 由一只小貓帶咱們走進深度學習的世界吧!
由一只小貓帶咱們走進深度學習的世界吧!
首先就由一只小貓帶咱們走進深度學習的世界吧!
對于一個輸入樣本來說,深度學習和機器學習有著相同的目的,就是要把這個樣本進行最準確的分類。咱們從肉眼看很容易這是一只貓,因為我們有著這么多年的積累常識嘛!但是計算機可不這么聰明一眼就能看得出來,在計算機中,一個圖像是由像素點所構成的。
這里可能有同學對于計算機視覺不是很了解,我簡單的介紹下,像素點是一個從0到255范圍內的一個正值,那么這個點的大小意味著這個點所對應區域的一個亮度。咱們也可以把一個圖片當成一個三維數組比如[256,256,3]這里的256就分別代表了圖片的長和寬的大小,最后的3就是圖片的顏色通道,不知道通道是什么也不要緊,咱們暫且知道圖片是矩陣組成的就好啦!
這個矩陣就是長的這個樣子
那么我們所面臨的挑戰是什么呢?
我們要面對的可不僅僅是這樣一只蹲在我們面前可愛的小貓,在實際中有著很多的可能性,比如光照強度,遮蔽程度,角度等等,這些就成為了我們深度學習任務的一個極大的挑戰。
這些異形就是我們所面臨的挑戰
深度學習要解決的最核心也是最基本的問題就是分類任務了,它也是咱們理解深度學習一個最好的入手點。
分類問題的常規套路
一個分類任務的常規套路大致可以分為三點:
1、收集數據并給定標簽:
就是我們要制作訓練集了,包括data label這兩部分,別小看收集數據了,這部其實很麻煩的,沒有合適的數據很難訓練出優秀的模型的,兩個量都很重要,一個是質量一個是數量,對于我們深度學習來說,數量是很重要的,基本上都要以萬為基本單位的。
2、訓練一個分類器:這步可以說是很核心的一步,分類器的效果好壞決定了我們最終應用的效果,深度學習之所以效果要超過傳統的機器學習在部分領域上比如計算機視覺,主要在于深度學習所訓練的分類器更強大,這節課咱們只簡單的介紹,干貨還是在后面的。
3、測試評估:一個好的分類器,不是咱們通過大量的數據和一個強大的模型結構就可以的。在訓練好分類器后,一個更重要的點就是我們要去測試和評估,比如準確率,召回率等衡量指標。我們要通過這些指標反復調節模型參數直到得到最好的模型無論是機器學習還是深度學習都離不開這三步,有了這樣的一個流程下面我們就來看一看傳統的機器學習算法是如何進行分類任務的。
這個就是數據庫,簡單說下這個數據庫有10類標簽,就是有10個類別,接下來要做的就是訓練一個分類模型啦。
我的這個做法很多同學可能會說我很二,但是為了更好的給那些剛入門(坑)的同學更直觀的表達,咱們簡單的來樂呵下就好。

用每個圖片的像素點所構成的矩陣去算和它像素點差異最小的那幾個數據樣本是哪幾個。雖然做法很二,但這也是一個簡單的K近鄰問題,我們通過像素點的L1距離(這個看公式吧)去計算輸入和所有訓練集中的樣本的距離然后找出最小的那K個,輸入的樣本的類別就是那K個里投票和。
這里我要強調的是,我不是用這種做法去說一個分類的流程,而是讓大家看到咱們傳統做法所需的一些東西。這里咱們在做分類的時候所需的參數有K近鄰中的K的大小,還要選擇距離公式也就是L的選擇,這只是最少的參數選擇,要是更復雜的模型我們所需選擇的參數就更多了。不同的參數選擇可以說對于最終的結果有著很大的影響,這也就是傳統的機器學習算法很頭疼的一個問題很多東西都需要咱們不斷去嘗試。那么深度學習一個很強大的地方就是我們并不需要設定很多這樣的超參數。
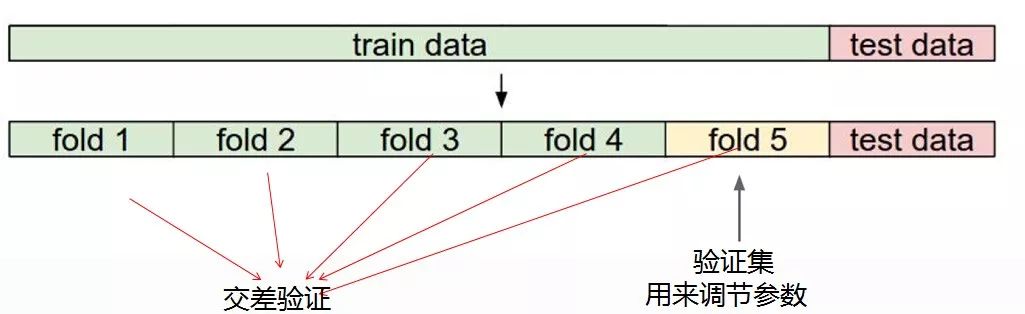
接下來咱們再來強調下上面這張圖,這個的目的就是很多同學并沒有太多機器學習和實戰的基礎,需要給大家對數據集的劃分有個大致的概念。
我們在訓練模型之前的數據準備要把整個數據分成兩個大部分,一個是訓練數據,一個是測試數據。理論上來說測試數據是很寶貴的,我們只有在最后的時候才能使用測試數據去評估,在訓練的過程中決不允許出現測試數據。
還有就是我們還要把訓練數據這個大部分切分成幾個小份,比如5個小份,這么做的目的是我們還需要驗證集,驗證集的意思就是我們在訓練模型的時候要不斷的做一個模型自測試效果的過程,比如用其中的4小份作為訓練數據,用另一小份作為驗證數據。還有一個知識點要給大家強調下,我們在實際訓練模型的時候更多的是使用交差驗證,什么是交差呢?就是我們這次取這4個作為訓練下次我們再取另外4個作為訓練,這樣就可以保證咱們訓練模型的可靠性更大!
-
分類器
+關注
關注
0文章
152瀏覽量
13202 -
機器學習
+關注
關注
66文章
8425瀏覽量
132775 -
深度學習
+關注
關注
73文章
5507瀏覽量
121298
原文標題:由一只貓看深度學習面臨哪些挑戰?
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
從零開始走進FPGA世界 V2.0【轉】
養一只compass需要什么樣的條件?
什么是深度學習?使用FPGA進行深度學習的好處?

電子玩具--小貓捉鳥電路圖
還記得那些年的華碩筆記本電腦嗎?讓我們一起走進華碩筆記本世界吧!
改進深度學習算法的光伏出力預測方法






 工商網監
工商網監
評論