

Deepmind在Alphago上的成就把強化學(xué)習(xí)這一方法帶入了人工智能的主流學(xué)習(xí)領(lǐng)域,【從零開始學(xué)習(xí)】也似乎成為了拋棄人類先驗經(jīng)驗、獲取新的技能并在各類游戲擊敗人類的“秘訣”。來自斯坦福的Andrey Kurenkov對強化學(xué)習(xí)的這一基礎(chǔ)提出了質(zhì)疑。本文中,他從強化學(xué)習(xí)的基本原則及近期取得的成就說起,肯定了其成果,也指出了強化學(xué)習(xí)的基礎(chǔ)性局限。大數(shù)據(jù)文摘對本文進(jìn)行了精華編譯。
玩過棋牌游戲么?
假設(shè)你不會玩,甚至從來沒有接觸過。
現(xiàn)在你的朋友邀請你和他對戰(zhàn)一局,并且愿意告訴你玩兒法。
你的朋友很耐心,他手把手教了你下棋的步驟,但是卻始終不告訴你他所走每一步的含義,只在最后告訴你這盤棋的輸贏結(jié)果。
對局開始。由于“沒經(jīng)驗”,你一直輸。但在經(jīng)歷了多次“失敗的經(jīng)驗”后,你漸漸地發(fā)現(xiàn)了一些規(guī)律。
幾個禮拜過去了,在幾千把游戲?qū)崙?zhàn)的“磨練”下,你終于可以在對戰(zhàn)中獲得勝利。
挺傻的對吧?為什么你不直接問為什么下這個棋以及怎么下棋呢?
但是,這種學(xué)下棋的方法其實是今天大部分的強化學(xué)習(xí)方法的縮影。
什么是強化學(xué)習(xí)?
強化學(xué)習(xí)是人工智能基本的子領(lǐng)域之一,在強化學(xué)習(xí)的框架中,智能體通過與環(huán)境互動,來學(xué)習(xí)采取何種動作能使其在給定環(huán)境中的長期獎勵最大化,就像在上述的棋盤游戲寓言中,你通過與棋盤的互動來學(xué)習(xí)。
在強化學(xué)習(xí)的典型模型中,智能體只知道哪些動作是可以做的,除此之外并不知道其他任何信息,僅僅依靠與環(huán)境的互動以及每次動作的獎勵來學(xué)習(xí)。
先驗知識的缺乏意味著角色要從零開始學(xué)習(xí)。我們將這種從零開始學(xué)習(xí)的方法稱作“純強化學(xué)習(xí)(Pure RL)”。
純強化學(xué)習(xí)在西洋雙陸棋和圍棋這類游戲中被廣泛應(yīng)用,同時也應(yīng)用于機器人技術(shù)等領(lǐng)域。
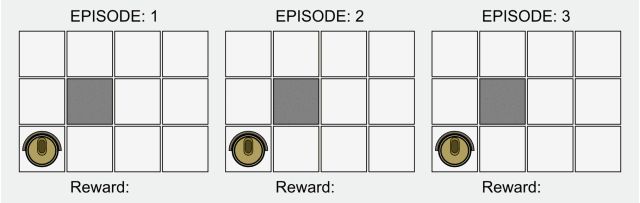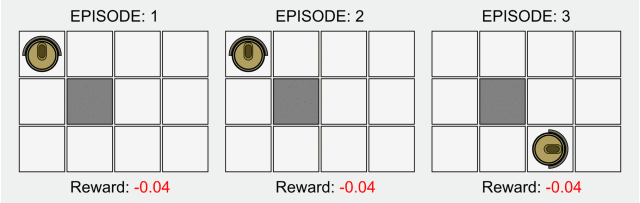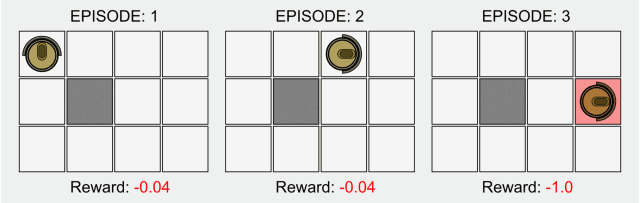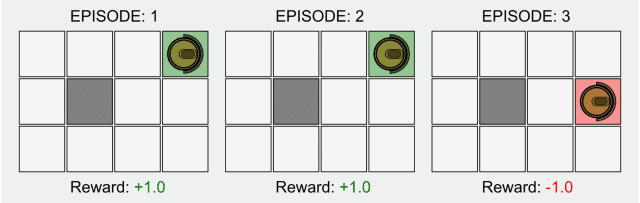
在傳統(tǒng)的強化學(xué)習(xí)中,只有在最終狀態(tài)才有非零獎勵。這一領(lǐng)域的研究最近因為深度學(xué)習(xí)而再次受到關(guān)注,但是其基本的模型卻并沒有什么改進(jìn)。
畢竟這種從零開始的學(xué)習(xí)方法可以追溯到強化學(xué)習(xí)研究領(lǐng)域的最初創(chuàng)建時期,也在最初的基本公式中就被編碼了。
所以根本的問題是:如果純強化學(xué)習(xí)沒有什么意義,那么基于純強化學(xué)習(xí)來設(shè)計AI模型還合理嗎?
