 寒武紀MLUv01架構采用臺積電16FF,MLU-100芯片
寒武紀MLUv01架構采用臺積電16FF,MLU-100芯片
寒武紀科技公司與華為海思合作,為麒麟970智能手機芯片組提供AI IP,并為數據中心創建了自己的系列芯片。
麒麟970內部的IP被稱為Cambricon-1A,是該公司的第一個可授權IP。當時,查找寒武紀的信息非常困難:它的網站是一系列靜態圖像,中文嵌入圖像本身。有趣的是,我們的AI加速翻譯功能應用在華為Mate 10上來翻譯網站內容。快進12-18個月,寒武紀網站現在可以互動并提供即將推出的產品的相關信息,包括一些最近發布的信息。
大芯片:走向數據中心
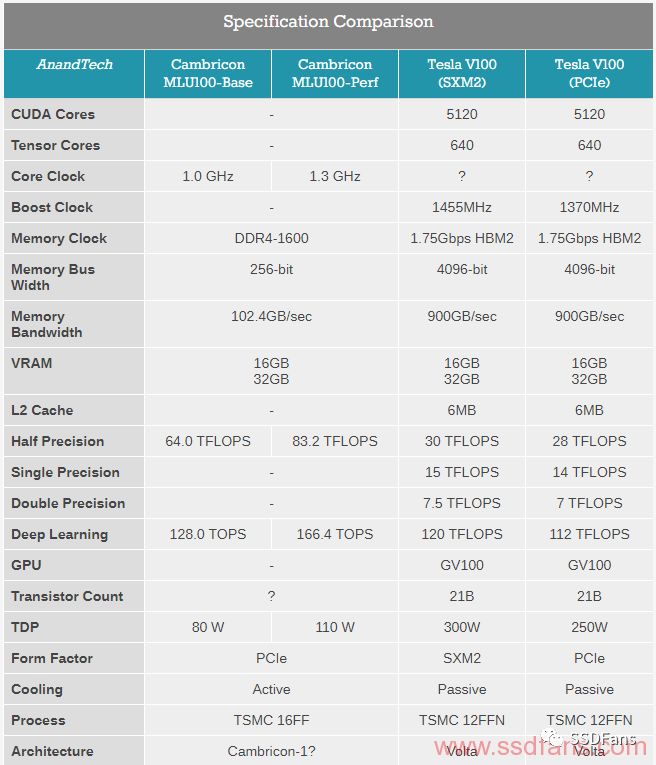
基于臺積電16FF,MLU-100是一款80W芯片,在1.0 GHz,或'標準'模式下,使用機器學習算法中常用的8位整數度量,具有64 TFLOPS的傳統半精度或128 TOPS功能。寒武紀的首席執行官陳天石博士表示,他們的新芯片具有1.30 GHz的高性能模式,允許83.2 TFLOPS(16位浮點)或166.4 TOPS( 8位整數),但功耗上升到110W。 這在技術上降低了能源效率,但是允許使用更快的芯片。 所有這些數據都依賴于啟用稀疏數據模式。
該芯片背后的技術是寒武紀最新的MLUv01架構,該架構被理解為是用于麒麟芯片組的Cambricon-1A的一種變體,但規模更大更快。顯然,與移動IP相比,必須對數據和電源管理實施額外的優化。 寒武紀也有它的1H架構和最新公布的1M架構,但是沒有公開如何將數據傳遞到芯片。
WikiChip的David Schor指出,如果提供給商業合作伙伴,這可能是NVIDIA的首次機器學習ASIC競賽。為此,寒武紀還在制造PCIe卡。
很明顯,NVIDIA在這方面擁有強大的用戶群和多代產品,以及利用其硬件優勢的軟件。 Cambricon沒有詳細說明他們計劃如何支持新芯片的SDK,但是它的網站上有一系列的SDK,支持TensorFlow,Caffe和MXNet。
進入數據中心:PCIe
在數據中心中即插即用的最佳方式是通過PCIe卡。 Cambricon的MLU100加速器卡就是這樣的:一個PCIe 3.0 x16實現256位16或32 GB DDR4-3200內存,這對于102.4 GB / s的帶寬是有好處的。要在NVIDIA上獲得大量內存,需要高端顯卡,但這些顯卡提供多倍的顯存帶寬。 MLU100卡上的存儲器也啟用了ECC。
迄今為止的報告稱,聯想將其卡作為ThinkSystem SR650雙Intel Xeon服務器的附加產品; 每臺機器最多兩個。 從聯想網站上看,它目前并不能使用。 鑒于華為在企業中的巨大影響力,我們很可能會看到這些系統中的芯片。
下一代:5TOPS/Watt
另外報道的是新的Cambricon-1M IP,盡管該公司沒有提供細節。 WikiChip公司表示,這款新IP主要針對7nm制造,所以當華為/海思開始發布7nm移動處理器,然后進入下一代面向服務器的產品時,我們很可能會看到它。與ARM的IP所宣傳的3 TOPS /瓦特相比,這個IP的目標是達到5 TOPS /瓦特。 寒武紀今年晚些時候會有一個培訓和推理芯片計劃,并在2019年再次進行更新。
-
芯片
+關注
關注
455文章
50714瀏覽量
423154 -
臺積電
+關注
關注
44文章
5632瀏覽量
166414 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565
原文標題:華為的麒麟NPU IP制造商寒武紀,生產出一個大AI芯片和PCIe卡
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
谷歌Tensor G系列芯片代工轉向臺積電
臺積電美國工廠投產A16芯片,蘋果成首批客戶
臺積電美國工廠啟動生產蘋果A16芯片
X86架構處理器有哪些優點和缺點
算力概念股寒武紀20cm漲停市值重回千億
臺積電正積極研發并推廣背面供電網絡(BSPDN)方案
臺積電準備生產HBM4基礎芯片
移動端芯片性能提升,Armv9架構新升級引發關注
寒武紀2023年報出爐:營收穩健虧損收窄 毛利率達69.16%
“AI芯片第一股”寒武紀發布2023年度業績快報 虧8.36億元!
arm架構和x86架構區別 linux是x86還是arm
寒武紀與智象未來聯手,推動視覺大模型的技術創新與應用
寒武紀與智象未來達成戰略合作并完成大模型適配






 工商網監
工商網監
評論