


大規模帶標注的數據集的出現是深度學習在計算機視覺領域取得巨大成功的關鍵因素之一。然而,監督式學習存在一個主要問題:過于依賴大規模數據集,而數據集的收集和手動數據標注需要耗費大量的人力成本。
作為替代方案,自監督學習旨在通過設計輔助任務來學習可區別性的視覺特征,如此,目標標簽就能夠自由獲取。這些標簽能夠直接從訓練數據或圖像中獲得,并為計算機視覺模型的訓練提供監督信息,這與監督式學習的原理是相同的。但是不同于監督式學習的是,自監督學習方法通過挖掘數據的性質,從中學習并生成視覺特征的語義標簽信息。還有一類方法是弱監督學習,這種學習方式能夠利用低水平的注釋信息來解決更復雜的計算機視覺任務,如利用自然場景下每張圖像的類別標簽進行目標檢測任務。
我們的目標是探索一種自監督的解決方案,利用圖像和圖像之間的相關性來替代完全監督式的 CNN訓練。此外,我們還將探索非結構化語言語義信息的強弱,并將其作為文本監督信號來學習視覺特征。
我們擴展了之前提出的方法并展示了以自監督的方式進行插圖文章的學習,這能夠進一步擴展到更大的訓練數據集(如整個英語維基百科)。
通過實驗,我們驗證了 TextTopicNet的表現優于其他基準評估中的自監督或自然監督的方法。此外,我們還在更具挑戰性的 SUN397數據集上測試了我們的方法,結果表明 TextTopicNet能夠減少自監督學習和監督學習之間的性能差距。
我們展示了將上下文的文本表征用于模型的訓練,這能夠有助于網絡自動學習多模態的語義檢索。在圖像——文本的檢索任務中,TextTopicNet的表現超過了無監督學習的方法,而與監督學習的方法相比,我們的方法能夠在無需任何特定類別信息的情況下還能表現出有競爭力的性能。
在自監督學習設置下,我們對不同的文本嵌入方法進行了對比分析,如word2vec,GloVe,FastText,doc2vec等。
此外,我們還公開發布了我們所收集的數據集,該數據集采自整個英語維基百科,由 420 萬個圖像組成,每張圖像都有對應的文字描述信息。
維基圖像——文本數據集
我們以維基百科作為數據的來源,這是一個基于網絡的多語言的百科全書項目,目前有 4000 多萬篇文章,含 299 種不同語言。維基百科文章通常由文字及其他多媒體類型的對象(如圖像,音頻或視頻文件)組成,因此可以將其視為多模態的文檔數據。對于我們的實驗,我們使用兩個不同的維基百科文章集合:(a) ImageCLEF 2010維基百科數據集;(b)我們所收集的英語維基百科圖像——文本數據集,包含 420 萬圖像文本對組成的數據,下圖1展示了 11 種類別的文章分布情況。
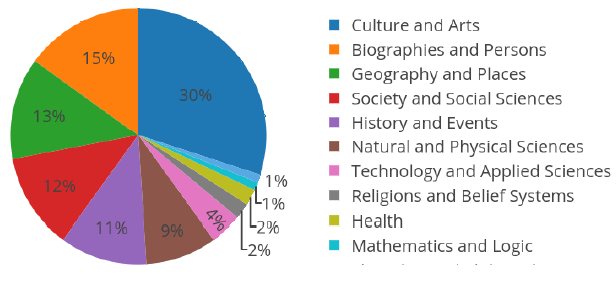
圖1英語維基百科種11種類別的文章分布情況
