1,整個(gè)神經(jīng)網(wǎng)絡(luò)是一個(gè)二部圖。
可見節(jié)點(diǎn)用向量表示為v,隱藏節(jié)點(diǎn)用向量表示為h。任意可見節(jié)點(diǎn)和隱藏節(jié)點(diǎn)之間都有邊連接。(v, h)的聯(lián)合概率服從玻爾茲曼分布,聯(lián)合概率定義為:
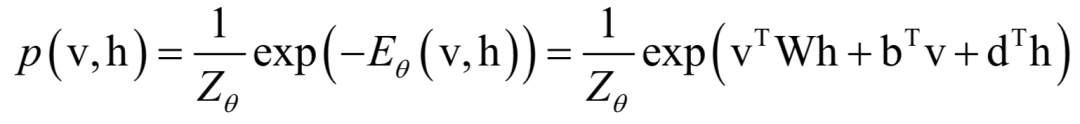
訓(xùn)練時(shí)迭代更新權(quán)重參數(shù)直至網(wǎng)絡(luò)收斂,這種方法稱為Contrastive Divergence。
和自動(dòng)編碼器類似,可以將多個(gè)受限玻爾茲曼機(jī)層疊加起來使用,在種結(jié)構(gòu)稱為深度玻爾茲曼機(jī)(Deep Boltzmann Machine),簡稱DBM。通過多層的受限玻爾茲曼機(jī),可以完成數(shù)據(jù)在不同層次上的特征提取和抽象。
在DBM中,所有層的節(jié)點(diǎn)之間的連接關(guān)系是無向的,如果我們限制某些層之間的連接關(guān)系為有向的,就得到了另外一種結(jié)構(gòu),稱為深信度網(wǎng)絡(luò)(Deep Belief Network),簡稱DBN。在DBN中,靠近輸入層的各個(gè)層之間的連接關(guān)系是有向的,是貝葉斯置信網(wǎng);靠近輸出層的各個(gè)層之間的連接關(guān)系是無向的,是受限玻爾茲曼機(jī)。
在所有深度學(xué)習(xí)框架中,卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用最為廣泛,在機(jī)器視覺等具有空間結(jié)構(gòu)的數(shù)據(jù)問題上取得了成功。標(biāo)準(zhǔn)的卷積神經(jīng)網(wǎng)絡(luò)由卷積層,池化層,全連接層構(gòu)成。可以看做是權(quán)重共享的全連接神經(jīng)網(wǎng)絡(luò)。
訓(xùn)練時(shí)同樣采用梯度下降法和反向傳播算法。對(duì)于卷積層,根據(jù)誤差項(xiàng)計(jì)算卷積核梯度的計(jì)算公式為:
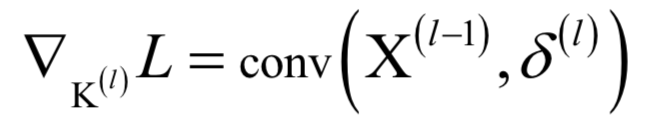
卷層誤差項(xiàng)的遞推公式為:
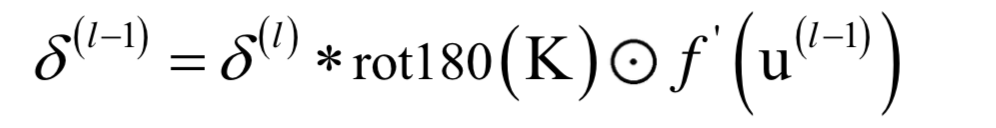
也可以用矩陣乘法來實(shí)現(xiàn)卷積,這種做法更容易理解,可以方便的計(jì)算出對(duì)卷積核的梯度值。
循環(huán)神經(jīng)網(wǎng)絡(luò)是僅次于卷積神經(jīng)網(wǎng)絡(luò)的第二大深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),在語音識(shí)別、自然語言處理等問題上取得了成功。循環(huán)神經(jīng)網(wǎng)絡(luò)具有記憶功能,用于時(shí)間序列數(shù)據(jù)預(yù)測。循環(huán)層實(shí)現(xiàn)的映射為:
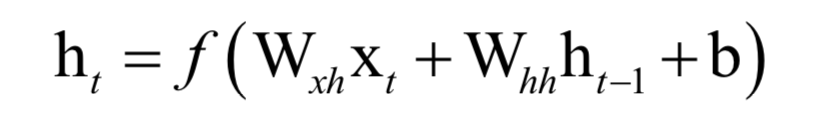
輸出層實(shí)現(xiàn)的映射為:
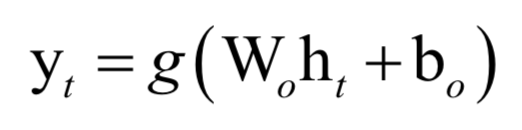
對(duì)單個(gè)樣本,訓(xùn)練時(shí)的損失函數(shù)為各個(gè)時(shí)刻的損失函數(shù)之和:
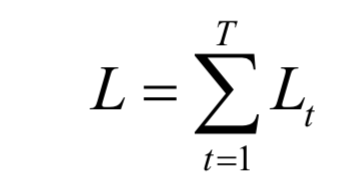
這里的反向傳播算法稱為BPTT(Back Propagation Through Time),在時(shí)間軸上進(jìn)行反向傳播。誤差項(xiàng)的遞推計(jì)算公式為:
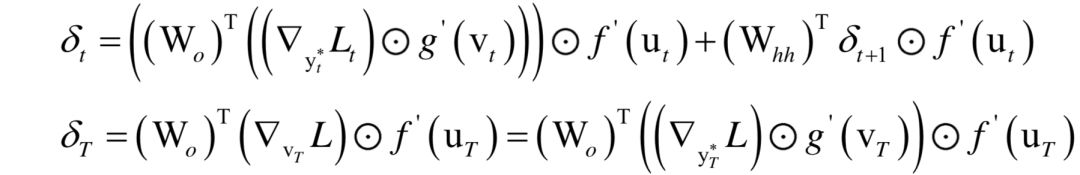
根據(jù)誤差項(xiàng)計(jì)算權(quán)重和偏置的公式為:
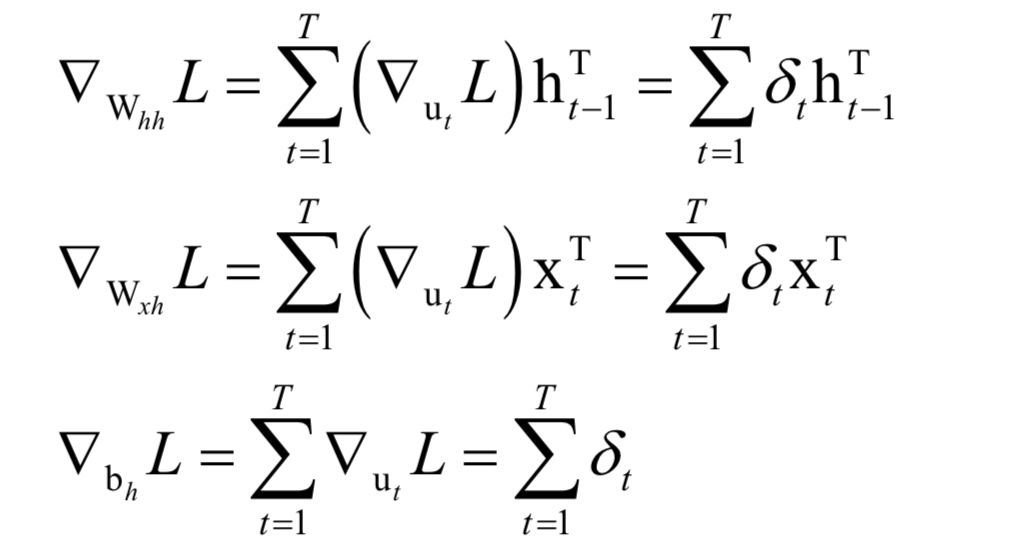
生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,簡稱GAN)是用機(jī)器學(xué)習(xí)的方法來解決數(shù)據(jù)生成問題的一種框架,它的目標(biāo)是生成服從某種隨機(jī)分布的數(shù)據(jù),由Goodfellow在2014年提出。 這種模型能夠找出樣本數(shù)據(jù)內(nèi)部的概率分布規(guī)律,并根據(jù)這種規(guī)律產(chǎn)生出新的數(shù)據(jù)。
整個(gè)框架由一個(gè)生成模型和一個(gè)判別模型組成。生成模型用于學(xué)習(xí)真實(shí)數(shù)據(jù)的概率分布,并生成符合這種分布的數(shù)據(jù);判別模型的任務(wù)是判斷一個(gè)輸入數(shù)據(jù)是來自于真實(shí)數(shù)據(jù)集還是由生成模型生成的。在訓(xùn)練時(shí),通過兩個(gè)模型之間不斷的競爭,從而分別提高這兩個(gè)模型的生成能力和判別能力。
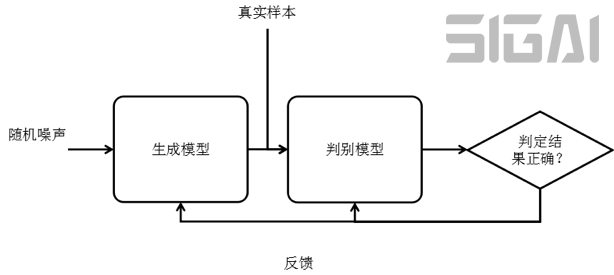
生成模型的輸入是隨機(jī)噪聲z,輸出是產(chǎn)生的數(shù)據(jù)G(z)。判別模型的輸入是真實(shí)樣本,或者生成網(wǎng)絡(luò)生成的數(shù)據(jù),得到的是它們的分類結(jié)果D(x)。
訓(xùn)練的目標(biāo)是讓判別模型能夠最大程度的正確區(qū)分真實(shí)樣本和生成模型生成的樣本;同時(shí)要讓生成模型使生成的樣本盡可能的和真實(shí)樣本相似。即:判別模型要盡可能將真實(shí)樣本判定為真實(shí)樣本,將生成模型產(chǎn)生的樣本判定為生成樣本;生成模型要盡量讓判別模型將自己生成的樣本判定為真實(shí)樣本。基于以上3個(gè)要求,對(duì)于生成模型生成的樣本,要最小化如下目標(biāo)函數(shù):
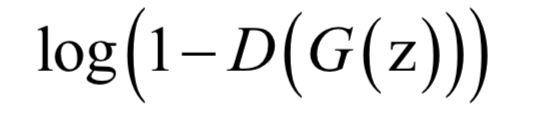
這意味著如果生成模型生成的樣本和真實(shí)樣本越接近,被判別模型判斷為真實(shí)樣本的概率就越大,即D(G(z))的值越接近于1,目標(biāo)函數(shù)的值越小。另外還要考慮真實(shí)的樣本,對(duì)真實(shí)樣本要盡量將它判別成1。這樣要優(yōu)化的目標(biāo)函數(shù)定義為:
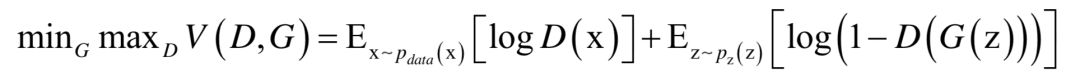
