 用人類智商測試題檢驗神經網絡的抽象推理能力
用人類智商測試題檢驗神經網絡的抽象推理能力
編者按:雖然神經網絡模型近年來在機器學習問題上取得了令人印象深刻的成果,但無數實踐也證實,這類模型很難進行抽象概念推理。即便是聲稱擁有良好“泛化”能力的模型,究其本質,也只能解決某幾類問題。今天,DeepMind發布了一項新成果,用人類智商測試題檢驗神經網絡的抽象推理能力,雖然這些模型的準確率都挺高,但它們卻也顯示了“泛化”這個詞的虛假性。
抽象推理——在介紹方法前,我們首先要理解這個概念,它可以參照古希臘學者阿基米德的著名事跡:Eureka。
一次,國王請阿基米德在不破壞王冠的前提下測量它是否摻假,這使他頭疼不已。洗澡時,他發現當自己坐進浴盆里后,水會溢出來,這使他想到:溢出來的水的體積正好應該等于他身體的體積,這意味著,不規則物體的體積可以精確的被計算。如果工匠往王冠里摻了假,這個王冠的體積就和原材料的體積不一樣。想到這里,阿基米德快樂地裸奔進了城里,并邊跑邊喊叫著“Eureka!尤里卡!”!
通過意識到溢出的水等于物體體積,阿基米德在概念層面理解了體積,并解決了不規則形狀物體的體積計算問題。這就是我們要探討的抽象推理。
我們希望人工智能也能有類似的能力,雖然目前一些系統已經可以在復雜戰略游戲中擊敗世界冠軍,但它們在其他看似簡單的問題上卻宛如“智障”,特別是需要在新環境中重新應用抽象概念時。舉個例子,如果之前我們是用三角形訓練AI系統的 ,那么即便訓練到最佳狀態,如果我們把三角形換成正方形、圓形,這個AI就什么都不會了。
因此,為了構建更好、更智能的系統,了解神經網絡處理抽象概念的方式和弱點非常重要。我們從人類智商測試中汲取靈感,發現了一種量化抽象推理的方法。
創建抽象推理數據集
在介紹數據集前,讀者不妨先來測測自己的智商:

