


1 引言
人類在對客觀世界的問題進行判斷時,往往都會根據過去的經驗來指導自己。例如,為什么看到微濕的路面、感到和風、看到晚霞,就認為明天是好天了呢?這是因為在我們的生活經驗中已經見過了很多類似的情況,頭一天觀察到上述的特征后,第二天天氣通常會很好,為什么色澤青綠、根蒂蜷縮、敲聲濁響,就能判斷出是正熟的好瓜?因為我們吃過、看到過很多西瓜,所以基于色澤、根蒂、敲聲這幾個特征我們就可以做出相當好的判斷。可以看出,我們能做出有效的判斷,是因為我們已經累計了許多經驗,而通過對經驗的利用,就能對新的情況作出有效的決策。
那么上面對經驗的利用是靠我們人類自身完成的,計算機能幫忙嗎?
機器學習正是這門學科,它致力于研究如何通過計算的手段,利用經驗來改善系統自身的性能。在計算機系統中,”經驗“通常以”數據“的形式存在,因此,機器學習所研究的主要內容,是關于在計算機上從數據中產生”模型“(model)的算法,即“學習算法”(learning algorithm)。有了學習算法,我們把經驗數據提供給它,它就能基于這些數據產生模型;在面對新的情況時(例如看到一個沒有剖開的西瓜),模型會給我們提供相應的判斷(例如好瓜)。如果說計算機科學是研究關于“算法”的學問,那么類似的,可以說機器學習是研究關于“學習算法”的學問。
2 模型評估與選擇
2.1 經驗誤差與過擬合
通常我們把分類錯誤的樣本占樣本總數的比例成為“錯誤率” (error rate),即如果在 個樣本中有 個樣本分類錯誤,則錯誤率 ;相應的, 稱為“精度” (accuracy),即 “精度=1-錯誤率”。更一般的,我們把學習期的實際預測輸出與樣本的真實輸出之間的差異成為“誤差” (error),學習器在訓練集上的誤差稱為“訓練誤差” (training error) 或“經驗誤差” (empirical error),在新樣本上的誤差稱為“泛化誤差” (generalization error)。顯然,我們希望得到泛化誤差最小的學習器。然而,我們事先并不知道新樣本是什么樣,實際能做的是努力使經驗誤差最小化。在很多情況下,我們可以學得一個經驗誤差很小、在訓練集上表現很好的學習器,例如甚至對所有訓練樣本都分類正確,即分類錯誤率為零,分類精度為100%,但這是不是我們想要的學習器呢?遺憾的是,這樣的學習器在多數情況下都不好。
我們實際希望的,是在新樣本上能表現得很好的學習器。為了達到這個目的,應該從訓練樣本中盡可能學出適用于所有潛在樣本的“普遍規律”,這樣才能在遇到新樣本時做出正確的判斷。然而,當學習器把訓練樣本學得“太好”的時候,很可能已經把訓練樣本自身的一些特點當做了所有潛在樣本都會具有的一般性質,這樣就會導致泛化能力下降。這種現象在機器學習中稱為“過擬合” (overfitting)。與“過擬合”相對的是“欠擬合” (underfitting),這是指對訓練樣本的一般性質尚未學好。
有很多因素可能導致過擬合,其中最常見的情況是由于學習能力過于強大,以至于把訓練樣本所包含的不太一般的特性也都學習到了,而欠擬合則通常是由于學習能力低下而造成的。欠擬合比較容易克服,例如在決策樹中擴展分支、在神經網絡學習中增加訓練輪數等,而過擬合則很麻煩。過擬合是機器學習面臨的關鍵障礙,各類學習算法都必然帶有一些針對過擬合的措施;然而必須認識到,過擬合是無法徹底避免的,我們所能做的只是“緩解”,或者說減小其風險。關于這一點,可大致這樣理解:機器學習面臨的問題通常是 NP 難甚至更難,而有效的學習算法必然是在多項式時間內運行完成,若克徹底避免過擬合,則通過經驗誤差最小化就能獲得最優解,這就意味著我們構造性地證明了 “P = NP”;因此,只要相信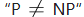 ?,過擬合就不可避免。
?,過擬合就不可避免。
在現實任務中,我們往往有很多學習算法可供選擇,甚至對同一個學習算法,當使用不同的參數匹配時,也會產生不同的模型。那么,我們該選用哪一個學習算法,使用哪一種配置參數呢?這就是機器學習中的“模型選擇” (model selection)問題。理想的解決方案當然是對候選模型的泛化誤差進行評估,然后選擇泛化誤差最小的那個模型。然而如上面所討論的,我們無法直接獲得泛化誤差,而訓練誤差又由于過擬合現象的存在而不適合作為標準,那么,在現實中如何進行模型評估與選擇呢?
