 用AI預測FIFA,失敗的原因是是什么?
用AI預測FIFA,失敗的原因是是什么?
2018年FIFA俄羅斯世界杯正式結束,法國隊獲得冠軍,克羅地亞和比利時隊分獲二三名。和2014年世界杯一樣,許多研究人員試圖提前預測結果一樣,今年也不例外,研究人員和科學家們試圖利用人工智能(AI)和統計知識來預測本屆FIFA世界杯64場比賽的結果。
近來人工智能(AI)的聲勢頗盛,被稱為是未來的技術。如今,人工智能也正在成為每個大中型企業不可或缺的一部分,但它的可信度有多高?在這篇文章里為大家展示一個簡單的示例 —— 分析AI在預測2018年世界杯結果中的表現。(注:這篇文章中是在最近的幾項研究中選取的,分析的方法和評價標準也是基于原研究進行的。)
預測FIFA世界杯的結果有許多不同的方法。一種方法是針對團隊能力和獲勝概率,通過成對比較來模擬每一場比賽結果。Zeileis,Leitner和Hornik使用相同的技術預測巴西將以 16.6% 的概率贏得本屆FIFA世界杯的冠軍,其次是德國(15.8%)和西班牙(12.5%)。
瑞士銀行瑞銀(UBS)也預測了本屆賽事的前 3 名的球隊,他們的結果是:德國將以 24.0%的概率獲得冠軍,其次是巴西(19.80%)、西班牙(16.1%)。
他們的預測模型考慮了四個因素,分別是:
Elo評級;
球隊在世界杯預選賽中的表現;
球隊在往屆世界杯比賽中所取得的成績;
主場優勢。
該模型通過10,000次蒙特卡羅模擬進行校準,以得到最終獲勝的概率和最近五次賽事的結果。
此外,2018年6月8日,來自德國的多特蒙德技術大學,慕尼黑技術大學和比利時根特大學的四位研究人員(A. Groll等人)在arXiv上發表了一篇關于2018年世界杯冠軍預測結果的研究論文。論文中采用著名的人工智能算法——隨機森林算法和泊松排序算法,并在6月14日世界杯開幕前公開發表。他們使用的數據集是一個涵蓋了過去四屆FIFA世界杯(2002-2014)的所有比賽。他們預測西班牙將成為冠軍,其次是德國隊和巴西隊。
以上這三項研究預測的前三名結果都涉及西班牙,德國和巴西三支隊伍,不同就在于對他們名次先后的順序。他們分別采用了三種不同的預測方法,數據和數據特征,但最終產生的結果幾乎相似。現在,世界杯結束了,我們可以來分析下這些預測失敗的模型。
