") GAN技術(shù)再到新高度 利用pytorch技術(shù)生成72種圖像
GAN技術(shù)再到新高度 利用pytorch技術(shù)生成72種圖像
隨著GAN的發(fā)展,單憑一張圖像就能自動(dòng)將面部表情生成動(dòng)畫(huà)已不是難事。但近期在Reddit和GitHub熱議的新款GANimation,卻將此技術(shù)提到新的高度。GANimation構(gòu)建了一種人臉解剖結(jié)構(gòu)(anatomically)上連續(xù)的面部表情合成方法,能夠在連續(xù)區(qū)域中呈現(xiàn)圖像,并能處理復(fù)雜背景和光照條件下的圖像。
若是能單憑一張圖像就能自動(dòng)地將面部表情生成動(dòng)畫(huà),那么將會(huì)為其它領(lǐng)域中的新應(yīng)用打開(kāi)大門(mén),包括電影行業(yè)、攝影技術(shù)、時(shí)尚和電子商務(wù)等等。隨著生成網(wǎng)絡(luò)和對(duì)抗網(wǎng)絡(luò)的流行,這項(xiàng)任務(wù)取得了重大進(jìn)展。像StarGAN這樣的結(jié)構(gòu)不僅能夠合成新表情,還能改變面部的其他屬性,如年齡、發(fā)色或性別。雖然StarGAN具有通用性,但它只能在離散的屬性中改變面部的一個(gè)特定方面,例如在面部表情合成任務(wù)中,對(duì)RaFD數(shù)據(jù)集進(jìn)行訓(xùn)練,該數(shù)據(jù)集只有8個(gè)面部表情的二元標(biāo)簽(binary label),分別是悲傷、中立、憤怒、輕蔑、厭惡、驚訝、恐懼和快樂(lè)。
GANimation的目的是建立一種具有FACS表現(xiàn)水平的合成面部動(dòng)畫(huà)模型,并能在連續(xù)領(lǐng)域中無(wú)需獲取任何人臉標(biāo)志(facial landmark)而生成具有結(jié)構(gòu)性(anatomically-aware)的表情。為達(dá)到這個(gè)目的,我們使用EmotioNet數(shù)據(jù)集,它包含100萬(wàn)張面部表情(使用其中的20萬(wàn)張)圖像。并且構(gòu)建了一個(gè)GAN體系結(jié)構(gòu),其條件是一個(gè)一維向量:表示存在/缺失以及每個(gè)動(dòng)作單元的大小。我們以一種無(wú)監(jiān)督的方式訓(xùn)練這個(gè)結(jié)構(gòu),僅需使用激活的AUs圖像。為了避免在不同表情下,對(duì)同一個(gè)人的圖像進(jìn)行訓(xùn)練時(shí)出現(xiàn)冗余現(xiàn)象,將該任務(wù)分為兩個(gè)階段。首先,給定一張訓(xùn)練照片,考慮一個(gè)基于AU條件的雙向?qū)菇Y(jié)構(gòu),并在期望的表情下呈現(xiàn)一張新圖像。然后將合成的圖像還原到原始的樣子,這樣可以直接與輸入圖像進(jìn)行比較,并結(jié)合損失來(lái)評(píng)估生成圖像的照片級(jí)真實(shí)感。此外,該系統(tǒng)還超越了最先進(jìn)的技術(shù),因?yàn)樗梢栽诓粩嘧兓谋尘昂驼彰鳁l件下處理圖像。
最終,構(gòu)建了一種結(jié)構(gòu)上連續(xù)的面部表情合成方法,能夠在連續(xù)區(qū)域中呈現(xiàn)圖像,并能處理復(fù)雜背景和光照條件下的圖像。它與其他已有的GAN方法相比,無(wú)論是在結(jié)果的視覺(jué)質(zhì)量還是生成的可行性上,都是具有優(yōu)勢(shì)的。
圖1:根據(jù)一張圖像生成的面部動(dòng)畫(huà)
無(wú)監(jiān)督學(xué)習(xí)+注意力機(jī)制
讓我們將一個(gè)輸入RGB圖像定義為 ,這是在任意面部表情下捕獲的。通過(guò)一組N個(gè)動(dòng)作單元