在這里判別模型和生成模型是目標(biāo)函數(shù)的自變量,它們的參數(shù)是要優(yōu)化的變量。求解時(shí)采用了交替優(yōu)化的策略,先固定住生成網(wǎng)絡(luò),訓(xùn)練判別網(wǎng)絡(luò);然后固定住判別網(wǎng)絡(luò),訓(xùn)練生成網(wǎng)絡(luò)。每個(gè)網(wǎng)絡(luò)的訓(xùn)練都采用梯度下降法和反向傳播算法。
集成學(xué)習(xí)家族
集成學(xué)習(xí)(ensemble learning)是一類機(jī)器學(xué)習(xí)算法,它通過多個(gè)模型的組合形成一個(gè)精度更高的模型,參與組合的模型稱為弱學(xué)習(xí)器(weak learner)。在預(yù)測時(shí)使用這些弱學(xué)習(xí)器模型聯(lián)合進(jìn)行預(yù)測;訓(xùn)練時(shí)需要用訓(xùn)練樣本集依次訓(xùn)練出這些弱學(xué)習(xí)器。隨機(jī)森林和AdaBoost算法是這類算法的典型代表。
隨機(jī)森林由多棵決策樹組成。用多棵決策樹聯(lián)合預(yù)測可以提高模型的精度,這些決策樹用對(duì)訓(xùn)練樣本集隨機(jī)抽樣構(gòu)造出樣本集訓(xùn)練得到。由于訓(xùn)練樣本集由隨機(jī)抽樣構(gòu)造,因此稱為隨機(jī)森林。隨機(jī)森林不僅對(duì)訓(xùn)練樣本進(jìn)行抽樣,還對(duì)特征向量的分量隨機(jī)抽樣,在訓(xùn)練決策樹時(shí),每次分裂時(shí)只使用一部分抽樣的特征分量作為候選特征進(jìn)行分裂。下圖是隨機(jī)森林對(duì)異或問題的分類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
對(duì)應(yīng)的隨機(jī)森林如下圖所示:
隨機(jī)森林是一種判別模型,也是一種非線性模型,它既支持分類問題,也支持回歸問題,并且支持多分類問題,有很好的解釋性。
Boosting算法也是一種集成學(xué)習(xí)算法。它的分類器由多個(gè)弱分類器組成,預(yù)測時(shí)用每個(gè)弱分類器分別進(jìn)行預(yù)測,然后投票得到結(jié)果;訓(xùn)練時(shí)依次訓(xùn)練每個(gè)弱分類器,在這里和隨機(jī)森林采用了不同的策略,不是對(duì)樣本進(jìn)行隨機(jī)抽樣構(gòu)造訓(xùn)練集,而是重點(diǎn)關(guān)注被前面的弱分類器錯(cuò)分的樣本。弱分類器是很簡單的分類器,它計(jì)算量小且精度不用太高。
AdaBoost算法由Freund等人提出,是Boosting算法的一種實(shí)現(xiàn)版本。在最早的版本中,這種方法的弱分類器帶有權(quán)重,分類器的預(yù)測結(jié)果為弱分類器預(yù)測結(jié)果的加權(quán)和。訓(xùn)練時(shí)訓(xùn)練樣本具有權(quán)重,并且會(huì)在訓(xùn)練過程中動(dòng)態(tài)調(diào)整,被前面的弱分類器錯(cuò)分的樣本會(huì)加大權(quán)重,因此算法會(huì)關(guān)注難分的樣本。
強(qiáng)分類器的計(jì)算公式為:
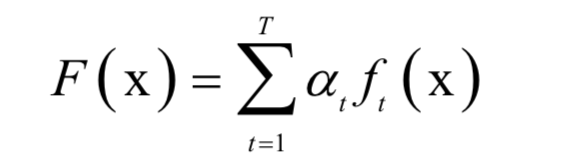
分類時(shí)的判定規(guī)則為:
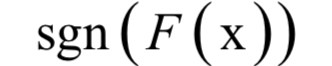
訓(xùn)練目標(biāo)是最小化指數(shù)損失函數(shù):
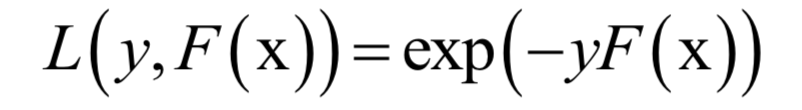
求解時(shí)采用了分階段優(yōu)化的策略,先把弱分類器的權(quán)重當(dāng)做常數(shù),優(yōu)化弱分類器。得到弱分類器之后,再優(yōu)化它的權(quán)重。弱分類器的權(quán)重計(jì)算公式為:
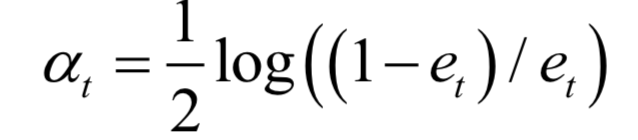
樣本權(quán)重的更新公式為:
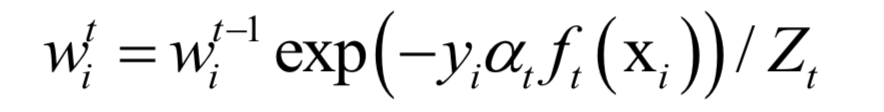
AdaBoost算法的原則是關(guān)注之前被錯(cuò)分的樣本,準(zhǔn)確率高的弱分類器有更大的權(quán)重。
AdaBoost算法是一個(gè)判別模型,也是非線性模型,它只支持二分類問題。下圖是用AdaBoost算法對(duì)異或問題的分類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
無監(jiān)督學(xué)習(xí)
相對(duì)于有監(jiān)督學(xué)習(xí),無監(jiān)督學(xué)習(xí)的研究進(jìn)展更為緩慢,算法也相對(duì)較少。無監(jiān)督學(xué)習(xí)可以分為聚類和降維兩大類,下面分別介紹。
聚類算法家族
聚類屬于無監(jiān)督學(xué)習(xí)問題,其目標(biāo)是將樣本集劃分成多個(gè)類,保證同一類的樣本之間盡量相似,不同類的樣本之間盡量不同。這些類被稱為簇(cluster)。與有監(jiān)督的分類算法不同,聚類算法沒有訓(xùn)練過程,直接完成對(duì)一組樣本的劃分從而確定每個(gè)樣本的類別歸屬。我們一般將距離算法分為層次距離,基于質(zhì)心的聚類,基于密度的聚類,基于概率分布的聚類,基于圖的聚類這幾種類型,它們從不同的角度定義簇。
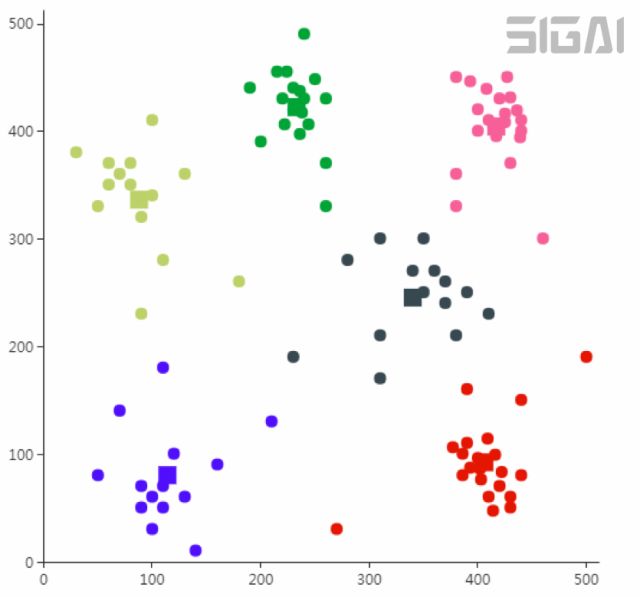
k均值算法是一種被廣為用于實(shí)際問題的聚類算法。它將樣本劃分成k個(gè)類,參數(shù)k由人工設(shè)定。算法將每個(gè)樣本分配到離它最近的那個(gè)類中心所屬的類,而類中心的確定又依賴于樣本的分配方案。假設(shè)樣本集有l(wèi)個(gè)樣本,給定參數(shù)k的值,算法將這些樣本劃分成k個(gè)集合:
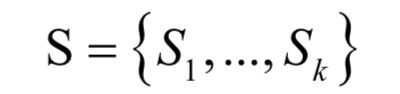
最優(yōu)分配方案是如下最優(yōu)化問題的解:
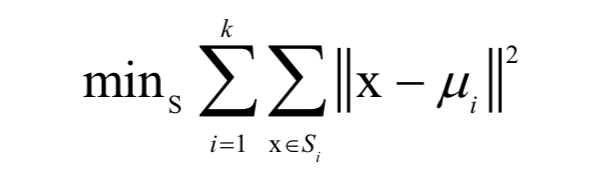
其中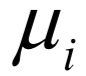 為類中心向量。這個(gè)問題是NP難問題,不易求得全局最優(yōu)解,只能近似求解。實(shí)現(xiàn)時(shí)采用迭代法近似求解,只能保證收斂的局部最優(yōu)解處。每次迭代時(shí),首先計(jì)算所有樣本離各個(gè)類中心的距離,然后將其分配到最近的那個(gè)類;接下來再根據(jù)這種分配方案更新類中心向量。下圖為k均值算法的聚類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