在這些研究中,將會分析的是 A. Groll等人的研究方案。首先,他們使用了一個很好的數據源。其次,他們考慮了許多訓練過程中的特征和參數。隨后,他們采用隨機森林算法。接下來,我將逐個分析這項研究中所涉及的數據特征,誤差以及最終預測失敗的原因。
數據特征
Groll等人考慮了與團隊自身相關的各種特征,比如:
經濟因素(國家人均GDP,人口數量等);
運動因素(如ODDSET概率,FIFA排名等);
主場優勢(如主辦方,大陸,聯邦等);
團隊的組成結構(如隊伍中同一俱樂部隊友的人數,隊員的平均年齡,參加冠軍聯賽的球員數量等);
團隊的教練因素(如教練的年齡,任期,國籍等)。
總的來說,他們總結了這16個數據特征來分析每支世界杯參賽隊。
分類模型
正如之前提到的,他們使用一種眾所周知的算法--隨機森林算法,該算法的工作原理是基于決策樹,在許多數據分類任務中表現出很高的性能。此外,他們還引入泊松模型,根據當前的實力對各支球隊進行排名。
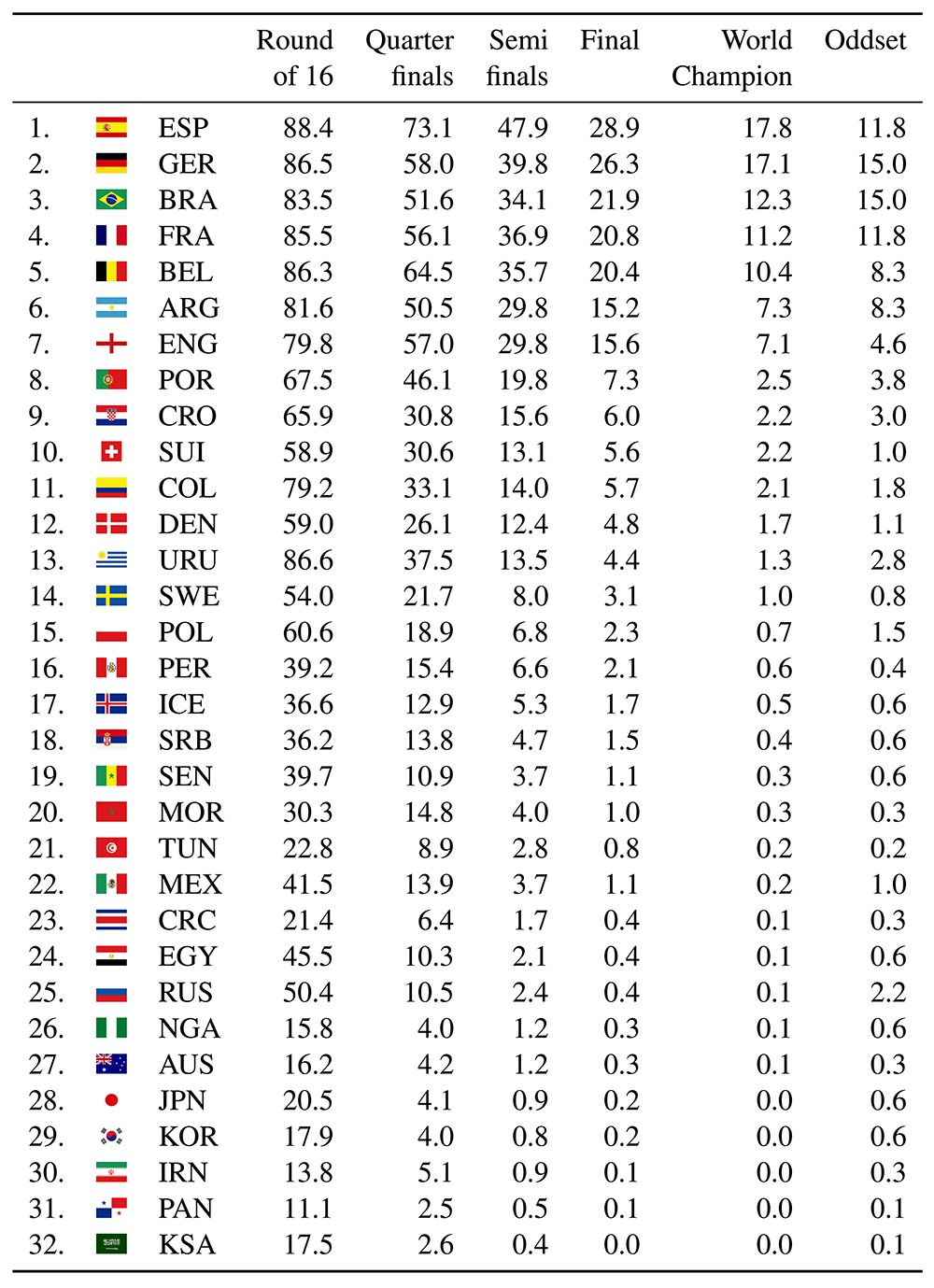
隨機森林算法預測的2018年FIFA世界杯比賽結果
預測
經過了 10 萬次賽事模擬后,他們的算法預測出西班牙隊有 28.9% 的機會晉級決賽,其次是德國(26.3%)和巴西隊(21.9%)。
錯誤
但是根據今年的世界杯結果來看,預測的前兩支球隊都未能進入四分之一決賽,更不用說決賽(巴西隊進入四分之一決賽)。根據世界杯的實際結果和預測,模型的均方根誤差(RMSE)和平均絕對誤差(MAE)計算結果如下:

這兩個指標顯示了模型的錯誤,以及它可以在多大程度上準確地預測出最終的團隊排名。盡管使用了 16 個特征以及大數據集(包含過去四屆世界杯的比賽數據),但最終得到的 RMSE和 MAE值都很高,這使得模型缺乏可信度,而基于機器學習的 AI方法(特別是隨機森林算法)也無法可靠地預測出結果。在本屆世界杯,俄羅斯,日本和伊朗的表現明顯好于預期,另一方面,德國也沒有晉級。
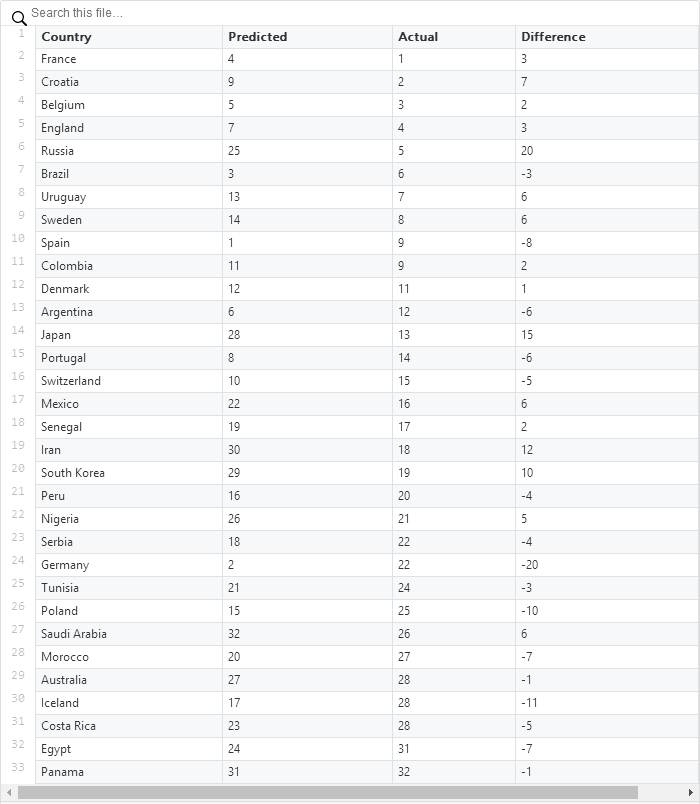
2018年 FIFA世界杯中每支球隊的預測排名、實際排名及預測差異結果(誤差)。
AI為什么失敗?