,這是在任意面部表情下捕獲的。通過(guò)一組N個(gè)動(dòng)作單元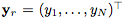 對(duì)每個(gè)手勢(shì)表達(dá)式進(jìn)行編碼,其中每個(gè)
對(duì)每個(gè)手勢(shì)表達(dá)式進(jìn)行編碼,其中每個(gè)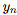 表示0到1之間的歸一化值,表示第n個(gè)動(dòng)作單元的大小。值得指出的是,由于這種連續(xù)的表示,可以在不同表情之間進(jìn)行自然插值,從而可以渲染各種逼真、流暢的面部表情。
表示0到1之間的歸一化值,表示第n個(gè)動(dòng)作單元的大小。值得指出的是,由于這種連續(xù)的表示,可以在不同表情之間進(jìn)行自然插值,從而可以渲染各種逼真、流暢的面部表情。
我們的目標(biāo)是學(xué)習(xí)一個(gè)映射 ,將
,將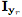 轉(zhuǎn)換成一個(gè)基于動(dòng)作單元目標(biāo)
轉(zhuǎn)換成一個(gè)基于動(dòng)作單元目標(biāo) 的輸出圖像
的輸出圖像 ,即:我們希望估計(jì)映射:
,即:我們希望估計(jì)映射:
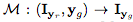
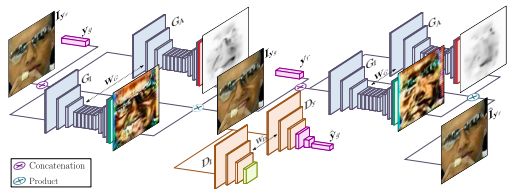
圖2. 生成照片級(jí)真實(shí)條件圖像方法的概述
所提出的架構(gòu)由兩個(gè)主要模塊組成:用于回歸注意力和color mask的生成器G; 用于評(píng)估所生成圖像的真實(shí)度 和表情調(diào)節(jié)實(shí)現(xiàn)
和表情調(diào)節(jié)實(shí)現(xiàn) 的評(píng)論家(critic) D。
的評(píng)論家(critic) D。
我們的系統(tǒng)不需要監(jiān)督,也就是說(shuō),不需要同一個(gè)人不同表情的圖像對(duì),也不假設(shè)目標(biāo)圖像
生成器G
生成器器 被訓(xùn)練來(lái)逼真地將圖像
被訓(xùn)練來(lái)逼真地將圖像
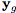
我們系統(tǒng)的一個(gè)關(guān)鍵要素是使G只聚焦于圖像的那些負(fù)責(zé)合成新表情的區(qū)域,并保持圖像的其余元素如頭發(fā)、眼鏡、帽子、珠寶等不受影響。為此,我們?cè)谏善髦星度肓艘粋€(gè)注意力機(jī)制。
圖3:Attention-based的生成器
給定一個(gè)輸入圖像和目標(biāo)表情,生成器在整個(gè)圖像上回歸并注意mask A和RGB顏色變換C。attention mask 定義每個(gè)像素強(qiáng)度,指定原始圖像的每個(gè)像素在最終渲染圖像中添加的范圍。
具體地說(shuō),生成器器不是回歸整個(gè)圖像,而是輸出兩個(gè)mask,一個(gè)color mask C和一個(gè)attention mask A。最終圖像可表示為:
首先測(cè)試主要組件,即單個(gè)和多個(gè)AU編輯。然后將我們的模型與離散化情緒編輯任務(wù)中的當(dāng)前技術(shù)進(jìn)行比較,并展示我們的模型處理野外圖像的能力,可以生成大量的解剖學(xué)面部變換的能力。最后討論模型的局限性和失敗案例。
值得注意的是,在某些實(shí)驗(yàn)中,輸入的面部圖像是未被裁剪的。在這種情況下,我們首先使用檢測(cè)器2來(lái)對(duì)面部進(jìn)行定位和裁剪,利用(1)式進(jìn)行表達(dá)式的轉(zhuǎn)換,以應(yīng)用于相關(guān)區(qū)域。 最后,將生成的面部圖像放回原圖像中的原始位置。注意力機(jī)制(attention mechanism)可以確保經(jīng)過(guò)變換處理的裁剪面部圖像和原始圖像之間的平滑過(guò)渡。
