 《硅谷》里使用深度學習識別熱狗的軟件Not Hotdog正式獲得艾美獎提名!
《硅谷》里使用深度學習識別熱狗的軟件Not Hotdog正式獲得艾美獎提名!
《硅谷》中演示了一款識別熱狗的軟件Not Hotdog,可以在安卓和IOS下載
繼AI制作動畫人物、創作劇本、編輯電影之后,今天,一款AI軟件正式獲得黃金時段艾美獎提名:熱播電視劇《硅谷》中一個使用深度學習自動識別熱狗的軟件再度走入公眾視野,使用TensorFlow和英偉達GPU開發。
不知道你有沒有看過熱播美劇《硅谷》。作為近年來最佳職場喜劇之一,《硅谷》為我們展現了程序員不為人知的一面。《硅谷》在嬉笑怒罵間描繪了一部IT業創業辛酸史,不僅如此,人工智能、機器學習、加密貨幣……劇集的主題一直緊跟現實硅谷圈的潮流。
其中,在第四季第四集就出現了一個使用深度學習算法識別熱狗的APP Not Hotdog,而且現在這款APP也能在安卓和iOS下載。
AI軟件正式獲得黃金時段艾美獎提名!
今天,制作這款的APP的Tim Anglade(是的,這款APP是他一個人制作的,當然得到了很多人的幫助)在Twitter上宣布,這款AI軟件正式獲得了黃金時段艾美獎提名!
實際上,在劇集播出后,這款APP就在硅谷掀起了一股話題熱潮,因為當時正是圖像識別的熱度達到巔峰時期。
《硅谷》劇組決定在劇集里做一個能夠在手機上運行的熱狗識別軟件。實現這一目標,Tim Anglade他們設計了一個直接在手機上運行的定制神經架構,并使用Tensorflow,Keras和Nvidia GPU進行訓練。
雖然只是用來識別熱狗(或者不是熱狗),但這款APP無疑是深度學習和邊緣計算的一個親切使用案例。所有的AI工作都由用戶的設備100%供電,處理圖像時無需離開手機。這為用戶提供了更快捷的體驗(無需往返云端),離線可用性和更好的隱私。
要知道,那時候還沒有TensorFlow Lite,100%在手機端實現物體識別還算是相對超前的概念。
這也使得整個APP能以0美元的成本運行,即使在100萬用戶的負載下,與傳統的基于云的AI方法相比,可以節省大量成本。
這款APP是由一個開發人員自己在內部開發的,用一臺筆記本電腦和附加GPU運行,使用手工收集的數據。
作者的開發環境,就是這樣簡單!
作為一款從劇集中誕生的衍生品,著實火熱了一把,還在蘋果開發者大會得到了宣傳。
作者Tim Anglade在Medium上超詳細地介紹了這款APP的設計、開發,從原型到產品的過程,可以閱讀原文了解詳情。

下面,我們將摘選介紹這款APP的技術細節,使用了什么架構、如何訓練,有什么要點。
對非技術公司,個人開發人員和業余愛好者等時間和資源有限的人,構建自己的深度學習APP,是再好不過的上手材料。
Deepdogs架構:受谷歌MobileNet論文推動
他們的最終架構在很大程度上受谷歌在2017年4月17日發布的論文MobileNet的推動,這種新的神經網絡架構具有類似Inception的準確性,但只有4M左右的參數。

