 探索GAN的景觀,并討論常見的陷阱和可重復性等問題
探索GAN的景觀,并討論常見的陷阱和可重復性等問題
隨著GAN越來越多的應用到實際研究當中,其技術中的缺陷與漏洞也隨之出現。從實際角度對GAN的當前狀態進行深入挖掘與理解就顯得格外重要。來自Google Brain的Karol Kurach等人重現了當前的技術發展水平,探索GAN的景觀,并討論常見的陷阱和可重復性等問題。
從實際角度對GAN的當前狀態進行深入挖掘與理解對GAN的發展有著重要的意義。來自Google Brain的Karol Kurach等人重現了當前的技術發展水平,探索GAN的景觀,并討論常見的陷阱和可重復性等問題。Lan Goodfellow等AI界大咖也對此成果表示贊同,并紛紛轉載。
深度生成模型可以應用于學習目標分布的任務。 他們最近在各種應用程序中被利用,在自然圖像的背景下充分發揮其潛力。 生成對抗網絡(GAN)是以完全無監督的方式學習這些模型的主要方法之一。 GAN框架可以被視為一個雙人游戲,其中第一個“玩家”,生成器(generator),正在學習將一些簡單的輸入分布(通常是標準的多元正態或均勻)轉換為圖像空間上的分布,這樣第二個“玩家”,鑒別器(discriminator),無法判斷樣本是屬于真實分布還是合成。 兩位“玩家”的目標都是盡量減少自己的損失,而比賽的解決方案就是Nash均衡(equilibrium),任何“玩家”都不能單方面改善他們的損失。 還可以通過最小化模型分布和真實分布之間的統計差異來導出GAN框架。
訓練GAN需要解決發生器和鑒別器參數的最小極大(nimimax)問題。 由于發生器和鑒別器通常都被參數化為深度卷積神經網絡,所以這種極小極大(minimax)問題在實踐中是非常困難的。 為此,提出了許多損失函數,正則化和歸一化以及神經結構的方案來做選擇。 其中一些是基于理論見解得出的,而另一些則是實際考慮角度出發的。
在這項工作中,我們對這些方法進行了全面的實證分析。我們首先定義GAN landscape—損失函數集,歸一化和正則化方案以及最常用的體系結構。我們通過超參數優化(hyperparameter optimization),在幾個現代大規模數據集以及高斯過程回歸(Gaussian Process regression)獲得的數據集上探索這個搜索空間。 