稍后圖中可見(jiàn),與以前的模型相比,經(jīng)過(guò)這三個(gè)步驟的處理可以得到分辨率更高的圖像(鏈接見(jiàn)文末)。
圖4:?jiǎn)蝹€(gè)動(dòng)作單元的編輯
隨著強(qiáng)度(0.33-1)的增加,一些特定的動(dòng)作單元被激活。圖中第一行對(duì)應(yīng)的是動(dòng)作單元應(yīng)用強(qiáng)度為零的情況,可以在所有情況下正確生成了原始圖片。
圖5: 注意力模型
中間注意力掩模A(第一行)和顏色掩模C(第二行)的細(xì)節(jié)。 最底下一行圖像是經(jīng)合成后的表達(dá)結(jié)果。注意掩模A的較暗區(qū)域表示圖像的這些區(qū)域與每個(gè)特定的動(dòng)作單元的相關(guān)度更高。 較亮的區(qū)域保留自原始圖像。
圖6: 與當(dāng)前最先進(jìn)技術(shù)的定性比較
圖為面部表情圖像合成結(jié)果,分別應(yīng)用DIAT、CycleGAN、IcGAN、StarGAN和我們的方法。可以看出,我們的解決方案在視覺(jué)準(zhǔn)確度和空間分辨率之間達(dá)到了最佳平衡。 使用StarGAN的一些結(jié)果則出現(xiàn)了一定程度的模糊。
圖7:采樣面部表情分布空間
通過(guò)yg向量對(duì)活動(dòng)單元進(jìn)行參數(shù)化,可以從相同的源圖像合成各種各樣的照片的真實(shí)圖像。
圖8:自然圖像的定性評(píng)估
上圖:分別給出了取自電影《加勒比海盜》中的一幅原圖像(左)及其用我們的方法生成的圖像(右)。 下圖:用類(lèi)似的方式,使用圖像框(最左綠框)從《權(quán)力的游戲》電視劇中合成了五個(gè)不同表情的新圖像。
圖9:成功和失敗案例
圖中分別表示了源圖像Iyr,目標(biāo)Iyg,以及顏色掩膜C和注意力掩模A. 上圖是在極端情況下的一些成功案例。 下圖是一些失敗案例
-
GaN
+關(guān)注
關(guān)注
19文章
1933瀏覽量
73286 -
pytorch
+關(guān)注
關(guān)注
2文章
807瀏覽量
13200
原文標(biāo)題:GAN如此簡(jiǎn)單的PyTorch實(shí)現(xiàn),一張臉生成72種表情(附代碼)
文章出處:【微信號(hào):AI_era,微信公眾號(hào):新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
一種將電子配線架靈活性提升到新高度的創(chuàng)新方案
ZIF架構(gòu)有哪些優(yōu)勢(shì)?如何使無(wú)線電設(shè)計(jì)性能達(dá)到的新高度?
圖像生成對(duì)抗生成網(wǎng)絡(luò)gan_GAN生成汽車(chē)圖像 精選資料推薦
Maxim全新高度集成的數(shù)字脈沖發(fā)生器
5G助力MBB走向新高度
必讀!生成對(duì)抗網(wǎng)絡(luò)GAN論文TOP 10
生成對(duì)抗網(wǎng)絡(luò)GAN論文TOP 10,幫助你理解最先進(jìn)技術(shù)的基礎(chǔ)
TCL推出免污式洗衣機(jī) 將免污技術(shù)推向了一個(gè)新高度
重磅新品 | 解鎖空間受限的消費(fèi)和工業(yè)應(yīng)用,ams微型攝像頭引領(lǐng)攝像新高度
音圈馬達(dá)加持的vivoX70再創(chuàng)手機(jī)影像新高度
工業(yè)智能新高度,昂視領(lǐng)跑機(jī)器視覺(jué)賽道正當(dāng)時(shí)

高技傳動(dòng)科技登陸央視,國(guó)家平臺(tái)助力打造品牌新高度

光纖矩陣,提升視覺(jué)體驗(yàn)新高度






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論