如果人類通過純強化學(xué)習(xí)來學(xué)習(xí)新的棋類游戲聽起來如此荒謬,那我們是不是應(yīng)該考慮,這是不是一個本身就有缺陷的框架,那么AI角色又如何通過這一框架進(jìn)行有效的學(xué)習(xí)呢?不依靠任何先前經(jīng)驗或指導(dǎo),僅僅靠獎勵信號來學(xué)習(xí),是否真的有意義呢?
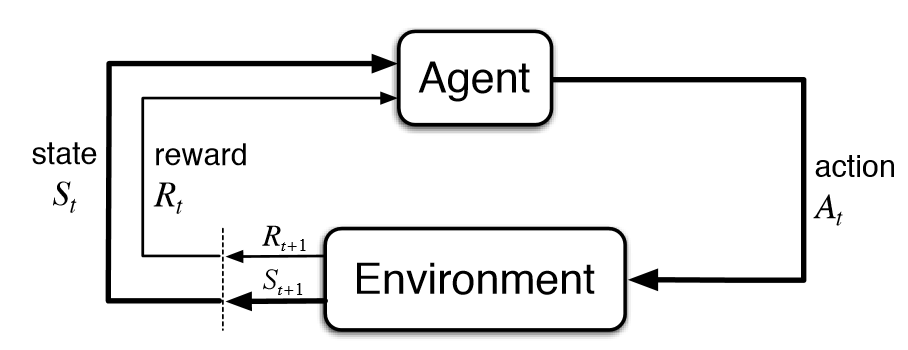
強化學(xué)習(xí)的基本公式
純強化學(xué)習(xí)是否真的有意義?
關(guān)于這個問題,強化學(xué)習(xí)專家們眾說紛紜:
有!純強化學(xué)習(xí)當(dāng)然有意義,AI智能體不是真正的人類,不用像我們一樣學(xué)習(xí)。何況純強化學(xué)習(xí)已經(jīng)可以解決很多復(fù)雜問題了。
沒有!從定義上看,AI研究包括讓機器也能做目前只有人類能做的事情,所以跟人類智能來比較很合理。至于那些純強化學(xué)習(xí)現(xiàn)在能解決的問題,人們總是忽視一點:那些問題其實沒有它們看起來那么復(fù)雜。
既然業(yè)內(nèi)無法達(dá)成共識,那就讓我們來用事實說話。
基于純強化學(xué)習(xí),以DeepMind為代表的業(yè)內(nèi)玩家已經(jīng)達(dá)成了很多“炫酷”的成就:
1)DQN (Deep Q-Learning)—— DeepMind的著名研究項目,結(jié)合了深度學(xué)習(xí)與純強化學(xué)習(xí),并加入了一些別的創(chuàng)新,解決了很多以前解決不了的復(fù)雜問題。這個五年前的項目大大提高了人們對強化學(xué)習(xí)的研究興趣。
毫不夸張的說,DQN是憑借一己之力重燃了研究者對于強化學(xué)習(xí)的熱情。雖然DQN只有幾項簡單的創(chuàng)新,但是這幾項創(chuàng)新對于深度強化學(xué)習(xí)的實用性至關(guān)重要。
