 新的深度神經網絡模型命名為CODEnn
新的深度神經網絡模型命名為CODEnn
在軟件開發過程中,經常需要進行代碼搜索。然而,現有的代碼搜索方法大都將代碼視作文本,依賴源代碼和自然語言查詢的文本相似性。由于缺乏對查詢和源代碼的語義的理解,在某些場景下,無法返回期望的結果。
例如,下面這段代碼讀取xml文檔:
publicstatic < S > S deserialize(Class c, File xml) {
try {
JAXBContext context = JAXBContext.newInstance(c);
Unmarshaller unmarshaller = context.createUnmarshaller();
S deserialized = (S) unmarshaller.unmarshal(xml);
return deserialized;
} catch (JAXBException ex) {
log.error("Error-deserializing-object-from-XML", ex);
returnnull;
}
}
然而,由于代碼中并不包含“讀取”(read)一詞,因此現存的方法可能無法成功返回這一代碼片段。
有鑒于此,HKUST和微軟研究院的研究人員顧小東、Hongyu Zhang、Sunghun Kim最近發表論文,使用深度神經網絡,學習源代碼和自然語言查詢的統一向量表示,以支持代碼語義搜索。
CODEnn
研究人員將其新提出的深度神經網絡模型命名為CODEnn(Code-Description Embedding Neural Network,代碼-描述嵌入神經網絡)。CODEnn的主要思路是將代碼片段和自然語言查詢聯合嵌入一個統一的向量空間,使查詢嵌入和相應的代碼片段嵌入為相近的向量(可以通過向量相似度匹配)。
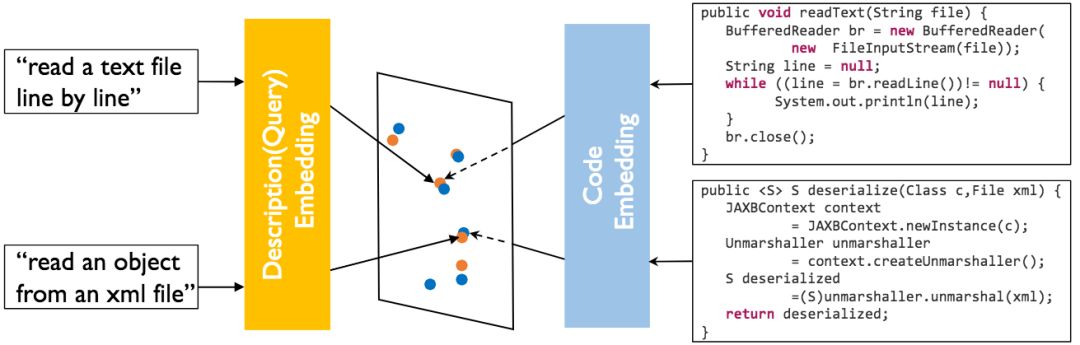
聯合嵌入
首先讓我們簡單溫習一下聯合嵌入的概念。
聯合嵌入(joint embedding),又稱多模態嵌入(multi-modal embedding),可以將異構數據嵌入統一的向量空間,使得模態不同而語義相似的概念在空間中占據相近區域。形式化地表述為:
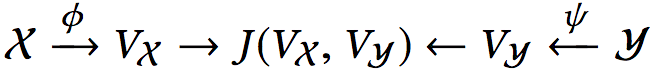
其中,φ、ψ為嵌入函數,J衡量相似度。
在CODEnn中,φ為源代碼嵌入網絡(CoNN),ψ為自然語言描述嵌入網絡(DeNN),J為余弦相似度。
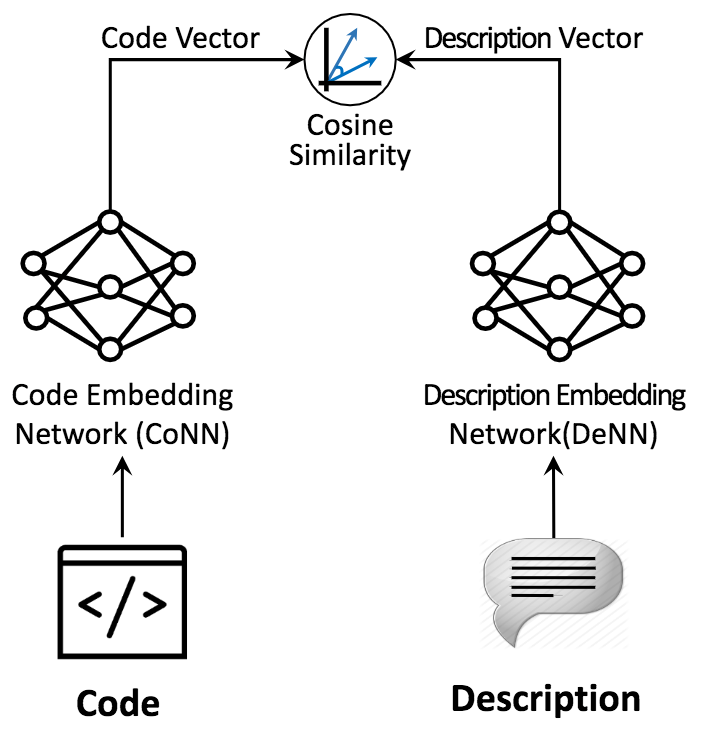
具體架構