在人工智能和機器學習領域,為模型訓練和模型設計并提供適當的數據是非常重要。但在這種情況下,盡管擁有適當的數據(16個已清洗的特征),相對較大的數據量(過往四屆世界杯的比賽數據)以及具有正確參數的優秀算法,但即使這樣訓練有素的模型最終仍會失敗。我認為這種失敗的原因在于我們所預測的本質。
FIFA世界杯和很多其他以人為本的事件一樣,比賽在賽前和比賽期間(最少90分鐘)有太多的因素(遠不止是本研究考慮的16個),這些因素被稱為混淆變量。為了能夠正準確地預測結果,每場比賽的每一分鐘都要模擬出來。每分鐘甚至每秒鐘狀態的結果都取決先前的狀態,這種現象也稱為馬爾可夫鏈過程。錯誤的模擬狀態很容易導致比賽產生不可靠的結果。
除了內部因素外,足球比賽的結果也可能受到一些外部因素的影響,例如不公平的裁判,天氣,政治情況,甚至球員的個人問題等。而這些重要特征通常很難被衡量和收集。此外,總有一些探索和不確定性的機會,例如球員的一個致命失誤或進球得分,這是不容易預測的。
簡而言之,像 FIFA世界杯或者一些以人的活動為基礎的領域,具有隨機和動態環境是如今人工智能技術還無法很好駕馭的領域。這個例子就很好地說明了我們必須非常注意 AI在類似動態環境領域的適用性。此外,通過具有非常復雜的數據結構,針對任何的潛在偏差可能非常難以修正我們已經訓練好的模型。存在的偏差會導致模型只適用于特定的群體決策。而實施這樣的系統也將會對個人和公司產生巨大的問題,因此建議將人工智能應用于這種隨機和動態環境時作為補充的決策平臺。
-
AI
+關注
關注
87文章
30741瀏覽量
268896
原文標題:這么多人用AI預測FIFA 2018,為什么總是會失敗?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
聯想集團與FIFA國際足聯達成合作
用PCM2904做的聲卡,造成波形失真的原因是什么呢?
晶閘管逆變失敗的原因和解決方案
OPA828ID發燙的原因是什么?
HSM引導加載程序的HSM閃存寫入請求失敗是什么原因導致的?
人臉識別模型訓練失敗原因有哪些
對配置為從屬設備的PSoC4的寫入操作失敗,原因是什么?
光纖熔接機熔接失敗的原因
用stlink燒錄stm32H562失敗的原因?
GD32 MCU ISP失敗的原因





 工商網監
工商網監
評論