TextTopicNet
我們提出了一種 TextTopicNet的方法,通過挖掘大規模多模態網絡文檔的大規模語料庫(如維基百科文章),以自監督的方式來學習視覺特征。在自監督學習設置下,TextTopicNet能夠使用免費可用的非結構化、多模態的內容來學習可區別的視覺特征,并在給定圖像的下,通過訓練 CNN來預測可能插圖的語義環境。我們的方法示意圖如下圖 2 所示,該方法采用一個文本嵌入算法來獲取文本部分的向量表征,然后將該表征作為 CNN視覺特征學習的一種監督信號。我們進一步使用多種類別的文檔以及詞級(word-level)的文本嵌入方法,發現通過 LDA主題模型框架發現的隱藏語義結構,能夠在主題層面最佳地展現文本信息。
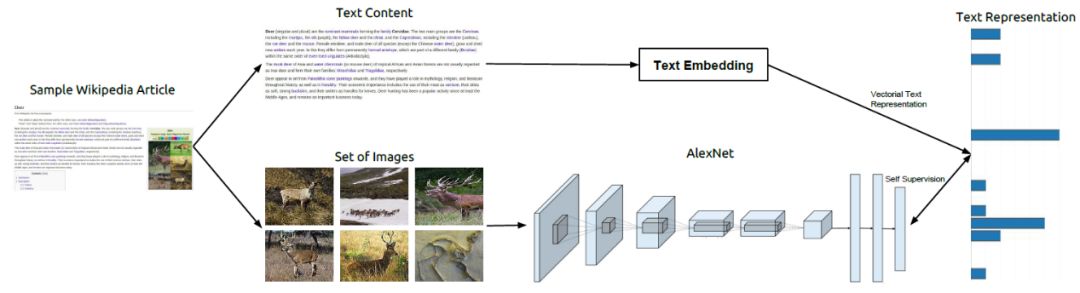
圖2 方法概覽。維基百科文章包含一個主題的文本描述,這些文章同時也附有支持文本的插圖。文本嵌入框架能夠與文本信息相關的全局上下文表征。而整篇文章的這種文本表征向量被用于為 CNN的訓練提供自監督信號
如圖 3 所示,作為主題層面的語義描述器,需要大量可用的關于特定類別或細粒度類別的視覺數據。雖然在我們收集的數據中,這類數據非常有限,但是這很容易在更廣泛的目標類別(如哺乳動物)中找到足夠多的、有代表性的圖像。因此,在給定的目標主題情況下,我們的方法能夠學習到期望的視覺特征,這種特征是通用的,即同樣適用于其他特定的計算機視覺任務。
圖 3 描述特定實體的維基百科文章。如 (a) 中“羚羊”或 (b) 中的“馬”,每個實體通常包含五張圖像。對于一些特定實體,如 (c)中的“食草哺乳動物”,相關的圖像很容易就達到數百或成千上萬張。
我們還訓練一個 CNN模型,它能夠直接將圖像投影到文本的語義空間,而 TextTopicNet不僅能夠在無需任何標注信息的情況下從頭開始學習數據的視覺特征,還可以以自然的方式進行多模態的檢索,而無需額外的注釋或學習成本。
實驗
我們通過大量的實驗來展示 TextTopicNet模型所學習到的視覺特征質量。衡量的標準是所習得的視覺特征具有足夠好的可區別性和魯棒性,并能進一步適用于那些未見過的類別數據。
首先,為了驗證圖像—文本對的自監督學習,我們比較了各種文本嵌入方法。其次,我們在 PASCAL VOC 2007 數據集的圖像分類任務中對 TextTopicNet模型每層的特征進行基準分析,以找到了 LDA模型的最佳主題數量。然后,我們分別在 PASCAL、SUN397和 STL-10數據集的圖像分類和檢測任務中進一步與當前最佳的自監督方法和無監督方法進行了比較。最后,我們利用維基百科檢索數據集對我們的方法進行了圖像檢索和文本查詢實驗。
自監督視覺特征學習的文本嵌入算法比較