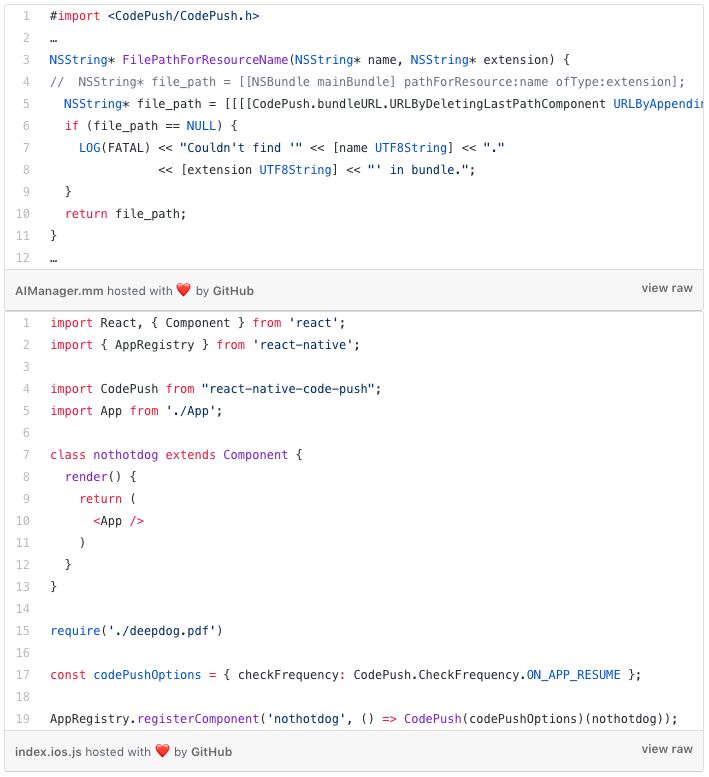
部分代碼截圖
之前團隊考慮過SqueezeNet,但SqueezeNet對于他們想要實現的目標來說又太簡單了,Inception或VGG則不能在手機上運行。MobileNet更適宜在移動端運行,這在當時是他們的首要考慮因素。
距離APP發布還有不到一個月的時間,團隊正在努力重現該論文的結果。但是,在MobileNet論文發表后的一天之內,伊斯坦布爾技術大學的學生Refik Can Malli已經在GitHub上公開提供了Keras實現代碼。深度學習社區的開放性和活躍性令人贊嘆。
團隊的最終架構叫做Deepdogs,與MobileNets架構有很大不同,特別是:
沒有在深度和逐點卷積(depthwise and pointwise)使用批量標準化(BN)和激活,因為XCeption論文似乎表明這樣做會導致這種類型的體系結構的準確性降低。同時,這樣還具有減小網絡規模的好處。
使用了ELU而不是ReLU。與SqueezeNet實驗一樣,激活函數使用ELU比ReLU提供了卓越的收斂速度和最終精度。
沒有使用PELU。雖然這種方法不錯,但只要我們嘗試使用它,這個激活函數似乎就會陷入二元狀態,網絡準確性不會逐步提高,而是從一批到下一批在~0%到100%之間交替。目前還不清楚為什么會發生這種情況。
沒有使用SELU。我們簡單做了個調查,iOS和Android版本之間使用SELU導致結果與PELU非常相似。我們懷疑SELU不應該作為激活函數被單獨使用,而是正如其論文的標題所暗示的那樣,作為狹義(narrowly-defined)SNN架構的一部分。
使用ELU維持BN。有許多跡象表明BN應該是不必要的,但是,在沒有BN的情況下運行的每個實驗都完全無法收斂。這可能是由于架構很小造成的。
在激活之前使用了BN。雖然現在關于這一點有所爭議,但他們的小型網絡在激活后做BN的實驗也未能收斂。
為了優化網絡,使用了Cyclical Learning Rates和Brad Kenstler的Keras實現。

在訓練時,團隊做了細致的數據增強和處理工作,解決了一些由閃光燈(如下)等造成的圖像扭曲等問題。
數據集的最終構成是150k圖像,其中只有3k是熱狗——熱狗再多花樣就那么幾種,但是長的像熱狗而不是熱狗的東西則太多了。這個比例 49:1的不平衡通過設置Keras的權重為49:1來解決。在剩余的147k圖像中,大多數都是食物,只有3k張非食物照片,這是為了幫助網絡更多地概括,如果圖像中出現紅色服裝中的人物,就不會被欺騙去將其識別為熱狗。
閃光燈和moiré 造成的扭曲變形
最終的訓練學習率和精度是這樣的:
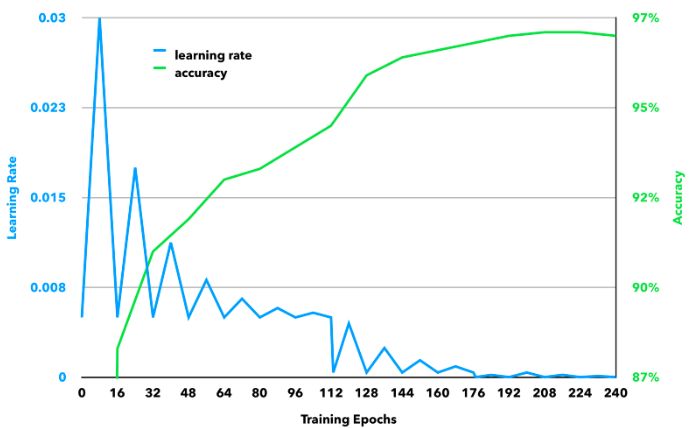
APP遇到番茄醬的情況還是會失效(但你要這樣在手臂上擠番茄醬也真沒辦法)