雖然這個游戲現(xiàn)在看起來非常簡單,僅僅是通過像素輸入來學(xué)習(xí),但在十年前,玩這個游戲是難以想象的。
2)AlphaGo Zero和AlphaZero——純粹用于戰(zhàn)勝人類的圍棋、國際象棋及日本將棋的強化學(xué)習(xí)模型
首先來進(jìn)行一個科普:AlphaGo Zero是谷歌DeepMinwd項目開發(fā)的最新的升級版AlphaGo。不同于原始的結(jié)合了監(jiān)督學(xué)習(xí)和強化學(xué)習(xí)方式的AlphaGo,AlphaGo Zero單純依靠強化學(xué)習(xí)和自我對弈來進(jìn)行算法學(xué)習(xí)。
因此,盡管該模型也利用了一個預(yù)先提供的算法規(guī)則,即棋類的游戲規(guī)則和自我對弈來進(jìn)行更可靠而持續(xù)的迭代更新,AlphaGo Zero更遵循純強化學(xué)習(xí)的整體方法論:算法從零開始,通過學(xué)習(xí)結(jié)果的獎勵信號反饋進(jìn)行迭代。
由于它不是從人類身上直接學(xué)習(xí)游戲規(guī)則的,AlphaGo Zero也因此被許多人認(rèn)為是一個比AlphaGo更具顛覆性的算法。然后就誕生了AlphaZero:作為一個更通用的算法,它不僅可以學(xué)習(xí)如何下圍棋,還可以學(xué)習(xí)下國際象棋和日本將棋。
這是史上第一次出現(xiàn)用單一算法來破解象棋和圍棋的算法。并且,它并沒有像過去的深藍(lán)計算機或者AlphaGo那樣對任何一種游戲規(guī)則做特殊定制。
毫無疑問,AlphaGo Zero和AlphaZero是強化學(xué)習(xí)發(fā)展史上里程碑式的案例。
歷史性的時刻——李世乭輸給了AlphaGo
3)OpenAI的Dota機器人–由深度強化學(xué)習(xí)算法驅(qū)動的AI智能體,可以在流行的復(fù)雜多人對戰(zhàn)游戲Dota2上擊敗人類。OpenAI在2017年在變化有限的1v1游戲中戰(zhàn)勝了職業(yè)玩家的戰(zhàn)績已經(jīng)足夠讓人驚嘆。最近,它更是在一局復(fù)雜得多的5v5比賽中戰(zhàn)勝了一整隊人類玩家。