2.2 評估方法
通常,我們可以通過實驗測試來對學習器的泛化誤差進行評估并進而做出選擇。為此,需要使用一個“測試集” (testing set)來測試學習器對新樣本的判別能力,然后以測試集上的“測試誤差” (testing error)作為泛化誤差的近似。通常我們假設測試樣本也是從樣本真實分布中獨立同分布采樣而得。但需要注意的是,測試集應該盡可能與訓練集互斥,即測試樣本盡量不在訓練集中出現、未在訓練過程中使用過。
測試樣本為什么要盡可能不出現在訓練集中呢?為理解這一點,不妨考慮這樣一個場景:老師出了 10 道題供同學們練習,考試時老師又用同樣的這 10 道題作為試題,這個考試成績能否有效反應出同學們學得好不好呢?答案是否定的,可能有的同學只會做這 10 道題卻能得高分。回到我們的問題上來,我們希望得到泛化性能很強的模型,好比是希望同學們對課程學得很好、獲得了對所學知識 “舉一反三” 的能力;訓練樣本相當于給同學們練習的習題,測試過程則是相當于考試。顯然,若測試樣本被用作訓練了,則得到的將是過于 “樂觀” 的估計結果。
可是,我們只有一個包含個樣例的數據集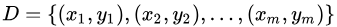 ?, 既要訓練,又要測試,怎樣才能做到呢?答案是:通過對?
?, 既要訓練,又要測試,怎樣才能做到呢?答案是:通過對?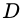 ?進行適當的處理,從中產生出訓練集 S?和測試集 T?。下面介紹幾種常見的做法。
?進行適當的處理,從中產生出訓練集 S?和測試集 T?。下面介紹幾種常見的做法。
2.2.1 留出法
“留出法”(hold-out) 直接將數據集D劃分成兩個互斥的集合,其中一一個集合作為訓練集S另一個作為測試集T,即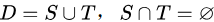 。在S上訓練出模型后,用T來評估其測試誤差,作為對泛化誤差的估計。
。在S上訓練出模型后,用T來評估其測試誤差,作為對泛化誤差的估計。
以二分類任務為例,假定D包含1000個樣本,將其劃分為S包含700個樣本, T包含300個樣本,用S進行訓練后,如果模型在T上有90個樣本分類錯誤,那么其錯誤率為90/300X100%,相應的,精度為1-30%=70%。
需注意的是,訓練/測試集的劃分要盡可能保持數據分布的一致性,避免因數據劃分過程引入額外的偏差而對最終結果產生影響,例如在分類任務中至少要保持樣本的類別比例相似。如果從采樣(sampling)的角度來看待數據集的劃分過程,則保留類別比例的采樣方式通常稱為 ”分層采樣”(stratified sampling)。例如通過對D進行分層采樣而獲得含70%樣本的訓練集S和含30% 樣本的測試集S,若D包含500個正例、500 個反例,則分層采樣得到的S應包含350個正例、350 個反例,而T 則包含150個正例和150個反例;若S、T中樣本類別比例差別很大,則誤差估計將由于訓練/測試數據分布的差異而產生偏差。
另一個需要注意的問題是,即便在給定的訓練測試集的樣本比例后,仍存在多種劃分方式對初始數據集 D 進行分割。例如在上面的例子中,可泌巴 D 中的樣本排序,然后把前 350 個正例放到訓練集中,也可以把最后 350 個正例放到訓練集中,…… 這些不同的劃分將導致不同的訓練測試集,相應的,模型評估的結果也會有差別。因此,單次使用留出法得到的估計結果往往不夠穩定可靠,在使用留出法時,一般要采用若干次隨機劃分、重復進行實驗評估后取平均值作為留出法的評估結果。佰收口進行 1 00 次隨相蒯分 r 每次產生一個訓練/測試集用于實驗評估, 100 次后就得到 1 00 個結果,而留出法返回的則是這 1 00 個結果的平均。