為類中心向量。這個(gè)問題是NP難問題,不易求得全局最優(yōu)解,只能近似求解。實(shí)現(xiàn)時(shí)采用迭代法近似求解,只能保證收斂的局部最優(yōu)解處。每次迭代時(shí),首先計(jì)算所有樣本離各個(gè)類中心的距離,然后將其分配到最近的那個(gè)類;接下來再根據(jù)這種分配方案更新類中心向量。下圖為k均值算法的聚類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
基于概率分布的算法假設(shè)每一個(gè)簇的樣本服從相同的概率分布,這是一種生成模型。經(jīng)常使用的是多維正態(tài)分布,如果服從這種分布,則為高斯混合模型,在求解時(shí)一般采用EM算法。
EM算法是一種迭代法,其目標(biāo)是求解似然函數(shù)或后驗(yàn)概率的極值,而樣本中具有無法觀測的隱含變量z。例如有一批樣本分屬于3個(gè)類,每個(gè)類的樣本都服從正態(tài)分布,均值和協(xié)方差未知,并且每個(gè)樣本屬于哪個(gè)類也是未知的,需要在這種情況下估計(jì)出每個(gè)正態(tài)分布的均值和協(xié)方差。算法在實(shí)現(xiàn)時(shí)分為兩步:
E步,基于當(dāng)前的參數(shù)估計(jì)值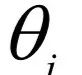 ,計(jì)算在給定x時(shí)對(duì)z的條件概率的數(shù)學(xué)期望:
,計(jì)算在給定x時(shí)對(duì)z的條件概率的數(shù)學(xué)期望:
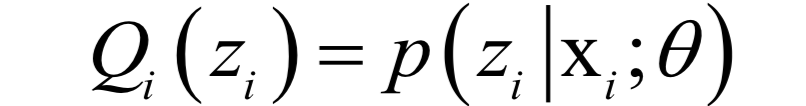
M步,求解如下極值問題,更新 的值:
的值:
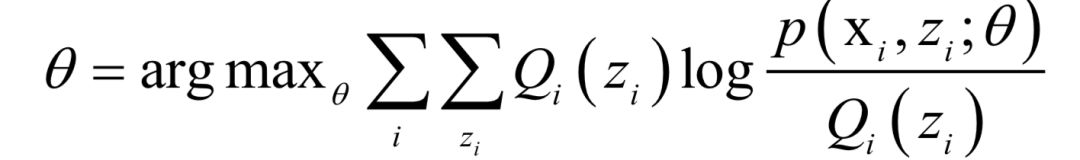
實(shí)現(xiàn)時(shí) 可以按照下面的公式計(jì)算:
可以按照下面的公式計(jì)算:
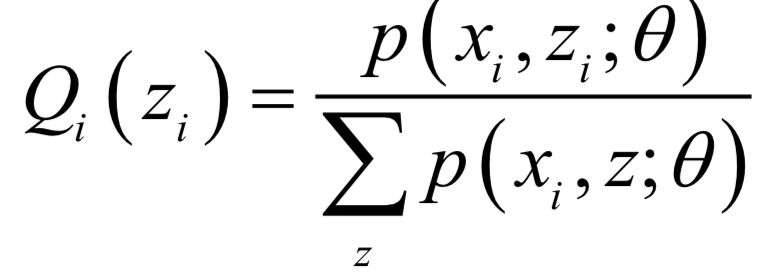
迭代終止的判定規(guī)則是相鄰兩次函數(shù)值之差小于指定閾值。
DBSCAN算法是一種基于密度的算法,對(duì)噪聲魯棒。它將簇定義為樣本密集的區(qū)域,算法從一個(gè)種子樣本開始,反復(fù)向密集的區(qū)域生長,直至到達(dá)邊界。
算法首先找出核心點(diǎn),即周圍樣本非常密集的那些樣本點(diǎn)。然后從某一核心點(diǎn)出發(fā),不斷向密度可達(dá)的區(qū)域擴(kuò)張,得到一個(gè)包含核心點(diǎn)和邊界點(diǎn)的最大區(qū)域,這個(gè)區(qū)域中任意兩點(diǎn)密度相連。下圖是DBSCAN算法的聚類結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
OPTICS算法是對(duì)DBSCAN算法的改進(jìn),對(duì)參數(shù)更不敏感。它不直接生成簇,而是對(duì)本進(jìn)行排序,這種排序包含了聚類信息。
均值漂移(Mean Shift)算基于核密度估計(jì)技術(shù),是一種尋找概率密度函數(shù)極值點(diǎn)的算法。在用于聚類任務(wù)時(shí),它尋找概率密度函數(shù)的極大值點(diǎn),即樣本分別最密集的位置,以此得到簇。
基于圖的算法把樣本數(shù)據(jù)看成圖的頂點(diǎn),通過數(shù)據(jù)點(diǎn)之間的距離構(gòu)造邊,形成帶權(quán)圖。通過圖的切割實(shí)現(xiàn)聚類,即將圖切分成多個(gè)子圖,這些子圖就是對(duì)應(yīng)的簇。基于圖的聚類算法典型的代表是譜聚類算法。譜聚類算法首先構(gòu)造數(shù)據(jù)的鄰接圖,得到圖的拉普拉斯矩陣。接下來對(duì)矩陣進(jìn)行特征值分解,通過特征值和特征向量構(gòu)造出簇。
數(shù)據(jù)降維
在有些應(yīng)用中,向量的維數(shù)非常高。以圖像數(shù)據(jù)為例,對(duì)于高度和寬度分別為100像素的圖像,如果將所有像素值拼接起來形成一個(gè)向量,這個(gè)向量的維數(shù)是10000。另外向量的各個(gè)分量之間可能存在相關(guān)性。直接將向量送入機(jī)器學(xué)習(xí)算法中處理效率會(huì)很低,也影響算法的精度。為了可視化顯示數(shù)據(jù),我們也需要把向量變換到低維空間中。
主成分分析(principal component analysis,簡稱PCA)是一種數(shù)據(jù)降維和去除相關(guān)性的方法,它通過線性變換將向量投影到低維空間。對(duì)向量進(jìn)行投影就是讓向量左乘一個(gè)矩陣得到結(jié)果向量,這也是線性代數(shù)中講述的線性變換:
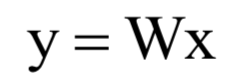
降維要確保的是在低維空間中的投影能很好的近似表達(dá)原始向量,即重構(gòu)誤差最小化。下圖是主分量投影示意圖:
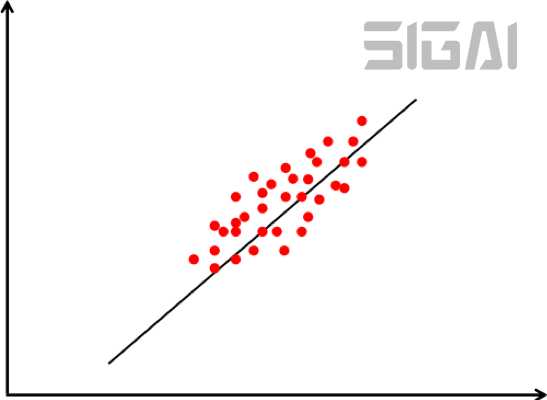
圖7.1 主分量投影示意圖
在上圖中樣本用紅色的點(diǎn)表示,傾斜的直線是它們的主要變化方向。將數(shù)據(jù)投影到這條直線上即完成數(shù)據(jù)的降維,把數(shù)據(jù)從2維降為1維。
尋找投影矩陣時(shí)要優(yōu)化的目標(biāo)是使得重構(gòu)誤差最小化:
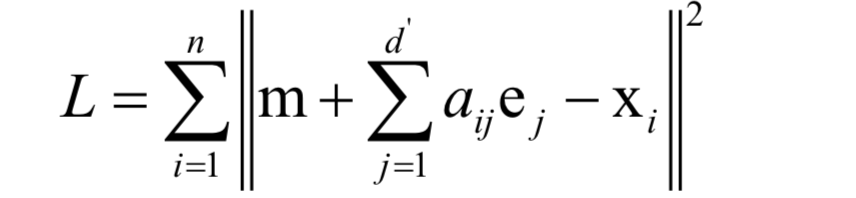
使得該函數(shù)取最小值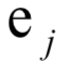 的為散度矩陣最大的
的為散度矩陣最大的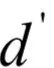 個(gè)特征值對(duì)應(yīng)的單位長度特征向量。即求解下面的優(yōu)化問題:
個(gè)特征值對(duì)應(yīng)的單位長度特征向量。即求解下面的優(yōu)化問題:
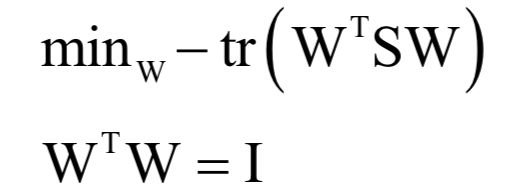
矩陣W的列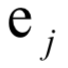 是我們要求解的基向量。散度矩陣是實(shí)對(duì)稱矩陣,因此屬于不同特征值的特征向量是正交的。下圖是主成分分析對(duì)手寫數(shù)字圖像的降維結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
是我們要求解的基向量。散度矩陣是實(shí)對(duì)稱矩陣,因此屬于不同特征值的特征向量是正交的。下圖是主成分分析對(duì)手寫數(shù)字圖像的降維結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
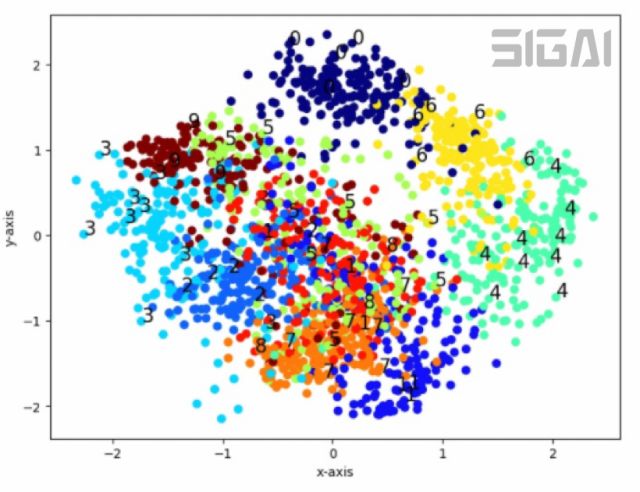