具體而言,CODEnn的嵌入網絡主要使用了循環神經網絡(RNN)和最大池化,架構如下:
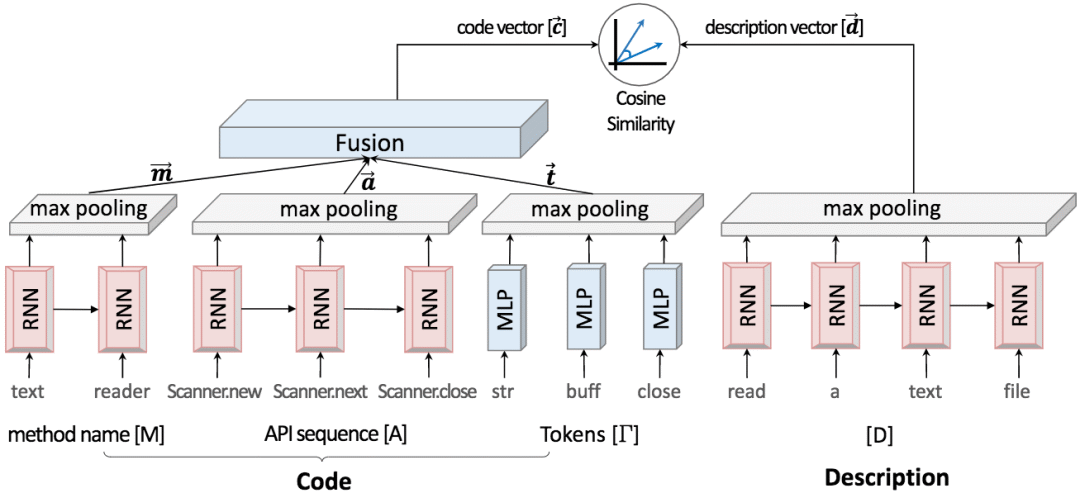
從上圖我們可以看到,正如我們之前提到的那樣,網絡架構分為三個模塊。下面我們將從上往下,從右向左地依次說明這三個模塊:
相似度模塊
DeNN
CoNN
相似度模塊
這是最簡單的模塊,將代碼和相應描述轉換為向量后,通過這一模塊衡量兩者的相似度。具體而言,使用的是余弦相似度:
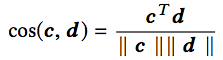
DeNN
DeNN將自然語言描述嵌入為向量。DeNN使用循環神經網絡(tanh激活)和最大池化完成嵌入:
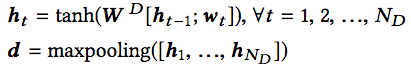
CoNN
由于代碼不是簡單的純文本,包含多種結構性信息。因此,CoNN的架構要比DeNN復雜。
CoNN考慮代碼的三個方面:
方法名
API調用序列
代碼中包含的token
從每個代碼片段中提取以上三方面的信息后,分別嵌入,然后融合成單個向量表示。
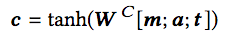
上式中,c為整個代碼片段的向量表示,m、a、t分別為方法名、API調用序列、token的嵌入向量表示。
方法名的嵌入和DeNN類似,同樣使用循環神經網絡(tanh激活)和最大池化:
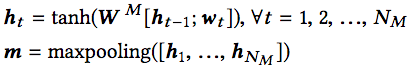
API調用序列的嵌入同理:
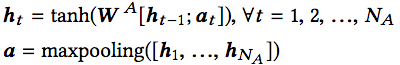
token的嵌入有所不同。因為并不在意token的順序,也就是說,不把token作為序列數據,所以就不使用循環神經網絡了。使用的是多層感知器(MLP),也就是普通的全連接層。不過仍然搭配了tanh激活和最大池化:
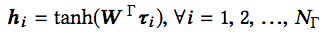
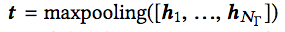
模型訓練
CODEnn接受代碼、描述作為輸入,預測其嵌入表示的余弦相似度。具體而言,每個訓練樣本為一個三元組(C, D+, D-),其中C為代碼片段,D+為正面樣本(C的正確描述),D-為負面樣本(隨機選取的不正確描述)。訓練時,CODEnn預測(C, D+)和(C, D-)的余弦相似度,并最小化以下損失:
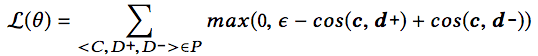