這一算法也與AlphaGo Zero一脈相承,因為它不需要任何人類知識,純粹通過自我對弈對算法進(jìn)行訓(xùn)練。在下面的視頻里,OpenAI自己出色地解釋了它的成就。
毫無疑問,在這種以團隊合作為基礎(chǔ)的高度復(fù)雜的游戲中,算法取得的好成績,遠(yuǎn)遠(yuǎn)優(yōu)于先前在Atari電子游戲和圍棋上取勝的戰(zhàn)績。
更重要的是,這種進(jìn)化是在沒有任何重大算法進(jìn)步的情況下完成的。
這一成就歸功于驚人的計算量、已經(jīng)成熟的強化學(xué)習(xí)算法、以及深度學(xué)習(xí)。在人工智能業(yè)內(nèi),大家普遍的共識是Dota機器人的勝利是令人驚嘆的成就,也是強化學(xué)習(xí)一系列重要里程碑的下一個:
沒錯,純強化學(xué)習(xí)算法已經(jīng)取得了很多成就。
但仔細(xì)一想,我們就會發(fā)現(xiàn),這些成就其實也“不過爾爾”。
純強化學(xué)習(xí)的局限性
讓我們從DQN開始回顧,在剛剛提到的這些案例中,純強化學(xué)習(xí)到底存在哪些局限性。
它可以在很多Atari游戲中達(dá)到超人的水平,但一般來說,它只能在基于反射的游戲中做得很好。而在這種游戲中,你其實并不需要推理和記憶。
即使是5年后的今天,也沒有任何一種純強化學(xué)習(xí)算法能破解推理和記憶游戲;相反,在這方面做得很好的方法要么使用指令,要么使用演示,而這些在棋盤游戲中也行得通。
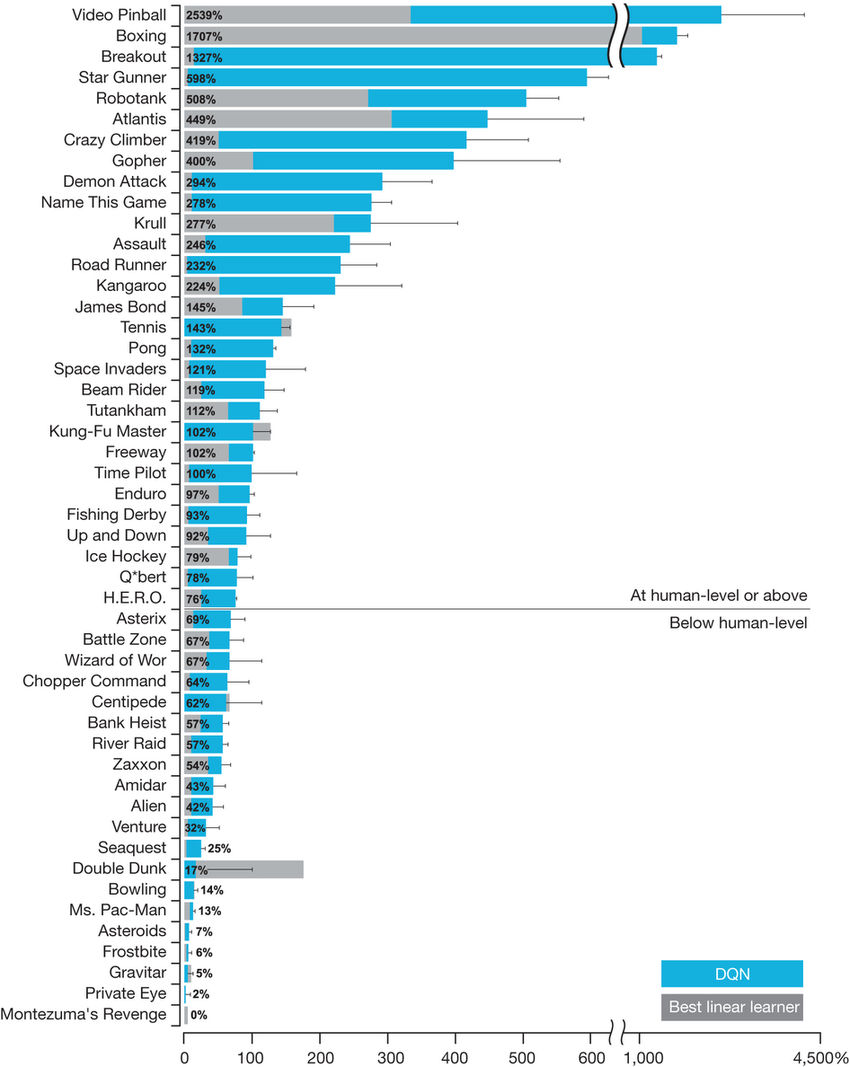
盡管DQN在諸如Breakout之類的游戲中表現(xiàn)出色,但它仍然無法完成像蒙特祖瑪?shù)膹?fù)仇這樣相對簡單的游戲。