01
已知九宮格中的最后一幅圖缺失,請從下列8個選項中選出最合適的一個,使之呈現一定的規律性。
點擊空白處查看答案
答:計數圓點數量:第一行2,3,4,第二行3,4,5,第三行2,3,?。由此規律可得,最后一幅圖應該有4個圓點,選擇A。
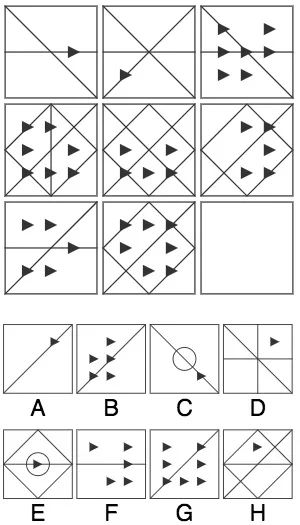
02
已知九宮格中的最后一幅圖缺失,請從下列8個選項中選出最合適的一個,使之呈現一定的規律性。
點擊空白處查看答案
答:首先,縱向來看,每一列都包含1個三角形、5個三角形、7個三角形三種圖案,所以最后一幅圖應該只有1個三角形,答案可能是A、C、D、E、H。其次,橫向來看,第一行三幅圖都有一條橫線、一條左上-右下的斜線,第二行都有一個正方形,以及一條右上-左下的斜線,而第三行兩幅圖的相同點是都有一條右上-左下的斜線。綜上,選擇A。
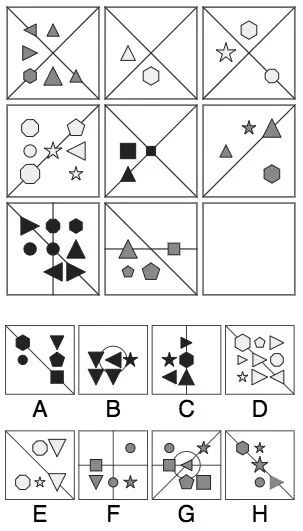
03
已知九宮格中的最后一幅圖缺失,請從下列8個選項中選出最合適的一個,使之呈現一定的規律性。
點擊空白處查看答案
答:首先,和上一題的推理方法類似,縱向來看三列都是等差數列,最后一幅圖應該包含5個圖形;橫向來看,最后一行都有一條左上-右下的斜線,答案可能是A、E、H。其次,我們看顏色,圖中有白、灰、黑三種填色,每列都包含這三種,所以最后一幅圖的圖形應該是黑色的。綜上,選擇A。
如上所示,我們在進行標準智商測試時,即便只是看幾個簡單圖形回答問題,我們也要結合日常學習到的經驗。比方說,看著不斷長高的樹木或是拔地而起的高樓,我們可以理解什么是“演變”(progressions);通過不斷積累數學知識,我們可以理解什么是“演變”;通過查看自己銀行賬戶上的定期利息,我們也能感受到“演變”(表示屬性增加的概念)。有了這個基礎,我們就能在解答上述問題時應用這一概念,推斷圖形數量、大小、顏色的順序性演變。
但我們的機器學習系統還沒有類似的“日常體驗”,這也意味著我們沒法輕易衡量它是怎么把現實世界知識用于解決抽象問題的。盡管如此,有了這些智商測試題,我們也能創建一個實驗設置,來測一測現有模型的“智商”。需要注意的是,由于日常生活太復雜,這里我們用的是圖形推理問題,考驗的是模型如何用抽象推理把這題的解題思路推廣到下一題。
既然目的是讓AI做題,我們先得有題啊!當然了,手動搜集整理是不可能的,為了創建題庫,首先我們構建了一個可以自動生成推理題的生成器,它包含一組抽象元素,包括它們的顏色、大小等屬性的“演變”。雖然元素不多,但它們足以生成大量互不相同的問題。
接著,我們對生成器可用的元素和組合進行了約束,得到了包含不同問題的訓練集和測試集,換言之,就像練習冊和考卷,即便我們刷遍了練習冊上的題,但老師在考卷上出的題總是新的。舉個例子,在訓練集中,有一種演變關系只會在線上出現,但在測試集上,這種演變卻也出現在圖形上,如果模型真的掌握了這種規律,無論是線條還是圖形還是其他沒見過的東西,它應該都能活學活用。
AI能進行抽象推理的證據
在實驗中,訓練數據和測試數據是從同一基礎分布中采樣的,即“考試”時都是常規題,難度沒有提高,也沒有特別的“加分題”。我們測試的神經網絡都表現出了很好的泛化誤差,一些模型的準確率甚至超過75%,令人驚訝。如下圖所示,我們構建了一個可以明確計算不同圖像元素間的關系,并在這基礎上評估答案的模型WReN(Wild Relation Network),它的性能是最好的。
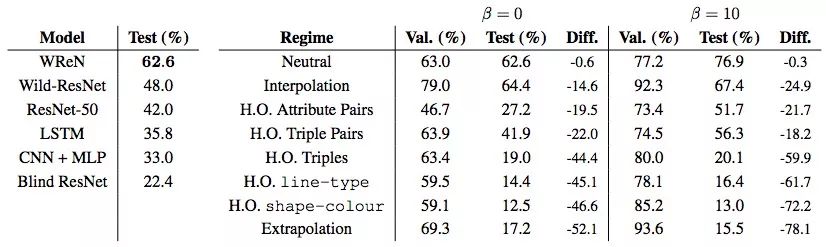
Val為訓練集,Test為測試集,β非零時表示使用了meta-target訓練,即針對各元素進行過訓練,這時模型不僅可以回答答案“是什么”,還能回答“為什么”
但這個實驗也體現了幾個問題。對于訓練集和測試集中都包含的相同的幾何演變,比如線條上的邏輯演變,神經網絡學得很好,無論線條怎么變,只要還是線條,它都能學以致用。但是如果涉及把線條的規律推廣到其他圖形上,神經網絡就表現得很差了,這也是測試集得分比較低的主因。尤其是當模型在訓練集中學到的是深色圖形演變,而我們在測試集上把深色改成了淺色,它們的性能會更差。
最后,當我們的模型不僅能預測正確答案,還能預測答案的“推理過程”時,我們發現它在訓練集、測試集上的得分更接近了,也就是泛化性能更好了。更有趣的是,我們發現,如果模型能理解圖中各元素背后的正確關系,那它預測的準確率就高,反之,準確率就低,里面存在一個正相關。這表明,當模型能正確推斷出任務背后的抽象概念時,它們可以獲得更好的性能。
注:為防止讀者誤解,這里的“預測推理過程”“了解背后元素關系”只是口語性表述,AI并不能像我們一樣一步步推理,它的“理解”也不等同于人類的理解,它只是知道,這些元素和答案有關聯。
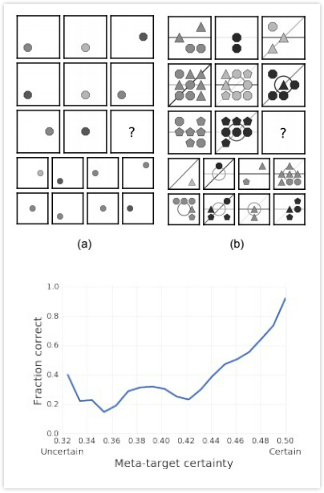
上:有些問題只包含單獨元素,但有些問題包含多種元素關系;下:WReN模型答案預測準確率和抽象概念預測準確率的關系
關于“泛化”的新認知
最近許多論文在集中探討神經網絡對于解決機器學習問題的優缺點,而大家爭論的矛頭通常是網絡的泛化能力。根據我們的研究結果,現階段關于泛化能力的討論似乎都是無益的:經測試,這些神經網絡在一些地方展現出了很好的泛化性,但在另一些地方卻表現很差。這種泛化性取決于一系列因素:
模型的架構;
模型有沒有經過針對性訓練;
模型能否為其“答案”提供可解釋的“理由”;
起碼到目前為止,只要神經網絡模型遇到的是完全不熟悉的輸入,或是完全不熟悉的元素,它的表現都難以令人滿意。這一點是非常關鍵、非常重要的,AI的抽象推理能力還有待提高,這也是未來工作中必須重視一個明確焦點。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100720 -
機器學習
+關注
關注
66文章
8408瀏覽量
132573 -
數據集
+關注
關注
4文章
1208瀏覽量
24690
原文標題:DeepMind新成果:讓AI做人類智商測試題,抽象推理能力堪憂!
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
應用人工神經網絡模擬污水生物處理
AI知識科普 | 從無人相信到萬人追捧的神經網絡
如何構建神經網絡?
基于BP神經網絡的PID控制
卷積神經網絡一維卷積的處理過程
圖像預處理和改進神經網絡推理的簡要介紹
ARM Cortex-M系列芯片神經網絡推理庫CMSIS-NN詳解
揭秘人工智能神經網絡為何無法實現人類的推理或產生意識

DeepMind提出了一種讓神經網絡進行抽象推理的新方法






 工商網監
工商網監
評論