雖然都是線性投影算法,但主成分分析和線性判別分析有本質(zhì)的不同,前者是無監(jiān)督的,后者是有監(jiān)督的,計(jì)算過程中使用了類別標(biāo)簽信息。
主成分分析是一種線性降維技術(shù),對(duì)于高度非線性的數(shù)據(jù)具有局限性,而在實(shí)際應(yīng)用中很多時(shí)候數(shù)據(jù)是非線性的。此時(shí)可以采用非線性降維技術(shù),流形學(xué)習(xí)(manifold learning)是非線性降維技術(shù)的典型代表。
流形是微分幾何中的一個(gè)概念,它是高維空間中的幾何結(jié)構(gòu),即空間中的點(diǎn)構(gòu)成的集合,可以簡單的理解成二維空間的曲線,三維空間的曲面在更高維空間的推廣。下圖是三維空間中的一個(gè)流形,這是一個(gè)卷曲的曲面:
假設(shè)有一個(gè)N維空間中的流形M,即:

流形學(xué)習(xí)降維要實(shí)現(xiàn)的是如下映射:
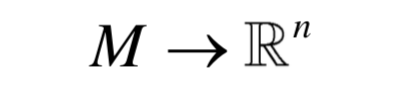
其中n<
局部線性嵌入(簡稱LLE)將高維數(shù)據(jù)投影到低維空間中,并保持?jǐn)?shù)據(jù)點(diǎn)之間的局部線性關(guān)系。其核心思想是每個(gè)點(diǎn)都可以由與它相近的多個(gè)點(diǎn)的線性組合來近似,投影到低維空間之后要保持這種線性重構(gòu)關(guān)系,并且有相同的重構(gòu)系數(shù)。
每個(gè)數(shù)據(jù)點(diǎn)和它的鄰居位于或者接近于流形的一個(gè)局部線性片段上,即可以用它鄰居點(diǎn)的線性組合來重構(gòu),組合系數(shù)刻畫了這些局部面片的幾何特性:
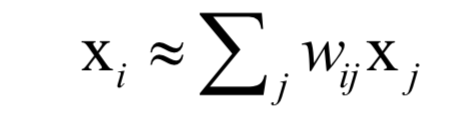
權(quán)重系數(shù)通最小化下面的重構(gòu)誤差確定:
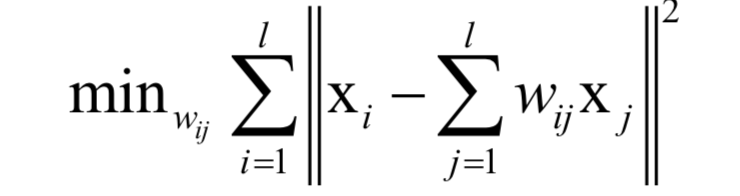
假設(shè)非線性映射將向量從D維空間的x映射為d維空間的y。每個(gè)點(diǎn)在d維空間中的坐標(biāo)由下面的最優(yōu)化問題確定:
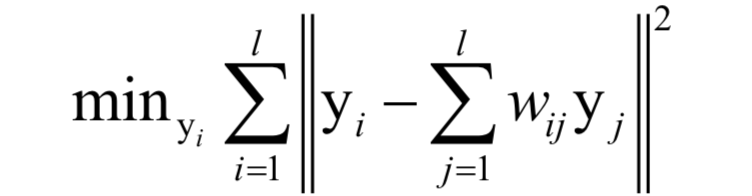
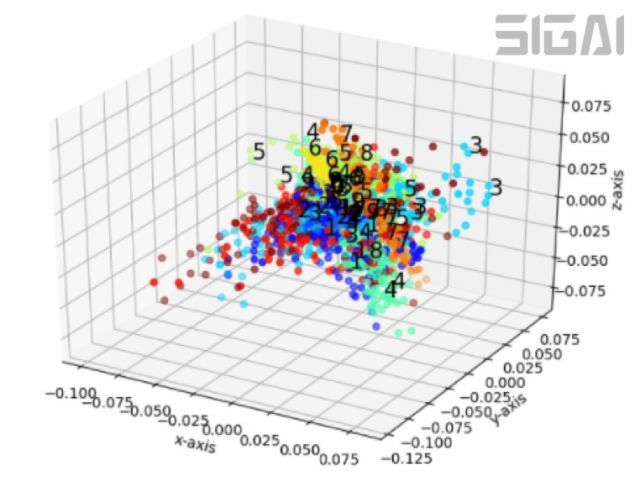
這里的權(quán)重和上一個(gè)優(yōu)化問題的值相同,在前面已經(jīng)得到。下圖為用LLE算法將手寫數(shù)字圖像投影到3維空間后的結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
等距映射(Isomap)使用了微分幾何中測地線的思想,它希望數(shù)據(jù)在向低維空間映射之后能夠保持流形上的測地線距離。
測地線源自于大地測量學(xué),是指地球上任意兩點(diǎn)之間在球面上的最短路徑。在三維空間中兩點(diǎn)之間的最短距離是它們之間線段的長度,但如果要沿著地球表面走,最短距離就是測地線的長度,因?yàn)槲覀儾豢赡軓牡厍騼?nèi)部穿過去。算法計(jì)算任意兩個(gè)樣本之間的測地距離,然后根據(jù)這個(gè)距離構(gòu)造距離矩陣。最后通過距離矩陣求解優(yōu)化問題完成數(shù)據(jù)的降維,降維之后的數(shù)據(jù)保留了原始數(shù)據(jù)點(diǎn)之間的距離信息。
降維過求解如下最優(yōu)化問題實(shí)現(xiàn):
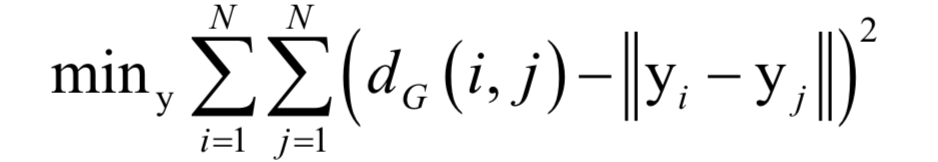
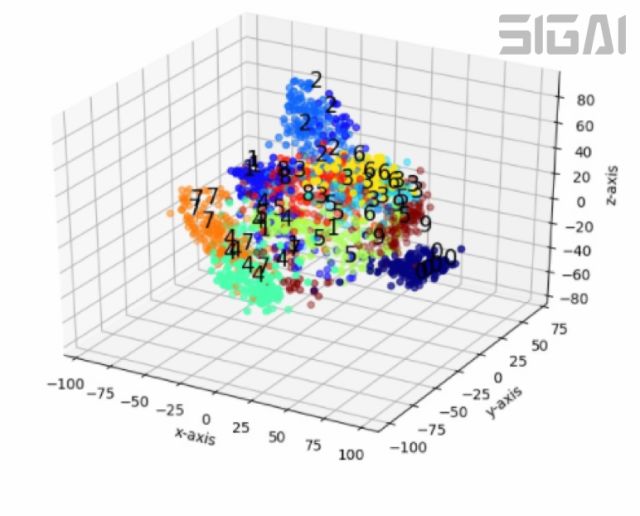
這個(gè)目標(biāo)函數(shù)的意義是向量降維之后任意兩點(diǎn)之間的距離要盡量的接近在原始空間中這兩點(diǎn)之間的最短路徑長度,因此可以認(rèn)為降維盡量保留了數(shù)據(jù)點(diǎn)之間的測地距離信息。下圖是等距映射對(duì)手寫數(shù)字圖像降維后的結(jié)果(來自SIGAI云端實(shí)驗(yàn)室):
強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)是一類特殊的機(jī)器學(xué)習(xí)算法,如果說有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)是要根據(jù)預(yù)測函數(shù)來確定輸出標(biāo)簽信息或者聚類類別、降維后的向量,則強(qiáng)化學(xué)習(xí)算法是要根據(jù)當(dāng)前的狀態(tài)確定要執(zhí)行的動(dòng)作。
強(qiáng)化學(xué)習(xí)與有監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)的目標(biāo)不同,它借鑒于行為主義心理學(xué)。算法要解決的問題是智能體在環(huán)境中怎樣執(zhí)行動(dòng)作以獲得最大的累計(jì)獎(jiǎng)勵(lì)。對(duì)于自動(dòng)行駛的汽車,強(qiáng)化學(xué)習(xí)算法控制汽車的動(dòng)作,保證安全行駛。智能體指強(qiáng)化學(xué)習(xí)算法,環(huán)境是類似車輛當(dāng)前狀態(tài)與路況這樣的由若干參數(shù)構(gòu)成的系統(tǒng),獎(jiǎng)勵(lì)是我們期望得到的結(jié)果,如汽車正確的在路面上行駛而不發(fā)生事故。
很多控制、決策問題都可以抽象成這種模型。和有監(jiān)督學(xué)習(xí)不同,這里沒有標(biāo)簽值作為監(jiān)督信號(hào),系統(tǒng)只會(huì)給算法執(zhí)行的動(dòng)作一個(gè)評(píng)分反饋,這種反饋一般還具有延遲性,當(dāng)前的動(dòng)作所產(chǎn)生的后果在未來才會(huì)完全得到,另外未來還具有隨機(jī)性。
強(qiáng)化學(xué)習(xí)要解決的問題可以抽象成馬爾可夫決策過程(Markov Decision Process,簡稱MDP)。馬爾可夫過程的特點(diǎn)是系統(tǒng)下一個(gè)時(shí)刻的狀態(tài)由當(dāng)前時(shí)刻的狀態(tài)決定,與更早的時(shí)刻無關(guān)。與馬爾可夫過程不同的是,在MDP中系智能體可以執(zhí)行動(dòng)作,從而改變自己和環(huán)境的狀態(tài),并且得到懲罰或獎(jiǎng)勵(lì)。
馬爾可夫決策過程可以表示成一個(gè)五元組:
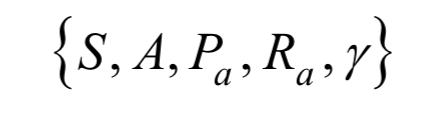