而即使是在DQN表現(xiàn)得很好的游戲里,和人類相比,它還是需要大量的時間和經(jīng)驗來學(xué)習(xí)。
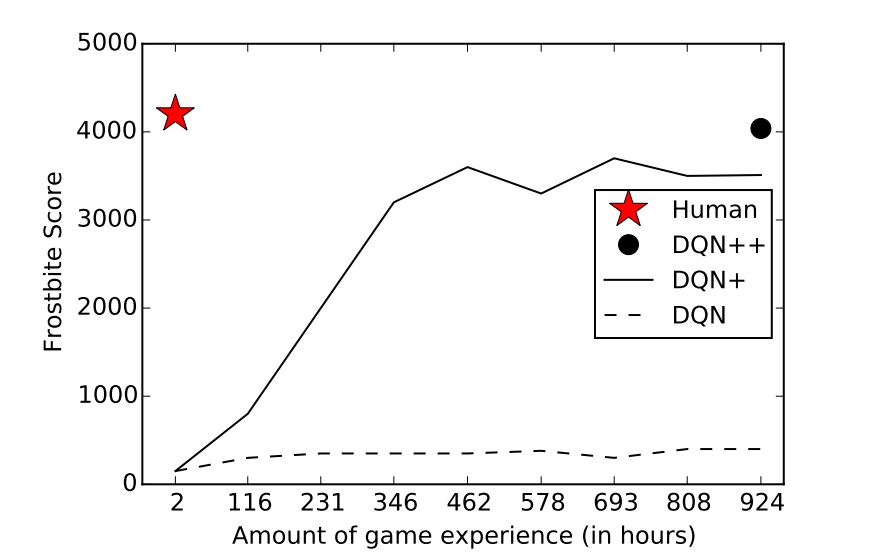
同樣的局限性在AlphaGo Zero和AlphaZero中也存在。
也就是說,它的每一種性質(zhì)都使學(xué)習(xí)任務(wù)變得容易:它是確定性的、離散的、靜態(tài)的、完全可觀察的、完全已知的、單智能體的、適用于情景的、廉價的、容易模擬的、容易得分的……
但在此前提下,對于圍棋游戲來說,唯一的挑戰(zhàn)是:它具有龐大的分支因子。
所以,盡管圍棋可能是easy模式下最難的一道題,但它仍然是easy模式。而大多數(shù)研究人員都認(rèn)識到,現(xiàn)實世界的多數(shù)問題比圍棋這類簡單的游戲復(fù)雜得多。
盡管有很多卓越的成就,但AlphaGo的所有變體在本質(zhì)上仍與“深藍(lán)”(Deep Blue)相似:它是一個經(jīng)過多年設(shè)計的、投入高達(dá)數(shù)百萬美元的昂貴系統(tǒng),卻純粹只是為了玩一款抽象的棋盤游戲——除此之外別無其他用途。
現(xiàn)在到Dota了。
是的,這是一個比圍棋復(fù)雜得多的游戲,缺乏很多使游戲變得簡單的特性:它不是離散的、靜態(tài)的、完全可觀察的、單智能體的或適用于情景的——這是一個極具挑戰(zhàn)性的問題。
但是,它仍然是一款很容易模擬的游戲,通過一個漂亮的API來控制——它完全消除了需要感知或運動控制。因此,與我們每天在真實世界中解決問題時所面臨的真正的復(fù)雜性相比,它依然是簡單的。
它仍然像AlphaGo一樣,需要大規(guī)模投資。許多工程師為了得到一個算法,使用長到離譜的時間來解決這個問題。這甚至需要數(shù)千年的游戲訓(xùn)練并使用多達(dá)256個的GPU和128000個CPU核。
因此,僅僅因為強化學(xué)習(xí)的這些成果就認(rèn)為純強化學(xué)習(xí)很強大,是不正確的。