此外,我們希望評估的是用 D 訓練出的模型的性能,但留出法需劃創 11 練/測試集,這就會導致一個窘境( a wkward situation ) :若令訓練集 S 包含絕大多數樣本,則訓練出的模型可能更接近于用 D 訓練出的模型,但由于 T 比較小,評估結果可能不夠穩定準確;若令測試集 T 多包含一些樣本,則訓練集 S 與 D 差別更大了,被評估的模型與用 D 訓練出的模型相比可能有較大的差別,從而降低了評估結果的保真性( fidelity )。這個問題沒有完美的解決方案,常見做法是將大約 2 / 3 ~4 / 5 的樣本用于訓練,剩余樣本用于測試。
2.2.2 交叉驗證法
“交叉驗證法” (cross validation)先將數據集D劃分為k個大小相似的互斥子集,即
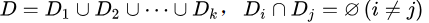 。每個子集D;都盡可能保持數據分布的一致性,即從D中通過分層采樣得到。然后,每次用k- 1個子集的并集作為訓練集,余下的那一個子集作為測試集;這樣就可獲得k組訓練測試集,從而可進行k次訓練和測試,最終返回的是這k個測試結果的均值。顯然,交叉驗證法評估結果的穩定性和保真性在很大程度上取決于k:的取值,為強調這一點,通常把交叉驗證法稱為“ k折交叉驗證”( k - foldcross validation)。? 最常用的取值是10,此時稱為10折交叉驗證;其他常用的k值有5、20等。
。每個子集D;都盡可能保持數據分布的一致性,即從D中通過分層采樣得到。然后,每次用k- 1個子集的并集作為訓練集,余下的那一個子集作為測試集;這樣就可獲得k組訓練測試集,從而可進行k次訓練和測試,最終返回的是這k個測試結果的均值。顯然,交叉驗證法評估結果的穩定性和保真性在很大程度上取決于k:的取值,為強調這一點,通常把交叉驗證法稱為“ k折交叉驗證”( k - foldcross validation)。? 最常用的取值是10,此時稱為10折交叉驗證;其他常用的k值有5、20等。
與留出法相似,將數據集 D劃分為k:個子集同樣存在多種劃分方式。為減小因樣本劃分不同而引入的差別, k折交叉驗證通常要隨機使用不同的劃分重復p次,最終的評估結果是這p次k折交叉驗證結果的均值,例如常見的有"10 次10折交叉驗證”。
假定數據集D中包含 m個樣本,若令k= m,則得到了交叉驗證法的一個特例:留一法(Leave-One-Out,簡稱LOO)。顯然,留一法不受隨機樣本劃分方式的影響,因為個樣本只有唯一的方式劃分為個子集每個子集包含一個樣本; 留一法使用的訓練集與初始數據集相比只少了一個樣本,這就使得在絕大多數情況下,留一法中被實際評估的模型與期望評估的用D訓練出的核型很相似。因此,留一法的評估結果往往被認為比較準確。然而,留一法也有其缺陷:在數據集比較大時,訓練m個模型的計算開銷可能是難以忍受的(例如數據集包含1百萬個樣本,則需要訓練1百萬個模型),而這還是在未考慮算法調參的情況下。另外,留一法的估計結果也未必永遠比其他評估方法準確; “沒有免費的午餐” 定理對實驗評估方法同樣適用。
2.2.3 自助法
我們希望評估的是用D訓練出的模型。但在留出法和交叉驗證法中,由于保留了一部分樣本用于測試,因此實際評估的模型所使用的訓練集比D小,這必然會引入一些因訓練樣本規模不同而導致的估計偏差。留一法受訓練樣本規模變化的影響較小,但計算復雜度又太高了。有沒有什么辦法可以減少訓練樣本規模不同造成的影響,同時還能比較高效地進行實驗估計呢?
