


要點
快速排序是一種交換排序。
快速排序由C. A. R. Hoare在1962年提出。
它的基本思想是:通過一趟排序將要排序的數據分割成獨立的兩部分:分割點左邊都是比它小的數,右邊都是比它大的數。
然后再按此方法對這兩部分數據分別進行快速排序,整個排序過程可以遞歸進行,以此達到整個數據變成有序序列。
詳細的圖解往往比大堆的文字更有說明力,所以直接上圖:
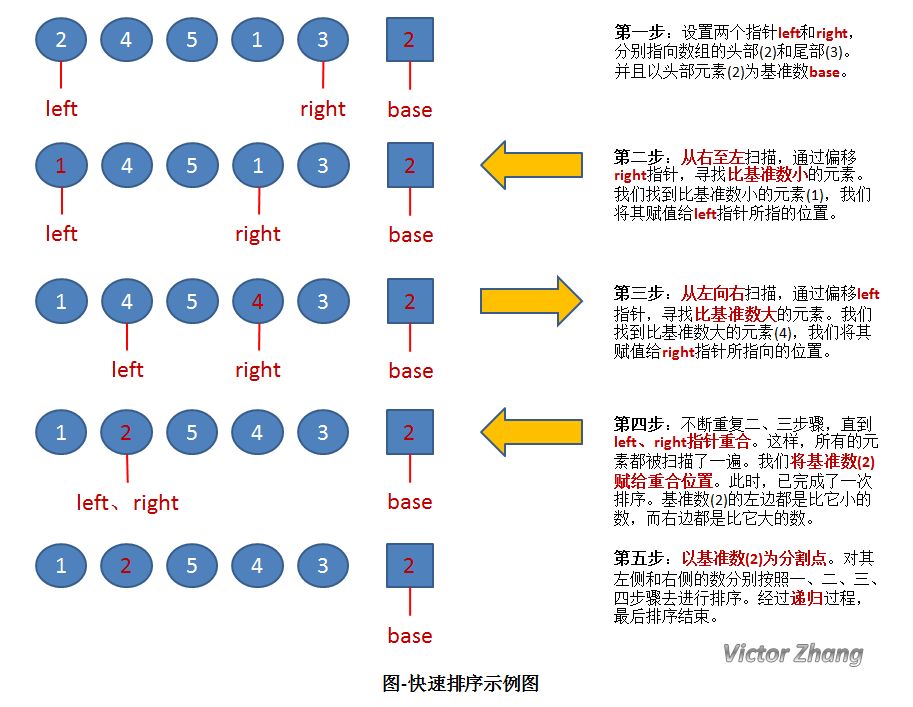
上圖中,演示了快速排序的處理過程:
初始狀態為一組無序的數組:2、4、5、1、3。
經過以上操作步驟后,完成了第一次的排序,得到新的數組:1、2、5、4、3。
新的數組中,以2為分割點,左邊都是比2小的數,右邊都是比2大的數。
因為2已經在數組中找到了合適的位置,所以不用再動。
2左邊的數組只有一個元素1,所以顯然不用再排序,位置也被確定。(注:這種情況時,left指針和right指針顯然是重合的。因此在代碼中,我們可以通過設置判定條件left必須小于right,如果不滿足,則不用排序了)。
而對于2右邊的數組5、4、3,設置left指向5,right指向3,開始繼續重復圖中的一、二、三、四步驟,對新的數組進行排序。
核心代碼
publicintdivision(int[]list,intleft,intright){//以最左邊的數(left)為基準intbase=list[left];while(left=base)right--;//找到了比base小的元素,將這個元素放到最左邊的位置list[left]=list[right];//從序列左端開始,向右遍歷,直到找到大于base的數while(left
快速排序算法的性能

時間復雜度
當數據有序時,以第一個關鍵字為基準分為兩個子序列,前一個子序列為空,此時執行效率最差。
而當數據隨機分布時,以第一個關鍵字為基準分為兩個子序列,兩個子序列的元素個數接近相等,此時執行效率最好。
所以,數據越隨機分布時,快速排序性能越好;數據越接近有序,快速排序性能越差。
空間復雜度
快速排序在每次分割的過程中,需要 1 個空間存儲基準值。而快速排序的大概需要 Nlog2N次的分割處理,所以占用空間也是 Nlog2N 個。
算法穩定性
在快速排序中,相等元素可能會因為分區而交換順序,所以它是不穩定的算法。
完整參考代碼
JAVA版本
代碼實現
1publicclassQuickSort{23publicintdivision(int[]list,intleft,intright){4//以最左邊的數(left)為基準5intbase=list[left];6while(left=base)9right--;10//找到了比base小的元素,將這個元素放到最左邊的位置11list[left]=list[right];1213//從序列左端開始,向右遍歷,直到找到大于base的數14while(left
運行結果
排序前: 1 3 4 5 2 6 9 7 8 0 base = 1: 0 1 4 5 2 6 9 7 8 3 base = 4: 3 2 4 6 9 7 8 5 base = 3: 2 3 base = 6: 5 6 7 8 9 base = 7: 7 8 9 base = 8: 8 9 排序后: 0 1 2 3 4 5 6 7 8 9
-
算法
+關注
關注
23文章
4713瀏覽量
95509 -
快速排序
+關注
關注
0文章
3瀏覽量
5516
原文標題:排序算法總結(2):快速排序
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
快速排序
揭秘冒泡排序、交換排序和插入排序
C語言排序中快速排序的技巧

php版冒泡排序是如何實現的?

jwt冒泡排序的原理





 工商網監
工商網監

評論