我們必須要考慮的是,在強化學(xué)習(xí)領(lǐng)域,純強化學(xué)習(xí)可能只是最先使用的方法,但也許,它不一定是最好的?
純強化學(xué)習(xí)的根本缺陷——從零開始
是否有更好的方法讓AI智能體學(xué)習(xí)圍棋或Dota呢?
“AlphaGo Zero”這個名字的含義就是指模型從零開始學(xué)習(xí)圍棋。讓我們回憶一下開頭講的那個例子。既然試著從頭學(xué)起棋盤游戲而不作任何解釋是荒謬的,那么AI為什么還一定要從零開始學(xué)習(xí)呢?
讓我們想象一下,對于人類來說,你會如何開始學(xué)習(xí)圍棋呢?
首先,你會閱讀規(guī)則,學(xué)習(xí)一些高層次的策略,回想過去你是如何玩類似游戲的,然后從高手那里獲取一些建議。
因此,AlphaGo和OpenAI Dota機器人從零開始學(xué)習(xí)的限制,導(dǎo)致他們和人類學(xué)習(xí)相比,依靠的是許多數(shù)量級的游戲指令和使用更原始的、無人能及的計算能力。
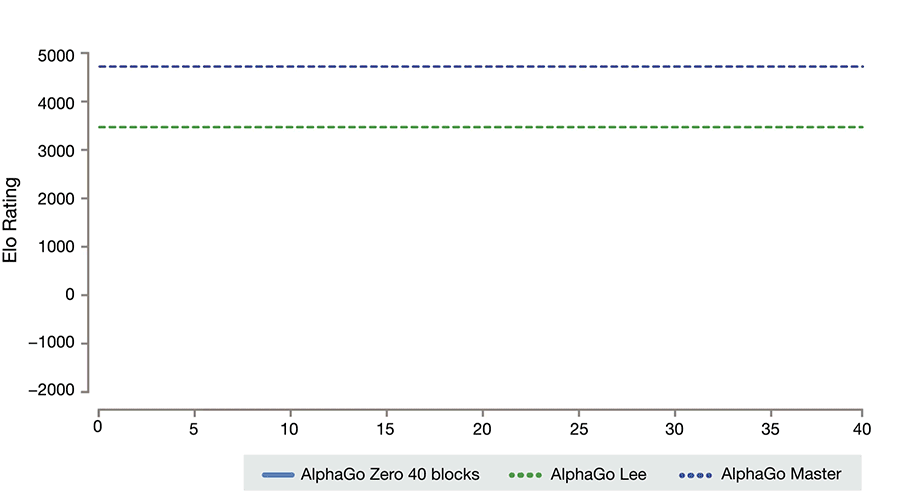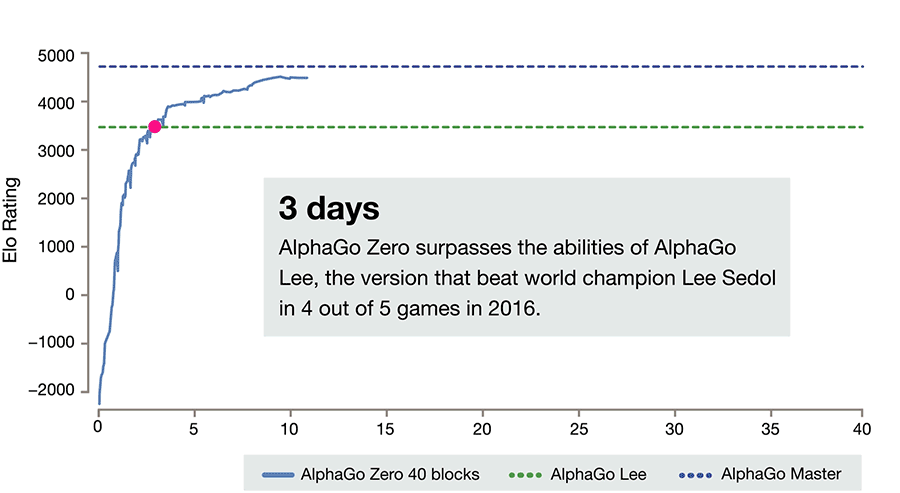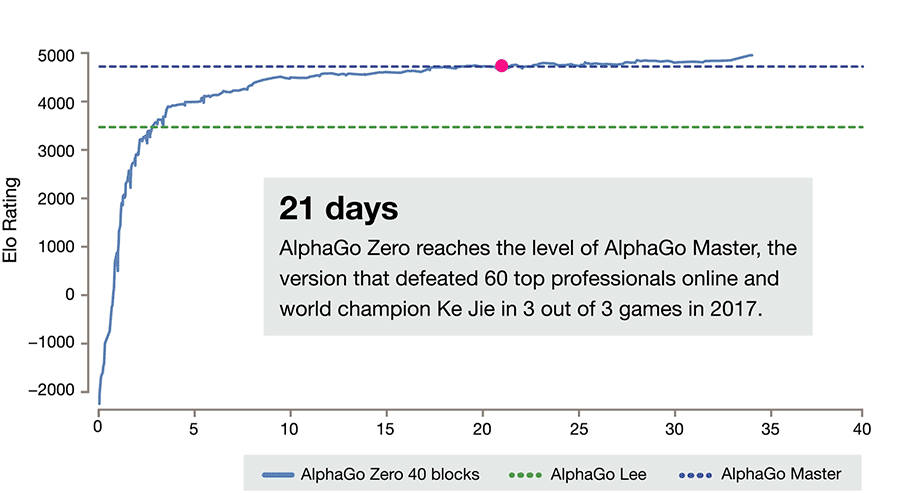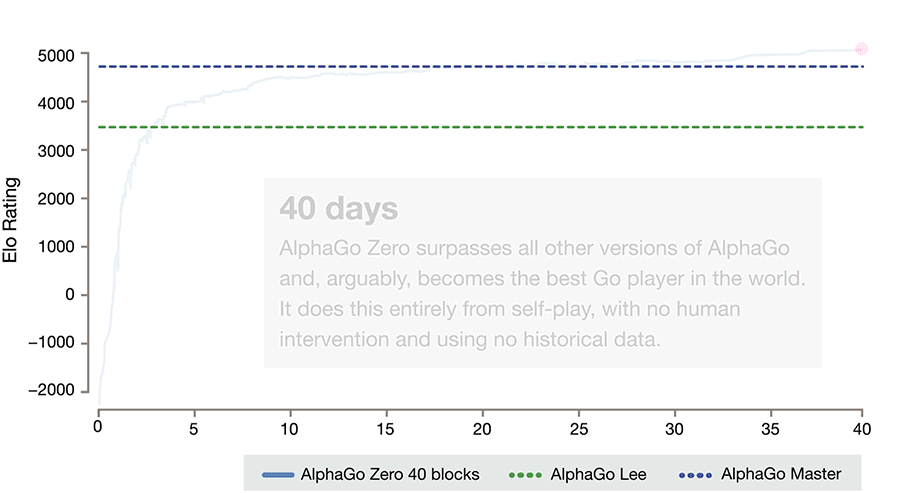
AlphaGo Zero的進(jìn)展。請注意,要達(dá)到ELO分?jǐn)?shù)為0,它需要一整天的時間和成千上萬次的游戲(而即使是最弱的人也能輕松做到)。
公平地說,純強化學(xué)習(xí)可以合理地用于諸如持續(xù)控制之類的“狹義”任務(wù),或者最近的復(fù)雜游戲,如Dota或星際爭霸。
然而,隨著深度學(xué)習(xí)的成功,AI研究社區(qū)現(xiàn)在正試圖解決越來越復(fù)雜的任務(wù),這些任務(wù)必須面對現(xiàn)實世界中到復(fù)雜性。正是這些復(fù)雜性,我們可能需要一些超越純強化學(xué)習(xí)的東西。