上式中,θ為模型參數,P為訓練數據集,c、d+、d-為C、D+、D-的嵌入向量,ε為邊緣常數,在研究人員的試驗中,ε的值定為0.05. 從直覺上說,最小化以上損失,將鼓勵代碼片段和正確描述的余弦相似度提高,代碼片段和錯誤描述的余弦相似度下降。
下面是一些實現的細節:
循環神經網絡選用的是雙向LSTM,每個雙向LSTM在每個方向上有200個隱藏單元。
詞嵌入維度為100.
嵌入token的MLP有100個隱藏單元。
融合代碼片段不同方面的MLP有400個隱藏單元。
優化算法為mini-batch Adam,batch大小為128.
詞匯量限制為10000(10000個訓練集中最常用的單詞)。
模型基于Keras構建。
在單塊Nvidia K40 GPU上,訓練耗時約50小時(500個epoch)。
收集訓練語料
CODEnn模型需要大規模的訓練語料,語料包括代碼元素和相應的描述,即(方法名, API調用序列, token, 描述)元組。

研究人員利用GitHub上的開源項目準備語料:
下載了GitHub上所有創建于2008年8月至2016年6月的Java項目。
排除所有未加星的項目,以移除玩具項目和試驗性項目。
選取帶有文檔注釋的Java方法(Java中的文檔注釋以/**開始,以*/收尾)。
最終收集到了18233872個Java方法。
Java方法名的提取很簡單,根據駝峰原則解析即可,例如,listFiles將被解析為list和files。
API調用序列的提取要復雜一點。研究人員使用Eclipse JDT編譯器解析了AST,并根據如下規則生成API調用序列:
new C()->C.new
o.m()->C.m(o為類C的實例)
方法調用作為參數傳入時,傳入的方法調用在前:o1.m1(o2.m2(), o3.m3())->C2.m2-C3.m3-C1.m1
提取語句序列s1;s2;...;sN中每個語句si的方法調用序列ai,并連接:a1-a2-...-aN
條件語句的調用序列包括所有分支:if (s1) {s2;} else {s3}->a1-a2-a3
循環語句:while (s1) {s2;}->a1-a2
token提取,同樣根據駝峰原則解析方法主體,并移除重復token。同時也移除了一些停止詞(例如the、in)和Java關鍵字,因為這些詞在源代碼中頻繁出現,區分性不好。
描述提取,也用到了Eclipse JDT編譯器,從AST提取JavaDoc注釋。根據Javadoc指導原則,JavaDoc注釋的第一句話通常是方法的概述,因此研究人員將JavaDoc注釋的第一句話作為描述。

一個提取的例子
DeepCS
研究人員基于CODEnn模型創建了一個代碼搜索工具DeepCS。給定自然語言查詢,DeepCS會建議最相關的K個代碼片段。DeepCS系統包含三個主要階段:
離線訓練
離線代碼嵌入
在線代碼搜索
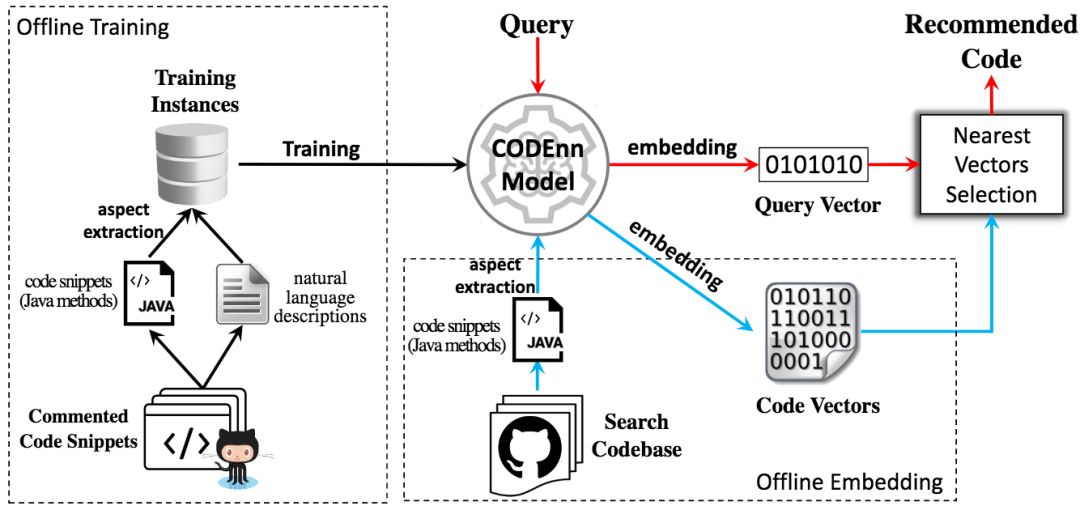
DeepCS事先將代碼庫中的所有代碼片段嵌入為向量(使用訓練好的CODEnn模型的CoNN模塊)。在線搜索時,當開發者輸入自然語言查詢時,DeepCS首先使用訓練好的CODEnn模型的DeNN模塊將查詢嵌入為向量,然后估計查詢向量和所有代碼向量的余弦相似度,并返回相似度最高的K個(比如,10個)代碼片段作為搜索結果。
試驗
試驗設置
為了更好地評估模型的表現,研究人員使用了不同于訓練語料的獨立代碼庫。研究人員選取了GitHub上至少有20星的Java項目。和訓練語料不同,測試數據集包含所有代碼(包括那些沒有Javadoc注釋的代碼)。總共收集了9950個項目,從中得到了16262602個方法。
研究人員從Stack Overflow問答網站中選取了得票最高的Java編程問題,并手工檢查了這些問題,確保其符合標準:
這個問題關于一項具體的Java編程任務。研究人員剔除了描述含糊抽象的問題,比如“加載JNI庫失敗”,“StringBuilder和StringBuffer的區別是什么?”,“為什么Java有transient域?”
接受的答案包含Java代碼片段。
不與之前的問題重復。
評估指標
兩個開發者獨立地查看搜索結果,并標注其相關性。接著互相討論不一致的標簽,并重新標注。重復這一過程,直到達成共識。
研究人員使用了4個常用的指標衡量代碼搜索的有效性。其中2個指標衡量單次代碼搜索查詢的有效性:
FRank首個命中結果在結果列表中的位置。由于用戶從上往下查看結果,因此較小的FRank值意味著找到所需結果需要花費的精力較少。
Precision at k衡量k個返回結果中相關結果所占的比例。

Precision at k很重要,因為開發者經常會查看多個結果,良好的帶嗎搜索引擎應該避免給開發者過多的噪聲。Precision at k越高,代碼搜索的表現就越好。研究人員評估了k值為1、5、10時的Precision at k.
另外兩個指標衡量一組查詢的表現:
SuccessRate at k衡量在前k個結果中命中結果的比例。
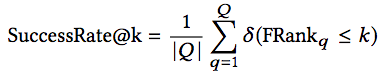
其中,Q為查詢集合,δ函數在輸入為真時返回1,否則返回0. SuccessRate at k越高,代碼搜索的總體表現就越好。和Precision at k一樣,研究人員評估了k值為1、5、10時的SuccessRate at k.
