 機器學習開發者如何尋找滿足自己需求的第三方庫?
機器學習開發者如何尋找滿足自己需求的第三方庫?
在軟件開發中容易被忽視的重要事情之一是共享代碼存儲庫的想法。作為程序員,充分利用第三方庫使開發更高效。從某種意義上說,他們改變了軟件的開發過程。
機器學習開發者如何尋找滿足自己需求的第三方庫?當然,除了共享代碼之外,我們還想分享預訓練模型。共享預訓練模型使開發人員可以根據不用領域、不用場景進行自定義,而無需訪問計算資源或用于訓練原始模型的數據。例如,NASNet 需要數千小時進行模型訓練。通過共享學習的權重,模型開發人員可以使其他人更容易重用和構建工作。
機器學習模型的 “成分” 被打包,并通過 TensorFlow Hub 進行共享 。從某種意義上說,除了架構本身之外,共享預先訓練的模型還共享用于開發模型所用的計算時間和數據集。
TensorFlow Hub 專門為機器學習開發者提供第三方庫。在本文中,我們將簡單介紹 TensorFlow Hub 中常用的幾種庫。TensorFlow Hub 是一個平臺,主要被用于發布、發現和重用機器學習模塊。一個模塊,我們指的是 TensorFlow 圖形的一個獨立部分及其權重,可以在其他類似任務中重復使用。通過重用模塊,開發人員可以使用較小的數據集訓練模型,提升泛化能力或簡單地加速訓練。讓我們看幾個例子來說明這一點。
圖像再訓練
作為第一個例子,讓我們看一下可以用來訓練圖像分類器的技術,僅從少量訓練數據開始。現代圖像識別模型具有數百萬個參數,當然,從頭開始訓練需要大量標記數據和計算能力。使用稱為圖像重新訓練的技術,您可以使用更少量的數據訓練模型,并且使用更少的計算時間。如下所示:
1# Download and use NASNet feature vector 2module.
3module = hub.Module(
4“https://tfhub.dev/google/imagenet/nasnet_large/feature_vector/1")
5features = module(my_images)
6logits = tf.layers.dense(features, NUM_CLASSES)
probabilities = tf.nn.softmax(logits)
基本思想是重用現有的圖像識別模塊從圖像中提取特征,然后在這些特征之上訓練新的分類器。如您所見,在構造 TensorFlow 圖時,可以從 URL(或從文件系統路徑)實例化 TensorFlow Hub 模塊。
TensorFlow Hub 上有多種模塊供您選擇,包括 NASNet,MobileNet(包括最近的 V2),Inception,ResNet 等。要使用模塊,請導入 TensorFlow Hub,然后將模塊的 URL 復制/粘貼到代碼中。

每個模塊都定義了接口,我們可以在很少或根本不了解其內部的情況下以可替換的方式使用。在這種情況下,此模塊有一個方法可用于獲取預期的圖像大小。作為開發人員,您只需要提供正確形狀的一批圖像,并調用模塊以獲取特征表示。此模塊負責為您預處理圖像,因此您可以在一個步驟中直接從一批圖像轉到特征表示。從這里開始,您可以在這些基礎上學習線性模型或其他類型的分類器。
請注意我們正在使用的模塊由 Google 托管,并且已經進行版本控制。模塊可以像普通的 Python 函數一樣應用,以構建圖形的一部分。一旦導出到磁盤,模塊就是自包含的,并且可以被其他人使用而無需訪問用于創建和訓練它的代碼和數據。
文本分類
我們來看看第二個例子。想象一下,你想訓練一個模型,將電影評論分類為正面或負面,從少量的訓練數據開始(比如幾百個正面和負面的電影評論)。由于您的示例數量有限,因此您決定利用先前在更大的語料庫中訓練的單詞嵌入數據集。如下所示:
1# Download a module and use it to retrieve word embeddings.
2embed = hub.Module(“https://tfhub.dev/google/nnlm-en-dim50/1")
3embeddings = embed([“The movie was great!”])
和以前一樣,我們首先選擇一個模塊。TensorFlow Hub 有多種文本模塊供您探索,包括各種語言的神經網絡語言模型,以及在維基百科上訓練的 Word2vec,以及在 Google 新聞上訓練的 NNLM。