那么,讓我們繼續(xù)討論我們的修正問題:純強化學(xué)習(xí),以及總體上從零開始學(xué)習(xí)的想法,是完成復(fù)雜任務(wù)的正確方法嗎?
我們還應(yīng)該堅持純強化學(xué)習(xí)嗎?
乍一看,這個問題的答案也許是:應(yīng)該。為什么這么說呢?
從零開始的學(xué)習(xí)意味著它沒有任何先入為主的主觀因素,這樣的話,經(jīng)過學(xué)習(xí)的人工智能會比我們更加優(yōu)秀,就像AlphaGo Zero一樣。畢竟,如果人類的直接存在錯誤,那不就限制了機器的學(xué)習(xí)能力了么?
隨著深度學(xué)習(xí)方法的成功,這個觀點已經(jīng)成為主流,雖然訓(xùn)練模型的數(shù)據(jù)量驚人,但是我們依舊只給予少量的先驗知識。
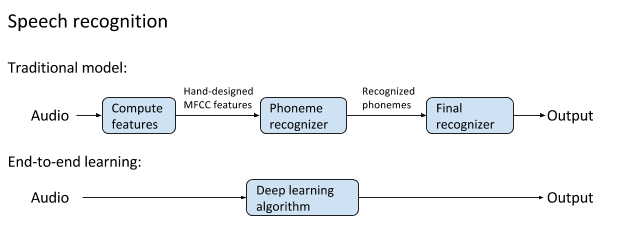
以前的非傳統(tǒng)語音識別和端對端深度學(xué)習(xí)方法的圖例,后者有更好的表現(xiàn),并成為了現(xiàn)代語音識別的基礎(chǔ)。
不過,讓我們重新審視這個問題:結(jié)合人類的先驗知識就一定會限制機器的學(xué)習(xí)能力么?
答案是否定的。也就是說,我們可以在深度學(xué)習(xí)的框架下(也就是只由數(shù)據(jù)出發(fā)),對手頭的任務(wù)下達(dá)一定的指示,而不至于限制機器的學(xué)習(xí)能力。
目前,這個方向已經(jīng)出現(xiàn)了諸多研究,相信這樣的技術(shù)也能很快被應(yīng)用到實際例子中。
比如像AlphaGo Zero這樣的算法,我們大可不必從零開始學(xué)習(xí),而是在不限制其學(xué)習(xí)能力的前提下加入人類知識的指導(dǎo)。
即使你覺得這個方向不靠譜,堅持要從零學(xué)習(xí),那純強化學(xué)習(xí)就是我們最佳的選擇嗎?