最神秘的部分:100%在手機端運行并識別熱狗
設計出了一個相對緊湊的神經體系結構,并且訓練它來處理在移動環境中可能發現的情況,但是,仍然還需要做很多工作才能使其正常在手機上運行。
關于如何讓Deepdog在手機上運行,可能是這個項目中最神秘的部分。因為在當時能找到在移動設備上運行商用深度學習APP的資料還相當匱乏。于是,他們咨詢了Tensorflow團隊,得到了特別是Pete Warden,Andrew Harp和Chad Whipkey的文檔以及慷慨幫助。
舍入網絡的權重有助于將網絡壓縮到其大小的約25%。本質上,不是使用從訓練中派生的任意stock value,而是優化選擇N個最常見的值,并將網絡中的所有參數設置為這些值,從而大大減少壓縮后網絡的大小。但是,這對未壓縮的APP大小或內存使用量沒有影響。不過,團隊沒有使用這項優化,因為他們的網絡足夠小。
商用開發編譯時,使用-Os來優化TensorFlow庫
從TensorFlow庫中刪除不必要的操作:TensorFlow在某些方面就像是一個虛擬機,從中移除不必要的操作,可以節省大量的權重(和內存)。
團隊不是在iOS上使用TensorFlow,而是使用蘋果的內置深度學習庫(BNNS,MPSCNN和更高版本的CoreML)。他們在Keras中設計網絡,使用TensorFlow進行訓練,導出所有權重值,使用BNNS或MPSCNN重新實現網絡(或通過CoreML導入),并將參數加載到新的實現當中。
通過動態注入神經網絡來改變APP行為
如果你覺得動態地將JavaScript注入到應用程序中很酷,那就試試在應用程序中注入神經網絡吧!
他們使用的最后一個產品技巧是利用CodePush和蘋果相對寬松的服務條款,在提交給應用商店后實時注入我們的神經網絡的新版本。雖然這主要是為了幫助在發布后快速地向用戶提供準確的改進,但是你可以使用這種方法來大幅擴展或改變應用程序的特性集,而不必再通過應用程序商店的審查。
教訓總結和改進
有很多事情沒有成功,或者我們沒有時間去做,這些就是我們將來要研究的想法:
更仔細地調整我們的數據增強參數。
端到端測量準確性,即應用程序最終確定抽象事項,例如我們的程序是否有2個或更多的類別,Hotdog識別的最終閾值是什么(我們最終讓應用程序說“Hotdog”,如果識別在權重四舍五入后,等于0.90而不是默認值0.5)
在應用中建立一個反饋機制——如果結果是錯誤的,讓用戶發泄不滿,或者積極改進神經網絡。
用一個更大的分辨率而不是224 x 224像素識別圖像——本質上使用MobileNetsρ值> 1.0
UX/DX,偏見,以及人工智能的神秘谷
最后,不得不指出用戶體驗、開發人員體驗和內置偏見對開發人工智能應用明顯和重要的影響。這三件事在我們的經驗中有非常具體的影響:
用戶體驗(User Experience)在人工智能應用開發的每個階段都比傳統應用更重要。目前還沒有深度學習算法能夠給你帶來完美的結果,但在很多情況下,深度學習+用戶體驗的正確組合將導致無法區分完美的結果。當開發人員設置正確的路徑來設計他們的神經網絡,在用戶使用應用程序時設置正確的期望,以及優雅地處理不可避免的AI故障時,正確的UX期望是不可替代的。在沒有用戶體驗第一思維模式的情況下構建AI應用程序就像訓練沒有隨機梯度下降的神經網絡:在構建完美的AI用例的過程中,最終會陷入Uncanny Valley的局部最小值。
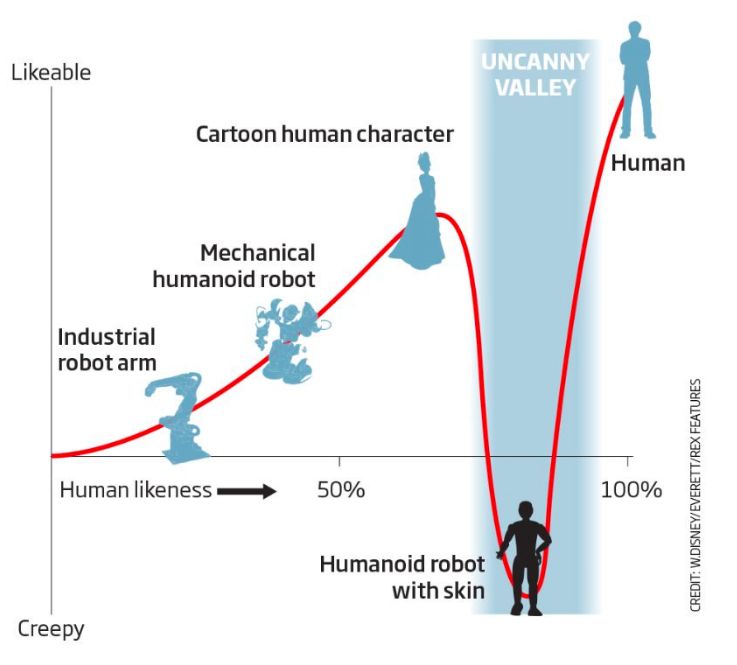
DX(開發人員體驗)也非常重要,因為深度學習訓練時間是等待程序編譯時的新內容。我們建議您首先使用DX(因此使用了Keras),因為總是可以為以后的運行優化運行時間(手工的GPU并行化、多進程數據增強、TensorFlow pipeline,甚至是咖啡因2 / pyTorch的重新實現)。
即使是使用相對遲鈍的API和文檔(如TensorFlow)的項目,也可以通過為訓練和運行神經網絡提供一個經過高度測試、高度使用、維護良好的環境來大大改進DX。
出于同樣的原因,很難同時擁有自己的本地GPU進行開發的成本和靈活性。能夠在本地查看/編輯圖像,用您喜歡的工具編輯代碼而不延遲,這極大地提高了人工智能項目的開發質量和速度。
大多數人工智能應用程序將比我們的應用程序受到更嚴重的文化偏見,舉個例子,我們在初始數據集中引發了內置偏見,這使得應用程序無法識別法國式Hotdog、亞洲Hotdog等等我們沒見過的東西。
重要的是要記住,人工智能并不比人類做出“更好”的決定——他們通過人類提供的訓練集感染了我們人類的偏見。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
硅谷
+關注
關注
1文章
121瀏覽量
16545 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:美劇《硅谷》深度學習APP獲艾美獎提名:使用TensorFlow和GPU開發
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
賽靈思Zynq-7000 All Programmable SoC獲年度最具潛力新技術獎提名
2017中國IoT技術創新獎提名:Renesas Synergy? 平臺
技術產品創新獎提名 | 2017中國IoT大會(持續更新中...)
Nanopi深度學習之路(1)深度學習框架分析
什么是深度學習?使用FPGA進行深度學習的好處?
《幻想裝置》,《阿波羅11號》及其他游戲獲得Viveport開發者大獎提名
一部講述Stuxnet病毒歷史的VR紀錄片獲得了艾美獎
艾美獎提名是蘋果旗艦系列第二次獲得重大提名
基于遷移深度學習的雷達信號分選識別
什么是深度學習(Deep Learning)?深度學習的工作原理詳解
鴻蒙智能終端操作系統基座與產業應用獲國家科技進步獎提名





 工商網監
工商網監
評論