其中S和A分別為狀態(tài)和動(dòng)作的集合。假設(shè)t時(shí)刻狀態(tài)為st,智能體執(zhí)行動(dòng)作a,下一時(shí)刻進(jìn)入狀態(tài)st+1。下一時(shí)刻的狀態(tài)由當(dāng)前狀態(tài)以及當(dāng)前采取的動(dòng)作決定,是一個(gè)隨機(jī)性變量,這一狀態(tài)轉(zhuǎn)移的概率為:
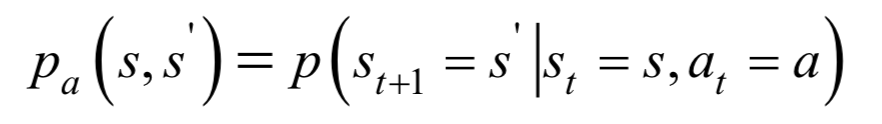
這是當(dāng)前狀態(tài)為s時(shí)行動(dòng)作a,下一時(shí)刻進(jìn)入狀態(tài)的條件概率。這個(gè)公式表明下一時(shí)刻的狀態(tài)與更早時(shí)刻的狀態(tài)和動(dòng)作無關(guān),狀態(tài)轉(zhuǎn)換具有馬爾可夫性。有一種特殊的狀態(tài)叫做終止?fàn)顟B(tài)(也稱為吸收狀態(tài)),到達(dá)該狀態(tài)之后不會(huì)再進(jìn)入其他后續(xù)狀態(tài)。對(duì)于圍棋,終止?fàn)顟B(tài)是一局的結(jié)束。
執(zhí)行動(dòng)作之后,智能體會(huì)收到一個(gè)立即回報(bào):
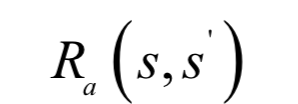
立即回報(bào)和當(dāng)前狀態(tài)、當(dāng)前采取的動(dòng)作以及下一時(shí)刻進(jìn)入的狀態(tài)有關(guān)。在每個(gè)時(shí)刻t,智能體選擇一個(gè)動(dòng)作at執(zhí)行,之后進(jìn)入下一狀態(tài)st+1,環(huán)境給出回報(bào)值。智能體從某一初始狀態(tài)開始,每個(gè)時(shí)刻選擇一個(gè)動(dòng)作執(zhí)行,然后進(jìn)入下一個(gè)狀態(tài),得到一個(gè)回報(bào),如此反復(fù):
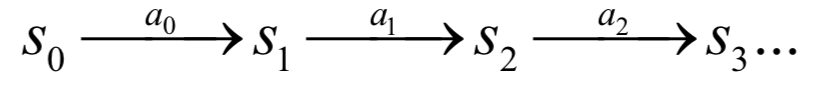
問題的核心是執(zhí)行動(dòng)作的策略,它可以抽象成一個(gè)函數(shù)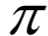 ,定義了在每種狀態(tài)時(shí)要選擇執(zhí)行的動(dòng)作。這個(gè)函數(shù)在狀態(tài)s所選擇的動(dòng)作為:
,定義了在每種狀態(tài)時(shí)要選擇執(zhí)行的動(dòng)作。這個(gè)函數(shù)在狀態(tài)s所選擇的動(dòng)作為:
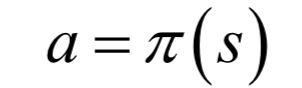
這是確定性策略。對(duì)于確定性策略,在每種狀態(tài)下智能體要執(zhí)行的動(dòng)作是唯一的。另外還有隨機(jī)性策略,智能體在一種狀態(tài)下可以執(zhí)行的動(dòng)作有多種,策略函數(shù)給出的是執(zhí)行每種動(dòng)作的概率:
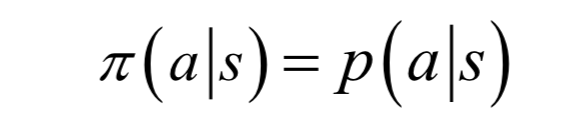
即按概率從各種動(dòng)作中選擇一種執(zhí)行。策略只與當(dāng)前所處的狀態(tài)有關(guān),于歷史時(shí)間無關(guān),在不同時(shí)刻對(duì)于同一個(gè)狀態(tài)所執(zhí)行的策略是相同的。
強(qiáng)化學(xué)習(xí)的目標(biāo)是要達(dá)到我們的某種預(yù)期,當(dāng)前執(zhí)行動(dòng)作的結(jié)果會(huì)影響系統(tǒng)后續(xù)的狀態(tài),因此需要確定動(dòng)作在未來是否能夠得到好的回報(bào),這種回報(bào)具有延遲性。對(duì)于圍棋,當(dāng)前走的一步棋一般不會(huì)馬上結(jié)束,但會(huì)影響后續(xù)的棋局,需要使得未來贏的概率最大化,而未來又具有隨機(jī)性,這為確定一個(gè)正確的決策帶來了困難。
選擇策略的目標(biāo)是按照這個(gè)策略執(zhí)行后,在各個(gè)時(shí)刻的累計(jì)回報(bào)值最大化,即未來的預(yù)期回報(bào)。按照某一策略執(zhí)行的累計(jì)回報(bào)定義為:
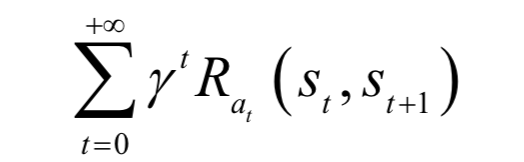
這里假設(shè)狀態(tài)轉(zhuǎn)移概率以及每個(gè)時(shí)刻的回報(bào)是已知的,算法要尋找最佳策略來最大化上面的累計(jì)回報(bào)。
如果每次執(zhí)行一個(gè)動(dòng)作進(jìn)入的下一個(gè)狀態(tài)是確定的,則可以直接用上面的累計(jì)回報(bào)計(jì)算公式。如果執(zhí)行完動(dòng)作后進(jìn)入的下一個(gè)狀態(tài)是隨機(jī)的,則需要計(jì)算各種情況的數(shù)學(xué)期望。為此定義狀態(tài)價(jià)值函數(shù)的概念,它是在某個(gè)狀態(tài)s下,按照策略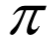 執(zhí)行動(dòng)作,累計(jì)回報(bào)的數(shù)學(xué)期望。狀態(tài)價(jià)值函數(shù)的計(jì)算公式為:
執(zhí)行動(dòng)作,累計(jì)回報(bào)的數(shù)學(xué)期望。狀態(tài)價(jià)值函數(shù)的計(jì)算公式為:
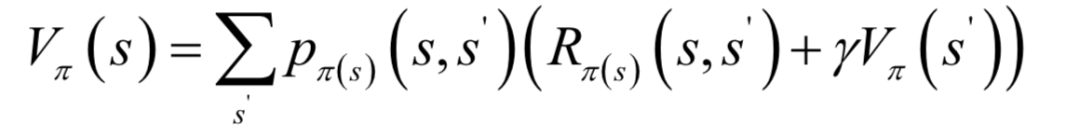
動(dòng)作價(jià)值函數(shù)是智能體按照策略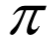 執(zhí)行,在狀態(tài)s時(shí)執(zhí)行具體的動(dòng)作a后的預(yù)期回報(bào),計(jì)算公式為:
執(zhí)行,在狀態(tài)s時(shí)執(zhí)行具體的動(dòng)作a后的預(yù)期回報(bào),計(jì)算公式為:
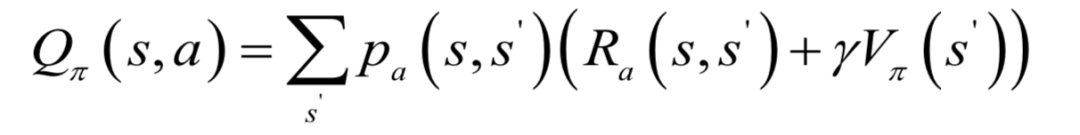
除了指定初始狀態(tài)與策略之外,還指定了在狀態(tài)s時(shí)執(zhí)行的動(dòng)作a。這個(gè)函數(shù)衡量的是給定某一策略,在某一狀態(tài)時(shí)執(zhí)行各種動(dòng)作的價(jià)值。
給定一個(gè)策略,可以用動(dòng)態(tài)規(guī)劃算法計(jì)算它的狀態(tài)價(jià)值函數(shù),即策略評(píng)估(Policy Evaluation)。在每種狀態(tài)下執(zhí)行的動(dòng)作有多種可能,需要對(duì)各個(gè)動(dòng)作計(jì)算數(shù)學(xué)期望。按照定義,狀態(tài)價(jià)值函數(shù)的計(jì)算公式為:
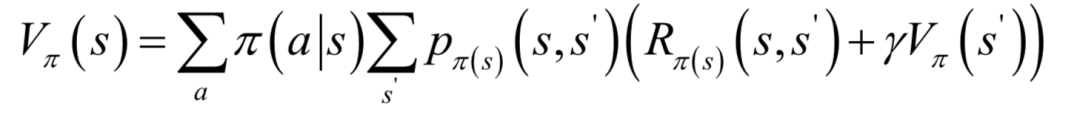
求解時(shí)使用迭代法,首先為所有狀態(tài)的價(jià)值函數(shù)設(shè)置初始值,然后用公式更新所有狀態(tài)的價(jià)值函數(shù),第k次迭代時(shí)的更新公式為:
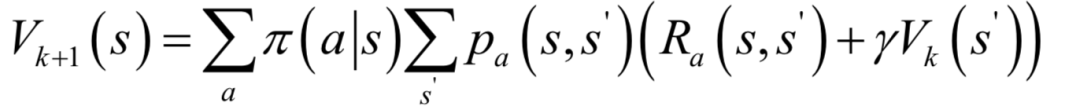
算法最后會(huì)收斂到真實(shí)的價(jià)值函數(shù)值。
策略評(píng)估的目的是為了得到更好的策略,即策略改進(jìn)。策略改進(jìn)通過按照某種規(guī)則對(duì)當(dāng)前策略進(jìn)行調(diào)整,得到更好的策略。
策略迭代是策略評(píng)估和策略改進(jìn)的結(jié)合。從一個(gè)初始策略開始,不斷的改進(jìn)這個(gè)策略達(dá)到最優(yōu)解。每次迭代時(shí)首先用策略估計(jì)一個(gè)策略的狀態(tài)價(jià)值函數(shù),然后根據(jù)策略改進(jìn)方案調(diào)整該策略,再計(jì)算新策略的狀態(tài)價(jià)值函數(shù),如此反復(fù)直到收斂。這一過程如下圖所示:
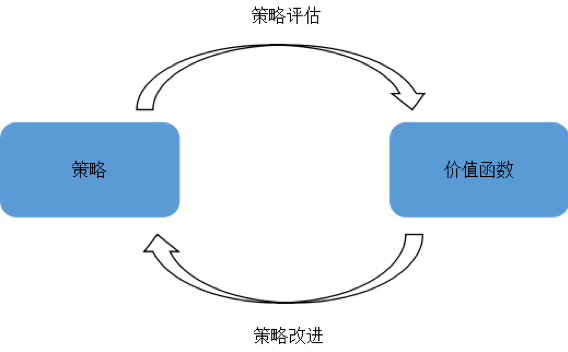
在策略迭代算法中,策略評(píng)估的計(jì)算量很大,需要多次掃描所有狀態(tài)并不斷的更新狀態(tài)價(jià)值函數(shù)。實(shí)際上不需要知道狀態(tài)價(jià)值函數(shù)的精確值也能迭代到最優(yōu)策略,值迭代就是其中的一種方法。
根據(jù)貝爾曼最優(yōu)化原理,如果一個(gè)策略是最優(yōu)策略,整體最優(yōu)的解局部一定也最優(yōu),因此最優(yōu)策略可以被分解成兩部分:從狀態(tài)s到 采用了最優(yōu)動(dòng)作,在狀態(tài)
采用了最優(yōu)動(dòng)作,在狀態(tài)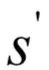 是采用的策略也是最優(yōu)的。根據(jù)這一原理,每次選擇當(dāng)前回報(bào)和未來回報(bào)之和最大的動(dòng)作,價(jià)值迭代的更新公式為:
是采用的策略也是最優(yōu)的。根據(jù)這一原理,每次選擇當(dāng)前回報(bào)和未來回報(bào)之和最大的動(dòng)作,價(jià)值迭代的更新公式為:
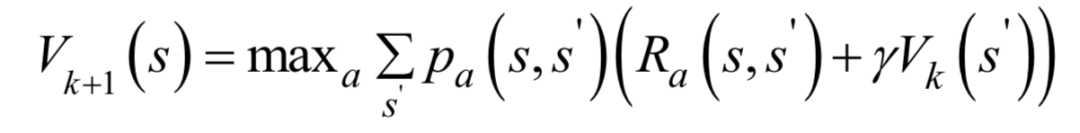
策略迭代算法和價(jià)值迭代算法雖然都可以得到理論上的最優(yōu)解,但是它們的計(jì)算過程依賴于狀態(tài)轉(zhuǎn)移概率以及回報(bào)函數(shù)。對(duì)于很多應(yīng)用場景,我們無法得到準(zhǔn)確的狀態(tài)模型和回報(bào)函數(shù)。因此前面介紹的這兩種算法在實(shí)際問題中使用價(jià)值有限。
對(duì)于無法建立精確的環(huán)境模型的問題,我們只能根據(jù)一些狀態(tài)、動(dòng)作、回報(bào)值序列樣本進(jìn)行計(jì)算,估計(jì)出價(jià)值函數(shù)和最優(yōu)策略。基本思想是按照某種策略嘗試執(zhí)行不同的動(dòng)作,觀察得到的回報(bào),然后進(jìn)行改進(jìn)。
蒙特卡洛算法和時(shí)序差分算法是解決這這類問題的兩種方法。蒙特卡洛算法是一種隨機(jī)數(shù)值算法,它通過使用隨機(jī)數(shù)來近似解決某些難以直接求解的問題。在強(qiáng)化學(xué)習(xí)中,蒙特卡洛算法可以根據(jù)樣本得到狀態(tài)價(jià)值函數(shù)以及動(dòng)作價(jià)值函數(shù)的估計(jì)值,用于近似數(shù)學(xué)期望值。
在上面的例子中,樣本是一些隨機(jī)的點(diǎn),在用于計(jì)算強(qiáng)化學(xué)習(xí)的價(jià)值函數(shù)時(shí),樣本是一些片段。在這里先定義片段(episode)的概念,它是從某一狀態(tài)開始,執(zhí)行一些動(dòng)作,直到終止?fàn)顟B(tài)為止的一個(gè)完整的狀態(tài)和動(dòng)作序列,這類似于循環(huán)神經(jīng)網(wǎng)絡(luò)中的時(shí)間序列樣本。蒙特卡洛算法從這些片段樣本中學(xué)習(xí),估算出狀態(tài)價(jià)值函數(shù)和動(dòng)作價(jià)值函數(shù)。實(shí)現(xiàn)時(shí)的做法非常簡單:
按照一個(gè)策略執(zhí)行,得到一個(gè)狀態(tài)和回報(bào)序列,即片段。多次執(zhí)行,得到多個(gè)片段。接下來根據(jù)這些片段樣本估計(jì)出價(jià)值函數(shù)。
蒙特卡洛算法需要使用完整的片段進(jìn)行計(jì)算,這在有些問題中是不現(xiàn)實(shí)的,尤其是對(duì)于沒有終止?fàn)顟B(tài)的問題。時(shí)序差分算法(Temporal Difference learning,簡稱TD學(xué)習(xí))在執(zhí)行一個(gè)動(dòng)作之后就進(jìn)行價(jià)值函數(shù)估計(jì),無需使用包括終止?fàn)顟B(tài)的完整片段,它結(jié)合了蒙特卡洛算法與動(dòng)態(tài)規(guī)劃算法的思想。與蒙特卡洛算法一樣,TD算法無需依賴狀態(tài)轉(zhuǎn)移概率,直接采樣計(jì)算。TD算法用貝爾曼方程估計(jì)價(jià)值函數(shù)的值,然后構(gòu)造更新項(xiàng)。迭代更新公式為:
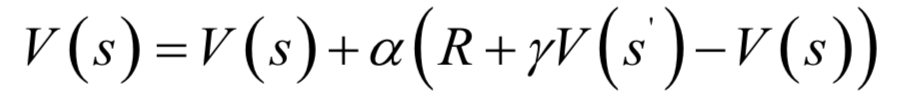
算法用當(dāng)前動(dòng)作的立即回報(bào)值與下一狀態(tài)當(dāng)前的狀態(tài)價(jià)值函數(shù)估計(jì)值之和構(gòu)造更新項(xiàng),更新本狀態(tài)的價(jià)值函數(shù):
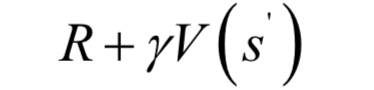
在上式中沒有使用狀態(tài)轉(zhuǎn)移概率,而是和蒙特卡洛算法一樣隨機(jī)產(chǎn)生一些樣本來進(jìn)行計(jì)算,因此稱為無模型的算法。用于估計(jì)狀態(tài)價(jià)值函數(shù)時(shí),算法的輸入為策略,輸出為該策略的狀態(tài)值函數(shù)。
Sarsa算法用于估計(jì)給定策略下的動(dòng)作價(jià)值函數(shù),同樣是每次執(zhí)行一個(gè)動(dòng)作之后就進(jìn)行更新。它的迭代更新公式為:
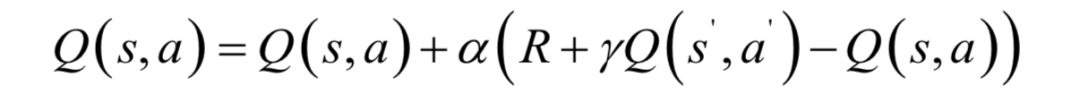
由于更新值的構(gòu)造使用了
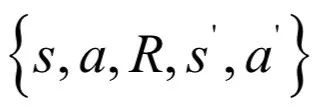
這5個(gè)變量,因此被命名為Sarsa算法。根據(jù)所有狀態(tài)-動(dòng)作對(duì)的價(jià)值函數(shù)可以得到最優(yōu)策略。
Q學(xué)習(xí)算法估計(jì)每個(gè)動(dòng)作價(jià)值函數(shù)的最大值,通過迭代可以直接找到價(jià)值函數(shù)的極值,從而確定最優(yōu)策略,類似于價(jià)值迭代算法的思想。
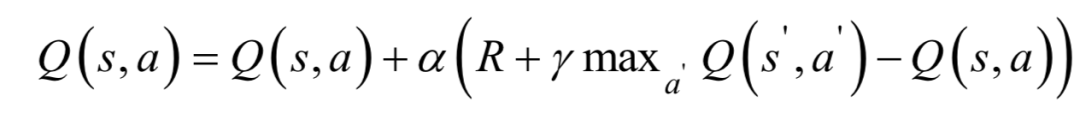
實(shí)現(xiàn)時(shí)需要根據(jù)當(dāng)前的動(dòng)作價(jià)值函數(shù)的估計(jì)值為每個(gè)狀態(tài)選擇一個(gè)動(dòng)作來執(zhí)行,這里有兩種方案。第一種方案是隨機(jī)選擇一個(gè)動(dòng)作,這稱為探索(exploration)。第二種方案是根據(jù)當(dāng)前的動(dòng)作函數(shù)值選擇一個(gè)價(jià)值最大的動(dòng)作執(zhí)行:
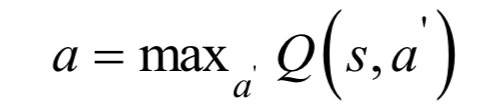
這稱為利用(exploitation)。第三種方案是二前兩者的結(jié)合,即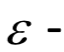 貪心策略。執(zhí)行完動(dòng)作之后,進(jìn)入狀態(tài)
貪心策略。執(zhí)行完動(dòng)作之后,進(jìn)入狀態(tài)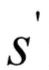 ,然后尋找狀態(tài)
,然后尋找狀態(tài)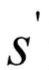 下所有動(dòng)作的價(jià)值函數(shù)的極大值,構(gòu)造更新項(xiàng)。算法最終會(huì)收斂到動(dòng)作價(jià)值函數(shù)的最優(yōu)值。用于預(yù)測時(shí),在每個(gè)狀態(tài)下選擇函數(shù)值最大的動(dòng)作執(zhí)行,這就是最優(yōu)策略,具體實(shí)現(xiàn)時(shí)同樣可以采用
下所有動(dòng)作的價(jià)值函數(shù)的極大值,構(gòu)造更新項(xiàng)。算法最終會(huì)收斂到動(dòng)作價(jià)值函數(shù)的最優(yōu)值。用于預(yù)測時(shí),在每個(gè)狀態(tài)下選擇函數(shù)值最大的動(dòng)作執(zhí)行,這就是最優(yōu)策略,具體實(shí)現(xiàn)時(shí)同樣可以采用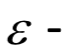 貪心策略。
貪心策略。
前面介紹的算法只能用于狀態(tài)和動(dòng)作的集合是有限的離散基且狀態(tài)和動(dòng)作數(shù)量較少的情況,狀態(tài)和動(dòng)作需要人工預(yù)先設(shè)計(jì)。實(shí)際應(yīng)用中的場景可能會(huì)很復(fù)雜,很難定義出離散的狀態(tài);即使能夠定義,數(shù)量也非常大,無法用數(shù)組存儲(chǔ)。用一個(gè)函數(shù)來逼近價(jià)值函數(shù)或策略函數(shù)成為解決這個(gè)問題的一種思路,函數(shù)的輸入是原始的狀態(tài)數(shù)據(jù),函數(shù)的輸出是價(jià)值函數(shù)值或策略函數(shù)值。
在有監(jiān)督學(xué)習(xí)中,我們用神經(jīng)網(wǎng)絡(luò)來實(shí)現(xiàn)分類或回歸函數(shù),同樣的,也可以用神經(jīng)網(wǎng)絡(luò)可來擬合強(qiáng)化學(xué)習(xí)中的價(jià)值函數(shù)和策略函數(shù),這就是深度強(qiáng)化學(xué)習(xí)的基本思想。在這里,神經(jīng)網(wǎng)絡(luò)被用于從原始數(shù)據(jù)如圖像中直接預(yù)測出函數(shù)值。
在Q學(xué)習(xí)中用表格存儲(chǔ)動(dòng)作價(jià)值函數(shù)的值,如果狀態(tài)和動(dòng)作太多這個(gè)表將非常大,在某些應(yīng)用中也無法列舉出所有的狀態(tài)形成有限的狀態(tài)集合。解決這個(gè)問題的方法是用一個(gè)函數(shù)來近似價(jià)值函數(shù),深度Q學(xué)習(xí)用神經(jīng)網(wǎng)絡(luò)來近似動(dòng)作價(jià)值函數(shù)。網(wǎng)絡(luò)的輸入是狀態(tài),輸出是各種動(dòng)作的價(jià)值函數(shù)值。下面用一個(gè)例子進(jìn)行說明。算法要實(shí)現(xiàn)自動(dòng)駕駛,將當(dāng)前場景的圖像作為狀態(tài),神經(jīng)網(wǎng)絡(luò)的輸入是這種圖像,輸出是每個(gè)動(dòng)作對(duì)應(yīng)的Q函數(shù)值,這里的動(dòng)作是左轉(zhuǎn),右轉(zhuǎn),剎車,加油門等。顯然,神經(jīng)網(wǎng)絡(luò)輸出層的尺寸與動(dòng)作數(shù)相等。
DeepMind提出了一種用深度Q解決Atari游戲的方法,使用卷積神經(jīng)網(wǎng)絡(luò)擬合Q函數(shù),稱為深度Q網(wǎng)絡(luò)(簡稱DQN)。網(wǎng)絡(luò)的輸入為經(jīng)過處理后游戲圖像畫面,原始的畫面是210x160的彩色圖像,每個(gè)像素的值為[0, 255]之間的整數(shù),所有可能的狀態(tài)數(shù)為:
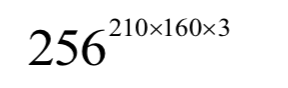
這個(gè)規(guī)模的矩陣無法直接用表格存儲(chǔ)。網(wǎng)絡(luò)的輸出值是在輸入狀態(tài)下執(zhí)行每個(gè)動(dòng)作的Q函數(shù)值,在這里有18個(gè)值,代表游戲中的18種動(dòng)作。神經(jīng)網(wǎng)絡(luò)用于近似最優(yōu)Q函數(shù):
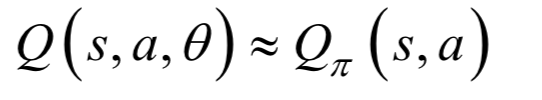
其中是網(wǎng)絡(luò)的參數(shù)。網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
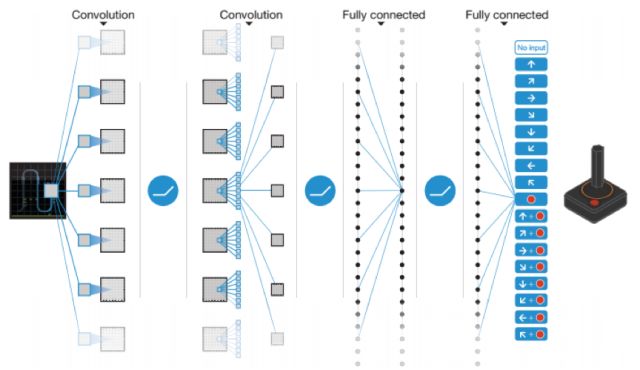