在這種情況下,我們將使用一個模塊進行字嵌入。上面的代碼下載一個模塊,用它來預處理一個句子,然后獲取每個標記的嵌入。
這意味著您可以直接從數據集中的句子轉換為適合分類器的格式。該模塊負責對句子進行標記,以及其他邏輯。預處理邏輯和嵌入都封裝在一個模塊中,可以更輕松地試驗各種單詞嵌入數據集或不同的預處理策略,而無需大幅更改代碼。

如果您想嘗試,請使用本教程進行操作,并了解 TensorFlow Hub 模塊如何與 TensorFlow Estimators 配合使用。
注:教程鏈接
https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub
通用句子編碼器
我們還分享了一個新的 TensorFlow Hub 模塊!下面是使用 Universal Sentence Encoder 的示例。它是一個句子級嵌入模塊,適用于各種數據集。它擅長語義相似性,自定義文本分類和聚類。
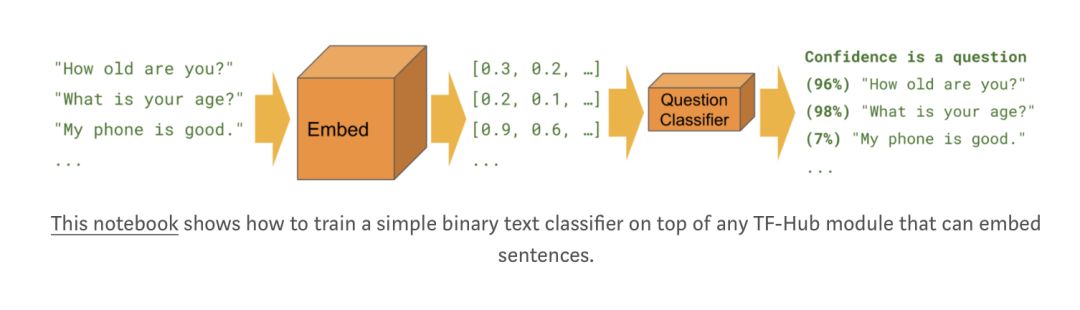
與圖像再訓練一樣,需要相對較少的標記數據使模塊適應特定的任務。如下所示:
1# Use pre-trained universal sentence encoder to build text vector
2review = hub.text_embedding_column(
3“review”, “https://tfhub.dev/google/universal-sentence-encoder/1")
4features = {
5“review”: np.array([“this movie is a masterpiece”, “this movie was terrible”, …])
6}
7labels = np.array([[1], [0], …])
8input_fn = tf.estimator.input.numpy_input_fn(features, labels, shuffle=True)
9estimator = tf.estimator.DNNClassifier(hidden_units, [review])
10estimator.train(input_fn, max_steps=100)
查看本教程以了解更多信息。
注:教程鏈接
https://www.tensorflow.org/hub/tutorials/text_classification_with_tf_hub
其他模塊
TensorFlow Hub 不僅僅有圖像和文本分類庫。在網站上,你還可以找到幾個 Progressive GAN 模型和 Google Landmarks Deep Local Features.
注意事項
使用 TensorFlow Hub 模塊時有幾個重要注意事項。首先,請記住模塊包含可運行的代碼。并始終使用受信任來源的模塊。其次,與所有機器學習一樣,fairness 是一個重要的考慮因素。我們上面展示的兩個示例都利用了大量預先訓練的數據集。重用這樣的數據集時,重要的是要注意它包含哪些數據,以及它們如何影響您正在構建的產品及其用戶。
-
分類器
+關注
關注
0文章
152瀏覽量
13202 -
機器學習
+關注
關注
66文章
8425瀏覽量
132775 -
tensorflow
+關注
關注
13文章
329瀏覽量
60544
原文標題:TensorFlow Hub:可重用的機器學習模型庫
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論