通過分析損失函數的影響,我們得出結論,非飽和損失(non-saturating loss)在數據集、體系結構和超參數之間足夠穩定。然后,我們繼續分析各種歸一化和正則化方案以及不同的體系結構的效果。我們表明,梯度抑制(gradient penaltyas)以及頻譜歸一化(spectral normalization)在高容量(high-capacity)結構的背景下都是有用的。然后,我們發現人們可以進一步受益于同時正規化和規范化。最后,我們討論了常見的陷阱,可重復性問題和實際考慮因素。
GAN Landscape
損失函數
令P表示目標分布,Q表示模型分布。原始的GAN公式有兩種損失函數:minimax GAN和非飽和(NS) GAN。前者,鑒別器最小化二分類問題的負對數似然(即樣本是真的還是假的),相當于最小化P和Q之間的Jensen-Shannon(JS)偏差。后者,生成器最大化生成樣本是真實的概率。對應的損失函數定義為:
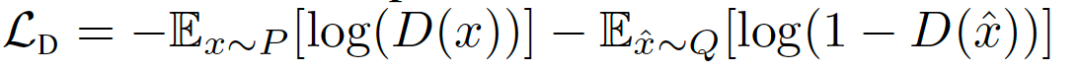
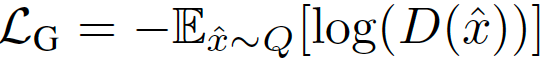
在綜合考慮前人的研究后,我們考慮用最小平方損失(LS),相當于最小化P和Q之間的Pearson卡方散度(divergence)。對應的損失函數定義為:
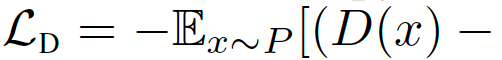
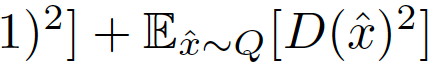
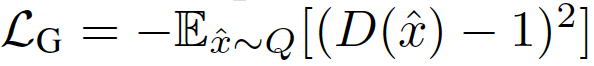
鑒別器的歸一化和正則化
Gradient norm penalty
在訓練點和生成的樣本之間的線性插值上評估梯度,作為最佳耦合的代理(proxy)。 還可以在數據流形周圍評估梯度損失,這促使鑒別器在該區域中成分段線性。梯度范數懲罰可以純粹被認為是鑒別器的正則化器,并且它表明它可以改善其他損失的性能。計算梯度范數(gradient norms)意味著一個非平凡的運行時間懲罰(penalty) - 基本上是運行時間的兩倍。
鑒別器歸一化
從優化角度(更有效的梯度流、更穩定的優化)以及從表示的角度來看,歸一化鑒別器是有用的 - 神經網絡中層的表示豐富度取決于相應權重的譜結構矩陣。