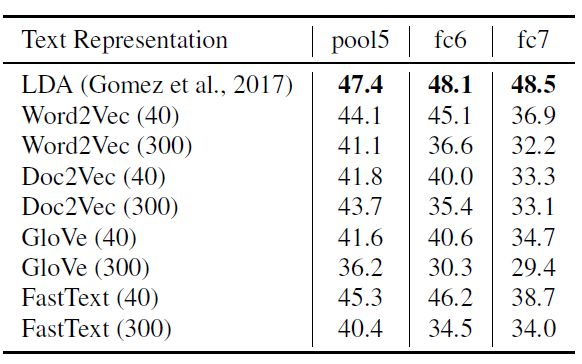
在自監督視覺特征學習的設置下,我們對 word2vec,GloVe,FastText,doc2vec及 LDA算法進行了比較分析。對于每種文本嵌入方法,我們都將訓練一個 CNN模型并利用網絡不同層獲得的特征信息去學習一個一對多的SVM (one-vs-all SVM)。下表1顯示了在 PASCAL VOC2007數據集中,使用不同文本嵌入方法,模型所展現的分類性能。我們觀察到在自監督的視覺特征學習任務中,基于嵌入的 LDA方法展現了最佳全局表現。
表1:使用不同文本嵌入方法的 TextTopicNet模型在 PASCAL VOC2007數據集圖像分類任務上的性能表現(%mAP)
LDA模型的超參數設置
我們用 ImageCLEF Wikipedia數據集上 35582 篇文章訓練了一個 LDA 模型,以確定 LDA模型的主題數量。下圖4展示了實驗結果,我們可以看到擁有 40 個主題數的 LDA模型能夠獲得最佳的 SVM驗證準確性。
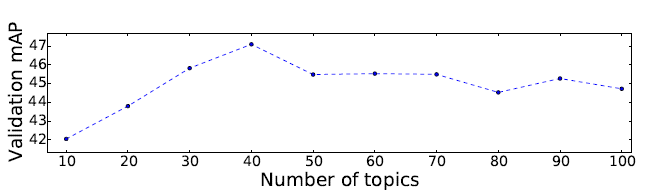
圖4隨著 LDA主題數量的變化,PASCAL VOC2007數據集上 One vs. Rest線性 SVM所取得的驗證準確性(%mAP)
圖像分類和圖像檢測
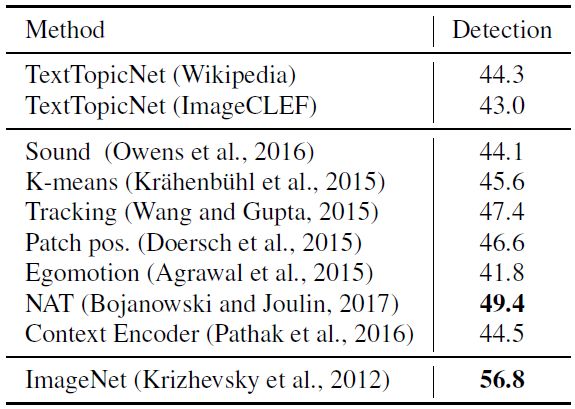
我們分別在 PASCAL、SUN397和 STL-10數據集進行圖像分類和檢測任務,比較并分析 TextTopicNet以及當前最佳的自監督和無監督模型的表現。下表 2、3和4 分別展示各模型在 PASCAL VOC 2007、SUN397和 STL-10數據集上的分類表現,表 5 展示了在 PASCAL VOC 2007數據集上模型的檢測性能。
表 2 PASCAL VOC2007數據集上各模型的分類表現(%mAP)
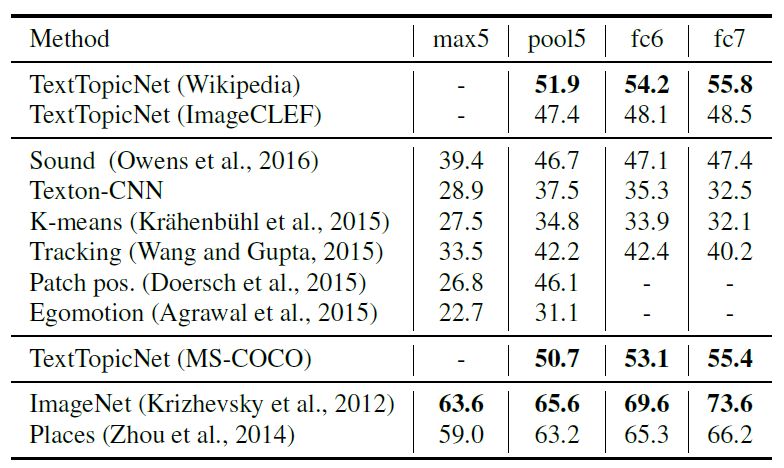
表 3 SUN397數據集上各模型的分類表現(%mAP)
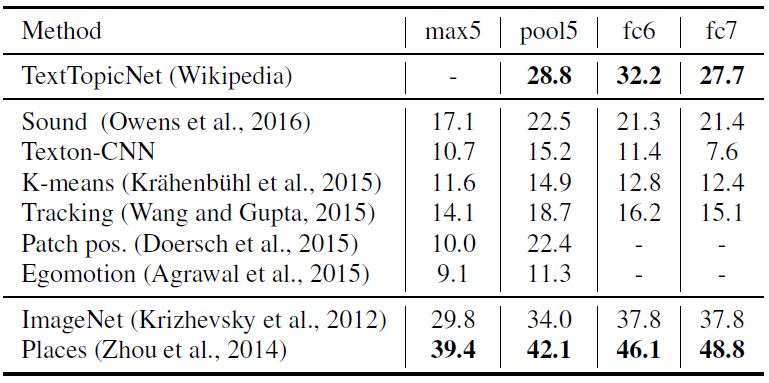
表 4 STL-10數據集上各模型的分類表現(%mAP)

表 5 PASCAL VOC 2007數據集上各模型的檢測表現(%mAP)
圖像檢索和文本查詢
我們還在多模態檢索任務中評估所習得的自監督視覺特征:(1)圖像查詢與文本數據庫; (2)文本查詢與圖像數據庫。我們使用維基百科檢索數據集,由2,866 個圖像文檔對組成,包含 2173 和 693 對訓練和測試數據。每個圖像--文本對數據都帶有其語義標簽。下表 6 展示了監督和無監督學習方法在多模態檢索任務中的表現,其中監督學習的方法能夠利用與類別相關的每個圖像--文本對信息,而無監督學習方法則不能。
