 Pandas有哪幾種數據類型?
Pandas有哪幾種數據類型?
在我看來,對于Numpy以及Matplotlib,Pandas可以幫助創建一個非常牢固的用于數據挖掘與分析的基礎。而Scipy(會在接下來的帖子中提及)當然是另一個主要的也十分出色的科學計算庫,但是我認為前三者才是真正的Python科學計算的支柱。
所以,不需要太多精力,讓我們馬上開始Python科學計算系列的第三帖——Pandas。
導入Pandas
我們首先要導入我們的演出明星——Pandas。

Pandas的數據類型
Pandas基于兩種數據類型:series與dataframe。
一個series是一個一維的數據類型,其中每一個元素都有一個標簽。如果你閱讀過這個系列的關于Numpy的文章,你就可以發現series類似于Numpy中元素帶標簽的數組。其中,標簽可以是數字或者字符串。
一個dataframe是一個二維的表結構。Pandas的dataframe可以存儲許多種不同的數據類型,并且每一個坐標軸都有自己的標簽。你可以把它想象成一個series的字典項。
將數據導入Pandas
在我們開始挖掘與分析之前,我們首先需要導入能夠處理的數據。幸好,Pandas在這一點要比Numpy更方便。
在這里我推薦你使用自己所感興趣的數據集來使用。你的或其他國家的政府網站上會有一些好的數據源。例如,你可以搜索英國政府數據或美國政府數據來獲取數據源。當然,Kaggle是另一個好用的數據源。
在此,我將采用英國政府數據中關于降雨量數據,因為他們十分易于下載。此外,我還下載了一些日本降雨量的數據來使用。

將你的數據準備好以進行挖掘和分析
現在我們已經將數據導入了Pandas。在我們開始深入探究這些數據之前,我們一定迫切地想大致瀏覽一下它們,并從中獲得一些有用信息,幫助我們確立探究的方向。
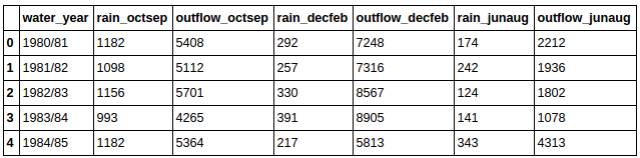
想要快速查看前x行數據:

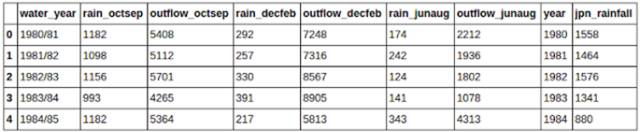
你將獲得一個類似下圖一樣的表:


你將獲得類似下圖的表


你將獲得同之前一樣的數據,但是列名已經變了:

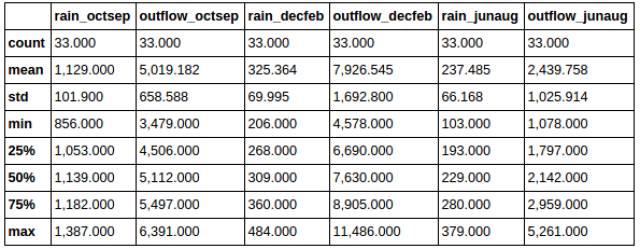
此外,你可能需要知道你數據的一些基本的統計信息。Pandas讓這件事變得非常簡單。

過濾
當你查看你的數據集時,你可能希望獲得一個特殊的樣本數據。例如,如果你有一個關于工作滿意度的問卷調查數據,你可能想要獲得所有在同一行業或同一年齡段的人的數據。
Pandas為我們提供了多種方法來過濾我們的數據并提取出我們想要的信息。有時候你想要提取一整列。可以直接使用列標簽,非常容易。

還記得我所說的命名列標簽的注意事項嗎?不使用空格和橫線等可以讓我們以訪問類屬性相同的方法來訪問列,即使用點運算符。

如果你讀過這一系列中Numpy那一篇帖子,你可能會記得一項技術叫做‘boolean masking’,即我們可以在數組上運行一個條件語句來獲得對應的布爾值數組。好,我們也可以在Pandas中做同樣的事。

我們也可以使用這些條件表達式來過濾一個已知的dataframe。



值得注意的是,由于操作符優先級的問題,在這里你不可以使用關鍵字‘and’,而只能使用’&’與括號


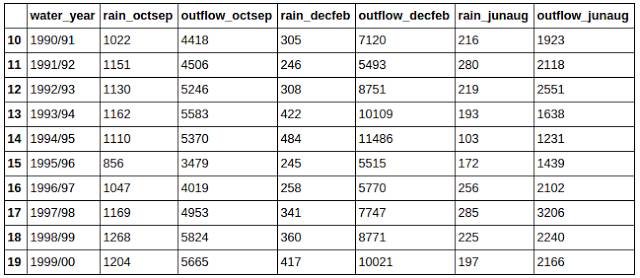
前幾部分為我們展示了如何通過列操作來獲得數據。實際上,Pandas同樣有標簽化的行操作。這些行標簽可以是數字或是其他標簽。獲取行數據的方法也取決于這些標簽的類型。
如果你的行有數字索引,你可以使用iloc引用他們:

可能在你的數據集里有年份的列,或者年代的列,并且你希望可以用這些年份或年代來索引某些行。這樣,我們可以設置一個(或多個)新的索引。
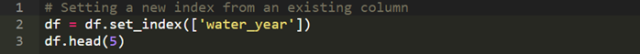

ix是另一個常用的引用一行的方法。那么,如果loc是字符串標簽的索引方法,iloc是數字標簽的索引方法,那什么是ix呢?事實上,ix是一個字符串標簽的索引方法,但是它同樣支持數字標簽索引作為它的備選。

既然ix可以完成loc和iloc二者的工作,為什么還需要它們呢?最主要的原因是ix有一些輕微的不可預測性。還記得我說數字標簽索引是ix的備選嗎?數字標簽可能會讓ix做出一些奇怪的事情,例如將一個數字解釋成一個位置。而loc和iloc則為你帶來了安全的、可預測的、內心的寧靜。然而必須指出的是,ix要比loc和iloc更快。
通常我們都希望索引是整齊有序地。我們可以在Pandas中通過調用sort_index來對dataframe實現排序。


對數據集應用函數
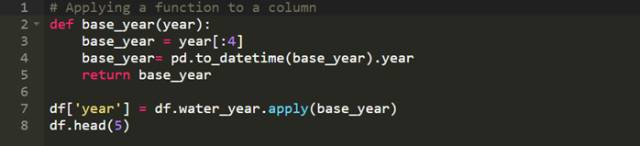
有時候你會想以某些方式改變或是操作你數據集中的數據。例如,如果你有一列年份的數據而你希望創建一個新的列顯示這些年份所對應的年代。Pandas對此給出了兩個非常有用的函數,apply和applymap。
操作一個數據集結構
另一件經常會對dataframe所做的操作是為了讓它們呈現出一種更便于使用的形式而對它們進行的重構。
首先,groupby:








合并數據集
有時候你有兩個單獨的數據集,它們直接互相關聯,而你想要比較它們的差異或者合并它們。沒問題,Pandas可以很容易實現:

如下你可以看到,兩個數據集在年份這一類上已經合并了。rain_jpn數據集僅僅包含年份以及降雨量。當我們以年份這一列進行合并時,僅僅’jpn_rainfall’這一列和我們UK雨量數據集的對應列進行了合并。
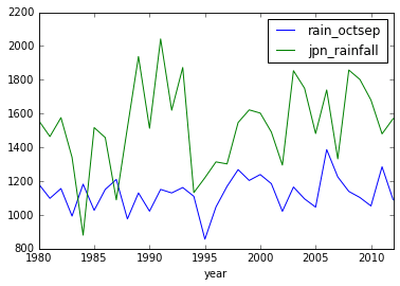
采用Pandas快速繪制圖表
Matplotlib很好用,但是想要畫出一個中途下降的圖表還是需要費一番功夫的。而有的時候你僅僅想要快速畫出一個數據的大致走勢來幫助你發掘搞清這些數據的意義。Pandas提供了plot函數滿足你的需求:

存儲你的數據集
在清理、重構以及挖掘完你的數據后,你通常會剩下一些非常重要有用的東西。你不僅應當保留下你的原始數據,也同樣需要保存下你最新處理過的數據集。

上述代碼會將你的數據存入一個csv文件以備下次使用。
到此為止,我們簡單介紹了Pandas。正如我之前說的,Pandas是非常好用的庫,而我們僅僅是接觸了一點皮毛。但是我希望通過我的介紹,你可以開始進行真正的數據清理與挖掘工作了。
像往常一樣,我非常希望你能盡快開始嘗試Pandas。找一兩個你喜歡的數據集,開一瓶啤酒,坐下來,然后開始探索你的數據吧。這確實是唯一的熟悉Pandas以及其他這一系列文章中提到的庫的方式。再加上你永遠不知道的,你會找到一些你感興趣的東西的。
-
數據
+關注
關注
8文章
7002瀏覽量
88943 -
series
+關注
關注
0文章
16瀏覽量
12657 -
python
+關注
關注
56文章
4792瀏覽量
84628
原文標題:Python科學計算之Pandas
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論