“自助法”(bootstrapping)是一個比較好的解決方案,它直接以自助采樣法(bootstrapsampling)為基礎。給定包含m個樣本的數據集D ,我們對它進行采樣產生數據集D' :每次隨機從D中挑選一個樣本,將其拷貝放入D',然后再將該樣本放回初始數據集中,是的該樣本在下次采樣時仍有可能被采到;這個過程重復執行m次后,我們就得到了包含m個樣本的數據集,這就是自助采樣的結果。顯然,D中有一部分樣本會在D'中多次出現,而另一部分樣本不出現。可以做一個簡單的估計,樣本在m次采樣中始終不被采到的概率是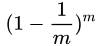 ?,取極限得到:
?,取極限得到:
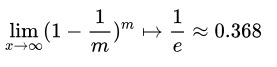
即通過自助采樣,初始數據集D中約有36.8% 的樣本未出現在采樣數據集D'中。于是我們可將D'用作訓練集, D D' 用作測試集;這樣實際評估的模型與期望評估的模型都使用m個訓練樣本,而我們仍有數據總量約1/3 的、沒在訓練集中出現的樣本用于測試。這樣的測試結果,亦稱“外包估計”(out-of-bag estimate)。
自助法在數據集較小、難以有效劃分訓練/測試集時很有用;此外, 自助法能從初始數據集中產生多個不同的訓練集,這對集成學習等方法有很大的好處。然而,自助法產生的數據集改變了初始數據集的分布,這會引入估計偏差。因此,在初始數據集足夠時,留出法和交叉驗證法更為常用一些。
2.2.4 調參與最終模型
大多數學習算法都有些參數 (parameter) 需要設定,參數配置不同,學得模型的性能往往有顯著差別。因此,在進行模型評估與選擇時,除了要對適用學習算法進行選擇,還需要對算法參數進行設定,這就是通常所說的 “參數調節” 或簡稱 “調參” (parameter tuning)。
這里需要注意一點:學習算法的很多參數是在實數范圍內取值,因此,對每種參數配置都訓練出模型來是不可行的。現實中常用的做法,是對每個參數選定一個范圍和變化步長, 例如在[0, 0.2]范圍內以0.05為步長,則實際要評估的候選參數值有5個,最終是從這5個候選值中產生選定值。顯然,這樣選定的參數值往往不是“最佳” 值,但這是在計算開銷和性能估計之間進行折中的結果,通過這個折中,學習過程才變得可行。事實上,即便在進行這樣的折中后,調參往往仍很困難。可以簡單估算一下: 假定算法有3個參數,每個參數僅考慮5個候選值,這樣對每一組訓練/測試集就有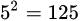
給定包含m個樣本的數據集D, 在模型評估與選擇過程中由于需要留出一部分數據進行評估測試,事實上我們只使用了-部分數據訓練模型。因此,在模型選擇完成后,學習算法和參數配置已選定,此時應該用數據集D重新訓練模型。這個模型在訓練過程中使用了所有m個樣本,這才是我們最終提交給用戶的模型。
另外,需要注意的是,我們通常把學得模型在實際使用中遇到的數據稱為測試數據,為了加以區分,模型評估與選擇中用于評估測試的數據集常稱為 “驗證集” (validation set)。例如,在研究對比不同算法的泛化性能時,我們用測試集上的判斷效果來估計模型在實際使用時的泛化能力,而把訓練數據另外劃分為訓練集和驗證集,基于驗證集上的性能來進行模型選擇和調參。
-
計算機
+關注
關注
19文章
7639瀏覽量
90424 -
機器學習
+關注
關注
66文章
8499瀏覽量
134273
原文標題:機器學習中的模型評估與選擇
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論