表 8維基數據集上各監督學習和無監督學習方法的表現(%mAP)
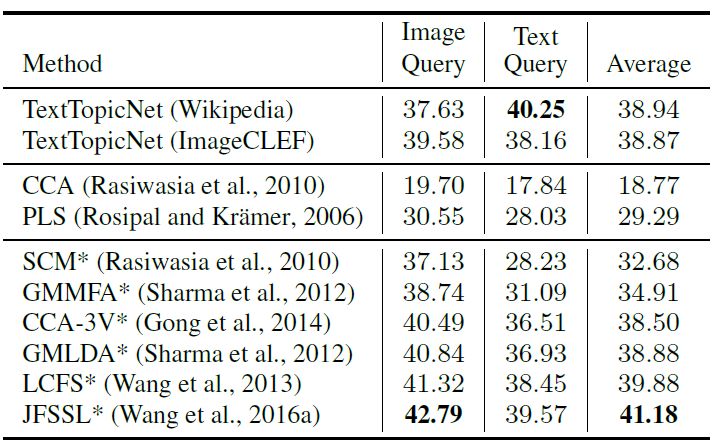
圖 4 顯示了與給定查詢圖像(最左側)最接近的 4 張圖像,其中每行使用的是 TextTopicNet模型不同層次獲得的特征,從上到下:prob,fc7,fc6,pool5層。這些查詢圖像是從 PASCAL VOC 2007中隨機選擇的,且從未在訓練時出現過。
圖4與查詢圖像(最左側)最相近的4張圖像
圖 5顯示了在 TextTopicNet主題空間中,與給定查詢文本最接近的 12 個查詢內容。可以看到,對于第一條查詢文本(“飛機”),所檢索到的圖像列表幾乎是其相同的同義詞,如“flight”,“airway”或“aircraft”。利用文本的語義信息,我們的方法能夠學習多義詞的圖像表示。此外,TextTopicNet模型還能夠處理語義文本查詢,如檢索(“飛機”+ “戰斗機”或“飛行”+“天空”)等。
圖 5與不同文本查詢最接近的12個查詢內容
結論
在本文中,我們提出了一種自監督學習方法,用于學習 LDA模型的文本主題空間。該方法 TextTopicNet能夠在無監督設置下,利用多模態數據的優勢,學習并訓練計算機視覺算法。將文章插圖中的文字視為噪聲圖像標注信息,我們的方法能夠通過視覺特征的學習,訓練 CNN模型并預測在特定的上下文語義中最可能出現的插圖。
我們通過實驗證明我們方法的有效性,并可以擴展到更大、更多樣化的訓練數據集。此外,TextTopicNet模型學到了視覺特征不僅適用于廣泛的主題,而且還能將其應用到更具體、復雜的計算機視覺任務,如圖像分類,物體檢測和多模態檢索。與現有的自監督或無監督方法相比,我們方法的表現更優。
-
計算機
+關注
關注
19文章
7672瀏覽量
90914 -
視覺特征
+關注
關注
0文章
3瀏覽量
5391
原文標題:CMU最新視覺特征自監督學習模型——TextTopicNet
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
任正非說 AI已經確定是第四次工業革命 那么如何從容地加入進來呢?
最新人工智能硬件培訓AI 基礎入門學習課程參考2025版(大模型篇)
使用MATLAB進行無監督學習

機器學習模型市場前景如何
AI模型部署邊緣設備的奇妙之旅:目標檢測模型
cmp在機器學習中的作用 如何使用cmp進行數據對比
時空引導下的時間序列自監督學習框架

LLM和傳統機器學習的區別
FPGA加速深度學習模型的案例
AI大模型與深度學習的關系
特征工程實施步驟






 工商網監
工商網監

評論