從優化角度來看,一些關于GAN的技術已經成熟,例如: Batch normalization和Layer normalization (LN);從表示的角度來看,必須將神經網絡視為(可能是非線性)映射的組合并分析它們的光譜特性(spectral properties)。特別地,為了使鑒別器成為有界線性算子,控制最大奇異值(maximum singular value)就可以了。
生成器和鑒別器機構
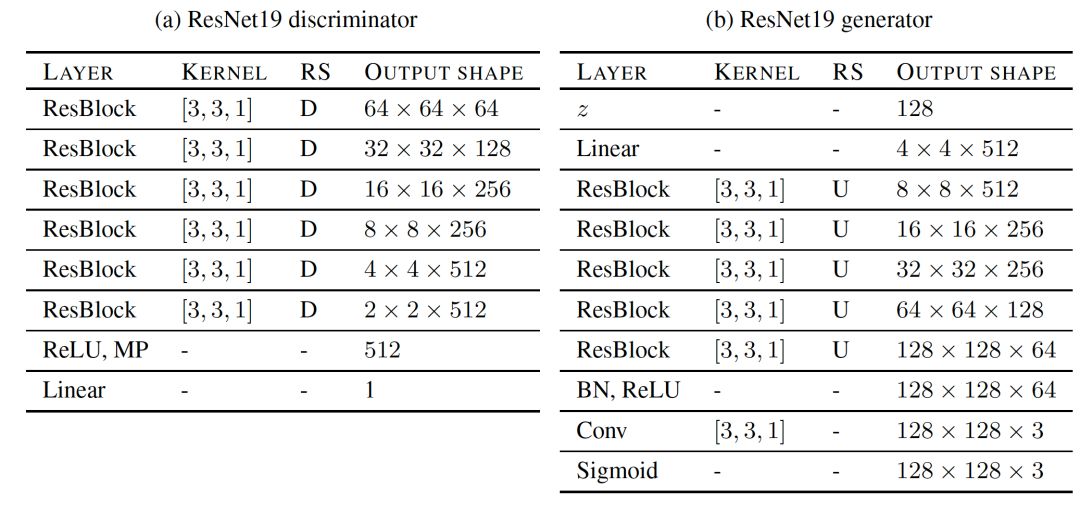
我們在這項研究中探索了兩類架構:深度卷積生成對抗網絡(DCGAN)和殘余網絡(ResNet)。ResNet19是一種架構,在生成器中有五個ResNet塊,在鑒別器中有六個ResNet塊,可以在128×128圖像上運行。我們在每個鑒別器塊中進行下采樣,并且第一個塊不包含任何自定義更改。 每個ResNet塊由三個卷積層組成,這使得鑒別器總共有19層。 表3a和表3b總結了鑒別器和發生器的詳細參數。 通過這種設置,我們能夠重現并改進當前已有的最好結果。
評估方法
我們專注于幾個最近提出的非常適合圖像域的指標。
Inception Score (IS)
IS提供了一種定量評估生成樣本質量的方法。 包含有意義對象的樣本的條件標簽分布應該具有低熵,并且樣本的可變性應該高。 IS可以表示為:
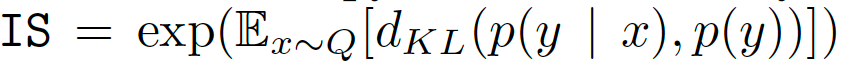
來自P和Q的樣本首先嵌入到特征空間(InceptionNet的特定層)中。 然后,假設嵌入數據遵循多元高斯分布,估計均值和協方差。 最后,計算這兩個高斯之間的Fréchet距離:
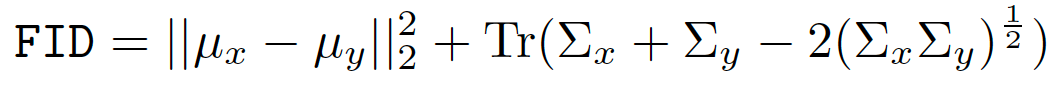
圖像質量(MS-SSIM)和多樣性的多尺度結構相似性
GAN中的一個關鍵問題是模式崩潰和模式丟失 - 無法捕獲模式,或者從給定模式生成樣本的多樣性較低。MS-SSIM得分用于測量兩個圖像的相似度,其中較高的MS-SSIM得分表示更相似的圖像。
數據集
我們考慮三個數據集,即CIFAR10,CELEBA-HQ-128和LSUN-BEDROOM。LSUN-BEDROOM數據集[包含300多萬張圖像。 我們將圖像隨機分成訓練集和測試集,使用30588張圖像作為測試集。 其次,我們使用30k張圖像的CELEBA-HQ數據集,將3000個示例作為測試集,其余示例作為訓練集。 最后,為了重現現有結果,我們還采用了CIFAR10數據集,其中包含70K張圖像(32x32x3),60000個訓練實例和10000個測試實例。 CELEBA-HQ-128的基線FID評分為12.6,LSUN-BEDROOM為3.8,CIFAR10為5.19。