以前的話,答案是毋庸置疑的;在無梯度優(yōu)化的領(lǐng)域中,純強化學(xué)習(xí)是理論最完備而方法最可靠的。
不過近期很多文章都質(zhì)疑這個論斷,因為他們發(fā)現(xiàn)了相對簡單的方法(而且總體而言沒那么受到重視的)、基于進(jìn)化策略的方法在一些典型的任務(wù)中似乎和純強化學(xué)習(xí)表現(xiàn)得一樣好:
《Simple random search provides a competitive approach to reinforcement learning》
《Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning》
大數(shù)據(jù)文摘微信公眾號后臺回復(fù)“缺陷”下載這兩篇論文。
Ben Recht是最優(yōu)化算法的理論與實踐研究的帶頭人,他總結(jié)說:
我們發(fā)現(xiàn)隨機搜索在簡單線性問題中比強化學(xué)習(xí)更加優(yōu)秀,比如策略梯度。不過,當(dāng)我們遇到更加困難的問題時,隨機搜索就會崩潰嗎?并沒有。
因此,并不能說強化學(xué)習(xí)是從零學(xué)習(xí)的最佳方法。
回到人類從零學(xué)習(xí)的問題上來,人類學(xué)習(xí)一個新的復(fù)雜技巧時就沒有任何先驗知識嗎(比如組裝一個家具或駕駛汽車)?其實并不是這樣子的,對不對?
也許對于一些非常基礎(chǔ)的問題來說(比如嬰兒要學(xué)習(xí)的),我們可以從零開始,使用純強化學(xué)習(xí),但是對于AI領(lǐng)域中的很多重要問題,從零開始并沒有特別的優(yōu)勢:我們必須清楚,我們想要AI學(xué)會什么,而且必須要提供這方面的演示和指導(dǎo)。
實際上,目前人們廣泛認(rèn)為,從零開始學(xué)習(xí)是強化學(xué)習(xí)模型受到限制的主要原因:
目前的AI是“數(shù)據(jù)依賴”的——大多數(shù)情況下,AI需要海量的數(shù)據(jù)才能發(fā)揮它的作用。這對于純強化學(xué)習(xí)技術(shù)來說非常不利。回想一下,AlphaGo Zero需要上百萬的對局來達(dá)到ELO分?jǐn)?shù)為0的水平,而人類用很少的時間就能達(dá)到這個水平。顯然,從零開始學(xué)習(xí)是效率最低的一種學(xué)習(xí)方法;
目前的AI是不透明的——在多數(shù)情況下,對于AI算法的學(xué)習(xí),我們只有高層次的直覺。對于很多AI問題,我們希望算法是可預(yù)測和可解釋的。但是一個什么都從零開始學(xué)習(xí)的巨型神經(jīng)網(wǎng)絡(luò),其解釋性和預(yù)測性都是最差的,它只能給出一些低層次的獎勵信號或是一個環(huán)境模型。
目前AI是狹隘的——在很多情況下,AI模型只能夠在特定領(lǐng)域表現(xiàn)的非常好,而且非常不穩(wěn)定。從零開始學(xué)習(xí)的模式限制了人工智能學(xué)習(xí)能力。
目前的AI是脆弱的——AI模型只能把海量數(shù)據(jù)作為無形的輸入進(jìn)行泛化,但是結(jié)果非常不穩(wěn)定。因此,我們只能知道我們要AI智能體學(xué)習(xí)的是什么。
如果是一個人,那么在開始學(xué)習(xí)前,應(yīng)該能夠?qū)θ蝿?wù)進(jìn)行解釋并提供一些建議。這對于AI來說,同樣適用。
-
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247483 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8953瀏覽量
139705 -
強化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11536
原文標(biāo)題:非得從零開始學(xué)習(xí)?扒一扒強化學(xué)習(xí)的致命缺陷
文章出處:【微信號:CAAI-1981,微信公眾號:中國人工智能學(xué)會】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
什么是深度強化學(xué)習(xí)?深度強化學(xué)習(xí)算法應(yīng)用分析

深度強化學(xué)習(xí)實戰(zhàn)
將深度學(xué)習(xí)和強化學(xué)習(xí)相結(jié)合的深度強化學(xué)習(xí)DRL
薩頓科普了強化學(xué)習(xí)、深度強化學(xué)習(xí),并談到了這項技術(shù)的潛力和發(fā)展方向
如何深度強化學(xué)習(xí) 人工智能和深度學(xué)習(xí)的進(jìn)階
人工智能機器學(xué)習(xí)之強化學(xué)習(xí)
基于強化學(xué)習(xí)的MADDPG算法原理及實現(xiàn)
深度強化學(xué)習(xí)你知道是什么嗎
DeepMind發(fā)布強化學(xué)習(xí)庫RLax
機器學(xué)習(xí)中的無模型強化學(xué)習(xí)算法及研究綜述

《自動化學(xué)報》—多Agent深度強化學(xué)習(xí)綜述

徹底改變算法交易:強化學(xué)習(xí)的力量
什么是強化學(xué)習(xí)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論