關(guān)鍵問題是訓(xùn)練樣本標(biāo)簽值的與損失函數(shù)的設(shè)計(jì)。這里的目標(biāo)是逼近最優(yōu)策略的Q函數(shù)值,因此可以采用Q學(xué)習(xí)的做法。損失函數(shù)用神經(jīng)網(wǎng)絡(luò)的輸出值與Q學(xué)習(xí)每次迭代時(shí)的更新值構(gòu)造,定義為:
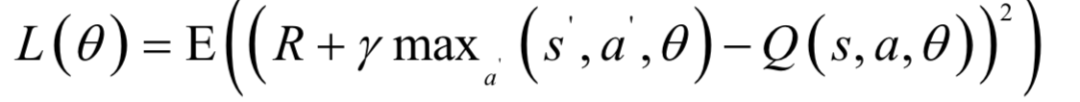
在這里采用了歐氏距離損失,是神經(jīng)網(wǎng)絡(luò)的輸出值與Q函數(shù)估計(jì)值之間的誤差,與Q學(xué)習(xí)中的更新項(xiàng)相同。另一個(gè)問題是如何得到訓(xùn)練樣本,和Q學(xué)習(xí)類似,可以通過執(zhí)行動(dòng)作來生成樣本。實(shí)現(xiàn)時(shí),用當(dāng)前的神經(jīng)網(wǎng)絡(luò)進(jìn)行預(yù)測,得到所有動(dòng)作的價(jià)值函數(shù),然后按照策略選擇一個(gè)動(dòng)作執(zhí)行,得到下一個(gè)狀態(tài)以及回報(bào)值,以此作為訓(xùn)練樣本。
這里還使用了經(jīng)驗(yàn)回放(Experience Replay)技術(shù)。神經(jīng)網(wǎng)絡(luò)要求訓(xùn)練樣本之間獨(dú)立同分布,而Atari游戲的訓(xùn)練樣本是一個(gè)時(shí)間序列,前后具有相關(guān)性。解決這個(gè)問題的做法是經(jīng)驗(yàn)池,將樣本存儲(chǔ)在一個(gè)集合中,然后從中隨機(jī)采樣得到每次迭代所用的訓(xùn)練樣本。
深度Q學(xué)習(xí)基于動(dòng)作價(jià)值函數(shù),它用神經(jīng)網(wǎng)絡(luò)擬合Q函數(shù)的最優(yōu)值,通過函數(shù)值間接得到最優(yōu)策略。如果動(dòng)作集合是連續(xù)的或維數(shù)很高,這種方法將面臨問題。例如算法要控制機(jī)器人在和方向上移動(dòng),每個(gè)方向上的移動(dòng)距離是[-1.-, +1.0]之間的實(shí)數(shù),移動(dòng)距離無法窮舉出來離散化成動(dòng)作集合,因此無法使用基于價(jià)值函數(shù)的方法。此時(shí)可以讓神經(jīng)網(wǎng)絡(luò)根據(jù)輸入的狀態(tài)直接輸出和方向的移動(dòng)距離,從而解決連續(xù)性動(dòng)作問題。
策略梯度(Policy Gradient)算法是這種思想的典型代表,策略函數(shù)網(wǎng)絡(luò)的輸入是圖像之類的原始數(shù)據(jù)。策略函數(shù)根據(jù)這個(gè)輸入狀態(tài)直接預(yù)測出要執(zhí)行的動(dòng)作:
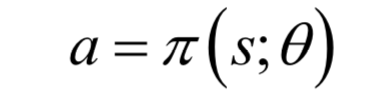
其中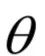 是神經(jīng)網(wǎng)絡(luò)的參數(shù)。對(duì)于隨機(jī)性策略,神經(jīng)網(wǎng)絡(luò)的輸出是執(zhí)行每種動(dòng)作的概率值:
是神經(jīng)網(wǎng)絡(luò)的參數(shù)。對(duì)于隨機(jī)性策略,神經(jīng)網(wǎng)絡(luò)的輸出是執(zhí)行每種動(dòng)作的概率值:
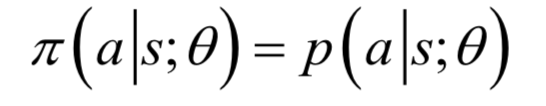
這是一種更為端到端的方法,神經(jīng)網(wǎng)絡(luò)的映射定義了在給定狀態(tài)的條件下執(zhí)行每種動(dòng)作的概率,根據(jù)這些概率值進(jìn)行采樣可以得到要執(zhí)行的動(dòng)作。對(duì)于離散的動(dòng)作,神經(jīng)網(wǎng)絡(luò)的輸出層神經(jīng)元數(shù)量等于動(dòng)作數(shù),輸出值為執(zhí)行每個(gè)動(dòng)作的概率。對(duì)于連續(xù)型動(dòng)作,神經(jīng)網(wǎng)絡(luò)的輸出值為高斯分布的均值和方差,動(dòng)作服從此分布。
這里的關(guān)鍵問題是構(gòu)造訓(xùn)練樣本和優(yōu)化目標(biāo)函數(shù),在這兩個(gè)問題解決之后剩下的就是標(biāo)準(zhǔn)的神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程。在樣本生成問題上,策略梯度算法采用的做法和DQN類似,用神經(jīng)網(wǎng)絡(luò)當(dāng)前的參數(shù)對(duì)輸入狀態(tài)進(jìn)行預(yù)測,根據(jù)網(wǎng)絡(luò)的輸出結(jié)果確定出要執(zhí)行的動(dòng)作,接下來執(zhí)行這個(gè)動(dòng)作,得到訓(xùn)練樣本,并根據(jù)反饋結(jié)果調(diào)整網(wǎng)絡(luò)的參數(shù)。如果最后導(dǎo)致負(fù)面的回報(bào),則更新網(wǎng)絡(luò)的參數(shù)使得在面臨這種輸入時(shí)執(zhí)行此動(dòng)作的概率降低;否則加大這個(gè)動(dòng)作的執(zhí)行概率。策略梯度算法在優(yōu)化目標(biāo)上和深度Q學(xué)習(xí)不同,深度Q學(xué)習(xí)是逼近最優(yōu)策略的Q函數(shù),而策略梯度算法是通過最大化回報(bào)而逼近最優(yōu)策略。
-
函數(shù)
+關(guān)注
關(guān)注
3文章
4333瀏覽量
62686 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8422瀏覽量
132714 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5504瀏覽量
121221
原文標(biāo)題:【算法地圖】一張地圖帶你玩轉(zhuǎn)機(jī)器學(xué)習(xí)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器學(xué)習(xí)之高級(jí)算法課程學(xué)習(xí)總結(jié)
如何區(qū)分深度學(xué)習(xí)與機(jī)器學(xué)習(xí)

系統(tǒng)機(jī)器學(xué)習(xí)算法總結(jié)知識(shí)分享
機(jī)器學(xué)習(xí)算法常用指標(biāo)匯總

機(jī)器學(xué)習(xí)和深度學(xué)習(xí)有什么區(qū)別?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論