

去年,我們引入了面向移動設備設計的通用型計算機視覺神經網絡系列MobileNetV1,支持分類和檢測等功能。在個人移動設備上運行深度網絡可以提升用戶體驗,允許隨時隨地訪問,并且在安全性、隱私和能耗方面同樣具有優勢。隨著可讓用戶與現實世界實時交互的新應用的出現,對更高效神經網絡的需求也逐漸增加。
今天,我們很高興地宣布,MobileNetV2已經發布,它將為下一代移動視覺應用提供支持。
MobileNetV2 在 MobileNetV1 的基礎上進行了重大改進,并推動了移動視覺識別技術的發展,包括分類、對象檢測和語義分割。MobileNetV2 作為TensorFlow-Slim 圖像分類庫的一部分發布,您也可以在Colaboratory中瀏覽 MobileNetV2。或者,也可以下載筆記本并在本地使用Jupyter操作。MobileNetV2 還將作為 TF-Hub 中的模塊,預訓練檢查點位于github中。
MobileNetV2 以 MobileNetV1 [1] 的理念為基礎,使用深度可分離卷積作為高效構建塊。此外,V2 在架構中引入了兩項新功能:1) 層之間的線性瓶頸,以及 2) 瓶頸之間的快捷連接。基本結構如下所示。
MobileNetV2 架構概覽
藍色塊表示上面所示的復合卷積構建塊
我們可以直觀地理解為,瓶頸層對模型的中間輸入和輸出進行編碼,而內層封裝了讓模型可以將低級概念(如像素)轉換為高級描述符(如圖像類別)的功能。最后,與傳統的殘差連接一樣,快捷連接也可以提高訓練速度和準確性。要詳細了解技術細節,請參閱論文 “MobileNet V2:Inverted Residuals and Linear Bottlenecks”。
MobileNetV2 與第一代 MobileNet 相比有何不同?
總體而言,MobileNetV2 模型在整體延遲時間范圍內可以更快實現相同的準確性。特別是在 Google Pixel 手機上,與 MobileNetV1 模型相比,新模型的運算數減少 2 倍,參數減少 30%,而速度提升 30-40%,同時準確性也得到提高。
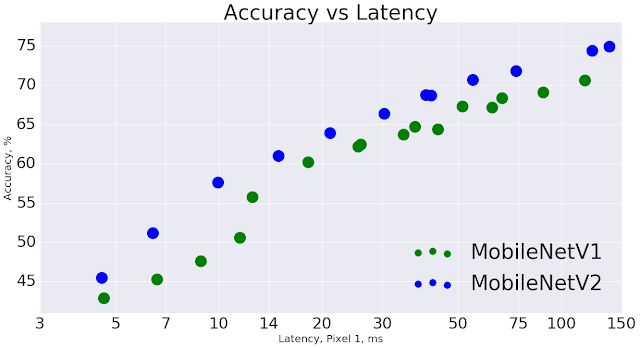
MobileNetV2 提高了速度(縮短了延遲時間)并提高了 ImageNet Top 1 的準確度
對于對象檢測和分割而言,MobileNetV2 是非常有效的特征提取器。例如,在檢測方面,與新引入的 SSDLite [2] 搭配使用時,在實現相同準確性的情況下,新模型的速度要比 MobileNetV1 快大約 35%。我們已在Tensorflow Object Detection API [4] 下開源該模型。

為了實現設備上語義分割,我們在近期宣布的 DeepLabv3 [3] 的簡化版中采用 MobileNetV2 作為特征提取器。在采用語義分割基準PASCAL VOC 2012的條件下,新模型的性能與使用 MobileNetV1 作為特征提取器的性能相似,但前者的參數數量減少 5.3 倍,乘加運算數量減少 5.2 倍。

綜上,MobileNetV2 提供了一個非常高效的面向移動設備的模型,可以用作許多視覺識別任務的基礎。我們現將此模型與廣大學術和開源社區分享,希望借此進一步推動研究和應用開發。
-
神經網絡
+關注
關注
42文章
4806瀏覽量
102699 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46552
原文標題:MobileNetV2:下一代設備上計算機視覺網絡
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
高通下一代頂級SoC驍龍855,以打造下一代5G設備
Supermicro將在 CES上發布下一代單路平臺
小草帶你體驗 下一代LabVIEW 軟件
支持更多功能的下一代汽車后座娛樂系統
為什么說射頻前端的一體化設計決定下一代移動設備?
如何建設下一代蜂窩網絡?
谷歌推出新的移動框架MobileNetV2提高多種計算機視覺任務
英國表示允許華為向該國提供下一代移動網絡即5G網絡建設
【R329開發板測評】全志 R329開發板跑 mobilenetv2






 工商網監
工商網監

評論