實驗結果
損失函數的影響
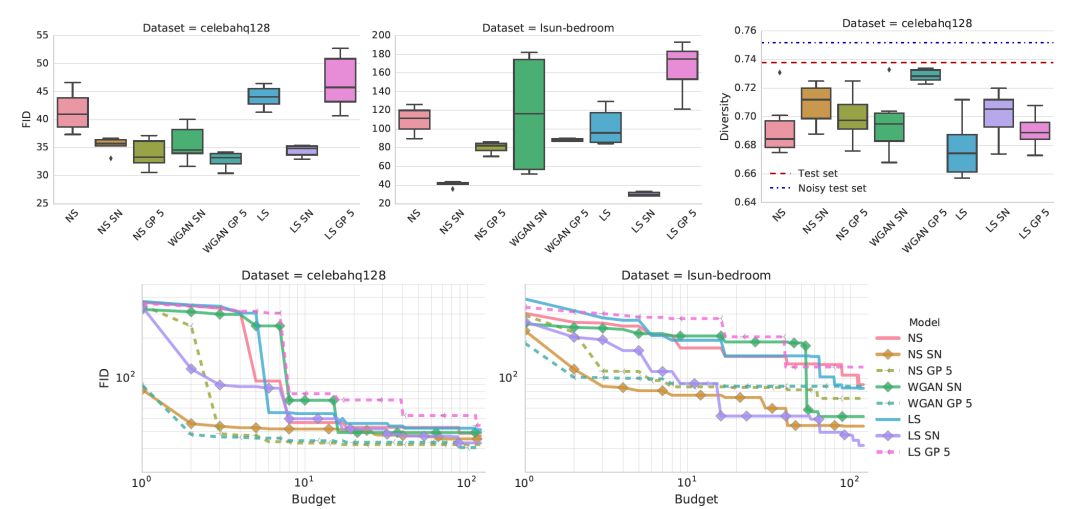
非飽和(NS)損失在兩個數據集上都是穩定的
Gradient penalty和光譜(spectral)歸一化提高了模型質量。 從計算預算的角度來看(即,需要訓練多少個模型以達到某個FID),光譜歸一化和Gradient penalty都比基線表現更好,但前者更有效。
Gradient penalty和譜歸一化(SN)都表現良好,應該被認為是可行的方法,而后者在計算成本上更好。 可惜的是,沒有人能完全解決穩定性問題。
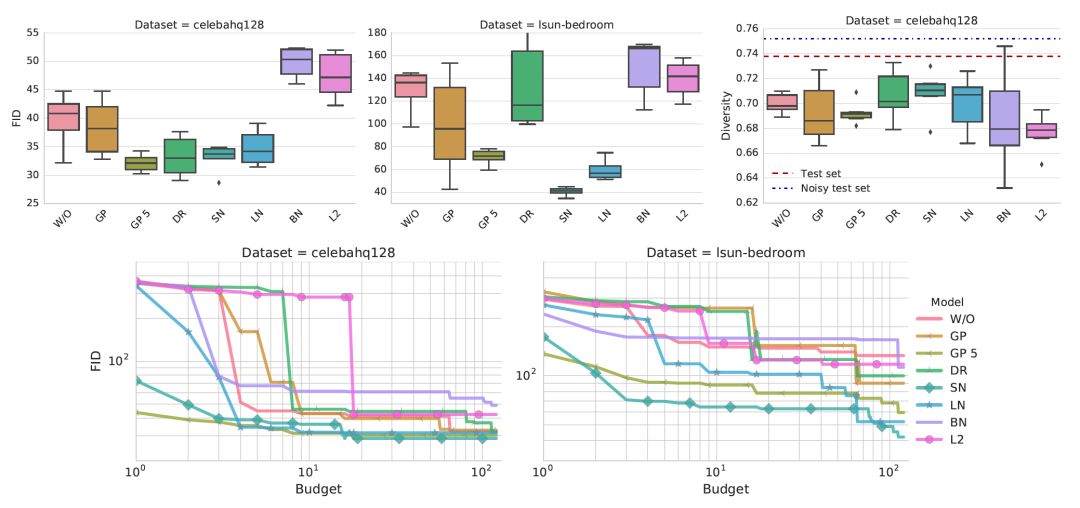
歸一化和正則化的影響
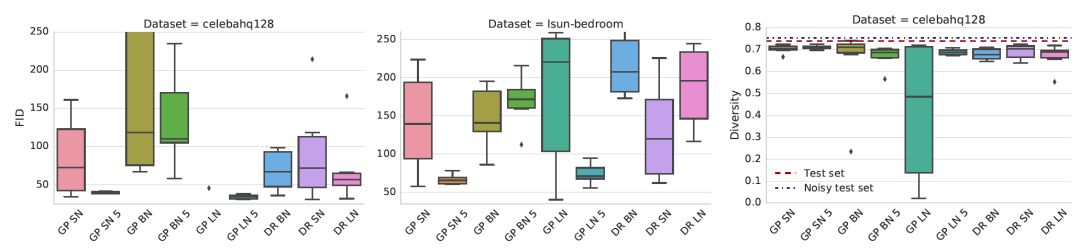
Gradient penalty加上光譜歸一化(SN)或層歸一化(LN)大大提高了基線的性能
生成器和鑒別器結構的影響
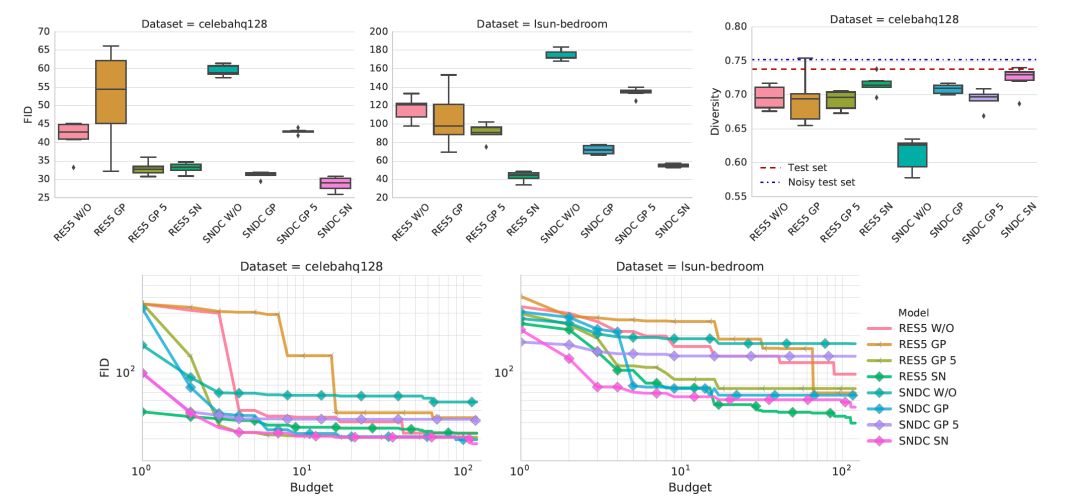
鑒別器和發生器結構對非飽和GAN損失的影響。光譜歸一化和Gradient penalty可以幫助改進非正則化基線。
-
發生器
+關注
關注
4文章
1368瀏覽量
61677 -
GaN
+關注
關注
19文章
1933瀏覽量
73298 -
數據集
+關注
關注
4文章
1208瀏覽量
24689
原文標題:【GAN全局實用手冊】谷歌大腦最新研究,Goodfellow力薦
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PGA-SAR系統無法達到12比特級別的可重復性時,Δ-Σ系統會怎么樣呢?
測量系統的的重復性和重現性
相控陣探頭的重復性與可靠性
選轉換器?考慮下時序、精確度和可重復性以外的參考
基于賽靈思FPGA設計的整體時序具有完全可重復性
微帶傳輸線PIM測試可重復性的問答詳解
機器人技術的可重復性和準確性分析
計量標準重復性的測量方法
計量標準的重復性考核要求
如何實現FPGA的可重復性設計
計量標準的重復性考核要求
立儀科技光譜共焦應用之金屬隔膜靜態重復性測量






 工商網監
工商網監
評論