MRR是一組查詢中FRank倒數的平均數。MRR越高,代碼搜索的總體表現就越好。
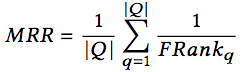
評測對比
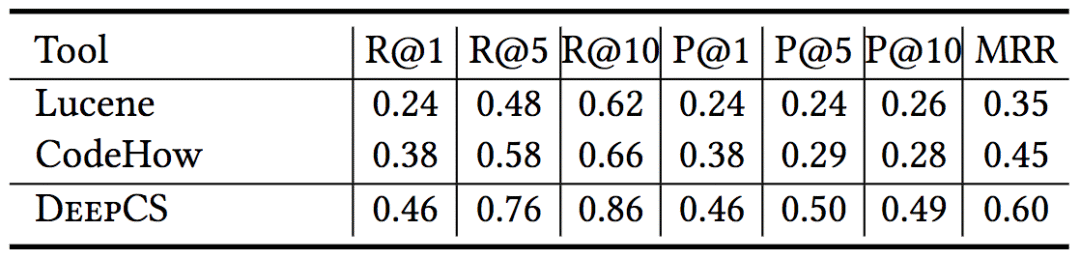
研究人員對比了CodeHow(當前最先進的代碼搜索引擎)和Lucene(許多代碼搜索工具使用的流行文本搜索引擎)的表現:
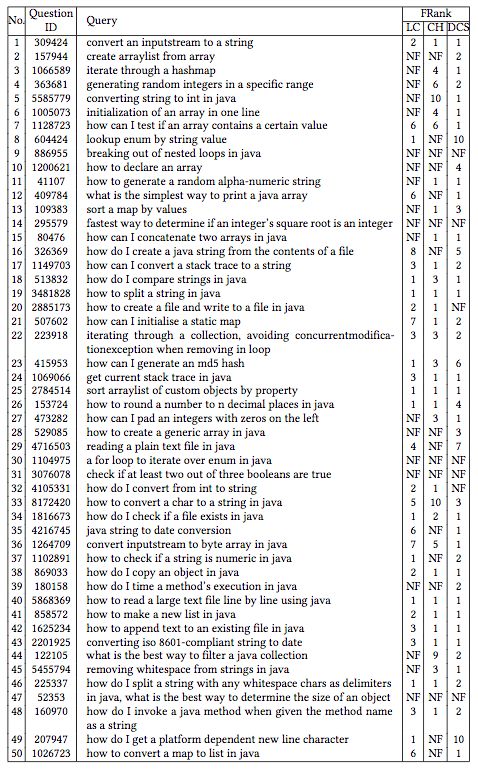
上表中,NF表示未找到,LC表示Lucene,CH表示CodeHow,DCS表示DeepCS。
從上表我們可以看到,一般來說,相比Lucene和CodeHow,DeepCS能返回更相關的結果。統計數據也證實了這一點。
例子
為了演示DeepCS的優勢,研究人員提供了一些具體的例子。

上面的兩個查詢中,第一個queue是動詞(加入隊列),第二個queue是名詞(隊列)。普通的文本搜索引擎很難區分兩者,而DeepCS成功理解了兩者的不同。

上面這個例子展示了DeepCS的魯棒性。CodeHow返回了很多與查詢中不太重要的單詞(比如specified和character)相關的結果,而DeepCS可以成功識別不同關鍵詞的重要性,理解查詢的關鍵點。

這個例子展示了DeepCS能夠理解查詢的語義。盡管代碼片段中不包含查詢中的關鍵詞“read”(讀取)和“song”(歌曲),DeepCS仍然找到了語義相關的結果,“deserialize”(反序列化)和“voice”(聲音)。
當然,DeepCS有時可能會返回不夠精確的結果。

上圖中的查詢語句為“生成md5”,精確結果在返回結果列表中排在第7,而部分相關的結果(生成校驗值)卻排在結果列表的前面。研究人員打算以后在模型中加入更多代碼特征(例如上下文環境),以進一步提升表現。
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100995 -
源代碼
+關注
關注
96文章
2946瀏覽量
66840 -
自然語言
+關注
關注
1文章
289瀏覽量
13376
原文標題:ICSE 2018:港科大、微軟研究院提出深度學習代碼搜索模型
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從AlexNet到MobileNet,帶你入門深度神經網絡
深度神經網絡是什么
如何構建神經網絡?
基于深度神經網絡的激光雷達物體識別系統
卷積神經網絡模型發展及應用
深度神經網絡模型的壓縮和優化綜述






 工商網監
工商網監
評論